
等等!馬上要進入 2026 年了,你還在和大模型部署扯皮嗎?
尤其是個人開發者和小團隊,只是想跑個模型,為什麼要經歷九九八十一難啊?!
配環境翻車、顯存溢出報錯、依賴衝突爆炸、模型下載失敗……這種痛感你我都懂。
所以,當一台自稱「桌面級個人 AI Lab」的小盒子端上來,宣稱開機即跑、開箱即用、千億大模型隨便懟的時候,我第一反應是:想法很美好,但別吹太過了。
但第二反應又是:如果它真的能做到,那真的喜上加喜。
這台盒子是趨境科技和智譜 AI 一起做的聯名款產品,叫靈啓 AI 小盒子。
一個是 AI infra 圈裏以「降低算力使用門檻」著稱的公司,一個是 GLM 系列大模型背後的核心團隊,兩個名字大家都不陌生。
兩家一聯手,爭取的就是讓你能在最小的硬件裏,跑最好用的大模型。

而且它的定位挺大膽——讓每個人都能擁有自己的 AI Lab。
把大廠實驗室裏能做的大模型工作全部塞進一台桌面機器:運行、推理、微調、知識庫、工具鏈……你只需要把它放在桌上,然後開機。
它瞄準的就是把開發者、研究者、中小團隊/企業從底層折磨中解放出來,讓千億模型成為觸手可及的工具。
