

前面已經完成了數據持久層的講解,接下來將圍繞數據庫數據頻繁讀寫的問題探討緩存層的實戰,本篇文章,我們就來聊聊緩存界的“頭號網紅”——讀緩存。這玩意兒大家常用到都快用出“包漿”了,所以基礎操作就此掠過,着重對比下常見緩存方案的優劣。
1.業務場景:如何將十幾秒的查詢請求優化成毫秒級
這次針對的場景是查詢商品詳情頁,隨着商品詳情頁從簡單到複雜,從簡答的商品介紹到加入商品推薦、交易情況... 詳情頁的查詢變得越來越慢,最後達到了十幾秒。
系統裏一共有5w多條商品,數據量不大。項目組開始考慮要怎麼優化。重構數據庫基本不可能,最好不要改動表結構。大家想到的方案也很通用,就是把大部分商品的詳情數據緩存起來,少部分的數據通過異步加載。比如,最近的成交數據通過異步加載,即用户打開商品詳情頁以後,再在後台加載最近的成交數據,並顯示給用户。
關於緩存,最簡單的實現方法就是使用本地緩存,即把商品詳情數據放在JVM裏面。在Google Guava中有一個內存緩存模塊,可以利用它把所有商品的ID與商品詳情信息一對一緩存至JVM內存中,用户獲取商品詳情數據時,系統會根據商品ID直接從緩存中讀取數據,能大大提升用户頁面的訪問速度。
值得注意的是,需要使用jvm緩存數據的時候一定要計算好所需要的內存。 針對當前場景,一條商品大概佔500kb的大小,再將這些數據緩存到本地的話,就要佔用500KB×50000≈25GB內存。此時,假設商品服務有30個服務器節點,僅緩存商品數據就需要額外準備750GB的內存空間,這種方法顯然不可取。
現在我們常用的方法是分佈式存儲,先將所有的緩存數據集中存儲在同一個地方,而非重複保存到各個服務器節點中。

這就涉及接下來要講的緩存中間件技術選型問題了。
2.緩存中間件技術選型(Memcached,MongoDB,Redis)
簡單對比
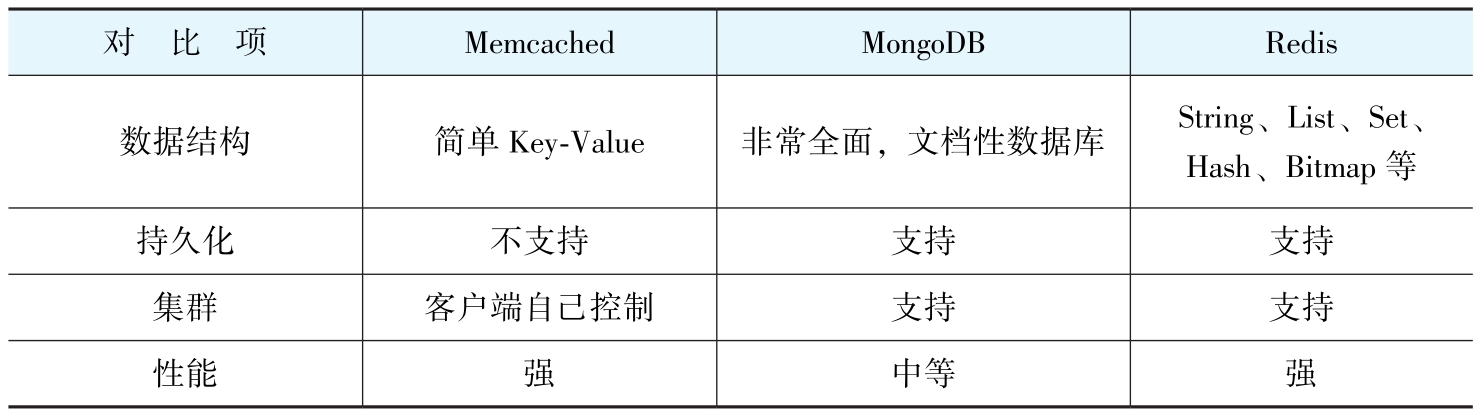
使用MongoDB的公司最少,因為它只是一個數據庫,由於它的讀寫速度與其他數據庫相比更快,人們才把它當作類似緩存的存儲。所以接下來就是比較Redis和Memcached,並從中做出選擇。
目前,Redis比Memcached更流行,這裏總結一下原因,共3點。
1.數據結構
Memcached更新列表繁瑣,需要“取出反序列化-修改-序列化放回”的笨重操作;而Redis則一步到位,直接原地修改,高效又簡單。
2.持久化
Memcached 本身是純內存的,一宕機數據肯定就沒了。雖然從 1.5.18 版本開始,它加個叫‘Restartable Cache 可重啓緩存’的功能,但它的原理是:重啓時CLI先發信號給守護進程,然後守護進程將內存持久化至一個文件中,系統重啓時再從那個文件中恢復數據。所以這招只在‘正常關機’時管用,要是服務器突然崩了這種意外情況,數據照樣丟,它處理不了。
而Redis是有持久化功能的。
3.集羣
Memcached 的集羣架構十分簡潔,其核心機制是依賴客户端進行哈希計算以直接定位目標節點。相比之下,Redis 集羣的設計則複雜許多,它全面考量了高可用性、主從複製、數據冗餘及故障自動轉移等分佈式核心訴求,整體上構成了一個更為完備的分佈式高可用解決方案。
