

隨着大語言模型(LLM)能力不斷增強,我們逐漸發現一個事實:
真正有價值的,不是模型“會説話”,而是模型“能做事”。
因為再強大的LLM,其核心優勢仍然在於語言理解與推理能力,而非實時計算或外部狀態獲取。, 在某些簡單事情上, 例如 查詢當前時間, 當前地區的天氣, 進行一個簡單的數學運算, 其實都不是大模型擅長的事情, 我們也不需要大模型全知全能, 這不是一個正確的路線.
大模型應該像人類的大腦, 他只需要足夠的聰明, 可以判斷出做某些事情,需要什麼工具. 就像人類大腦不會揀樹枝, 但是可以使用手臂做這件事.
例如在查詢天氣這件事上, 我們不需要給大模型本身上報各種數據庫, 而是需要大模型在判斷需要查詢天氣的時候,調用一個外部的接口即可. 做數學運算時,調用一個計算器接口, 等等
而“做事”,就繞不開 工具調用、Agent 協作、以及標準化協議。
1. Tool Calling: 工具調用
Tool Calling(函數調用) 是大模型的一種能力:
模型在推理過程中,不直接給出最終答案,而是返回一個結構化 JSON,表示“我需要調用某個工具”。
JavaAI 框架, 例如Spring AI 等, 對於ToolCalling都有實現, 註冊工具,告訴大模型可以執行該工具的條件和參數,大模型在決策需要調用時, 返回調用指令, 本地框架反射執行函數, 再將結果返回到上下文, 大模型繼續決策.
從系統角度看,Tool Calling 做了三件事:
- 模型 → 輸出結構化指令
- 框架 → 解析指令
- 本地代碼 → 執行真實邏輯
Tool Calling 的侷限
Tool Calling 雖然重要,但它有明顯邊界:
- 工具調用的決策和編排只存在於單個 Agent 的推理循環中
- 不同框架(Spring AI / LangChain)工具定義不通用
- 缺乏統一的權限、發現、生命週期管理
這就引出了下一階段。
2. MCP:Agent 世界的“HTTP 協議”
MCP(Model Context Protocol,模型上下文協議) ,2024年11月底,由Anthropic 推出的一種開放標準。旨在為大語言模型(LLM)提供統一的、標準化方式與外部數據源和工具之間進行通信。
一句話:
MCP 是 Agent 與外部世界交互的統一協議層。
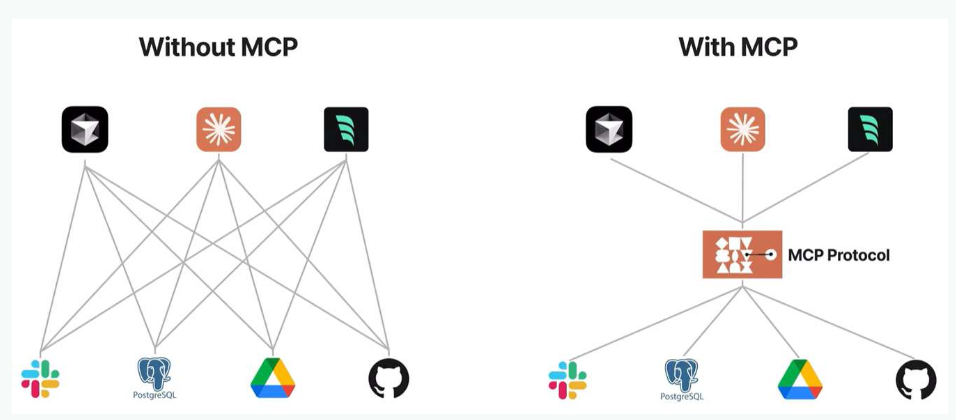
如上圖所示, 在傳統的大模型調用外部工具, 例如訪問數據庫,訪問互聯網數據的能力, 我們需要針對每一個框架, 每一個外部工具,都需要實現一套單獨的調用函數, 函數的調用和代碼完全耦合,
而有了MCP協議,在AI的世界裏, 不管是調用方還是被調用方, 大家只需要都實現這套協議, 就可以無障礙,無溝通的進行聯繫,就像硬件世界的USB