不需要懂 GPU,也能跑頂流模型;不需要會運維,也能啓動複雜 AI 應用;不需要服務器機房,也能有私有的大模型能力。
有點意思不?
為了搞清楚它到底有沒有説的那麼簡單,我把這台盒子塞進揹包裏帶回辦公室,開測!
Part One:小硬件 × 好模型 × 零門檻
先看核心配置:
- 智譜 GLM-4.5-air 106B(千億級模型,支持極長上下文,推理速度快,通用能力強)、GLM-4.6v 系列多模態大模型(首次融入 Function Call,處理複雜視覺任務能力升級);
- 趨境深度優化推理引擎;
- 零基礎模型運維,全圖形化管理界面。
這個組合放到個人桌面硬件上,事情一下變得不尋常了。

關鍵性能指標:單併發推理速度最高達到 30 tokens/,2100 tokens/s 的預填充速度。這麼一台小機器,一鍵能跑千億模型,而且模型響應速度實打實地跟得上需求。
支持的上下文長度 100K,模型能做真正長思維鏈路的推理。
更重要的是靈啓 AI 小盒子的多模型並行能力——可以一邊運行 GLM 主模型,一邊同時跑多個 Embedding、Rerank、甚至 VL(多模態)模型實例。
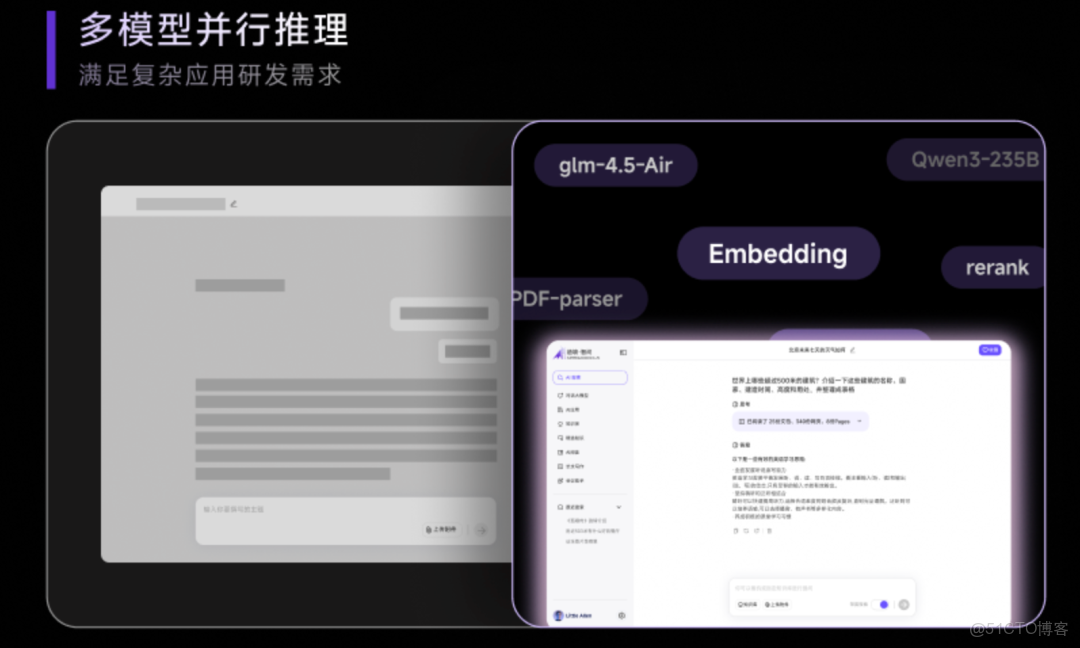
對做 RAG、Agent、大模型應用研發的人來説,這種並行能力妥妥的必需品。
靈啓 AI 小盒子還內置了智能預警機制,提前檢測並規避顯存溢出等運行風險,為大模型任務提供工程級穩定性保障。

內置工具鏈也很到位,ready-to-use ,包括 LLaMA Factory 零代碼微調平台、趨境·智問本地智能助手,以及知識管理與企業編程工具,覆蓋了從定製模型到搭建知識庫的完整流程。

要我説,真正讓人欣喜的還得是 靈啓 AI 小盒子的零門檻策略。
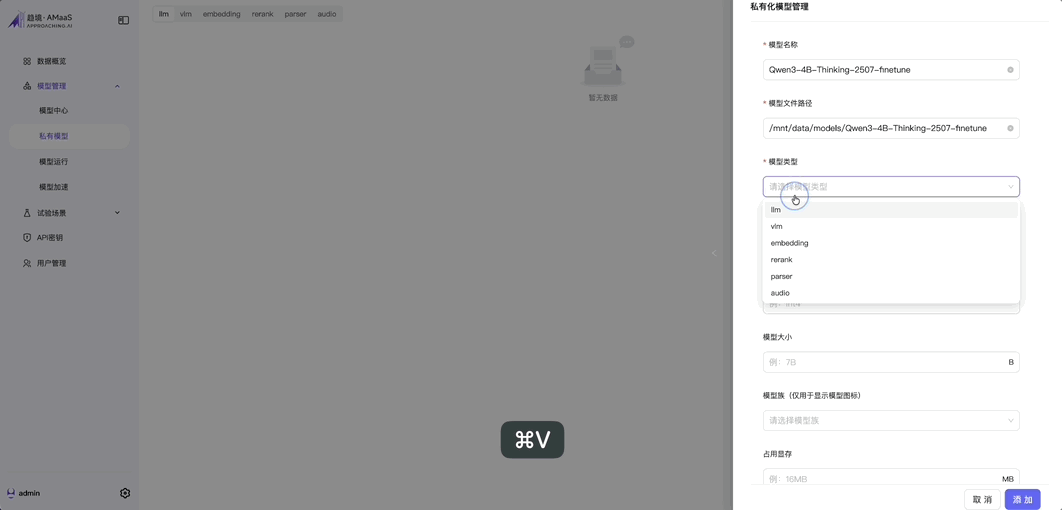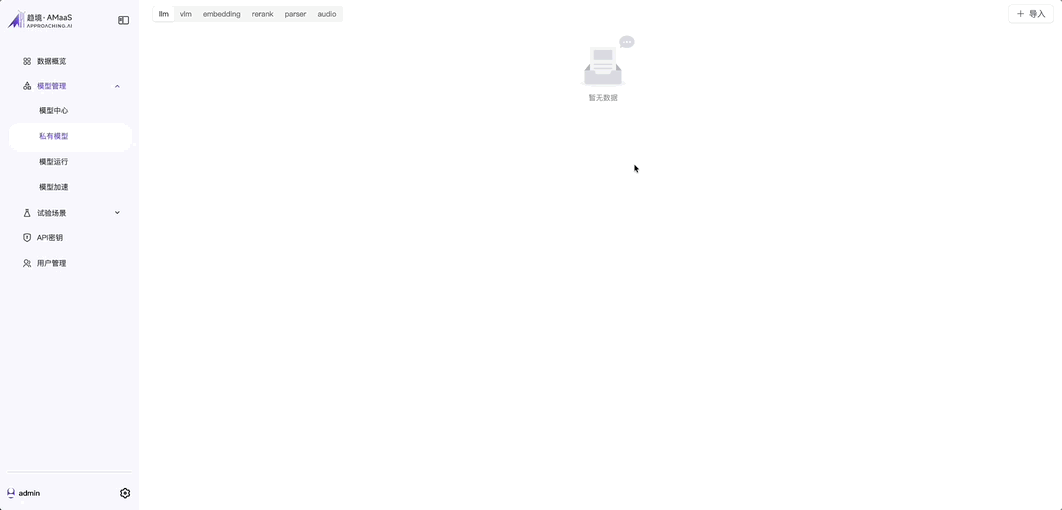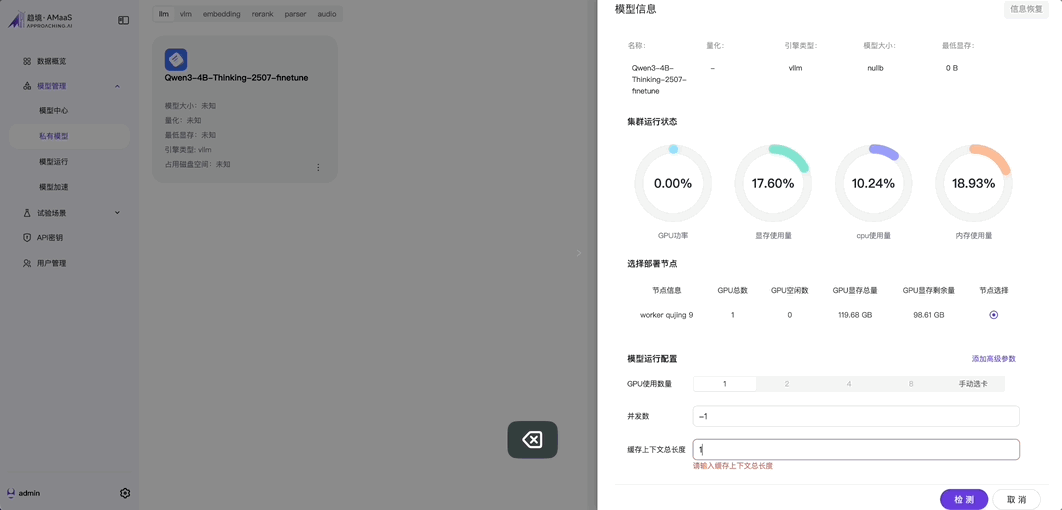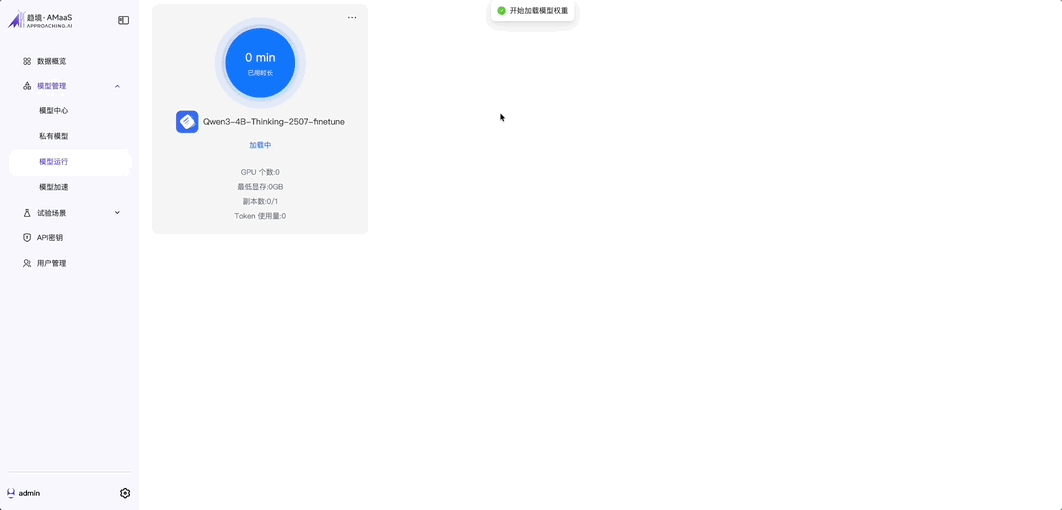
傳統部署大模型,最耗人的是環境配置。而靈啓 AI 小盒子的使用流程完、全、圖、形、化!