基於上述對比與審慎評估,項目組最終選定 Redis 作為緩存中間件。在完成技術選型後,團隊隨即開始着手規劃緩存的具體實施方案,首要考慮的問題便是數據寫入緩存的時機。
3 緩存何時存儲數據
3.1存儲邏輯
當前使用的邏輯如下:
1)先嚐試查詢緩存
2)若緩存中沒有數據或者數據過期,再從數據庫中讀取數據保存到緩存中。
3)最終把緩存數據返回給調用方。
此模式的主要風險在於,當緩存失效時,突發的併發請求會穿透至數據庫,瞬時的高頻讀取可能導致數據庫負載激增,最終可能導致數據庫崩潰。
3.2常見問題
數據庫的崩潰可以分為3種情況
1 緩存擊穿 - 單一數據過期或者不存在
解決方案:第一個線程如果發現Key不存在,就先給Key加鎖,再從數據庫讀取數據保存到緩存中,最後釋放鎖。
2 緩存雪崩 - 數據大面積過期或者Redis宕機
解決方案:設置緩存的過期時間為隨機分佈或設置永不過期即可。
3 緩存穿透 - 一個惡意請求獲取的Key不在數據庫
比如正常的商品ID是從1到50000,那麼惡意請求就可能會故意請求50000以上的數據。這種情況如果不做處理,惡意請求每次進來時,肯定會發現緩存中沒有值,那麼每次都會查詢數據庫,雖然最終也沒在數據庫中找到商品,但是無疑給數據庫增加了負擔。
解決方案:
- 在業務邏輯中直接校驗,在數據庫不被訪問的前提下過濾掉不存在的Key。
- 針對惡意請求的Key存放一個空值在緩存中,防止惡意請求騷擾數據庫。(例如 列表緩存一個[],對象緩存一個null)
3.3緩存預熱
上述討論聚焦於請求抵達後,系統如何通過“查詢緩存→未命中時查詢數據庫→回寫緩存”的流程來應對。這種被動模式在緩存失效時,會不可避免地消耗額外的服務器資源與數據庫連接。
因此,更優化的策略是在用户請求到達之前,主動將熱點數據加載至Redis中,此過程即為緩存預熱。具體實施上,通常選擇在夜間等業務低峯期,預先執行加載任務,將所需數據存入緩存。如此一來,當高峯流量到來時,絕大部分查詢便可直接命中緩存,從而從根本上減輕數據庫的讀取壓力。
有同學講到對於根據自己的業務邏輯選擇性預熱數據,比如抽獎業務用户進入抽獎頁面就緩存一些用户抽獎用的數據,其實兩者場景應用略有不同。緩存預熱是於流量低谷期主動批量加載數據,旨在應對高峯期的海量讀取壓力。而根據用户行為動態緩存數據,是一種實時按需的 “懶加載” 策略,其主要作用是分流寫入壓力,兩者解決的問題域不同。前者典型場景是高度可預測的集體性事件,後者典型場景是用户行為驅動的個性化請求。
至此,關於緩存數據初始存儲時機的問題已探討完畢。接下來,我們將進入緩存更新策略的討論。由於該環節同時涉及數據庫與緩存的雙寫操作,其一致性與可靠性方案更為複雜,需要展開詳細論述。
4.如何更新緩存
更新緩存的步驟特別簡單,共兩步:更新數據庫和更新緩存。但這簡單的兩步中需要考慮很多問題。
1)先更新數據庫還是先更新緩存?更新緩存時先刪除還是直接更新?
2)假設第一步成功了,第二步失敗了怎麼辦?
3)假設兩個線程同時更新同一個數據,A線程先完成第一步,B線程先完成第二步怎麼辦?
