
Golang 協程/線程/進程 區別詳解
轉載請註明來源:https://janrs.com/mffp
概念
進程 每個進程都有自己的獨立內存空間,擁有自己獨立的地址空間、獨立的堆和棧,既不共享堆,亦不共享棧。一個程序至少有一個進程,一個進程至少有一個線程。進程切換隻發生在內核態。
線程 線程擁有自己獨立的棧和共享的堆,共享堆,不共享棧,是由操作系統調度,是操作系統調度(CPU調度)執行的最小單位。對於進程和線程,都是有內核進行調度,有 CPU 時間片的概念, 進行搶佔式調度。內核由系統內核進行調度, 系統為了實現併發,會不斷地切換線程執行, 由此會帶來線程的上下文切換。
協程 協程線程一樣共享堆,不共享棧,協程是由程序員在協程的代碼中顯示調度。協程(用户態線程)是對內核透明的, 也就是系統完全不知道有協程的存在, 完全由用户自己的程序進行調度。在棧大小分配方便,且每個協程佔用的默認佔用內存很小,只有 2kb ,而線程需要 8mb,相較於線程,因為協程是對內核透明的,所以棧空間大小可以按需增大減小。
併發 多線程程序在單核上運行
並行 多線程程序在多核上運行
協程與線程主要區別是它將不再被內核調度,而是交給了程序自己而線程是將自己交給內核調度,所以golang中就會有調度器的存在。
詳解
進程
在計算機中,單個 CPU 架構下,每個 CPU 同時只能運行一個任務,也就是同時只能執行一個計算。如果一個進程跑着,就把唯一一個 CPU 給完全佔住,顯然是不合理的。而且很大概率上,CPU 被阻塞了,不是因為計算量大,而是因為網絡阻塞。如果此時 CPU 一直被阻塞着,其他進程無法使用,那麼計算機資源就是浪費了。