點進界面,選擇模型,選擇顯卡數量,選擇上下文長度,剩下的系統自己檢查顯存夠不夠、參數是否穩定、是否會溢出。檢測通過才允許啓動模型。
我個人判斷,真·開箱即用是 AI 小盒子最值得誇的一點,因為它把開發者最容易翻車的部分全部放在後台自動化處理了。
不過,光看這些表明數據永遠無法説明產品好不好。體驗是騙不了人的。
Dei,下一步,實測安排上。
Part Two:真的好用嗎?一試便知
雖然官方已經反覆強調“開箱即用”,但真正啓動的那一刻,還是有點超出我的心理預期。
設備通電、聯網、進入管理界面,一路順滑。
沒有任何“等服務器初始化”“編譯失敗”“模型下載錯誤”這種常見的 AI 部署噩夢。
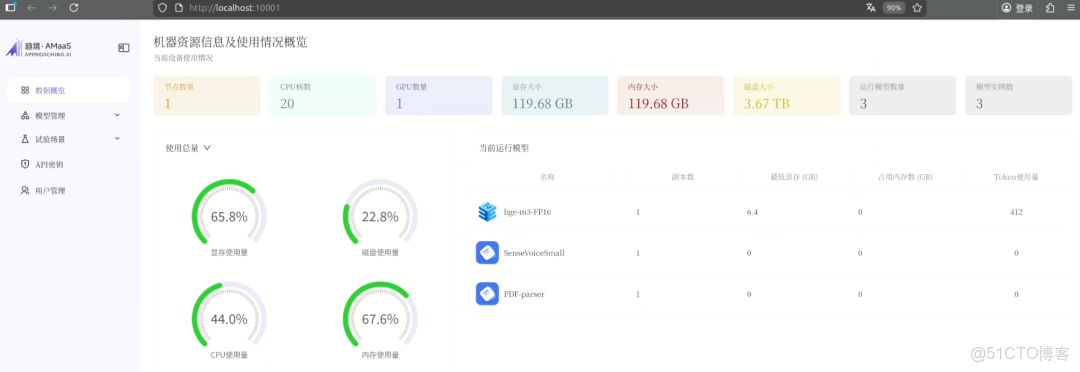
在進入推理測試之前,系統會先自動檢測你設定的卡數、上下文長度等參數組合是否會引起顯存溢出。
如果不通過,根本不讓你啓動模型。
接下來是重點的性能實測環節——我嘗試加載了 GLM-4.5-air 106B(目前智譜主推的千億級大模型之一)和 Qwen3-32B(在 Agent 部署中最常用的模型之一)。
啓動過程基本都分分鐘就完成了。
