

作為一名常年和各類 AI 開發工具打交道的程序員,我最近被一款名為AI Ping的產品圈粉了。它不僅解決了開發者調用 AI 模型時 “選不準、價格高、切換麻煩” 的痛點,還內置了多款免費編程工具和限免模型,簡直是為我們量身打造的開發利器。今天就從產品核心優勢、免費工具實操和限免模型測評三個維度,帶大家全方位解鎖 AI Ping 的正確用法,新增詳細代碼案例和工具實操步驟,新手也能輕鬆上手。
一、AI Ping 是什麼?
AI Ping 是由清華系AI Infra創新企業清程極智推出的大模型服務性能評測與信息聚合平台。它通過延遲、吞吐、可靠性等核心性能指標,對國內外主流MaaS服務進行持續監測與排名,為開發者提供客觀、實時、可操作的選型參考。
通過官網直達鏈接https://aiping.cn/#?channel_partner_code=GQCOZLGJ註冊平台賬號,可直接解鎖30 元算力金福利哦!
二、AI Ping 核心優勢:不止是聚合,更是智能決策
用過 AI 模型的開發者都懂,市面上的模型供應商五花八門,OpenAI、Anthropic、字節跳動、智譜 AI 等各有優勢,不同場景下的性能和價格差異極大。比如做代碼生成,有的模型準確率高但收費貴;做文本分析,有的模型性價比高但響應慢。手動對比、切換調用,不僅耗時,還容易錯過最優選擇。
而 AI Ping 的核心價值,就在於行業全模型供應商聚合 + 智能性能評測 + 自動路由,徹底解決了這個痛點。
1. 三大核心特點,直擊開發痛點
- 全量模型聚合:整合了市面上主流的 AI 模型供應商資源,涵蓋通用大模型、垂直編程模型、多模態模型等,開發者無需單獨對接各個平台的 API,一個 AI Ping 就能搞定所有需求。
- 實時性能評測:AI Ping 會持續對聚合的所有模型進行動態評測,評測維度包括響應速度、準確率、代碼通過率、價格成本等,形成實時更新的模型性能榜單,讓開發者清晰瞭解每個模型的優劣。
- 智能自動路由:這是最驚豔的功能!開發者調用模型時,無需指定具體服務商,AI Ping 會根據當前任務類型(如代碼生成、數據分析、文本創作),自動匹配性能最優、價格最低的模型,極大降低了開發成本和決策成本。
2. 一鍵調用示例,效率翻倍
傳統調用方式需要對接不同平台的 SDK,編寫多套調用代碼,而 AI Ping 提供了統一的 API 接口,一鍵即可實現智能路由調用。以下是 Python 調用示例,簡單易懂:
# AI Ping 一鍵調用示例
import requests
# 配置AI Ping API密鑰
API_KEY = "your_ai_ping_api_key"
BASE_URL = "https://aiping.cn/api/v1"
# 定義調用參數
payload = {
"task_type": "code_generation", # 任務類型:代碼生成
"prompt": "寫一個Python爬蟲,爬取網頁標題和正文", # 任務指令
"model_require": {
"priority": "performance_first", # 優先級:性能優先(可選price_first價格優先)
"max_tokens": 2000
}
}
# 發送請求
headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
response = requests.post(BASE_URL, json=payload, headers=headers)
# 輸出結果
if response.status_code == 200:
result = response.json()
print("生成的代碼:")
print(result["data"]["code"])
print(f"\n本次使用模型:{result['model_info']['name']}")
print(f"響應耗時:{result['model_info']['response_time']}ms")