這就出現了多進程調用了。多進程就是指計算機系統可以同時執行多個進程,從一個進程到另外一個進程的轉換是由操作系統內核管理的,一般是同時運行多個軟件。
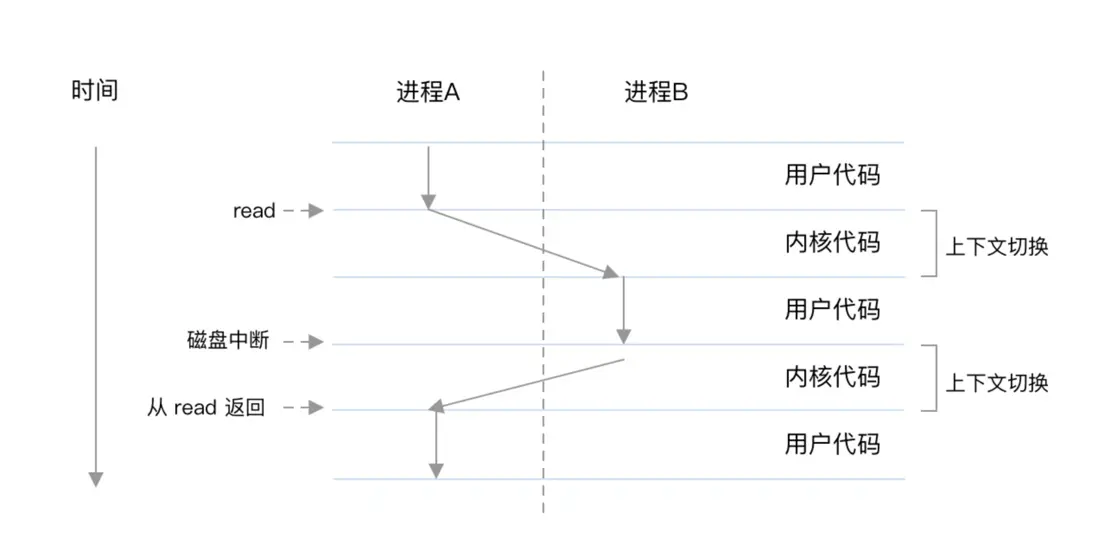
線程
有了多進程,為什麼還要線程?原因如下:
- 進程間的信息難以共享數據,父子進程並未共享內存,需要通過進程間通信(IPC),在進程間進行信息交換,性能開銷較大。
- 創建進程(一般是調用 fork 方法)的性能開銷較大。
在一個進程內,可以設置多個執行單元,這個執行單元都運行在進程的上下文中,共享着同樣的代碼和全局數據,由於是在全局共享的,就不存在像進程間信息交換的性能損耗,所以性能和效率就更高了。這個運行在進程中的執行單元就是線程。

協程
官方的解釋:鏈接:goroutines説明
Goroutines是使併發易於使用的一部分。 這個想法已經存在了一段時間,就是將獨立執行的函數(協程)多路複用到一組線程上。 當協程阻塞時,例如通過調用阻塞系統調用,運行時會自動將同一操作系統線程上的其他協程移動到不同的可運行線程,這樣它們就不會被阻塞。 程序員看不到這些,這就是重點。 我們稱之為 goroutines 的結果可能非常便宜:除了堆棧的內存之外,它們的開銷很小,只有幾千字節。為了使堆棧變小,
Go的運行時使用可調整大小的有界堆棧。 一個新創建的goroutine被賦予幾千字節,這幾乎總是足夠的。 如果不是,運行時會自動增加(和縮小)用於存儲堆棧的內存,從而允許許多goroutine存在於適度的內存中。 每個函數調用的CPU開銷平均約為三個廉價指令。 在同一個地址空間中創建數十萬個goroutine是很實際的。 如果goroutines只是線程,系統資源會以更少的數量耗盡。