其中,第1個問題就存在5種組合方案,下面逐一進行介紹。(3個問題因為緊密關聯,下面就一起説明)
4.1 更新數據庫 - 更新緩存
問題:在 “先更新緩存,再更新數據庫” 的組合下,若數據庫更新失敗,由於 Redis 不支持事務回滾,只能手動回滾緩存,這會引發複雜的數據一致性問題。
為了清晰展示這個困境,其核心衝突流程可以用下圖概括:
困境詳解
- 問題的根源:手動回滾需要知道“應該回滾到哪個值”。在多線程併發環境下,這個正確的值(上圖中的
c)可能已經被其他線程修改,發起回滾的線程(線程A)無法感知。 - 加鎖的可行性與其代價:
- 可行嗎? 可行。通過在更新緩存和數據庫的整個過程中加分佈式鎖,可以強制串行化,從根本上杜絕上述併發問題。
- 代價是什麼? 代價是系統的性能和複雜度。
- 性能瓶頸:更新操作(特別是耗時久的數據庫操作)會嚴重阻塞其他所有讀寫線程。
- 複雜性劇增:這直接將我們引向了數據庫領域的 “事務隔離級別” 問題(例如“可重複讀”、“讀已提交”)。我們需要考慮:
線程A在更新過程中,線程C來讀取緩存,應該讓它看到最新的值
b,還是原來的值a?如果看到b,但數據庫最終更新失敗了,這就是髒讀。
最終結論:不推薦使用“先更新緩存,再更新數據庫”這個組合。原因在於:我們僅僅是想使用緩存來提升讀性能,但這個組合卻迫使我們為了解決一致性問題,去實現一個重量級的、帶鎖的、需要考慮事務隔離級別的複雜方案。這無異於“殺雞用牛刀”,技術成本和帶來的性能損耗遠超過其收益。
4.2 刪除緩存 - 更新數據庫
此策略的優點是,若數據庫更新失敗,無需回滾緩存(因為緩存已刪)。然而,它引入了一個更棘手的數據不一致問題。其根本原因在於“刪除緩存”和“更新數據庫”這兩個操作不是原子的,在併發讀寫場景下,會導致緩存中存入舊數據。
為了直觀展示這一併發衝突,其典型時序困境可用下圖説明:

- 常見的解決嘗試與代價:
- 加鎖:為保證強一致性,可為該數據加分佈式鎖。寫操作(刪緩存+更新庫)持有鎖期間,所有併發的讀操作必須等待。
- 代價:系統可用性急劇下降。由於數據庫更新(特別是複雜事務)通常較慢,這會導致大量讀請求被長時間阻塞,違背了使用緩存提升性能的初衷。
結論:“先刪緩存,再更新數據庫”這一策略,在併發環境下會引發嚴重的緩存髒數據(舊值)問題。
若試圖通過加鎖來強制實現一致性,則會以犧牲系統可用性(性能) 為代價。這實質上反映了分佈式系統設計中經典的 “一致性”與“可用性”難以兼顧 的權衡困境(即CAP理論中的C與A的博弈)。
4.3 更新數據庫 - 更新緩存
問題1:第一步(更新數據庫)成功,第二步(更新緩存)失敗
- **場景**:數據庫更新成功,但後續緩存更新失敗(網絡異常、服務宕機等)。
- **後果**:數據庫為新值,緩存為舊值,數據不一致。
- **常規解決**:採用重試機制,但重試延遲期間不一致窗口依然存在,且重試本身可能失敗,處理複雜。
問題2:併發更新時序錯亂
- **場景**:兩個線程併發更新同一數據。
- **時序**:
1. 線程A更新數據庫為 `a`
2. 線程B更新數據庫為 `b`
3. 線程B更新緩存為 `b`
4. 線程A更新緩存為 `a`
- **結果**:數據庫最新值為 `b`,緩存卻為 `a`,再次不一致。
該組合雖然看似自然(先更新權威數據源,再同步緩存),但在分佈式環境下,缺乏事務邊界和時序保障,使得一致性問題難以規避。因此,在要求強一致或高併發的場景中,應避免直接使用此方案。
4.4 更新數據庫 - 刪除緩存
針對此方案,解決了方案3的問題2,不會出現併發更新緩存的問題,直接刪除緩存數據誰先完成已經不重要了。對於方案3的問題1,方案4也有可能發生,但概率更低,因為redis刪除操作要比更新操作簡單。那麼還有其他問題嗎?假設線程A要更新數據,先完成第一步更新數據庫,在線程A刪除緩存之前,線程B要訪問緩存,那麼取得的就是舊數據。這是一個小小的缺陷。
4.5 刪除緩存 - 更新數據庫 - 刪除緩存
這個方案跟方案4類似,也有可能遇到問題2類似的問題:線程A要更新數據庫,先刪除了緩存,線程B要讀緩存,並且更新了緩存,線程A完成更新數據庫;線程C也要訪問緩存,此時就是訪問的B讀的舊數據。

不過這種數據不一致的情況出現概率比方案4更底,因為他需要3個線程配合才會出現問題。
相較於方案四 規避了第二部刪除緩存失敗的問題,因為緩存已經刪除了.