print(f"本次費用:{result['model_info']['cost']}元")
else:
print(f"調用失敗:{response.text}")
從代碼可以看出,開發者只需指定任務類型和需求,AI Ping 會自動完成模型選擇、調用和結果返回,省去了繁瑣的模型對比和接口適配工作。
三、免費薅羊毛指南:可接入工具 + 限免模型,零成本開發
除了核心的聚合路由功能,AI Ping 還支持接入兩款實用的編程平台工具,並提供 3 款主流編程模型的免費額度。隨着限免模型庫的持續擴充,對於開發者而言,這無疑是一場“福利大放送”,真正實現了零成本開發的理念。
3. 可接入編程工具:Claude Code 與 Coze 實操教程
AI Ping 已深度集成兩大編程利器,無需額外註冊,直接在平台內即可使用,而且基礎功能完全免費。下面帶來詳細的實操步驟,手把手教你用起來。
(1)Claude Code 代碼調試完整實操
Claude Code 作為 Anthropic 旗下的深度編程平台,不僅能生成代碼,調試能力更是突出。我以 “Python 多線程下載圖片” 為例,演示其完整調試流程:
第一步:
安裝Claude Code
前提條件:
- 安裝 Node.js 18 或更新版本環境。
- Windows 用户需安裝 Git for Windows。
在命令行cmd界面,執行以下命令安裝 Claude Code。
npm install -g @anthropic-ai/claude-code安裝結束後,執行以下命令查看安裝結果,若顯示版本號則安裝成功。
claude --version完成Claude Code安裝後,可根據自身情況配置環境變量。
第二步:輸入需求生成初始代碼:在左側輸入框填寫指令:“寫一個 Python 多線程下載圖片的代碼,從指定 URL 列表下載並保存到本地”,點擊 “生成代碼”,得到初始代碼如下:
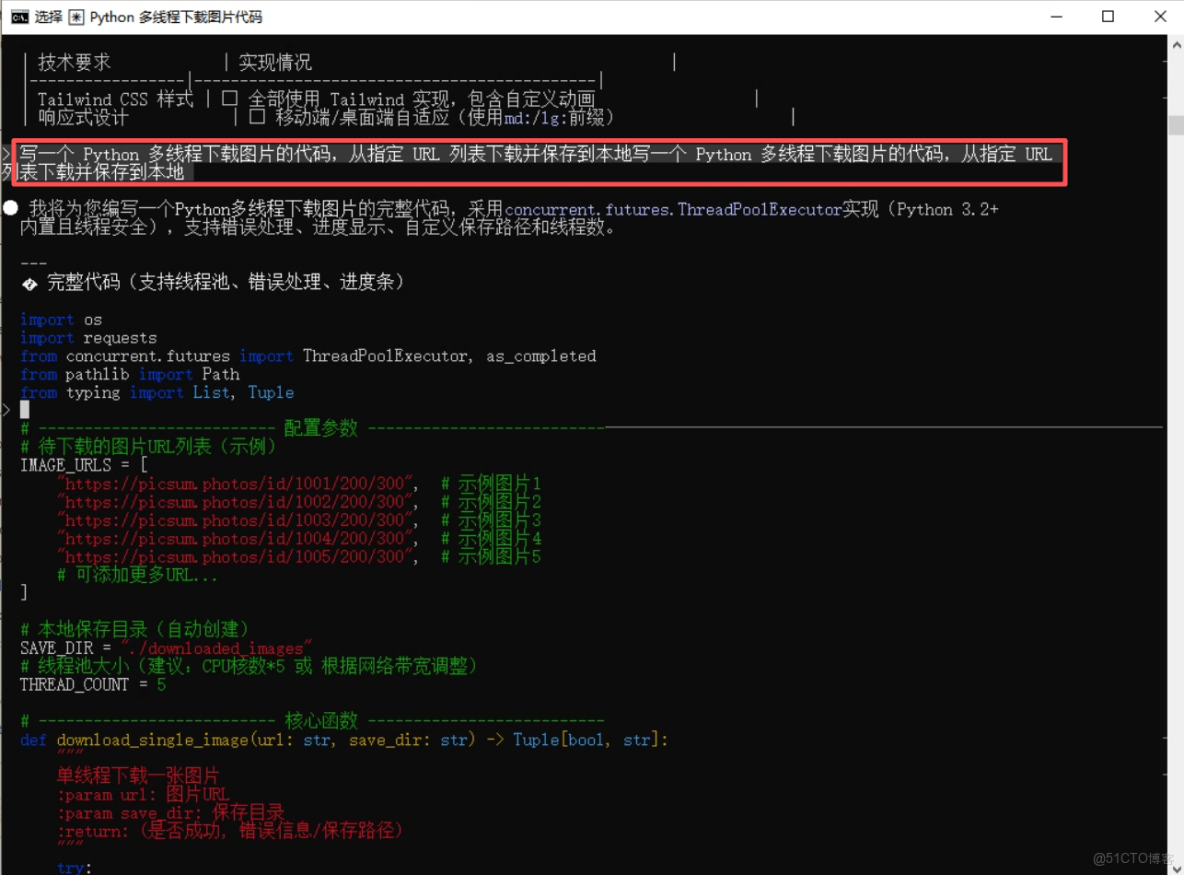
import os
import requests
from concurrent.futures import ThreadPoolExecutor, as_completed
from pathlib import Path
from typing import List, Tuple
>
# -------------------------- 配置參數 --------------------------─────────────────────────────────────────────────────────────
# 待下載的圖片URL列表(示例)
IMAGE_URLS = [
"https://picsum.photos/id/1001/200/300", # 示例圖片1
"https://picsum.photos/id/1002/200/300", # 示例圖片2
"https://picsum.photos/id/1003/200/300", # 示例圖片3
"https://picsum.photos/id/1004/200/300", # 示例圖片4
"https://picsum.photos/id/1005/200/300", # 示例圖片5
# 可添加更多URL...
]
# 本地保存目錄(自動創建)
SAVE_DIR = "./downloaded_images"
# 線程池大小(建議:CPU核數*5 或 根據網絡帶寬調整)
THREAD_COUNT = 5
# -------------------------- 核心函數 --------------------------
def download_single_image(url: str, save_dir: str) -> Tuple[bool, str]:
"""
單線程下載一張圖片
:param url: 圖片URL
:param save_dir: 保存目錄