從官方的解釋中可以看到,協程是通過多路複用到一組線程上,所以本質上,協程就是輕量級的線程。但是必須要區分的一點是,協程是用用户態的,進程跟線程都是內核態,這點非常重要,這也是協程為什麼高效的原因。
協程的優勢如下:
- 節省
CPU:避免系統內核級的線程頻繁切換,造成的CPU資源浪費。協程是用户態的線程,用户可以自行控制協程的創建於銷燬,極大程度避免了系統級線程上下文切換造成的資源浪費。 - 節約內存:在
64位的Linux中,一個線程需要分配8MB棧內存和64MB堆內存,系統內存的制約導致我們無法開啓更多線程實現高併發。而在協程編程模式下,只需要幾千字節(執行Go協程只需要極少的棧內存,大概4~5KB,默認情況下,線程棧的大小為1MB)可以輕鬆有十幾萬協程,這是線程無法比擬的。 - 開發效率:使用協程在開發程序之中,可以很方便的將一些耗時的
IO操作異步化,例如寫文件、耗時IO請求等。並且它們並不是被操作系統所調度執行,而是程序員手動可以進行調度的。 - 高效率:協程之間的切換髮生在用户態,在用户態沒有時鐘中斷,系統調用等機制,因此效率高。
Golang GMP 調度器
注: 以下相關知識摘自劉丹冰(AceLd)的博文:[[Golang三關-典藏版] Golang 調度器 GMP 原理與調度全分析](https://learnku.com/articles/41728 "[Golang三關-典藏版] Golang 調度器 GMP 原理與調度全分析")
簡介
G表示:goroutine,即Go協程,每個go關鍵字都會創建一個協程。M表示:thread內核級線程,所有的G都要放在M上才能運行。P表示:processor處理器,調度G到M上,其維護了一個隊列,存儲了所有需要它來調度的G。