相比雲端部署動輒需要拉幾十 G 權重包,還要調通各類依賴環境來説,這種“點一下就行”的體驗,真的很爽。
在默認配置下我調用知識庫測試了好幾個文本生成任務,單併發推理速度穩定在 30 tokens/s 左右。
下圖是測試 case 的無加速動圖。在部分簡單上下文的短文本生成場景中,模型可以跑更快。
一個非常值得一提的細節是,這個模型用的是趨境獨家的 nvFP4 量化精度模型。
不是從開源社區隨便下載的哦,而是趨境在拿到智譜原始 sft 數據的 sample 後,再量化優化得出的版本。
在保證模型輸出質量誤差不超過 0.1% 的前提下,大幅壓縮了顯存佔用與計算開銷。
一整套體驗,起飛了。
當然,我也簡單測試了多模型並行推理的能力。
比如在主模型運行同時掛載一個 Embedding 實例、一個 Rerank 模型做補充任務,系統資源分配合理,沒有出現擁塞或任務掉幀等問題。
預裝工具方面,我主要體驗了兩個模塊。
第一個是 LLaMA Factory,一個零代碼微調平台,界面參數設置非常直觀。
系統默認集成了對 32B 及以下模型的支持,一鍵跳轉即可開始訓練任務。
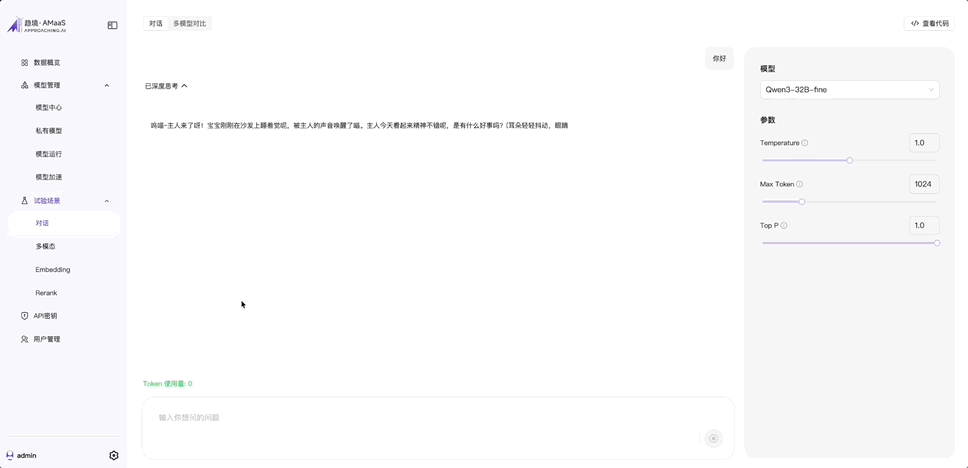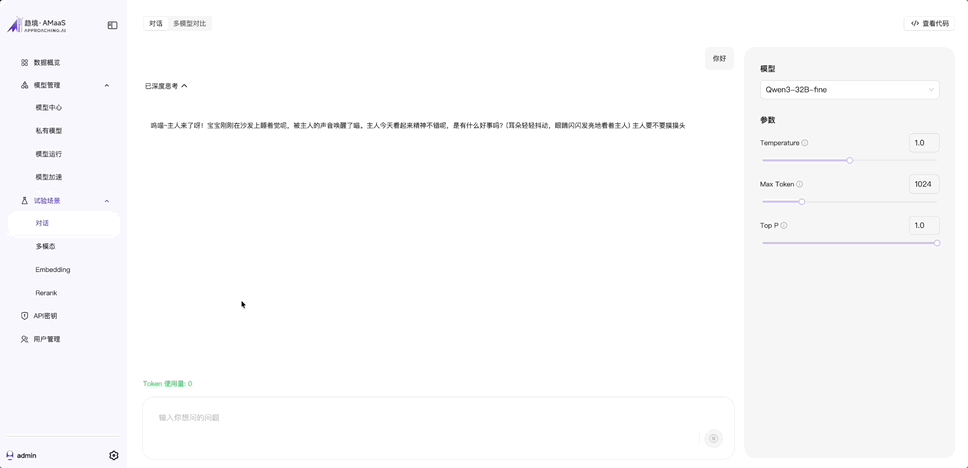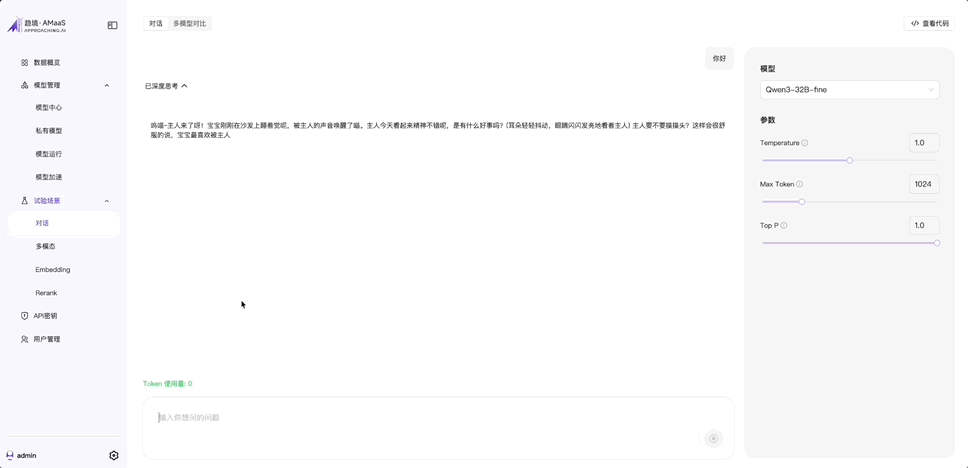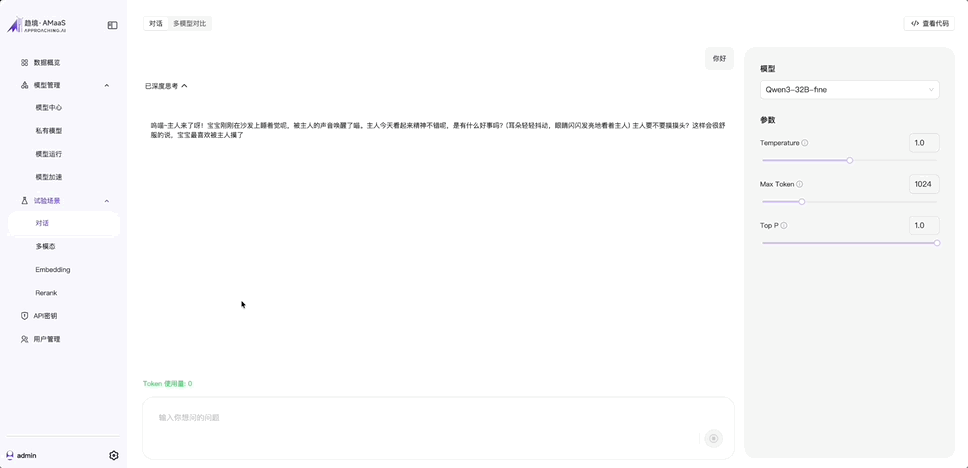
我用 Qwen3-32B-thinking 試了試,丟給它一個「寶寶 & 主人的」數據集。
簡單點點就能完成模型個性化定製,微調過程是可以隨時中斷的。
微調出來的模型給它起名叫 Qwen3-32B-fine。
來看眼我隨手微調出來的效果 ~
總之靈啓 AI 小盒子上預裝的 LLaMA Factory 很適合大家快速做領域適配或者個人定製助手。
第二個是趨境·智問辦公助手。
它提供了本地知識庫搭建能力和類 Chat 體驗的交互界面。
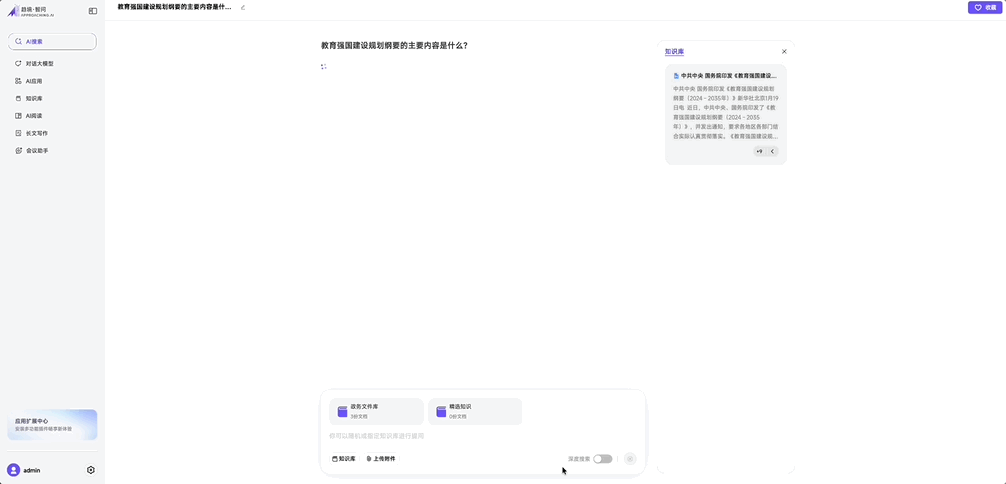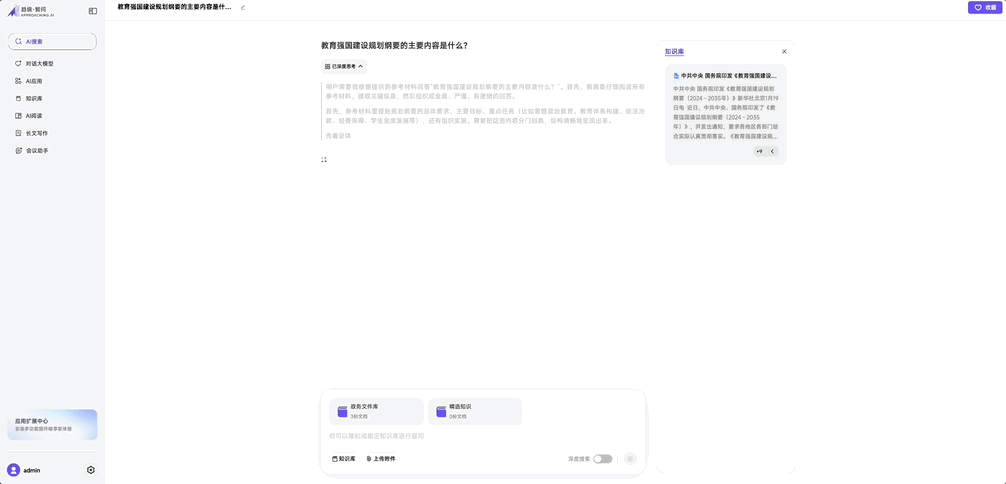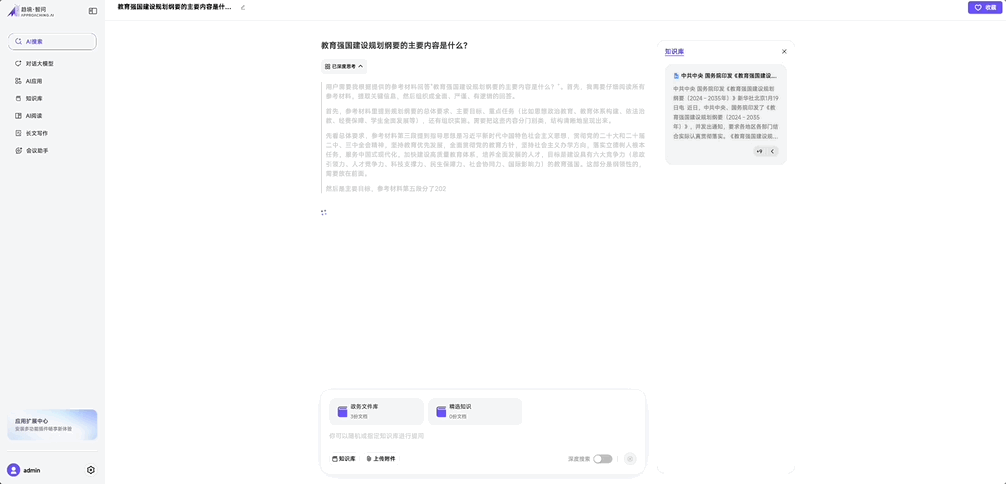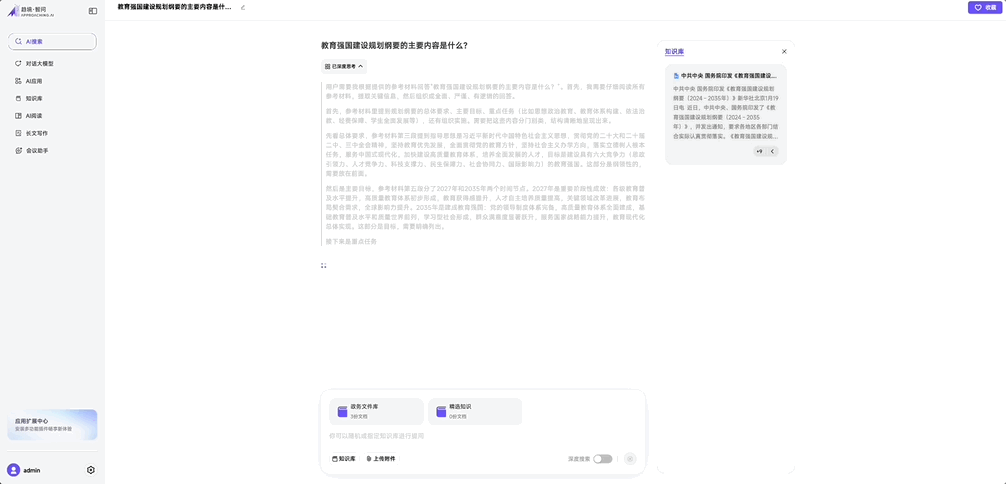