在諸多無鎖方案中,這是一個通過增加一次同步操作,在複雜度與一致性之間取得更好平衡的折中選擇。它承認沒有完美解,但致力於將不一致窗口和發生概率降到極低。
在實踐中,第二次刪除常被設置為延遲執行(例如,在數據庫更新完成後等待幾百毫秒),目的是為了確保能清除掉在“更新數據庫”期間可能被其他線程讀入緩存的舊數據。這步“延遲”是對方案的常見增強,旨在進一步壓縮不一致窗口。
不過這個組合也有一些問題要考慮,具體如下。
1)刪除緩存數據後變相出現緩存擊穿,此時該怎麼辦?此問題在前面已經給出了方案。
2)刪除緩存失敗如何重試?這個重試可以做得複雜一點,也可以做得簡單一點。簡單一點就是使用try…catch…,假設刪除緩存失敗了,在catch裏面重試一次即可;複雜一點就是使用一個異步線程不斷重試,甚至用到MQ。不過這裏沒有必要大動干戈。而且異步重試的延時大,會帶來更多的讀髒數據的可能性。所以僅僅同步重試一次就可以了。
3)不可避免的髒數據問題。雖然這個問題在組合5中出現的概率已經大大降低了,但是還是有的。關於這一點就需要與業務溝通,畢竟這種情況比較少見,可以根據實際業務情況判斷是否需要解決這個瑕疵。
TIPS:講到這裏你可以發現,沒有一個方案能夠100%解決數據不一致的問題,這些操作的組合旨在不加鎖限制性能的情況下 如何使得數據不一致的概率降到最低。任何一個方案都不是完美的,但如果剩下1%的問題需要花好幾倍的代價去解決,從技術上來講得不償失,這就要求架構師去説服業務方,去平衡技術的成本和收益。
5.緩存的高可用設計
關於緩存高可用設計,其內容本可獨立成章。但考慮到本書以場景實踐為核心,而非理論詳解,因此在此僅作概要性闡述,不展開討論詳細的實現機制,而是聚焦核心設計要點。
- 負載均衡:能否通過增加節點,以水平擴展的方式分散讀請求壓力。
- 數據分片:能否通過將數據劃分到不同節點,以水平擴展的方式分散寫壓力與存儲容量。
- 數據冗餘:當單一節點數據失效時,其他節點是否持有副本數據,可立即接管其職責,保障服務不中斷。
- 故障轉移(Failover):在任一節點發生故障後,集羣能否自動進行職責重新分配,確保整體持續可用。
- 一致性保證:在數據冗餘、故障轉移及數據再平衡的過程中,若出現意外,能否確保節點間或與底層數據源之間的數據一致性(注:這通常不能僅依賴緩存自身機制實現)。
若項目對緩存高可用有明確要求,Redis Cluster 模式是一個綜合性解決方案,它完整涵蓋了上述五個要點的設計。關於其具體配置與部署方式,可詳細參閲 Redis 官方文檔或相關專題教程。
6.緩存的監控
緩存上線後需建立持續的監控機制,通過關鍵指標分析來評估其效能並指導業務邏輯的調優。核心監控指標通常包括緩存命中率、內存使用率、慢查詢日誌、操作延遲及客户端連接數等。隨着業務複雜度提升,可進一步擴展監控維度以覆蓋更細緻的場景。
實踐中可依據技術棧與運維體系,選用自研監控平台或成熟的開源方案(如 RedisLive、Redis‑monitor 等)。監控工具的選型最終應結合實際的運維需求、技術儲備與成本進行綜合決策。
7.小結
這一篇關於“讀緩存”的內容,雖然比較常規,但是……(看,這裏也有個“但是”)能切實支撐業務、解決痛點的技術,就是好技術!
目前,“讀高併發”或“讀響應慢”的場景,我們已經有了緩存這把利器。但數據庫的“寫壓力”問題依然懸而未決。別走開,下一篇,我們將直面“寫緩存”的挑戰,看如何讓數據庫的寫入操作也能“輕裝上陣”。