Goroutine 調度器 P 和 OS 調度器是通過 M 結合起來的,每個 M 都代表了 1 個內核線程,OS 調度器負責把內核線程分配到 CPU 的核上執行,
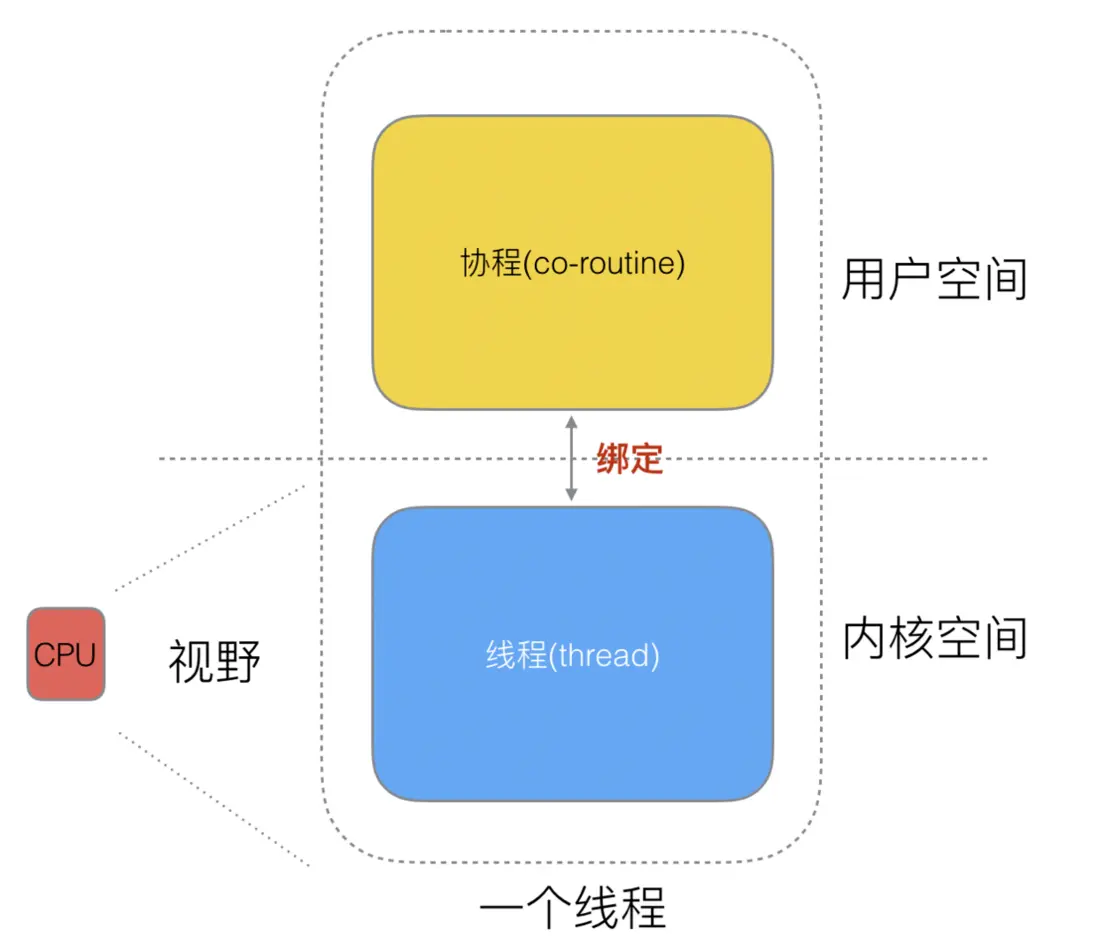
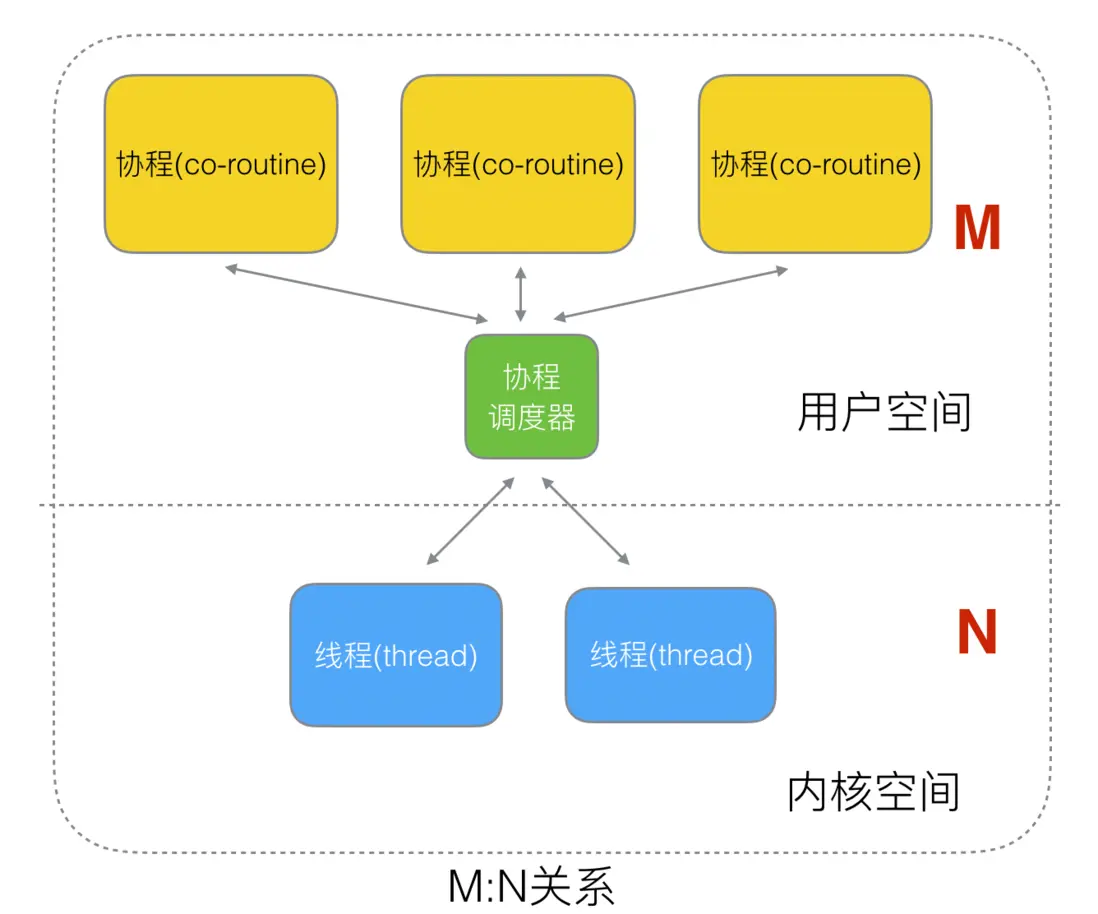
線程和協程的映射關係
在上面的 Golang 官方關於協程的解釋中提到:
將獨立執行的函數(協程)多路複用到一組線程上。 當協程阻塞時,例如通過調用阻塞系統調用,運行時會自動將同一操作系統線程上的其他協程移動到不同的可運行線程,這樣它們就不會被阻塞。
也就是説,協程的執行是需要通過線程來先實現的。下圖表示的映射關係:
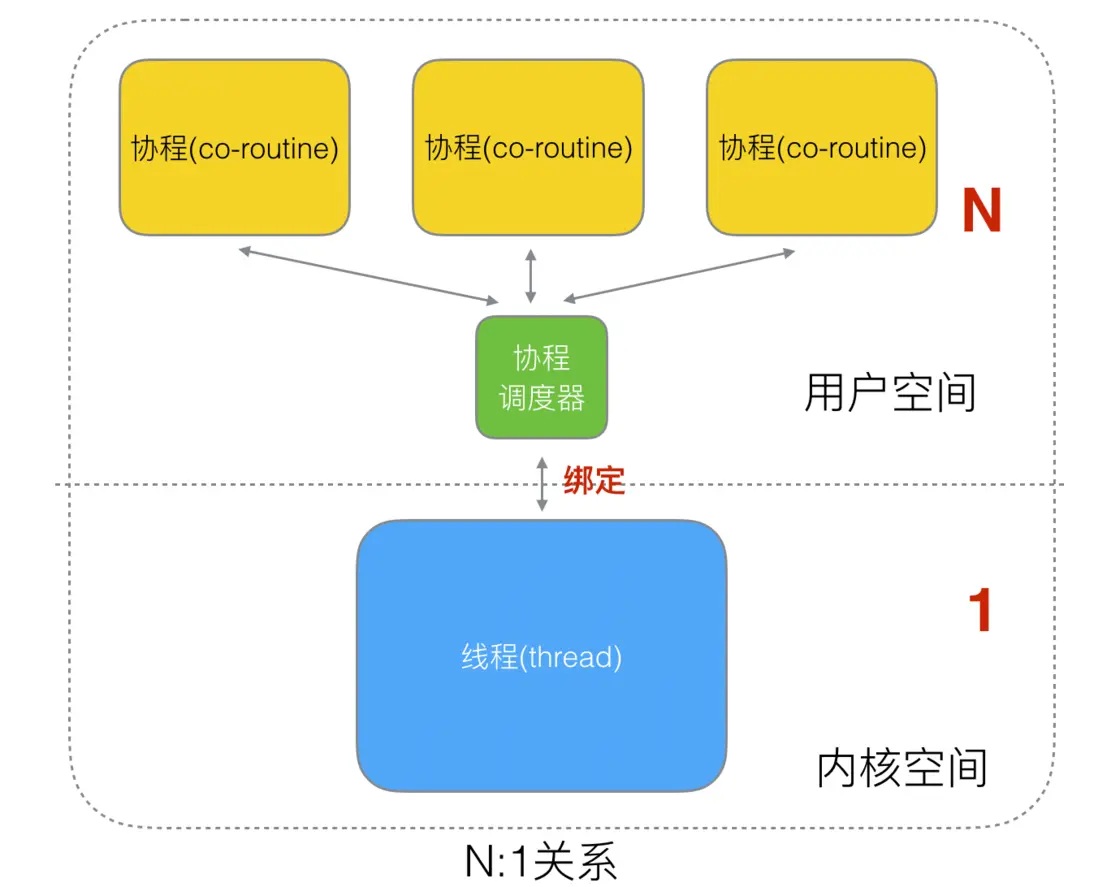
在協程和線程的映射關係中,有以下三種:
N:1關係1:1關係M:N關係
N:1 關係
N 個協程綁定 1 個線程,優點就是協程在用户態線程即完成切換,不會陷入到內核態,這種切換非常的輕量快速。但也有很大的缺點,1 個進程的所有協程都綁定在 1 個線程上。
缺點:
- 某個程序用不了硬件的多核加速能力
- 一旦某協程阻塞,造成線程阻塞,本進程的其他協程都無法執行了,根本就沒有併發的能力了。
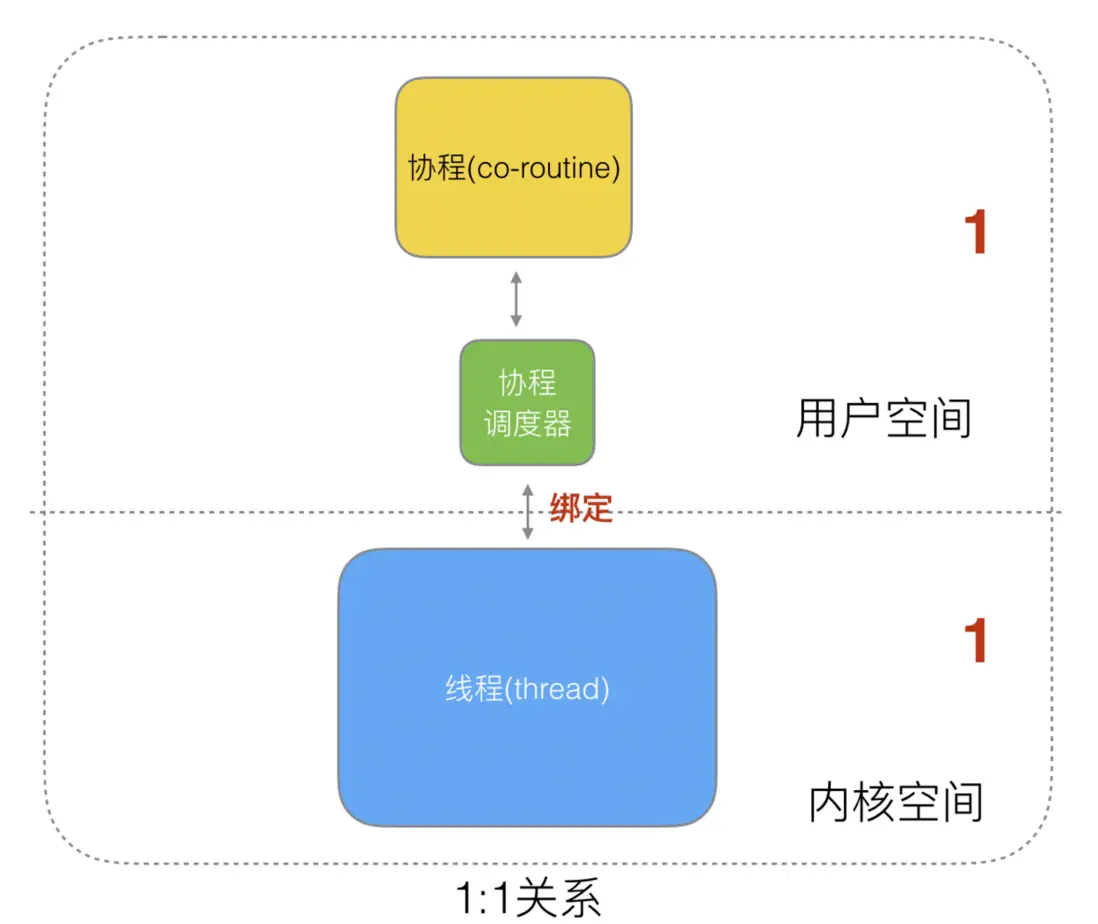
1:1 關係
1 個協程綁定 1 個線程,這種最容易實現。協程的調度都由 CPU 完成了,不存在 N:1 缺點。
缺點:
- 協程的創建、刪除和切換的代價都由
CPU完成,有點略顯昂貴了。
M:N 關係
M 個協程綁定 1 個線程,是 N:1 和 1:1 類型的結合,克服了以上 2 種模型的缺點,但實現起來最為複雜。