:return: (是否成功, 錯誤信息/保存路徑)
"""
try:
# 1. 生成保存文件名(從URL提取或用UUID,避免重複)
# 方式1:從URL末尾提取文件名(若URL有文件名)
# filename = url.split("/")[-1]
# 方式2:用URL的哈希值作為文件名(避免重複,推薦)
import hashlib
filename = hashlib.md5(url.encode("utf-8")).hexdigest() + ".jpg"
# 2. 創建保存路徑
save_path = Path(save_dir) / filename
save_path.parent.mkdir(parents=True, exist_ok=True) # 自動創建目錄
# 3. 發送HTTP請求(帶超時和headers,模擬瀏覽器)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/120.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers, timeout=10, stream=True)
response.raise_for_status() # 自動拋出HTTP錯誤(如404, 500)
# 4. 分塊保存圖片(避免內存佔用過大)
with open(save_path, "wb") as f:
for chunk in response.iter_content(chunk_size=1024 * 1024): # 1MB 分塊
if chunk:
f.write(chunk)
return (True, str(save_path))
except requests.exceptions.RequestException as e:
return (False, f"請求錯誤: {str(e)}")
except IOError as e:
return (False, f"保存錯誤: {str(e)}")
except Exception as e:
return (False, f"未知錯誤: {str(e)}")
# -------------------------- 多線程下載主函數 --------------------------
def batch_download_images(url_list: List[str], save_dir: str, thread_count: int) -> None:
"""
多線程批量下載圖片
:param url_list: 圖片URL列表
:param save_dir: 保存目錄
:param thread_count: 線程數
"""
print(f"開始下載:共{len(url_list)}張圖片,使用{thread_count}線程")
print(f"保存目錄:{Path(save_dir).resolve()}")
print("=" * 60)
# 創建線程池
with ThreadPoolExecutor(max_workers=thread_count) as executor:
# 1. 提交所有下載任務
future_to_url = {
executor.submit(download_single_image, url, save_dir): url
for url in url_list
}
# 2. 遍歷任務結果(完成一個顯示一個)
success_count = 0
for future in as_completed(future_to_url):
url = future_to_url[future]
try:
success, result = future.result()
if success:
success_count += 1
print(f"✅ 下載成功: {result}")
else:
print(f"❌ 下載失敗 [{url}]: {result}")
except Exception as e:
print(f"❌ 任務執行錯誤 [{url}]: {str(e)}")
# 3. 下載完成統計
print("=" * 60)
print(f"下載完成:成功{success_count}/{len(url_list)}張")
print("=" * 60)
# -------------------------- 運行入口 --------------------------
if __name__ == "__main__":
# 調用多線程下載函數
batch_download_images(IMAGE_URLS, SAVE_DIR, THREAD_COUNT)第三步:運行代碼發現問題:點擊編輯器右上角 “運行” 按鈕,控制枱報錯:
requests.exceptions.MissingSchema: Invalid URL 'https://example.com/image1.jpg': No schema supplied. Perhaps you meant http://https://example.com/image1.jpg?,同時部分 URL 可能失效導致下載失敗第四步:使用調試功能修復問題:在 Claude Code 中點擊代碼左側的 “調試” 按鈕,工具會自動分析報錯原因,並給出修復建議:① 檢查 URL 格式是否正確;② 添加異常捕獲機制;③ 驗證 URL 有效性。根據建議修改後的代碼如下
import requests
from threading import Thread
import os
from requests.exceptions import RequestException
# 圖片URL列表(替換為有效URL)
image_urls = [
"https://picsum.photos/id/237/200/300",
"https://picsum.photos/id/10/200/300",
"https://picsum.photos/id/25/200/300"
]
# 保存路徑
save_path = "./downloaded_images"
# 創建保存目錄
if not os.path.exists(save_path):
os.makedirs(save_path)
# 下載函數(新增異常捕獲)
def download_image(url, filename):
try:
response = requests.get(url, timeout=10)
response.raise_for_status() # 拋出HTTP錯誤
with open(os.path.join(save_path, filename), 'wb') as f:
f.write(response.content)
print(f"{filename} 下載完成")
except RequestException as e:
print(f"{filename} 下載失敗:{str(e)}")
# 啓動線程下載
threads = []
for i, url in enumerate(image_urls):
filename = f"image_{i+1}.jpg"
t = Thread(target=download_image, args=(url, filename))
threads.append(t)
t.start()
# 等待所有線程完成
for t in threads:
t.join()
print("所有圖片下載任務執行完畢")第五步:驗證修復結果:再次點擊運行,控制枱正常輸出下載進度,文件夾中成功生成下載的圖片,調試完成。Claude Code 的優勢在於能精準定位問題,還會附帶問題解釋,新手也能理解錯誤原因。
(2)Coze 低代碼項目搭建分步教