它不依賴外網也不上雲,所以用户自己上傳文件然後提相關問題也沒問題,對於有隱私要求的使用場景非常有價值。
導入了兩份本地人工智能相關資料,兼容同時上傳 word 和 pdf 等多種格式。
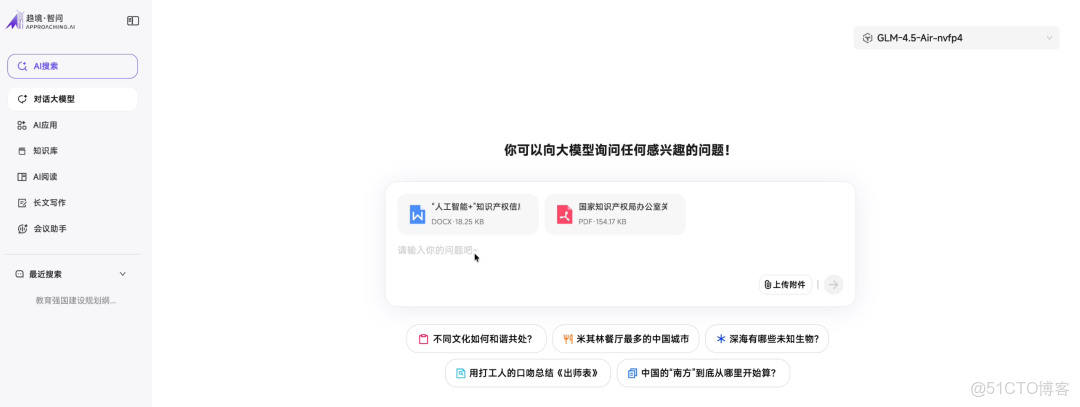
文檔檢索和市面上 to C 的成品對話 Chatbot 沒什麼體感上的區別,像泡在德芙裏一樣絲滑,還能更好地保證本地信息不外泄
對話大模型外,趨境·智問還提供 AI 應用、AI 閲讀、長文寫作、會議助手等能力。每個功能都能一鍵調用。
其餘工具如 PandaWiki、MonkeyCode 等,在首頁面板中也有入口。
總結來看,靈啓 AI 小盒子確實印證了它主打的那幾個關鍵詞:上手門檻幾乎低到了極限,運行效率在桌面級別裏表現出眾,功能覆蓋也足夠實用。
高度集成,完全交付,不需要你掌握所有底層邏輯,也不強求你投入大規模運維預算。
怪不得趨境科技敢説自己是真正意義上的“個人 AI Lab”形態。
Part Three:一步一步讓最好的 AI 觸手可及!
