

sed執行過程,特點逐行處理
1.把文本第1行讀入到內存 模式空間(pattern space),相當於放到流程水線上處理吧
2.把處理好的結果存放到另一個內存空間(hold space)相當於臨時的倉庫吧
3.輸出處理結果,循環處理第2行,覆蓋清空(pattern space)、(hold space)至最後一行
由於各種各樣的原因,比如用户希望在某個條件下腳本中的某個命令被執行,或者希望模式空間得到保留以便下一次的處理,都有可能使得sed在處理文件的時候不按照正常的流程來進行。這個時候,sed設置了一些高級命令來滿足用户的要求。
sed命令:
- g:[address[,address]]g 將hold space中的內容拷貝到pattern space中,原來pattern space裏的內容清除
- G:[address[,address]]G 將hold space中的內容append到pattern space\n後
- h:[address[,address]]h 將pattern space中的內容拷貝到hold space中,原來的hold space裏的內容被清除
- H:[address[,address]]H 將pattern space中的內容append到hold space\n後
- d:[address[,address]]d 刪除pattern中的所有行,並讀入下一新行到pattern中
- D:[address[,address]]D 刪除multiline pattern中的第一行,不讀入下一行
不管是大寫還是小寫g、h都是在pattern space、hold space相互拷貝
區別是 小寫代表清空原來數據,大寫是保留原來數據在後面追加新數據
案例
[root@case100 ~]# cat sed.txt
1
2
3
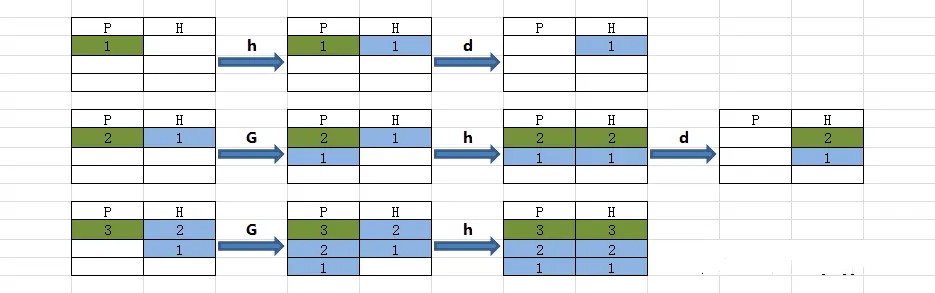
[root@case100 ~]# sed '1!G;h;$!d' sed.txt #ps:1!G第1行不 執行“G”命令,從第2行開始執行。 $!d,最後一行不刪除(保留最後1行)
3
2
1圖解分析過程
P:Pattern Space
H:Hold Space
藍色:Hold Space中的數據
綠色:Pattern Space中的數據
案例
[root@case100 ~]# cat sed2.txt
1
2
3
4
5
[root@case100 ~]# sed '2h;5G' sed2.txt #把第2行放到臨時倉庫(hold space),然後追加到(pattern space)第5行後面
1
2
3
4
5
2
[root@case100 ~]# sed '2h;5g' sed2.txt #把第2行放到臨時倉庫(hold space),然後覆蓋掉(pattern space)第5行數據
1
2
3
4
2
[root@case100 ~]# sed '2h;3H;5g' sed2.txt #把第2行、第3行放到臨時倉庫(hold space),然後覆蓋掉(pattern space)第5行數據
1
2
3
4
2
3
[root@case100 ~]# sed '2h;3h;5g' sed2.txt #把第2行讀入臨時倉庫(hold space);但被後面讀入的第3行數據覆蓋掉了,所以2h其實是無效的,然後第3行數據覆蓋掉(pattern space)第5行數據
1
2
3
4
3參考鏈接:
https://www.cnblogs.com/fhefh/archive/2011/11/22/2259097.html