協程跟線程是有區別的,線程由 CPU 調度是搶佔式的,協程由用户態調度是協作式的,一個協程讓出 CPU 後,才執行下一個協程。
調度器實現原理
注:Go目前使用的調度器是2012年重新設計的。
2012 之前的調度原理,如下圖所示:
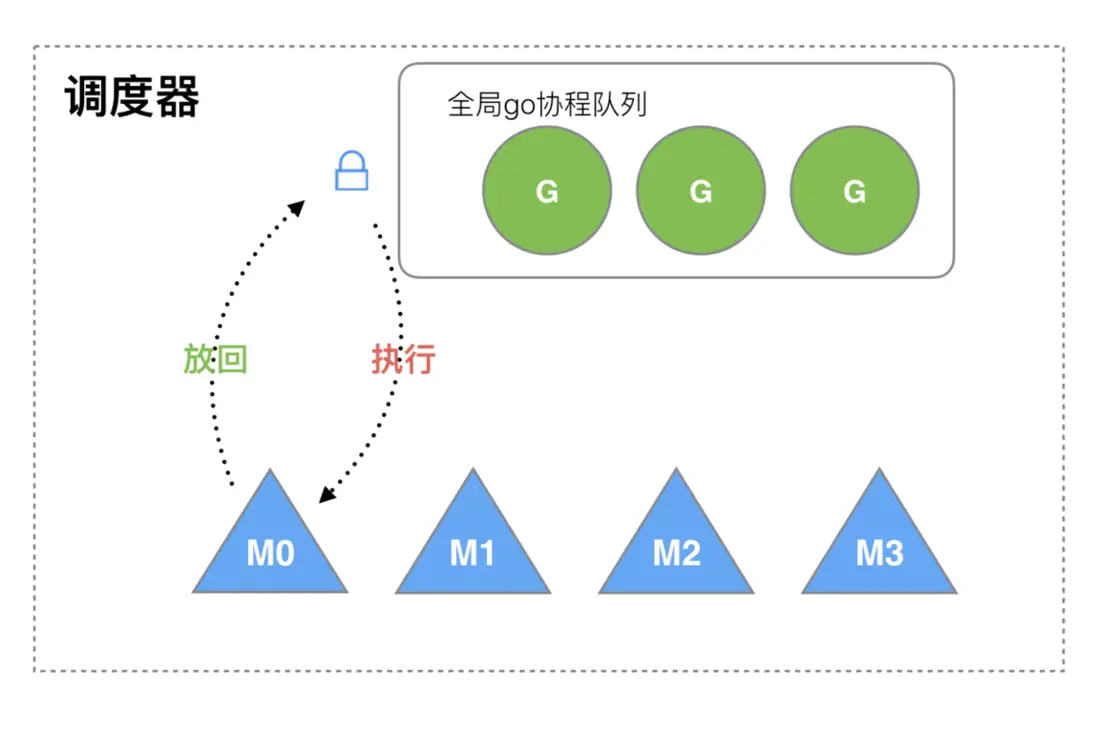
M 想要執行、放回 G 都必須訪問全局 G 隊列,並且 M 有多個,即多線程訪問同一資源需要加鎖進行保證互斥 / 同步,所以全局 G 隊列是有互斥鎖進行保護的。
缺點:
- 創建、銷燬、調度
G都需要每個M獲取鎖,這就形成了激烈的鎖競爭。 M轉移G會造成延遲和額外的系統負載。比如當G中包含創建新協程的時候,M創建了G,為了繼續執行G,需要把G交給M執行,也造成了很差的局部性,因為G和G是相關的,最好放在M上執行,而不是其他M。- 系統調用 (
CPU 在 M 之間的切換) 導致頻繁的線程阻塞和取消阻塞操作增加了系統開銷。
2012 年之後的調度器實現原理,如下圖所示:
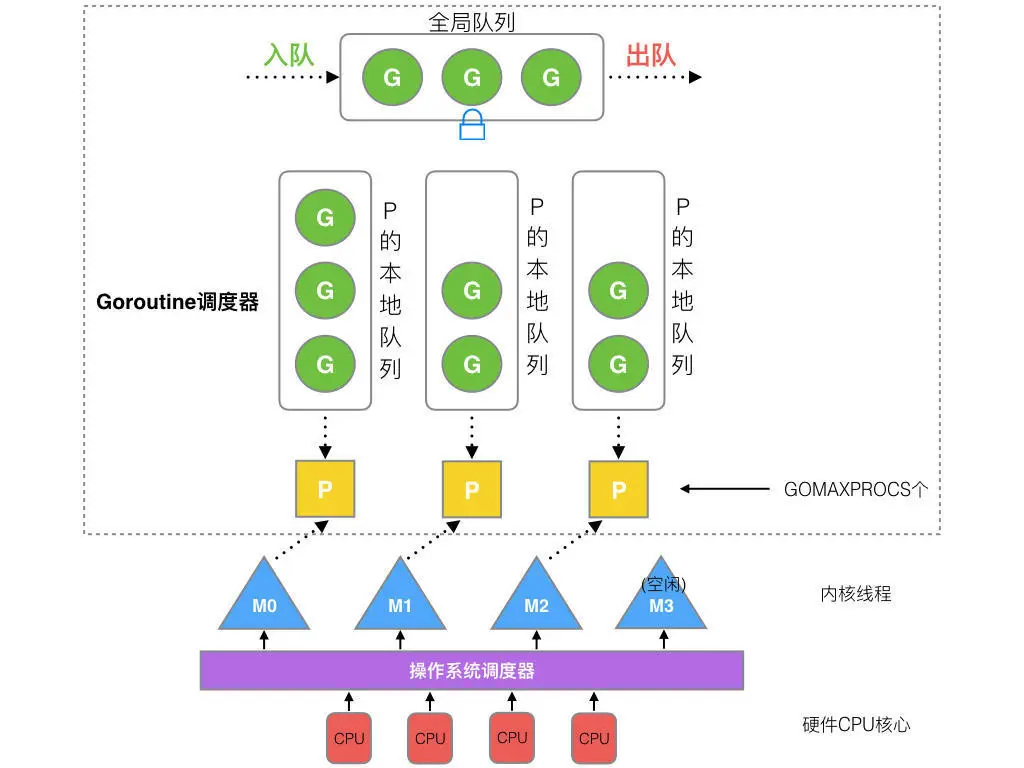
在新調度器中,除了 M (thread) 和 G (goroutine),又引進了 P (Processor)。Processor,它包含了運行 goroutine 的資源,如果線程想運行 goroutine,必須先獲取 P,P 中還包含了可運行的 G 隊列。
在 Go 中,線程是運行 goroutine 的實體,調度器的功能是把可運行的 goroutine 分配到工作線程上。調度過程如下:
- 全局隊列(