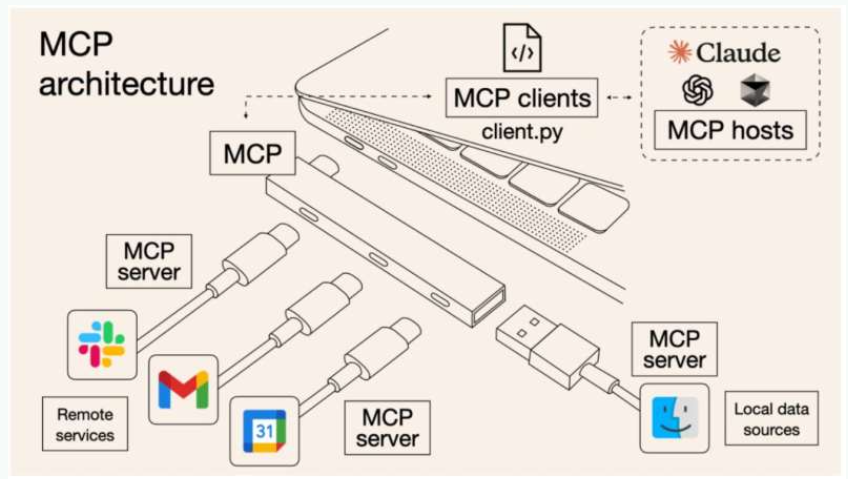
MCP 和 HTTP.TCP/IP協議的類比:
| 特徵 | MCP | TCP/IP、HTTPS |
|---|---|---|
| 本質 | 協議(Protocol) | 協議(Protocol) |
| 作用 | 標準化 AI 模型與上下文來源/工具之間的數據交互方式 | 標準化 設備之間的網絡通信方式 |
| 目標 | 讓不同 AI 應用 / Agent 以統一方式訪問外部資源和工具 | 讓不同設備、系統可以互通數據 |
| 好處 | 消除碎片化集成、形成生態閉環 | 解決設備互聯、實現互聯網基礎 |
2.1 MCP協議的兩種實現方式: stdio和SSE
在上文中, 我們知道了MCP是一種協議, 是規範Agent如何調用工具, 工具如何響應的規範, 而工具在這是作為Server. Agent作為Client, 他們的通信是如何實現的, 有哪些實現方式.
官方參考實現中,主要提供了 stdio 方式,同時也支持基於 HTTP/SSE(實驗 & 可選) 的遠程實現。 分別對應本地調用和遠程調用的使用.
2.1.1 SSE(Server-Sent Events)
SSE 是一種基於 HTTP 的單向流式通信方式:
- 客户端發起 HTTP 請求
- 服務器保持連接不斷開
- 服務器可以持續往客户端推送消息
SSE是實現Client遠程調用Server的方式. Server部署在雲端, 具體的工作流程如下:
Client
│
│ HTTP POST /agent/run (這裏就已經把請求發完了)
▼
Server
│
│ 200 OK
│ Content-Type: text/event-stream
│
│ 開始SSE
│ data: ...
│ data: ...
│ data: ...
注意, Client發送HTTP請求Server提出問題的流程,並不是SSE協議的部分, 這只是一個普通的HTTP請求. 只需要遵循相應的請求規範.
但是此時客户端將會與Server建立一個基於HTTP協議的長鏈接,一直監聽Server對於此問題的回答,此時才是SSE所描述的Server-Sent Events流程.
網上對於SSE的描述,都是説SSE是一個單向流式輸出的通道, 但不是理解成 SSE 是一個“只能服務器説話,客户端不能説話”的通道
正確理解
SSE 是一次普通 HTTP 請求 + 一個不斷寫數據的響應
下面是一個天氣預報查詢的示例, 展示通過SSE協議, Agent作為Client 如何與天氣預報Server交互
- 客户端 → Server(普通 HTTP 請求)
POST /agent/run
Content-Type: application/json
{
"input": "杭州今天天氣怎麼樣?"