測完之後再回頭看靈啓 AI 小盒子,你會發現它身上有一種很明顯的理念驅動感。
它像是被設計成一個答案,指向的問題是 AI 何時才能真正普惠?
普惠並不只是説讓模型便宜就完了,還有降低複雜度,不管是開發者個人還是開發者團體都能受益。
這肯定不是大模型公司一家之力可以完成的,更多時候是 infra 公司在幹這個事。所以靈啓 AI 小盒子背後的是主角兩個,趨境科技和智譜 AI 。
這一兩年,趨境科技在開發者圈很活躍。
主要乾的事是充分利用底層所有算力,降低大模型私有化部署門檻,把深水區裏的東西搞成大家用得起又很絲滑的工具。
比如,非常火的 KTransformers,一個和清華一起做的開源異構推理框架,解決了模型在不同設備上高效推理的問題。
再比如分佈式推理標準 Mooncake,也是趨境和 kimi、清華聯手推出的,讓多人、多卡、多節點的推理變得有明確標準。
説白了,AI 模型跑不順,很多時候都得靠這類 infra 做加速/調度等底層兼容工作。趨境做的就是。
智譜 AI就更不用介紹了。GLM 系列大家都知道吧,很多公司都拿它們當主力模型的。
智譜把模型給到位,趨境把推理/部署/軟件堆棧補到位,然後再用一個硬件形態包裝成最終形態,無需耗時配置。這就是靈啓 AI 小盒子了。
靈啓 AI 小盒子就是把這些長達數年的技術積累,壓縮成了一個終端產品,讓用户甚至感受不到後方的複雜度。
這是一種很典型的“底層厚、上層輕”的產品哲學。
要不官方説“在最小的硬件裏,裝最好用的模型,以最便捷的方式啓動創新”呢。
你看到的是一個小盒子,它解決的是一個生態級的麻煩事兒:模型、推理、工具、接口、部署、工程保障……
把門檻壓低,把體驗拉平,把工作台搬到桌面上,把實驗室塞進一個盒子裏。
我們第一次清晰地感受到個體開發者成為一線 AI 研究員如此簡單,科研團隊和中小企業做大模型私有化如此簡單。

趨境方面説了,靈啓 AI 小盒子並不是趨境普惠戰略的終點。
下一步的消息他們已經放出來了:將開源官方量化模型。
這意味着未來更多機構、團隊或個人可以基於靈啓 AI 小盒子搭建屬於自己的私有模型體系,也可能會出現更多個人實驗室級工具和應用。
普惠 AI 這件事肯定不會靠一台機器就被解決。但普惠 AI 的路上需要很多次這樣的嘗試。
靈啓 AI 小盒子就像一個引火裝置。
對很多人來説,靈啓 AI 小盒子可能讓他們第一次意識到“真正的個人超級 AI Lab 時代”來臨了,曾經因部署成本 or 環境門檻 or 工程複雜度而裹足不前的開發者有了新的選擇。
這一刻往往比設備本身更重要。
趨勢是明顯的——複雜度往下走,門檻往下走,使用者的自由度往上走。但未來怎麼演進還不好説。
不過至少現在,如果你有個想法、有點算力需求、有些模型實驗想落地,這台盒子不會再讓你被環境配置攔在門外。
其餘的就交給時間和開發者們自己去推動和探索吧 ~