Global Queue):存放等待運行的G。 P的本地隊列:同全局隊列類似,存放的也是等待運行的G,存的數量有限,不超過256個。新建G時,G優先加入到P的本地隊列,如果隊列滿了,則會把本地隊列中一半的G移動到全局隊列。P列表:所有的P都在程序啓動時創建,並保存在數組中,最多有GOMAXPROCS(可配置) 個。M:線程想運行任務就得獲取P,從P的本地隊列獲取G,P隊列為空時,M也會嘗試從全局隊列拿一批G放到P的本地隊列,或從其他P的本地隊列偷一半放到自己P的本地隊列。M運行G,G執行之後,M會從P獲取下一個G,不斷重複下去。
Goroutine 調度器和 OS 調度器是通過 M 結合起來的,每個 M 都代表了 1 個內核線程,OS 調度器負責把內核線程分配到 CPU 的核上執行。
調度器設計策略
複用線程: 避免頻繁的創建、銷燬線程,而是對線程的複用。
work stealing機制
當本線程無可運行的 G 時,嘗試從其他線程綁定的 P 偷取 G,而不是銷燬線程。
hand off機制
當本線程因為 G 進行系統調用阻塞時,線程釋放綁定的 P,把 P 轉移給其他空閒的線程執行。
- 利用並行:
GOMAXPROCS設置P的數量,最多有GOMAXPROCS個線程分佈在多個CPU上同時運行。GOMAXPROCS也限制了併發的程度,比如GOMAXPROCS = 核數/2,則最多利用了一半的CPU核進行並行。 - 搶佔:在
coroutine中要等待一個協程主動讓出CPU才執行下一個協程,在Go中,一個goroutine最多佔用CPU10ms,防止其他goroutine被餓死,這就是goroutine不同於coroutine的一個地方。 - 全局
G隊列:在新的調度器中依然有全局G隊列,但功能已經被弱化了,當M執行work stealing從其他P偷不到G時,它可以從全局G隊列獲取G。