}
這一步 不是 SSE
只是一個普通 HTTP POST。
- Server 內部
接收請求
↓
Server 調用天氣 API(這是 Server → 外部)
↓
拿到結果
- Server → Client(SSE 開始推送)
data: {"type":"thinking","content":"需要查詢天氣"}
data: {"type":"tool_call","name":"weather","args":{"city":"杭州"}}
data: {"type":"observation","content":"晴 26℃"}
data: {"type":"final","content":"杭州今天晴,26℃"}
客户端從頭到尾只發了一次請求
SSE的優缺點:
優點:
- 基於 HTTP,簡單
- 瀏覽器原生支持
- 適合流式 AI 輸出
缺點:
- 單向(Server → Client),
- 連接數多時壓力較大
2.1.2 stdio
stdio 的本質
stdio = 標準輸入 / 標準輸出
stdin → 程序輸入
stdout → 程序輸出
stderr → 錯誤輸出
這是 一個基於操作系統級別的進程通信方式。
所以基於stdio實現的Server都是通過本地進程的, 因為Client和Server 只能通過OS級別的通道進行交互
MCP 官方和目前大部分Server大部分都是使用 stdio. 這是一個設計取捨問題
原因 1:安全
- 不需要監聽端口
- 不暴露網絡服務
原因 2:本地工具友好,可以實現更多樣化的功能
- Git
- FileSystem
- SQLite
- Docker
對於stdio本地通信的理解:
stdio 只能“本地部署”
不等於:只能訪問本地數據
真正含義是:通信通道是本機進程級的. 具體的功能可以訪問外部數據
stdio的工作流程如下:
Agent需要調用某個工具
↓
啓動這個進程
↓
通過 stdin 發送 JSON
↓
通過 stdout/stderr 接收 JSON/
-
Agent 啓動 這個 MCP Server 進程
-
通過 管道(pipe) 通信
-
這兩個進程 必須在同一台機器上
所以當我們需要使用某個工具時, 需要在Agent本機部署一個對應Server即可, 網上有很多這樣的實現, 例如https://github.com/modelcontextprotocol/servers 下載需要的服務即可.
例如一個天氣預報的調用方式:
LLM Agent
│ stdio
▼
MCP Server
│
│ HTTP 請求
▼
天氣 API(公網)
本機的Server封裝了對遠程HTTPAPI的調用
對比:
| 對比項 | SSE | stdio |
|---|---|---|
| 層級 | 網絡(HTTP) | 操作系統 |
| 是否流式 | ✅ | ✅ |
| 通信方向 | 單向(推送) | 雙向 |
| 是否跨機器 | ✅ | ❌(本地) |
| 適合場景 | Web / 雲服務 | 本地工具 |
| MCP 常用 | 🌟🌟 | 🌟🌟🌟 |
2.2 MCP的使用
下面將通過一個簡單的示例演示一下如何在cursor中 使用MCP.
首先需要在MCP Servers 網站上找到自己需要的服務. 我這裏使用的是 https://www.mcpservers.cn/ , 也可以使用其他的, 例如 smithery.ai等.
然後搜索需要的服務, 例如MySQL的連接工具. 並進入它的github官網(https://github.com/designcomputer/mysql_mcp_server),找到配置方式. 例如:
"mysql": {
"type": "stdio",
"command": "uvx",
"args": [
"--from",
"mysql-mcp-server",
"mysql_mcp_server"
],
"env": {
"MYSQL_HOST": "121.36.**.**",
"MYSQL_PORT": "3306",
"MYSQL_USER": "root",
"MYSQL_PASSWORD": "****",
"MYSQL_DATABASE": "*****"
}
}
配置中指定協議方式為 stdio, 指令為 uvx 是 python的一個管理包指令, 需要在本地提前下載好. 將通過這個指定下載MCP服務,並啓動,而且這個MCP服務就是Python語言編寫的, env 配置為連接數據庫的參數.最後執行的指令 uvx --from mysql-mcp-server mysql_mcp_server
在cursor中的設置中配置如下:
{
"mcpServers": {
"mysql": {
"type": "stdio",
"command": "uvx",
"args": [
"--from",
"mysql-mcp-server",
"mysql_mcp_server"
],
"env": {
"MYSQL_HOST": "121.36.**.**",
"MYSQL_PORT": "3306",
"MYSQL_USER": "root",
"MYSQL_PASSWORD": "****",
"MYSQL_DATABASE": "*****"
}
}
}
}
配置成功後,這裏會有一個小綠點, 代表工具加載成功. 注意, 在配置前,最好先在本地命令行執行一遍命令uvx --from mysql-mcp-server mysql_mcp_server,把錯誤清理一遍,並且把該下載的包都下載好再進行配置. 因為只要有錯誤日誌, 或者下載包的日誌, 都不符合stdio的格式, 都會報錯.
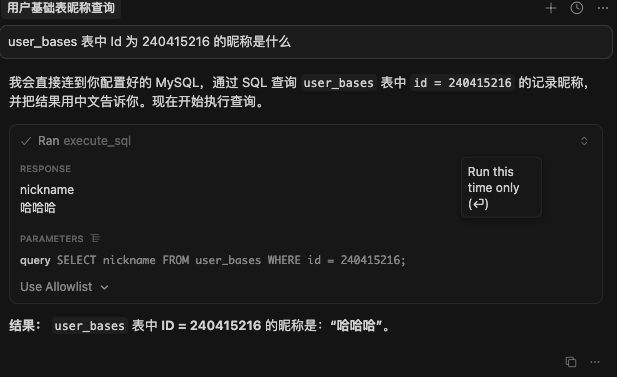
詢問數據庫中數據. cursor將會自動通過mcp查詢數據庫
3. A2A(Agent To Agent)
谷歌,25年4月10日發佈開源的、應用層協議 A2A(Agent-to-Agent 協議),即Agent-to-Agent。其設計目的是使智能體(Agent)間能夠以一種自然的模態進行協作,類似於人與人之間的互動。
在使用的感官上, A2A 和MCP非常相似, 都是定義了Agent如何與外界溝通的規範, 甚至網上有聲音, 有了MCP, A2A 完全沒有必要,
例如, 在一個AgentA 通過 A2A協議, 訪問 另外一個AgentB時, 我們同樣可以將AgentB 打包封裝成一個MCP服務, AgentA 仍然可以通過MCP協議方式訪問AgentB的功能, 這看似是合理的.
但是, A2A協議和MCP是不同的, MCP協議負責的是教會Agent如何感知工具,使用工具, 而A2A需要解決的是兩個智能體之間如何協作, 是一個互相發現和識別的過程,如下圖

MCP 關注的是 Agent 如何使用工具 (Agent-to-Tool/Context)。它讓 Agent 更方便地連接和使用各種外部資源(如 API、數據庫)。
A2A 關注的是 Agent 如何互相合作 (Agent-to-Agent)。它讓不同的 Agent 能夠像一個團隊一樣協同工作
本身程序就是對現實世界的抽象, 雖然功能相似,但不能混為一談(你不能把人當工具使!!!,來自一個工具人的吶喊)
特性對比
| 特性 | A2A | MCP |
|---|---|---|
| 核心目標 | 標準化 Agent 之間的通信和協作 | 標準化 Agent/應用與外部工具/數據源之間的上下文交互 |
| 交互層面 | Agent ↔ Agent (水平集成) | Agent/應用 ↔ 工具/數據源 (垂直集成) |
| 解決問題 | 如何讓不同來源、不同框架的 Agent 互相發現、對話、委託任務、協調工作流? | 如何讓一個 Agent/LLM 標準化、安全、高效地調用外部 API、訪問數據庫、獲取實時數據等“工具”? |
| 通信內容 | 任務指令、狀態更新、協作請求、結果工件、上下文共享、協商 | 傳遞給模型的結構化上下文、工具列表、工具調用請求、工具執行結果 |
| 設想類比 | Agent 之間的內部消息總線或協作框架 | AI 應用連接外部工具的“USB-C”接口 |
| 主要發起者 | Anthropic | |
| 典型場景 | 多 Agent 系統、複雜工作流自動化、跨平台協作 | 單個 Agent 需要調用多種外部工具、增強 LLM 的上下文理解和執行能力 |