go func () 調度流程
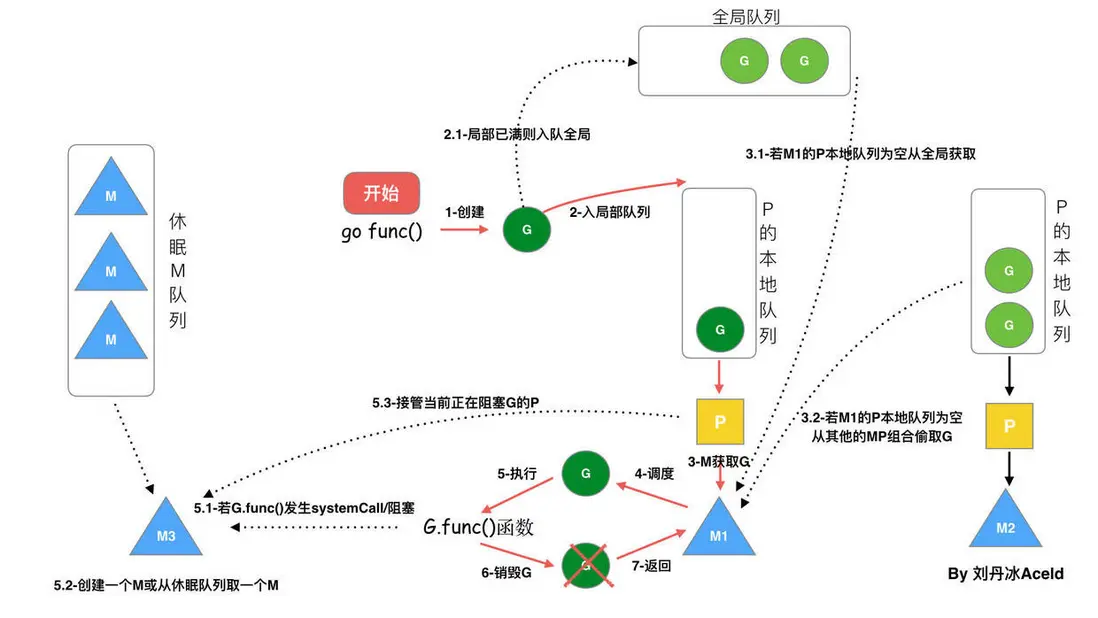
流程如下:
- 通過
go func ()來創建一個goroutine - 有兩個存儲
G的隊列,一個是局部調度器P的本地隊列、一個是全局G隊列。新創建的G會先保存在P的本地隊列中,如果P的本地隊列已經滿了就會保存在全局的隊列中; G只能運行在M中,一個M必須持有一個P,M與P是1:1的關係。M會從P的本地隊列彈出一個可執行狀態的G來執行,如果P的本地隊列為空,就會向其他的MP組合偷取一個可執行的G來執行;- 一個
M調度G執行的過程是一個循環機制; - 當
M執行某一個G時候如果發生了syscall或則其餘阻塞操作,M會阻塞,如果當前有一些G在執行,runtime會把這個線程M從P中摘除 (detach),然後再創建一個新的操作系統的線程 (如果有空閒的線程可用就複用空閒線程) 來服務於這個P; - 當
M系統調用結束時候,這個G會嘗試獲取一個空閒的P執行,並放入到這個P的本地隊列。如果獲取不到P,那麼這個線程M變成休眠狀態, 加入到空閒線程中,然後這個G會被放入全局隊列中。
調度器的生命週期
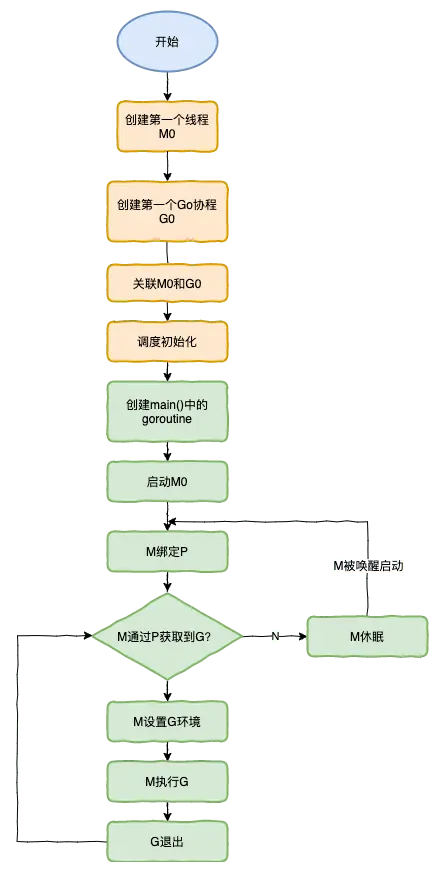
特殊的 M0 和 G0
M0
M0 是啓動程序後的編號為 0 的主線程,這個 M 對應的實例會在全局變量 runtime.m0 中,不需要在 heap 上分配,M0 負責執行初始化操作和啓動第一個 G, 在之後 M0 就和其他的 M 一樣了。
G0
G0 是每次啓動一個 M 都會第一個創建的 goroutine,G0 僅用於負責調度的 G,G0 不指向任何可執行的函數,每個 M 都會有一個自己的 G0。在調度或系統調用時會使用 G0 的棧空間,全局變量的 G0 是 M0 的 G0。
我們來跟蹤一段代碼:
package main
import "fmt"
func main() {
fmt.Println("Hello world")
}接下來我們來針對上面的代碼對調度器裏面的結構做一個分析,也會經歷如上圖所示的過程:
runtime創建最初的線程m0和goroutine g0,並把2者關聯。- 調度器初始化:初始化
m0、棧、垃圾回收,以及創建和初始化由GOMAXPROCS個P構成的P列表。 - 示例代碼中的
main函數是main.main,runtime中也有1個main函數 ——runtime.main,代碼經過編譯後,runtime.main會調用main.main,程序啓動時會為runtime.main創建goroutine,稱它為main goroutine吧,然後把main goroutine加入到P的本地隊列。 - 啓動
m0,m0已經綁定了P,會從P的本地隊列獲取G,獲取到main goroutine。 G擁有棧,M根據G中的棧信息和調度信息設置運行環境。M運行G。G退出,再次回到M獲取可運行的G,這樣重複下去,直到main.main退出,runtime.main執行Defer和Panic處理,或調用runtime.exit退出程序。
調度器的生命週期幾乎佔滿了一個 Go 程序的一生,runtime.main 的 goroutine 執行之前都是為調度器做準備工作,runtime.main 的 goroutine 運行,才是調度器的真正開始,直到 runtime.main 結束而結束。
轉載請註明來源:https://janrs.com/mffp