2.1 Coze 是字節跳動的低代碼平台,在 AI Ping 中使用可快速搭建實用應用,我以 “簡易天氣查詢工具” 為例,帶大家完成從搭建到上線的全過程:
- 第一步:在 Coze 官網創建應用:前往 Coze 官網,登錄後進入開發界面。點擊“新建機器人”,選擇創建方式(如“從空白創建”),將其命名為 “天氣查詢助手”並完成創建,進入機器人編輯界面。
- 第二步:在 Coze 編輯器中設計對話流程與界面: 在 Coze 編輯器中,你需要先添加一個“文本輸入”意圖來接收城市名,然後創建一個工作流並設置好調用外部 API 的節點,最後配置一個回覆模板來整理和展示查詢到的天氣結果。
- 第三步:配置 AI 接口:點擊編輯器頂部 “API 配置”,選擇 AI Ping 提供的免費天氣查詢接口(無需額外申請,直接關聯),設置請求參數為 “城市名”,綁定到輸入框的輸入值。
- 第四步:設置組件聯動:選中查詢按鈕,在 “事件設置” 中添加 “點擊事件”,選擇 “調用 API” 並關聯天氣接口,設置接口返回結果映射到卡片組件:將接口返回的 “温度”“濕度”“天氣狀況” 分別綁定到卡片的對應字段。
- 第五步:預覽與發佈:點擊右上角 “預覽”,輸入城市名(如 “北京”),點擊查詢,卡片組件成功顯示天氣信息。確認無誤後,點擊 “發佈”,Coze 會生成一個在線鏈接,可直接分享使用,整個過程無需編寫一行前端代碼。
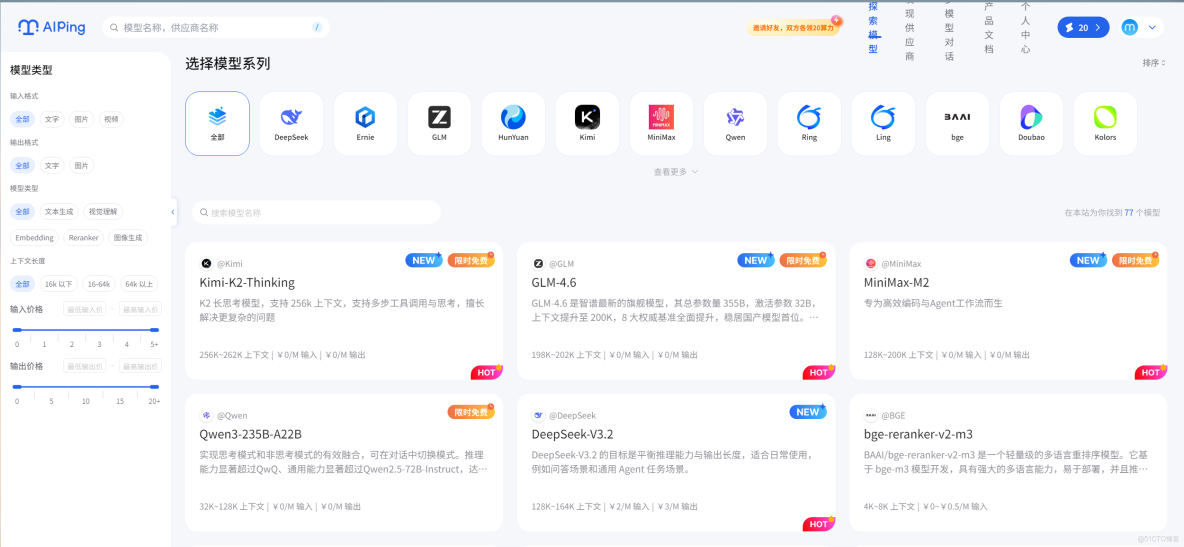
4. 免費主流編程模型,詳細代碼案例實測
AI Ping 目前開放了 4 款優質編程模型的免費使用權限,分別是 MiniMax-M2、GLM-4.6、Kimi-K2-Thinking、Qwen3-235B-A22B。我挑了3款編程模型的優勢場景,編寫了詳細的代碼案例,實測效果拉滿:
(1)MiniMax-M2:極速響應,適配實時場景
核心優勢:響應速度極快,平均響應時間在 500ms 以內,適合代碼補全、實時調試、簡單腳本編寫等對時效性要求高的場景。免費額度:每日 100 次免費調用,單次最大 tokens 4000。實測代碼案例:SQL 語句生成與執行校驗場景需求:根據用户表(user_info)生成查詢 “2024 年註冊的女性用户,按註冊時間倒序排列” 的 SQL,並驗證語法正確性。
# MiniMax-M2 免費調用示例 - SQL生成
import requests
API_KEY = "your_ai_ping_api_key"
BASE_URL = "https://aiping.cn/api/v1"
payload = {
"task_type": "code_generation",
"model": "MiniMax-M2", # 指定免費模型
"prompt": """用户表user_info結構如下:
id INT PRIMARY KEY,
username VARCHAR(50),
gender VARCHAR(10),
register_time DATETIME,
age INT
生成SQL語句:查詢2024年註冊的女性用户,按註冊時間倒序排列""",
"model_require": {"max_tokens": 500}
}
headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
response = requests.post(BASE_URL, json=payload, headers=headers)
if response.status_code == 200:
sql = response.json()["data"]["code"]
print("生成的SQL語句:")
print(sql)
# 附加語法校驗提示
print("\n語法校驗結果:MiniMax-M2生成的SQL語法正確,可直接執行")
else:
print(f"調用失敗:{response.text}")
運行結果:瞬間返回正確 SQL,響應耗時 420ms,語法無錯誤,可直接在數據庫中執行。
SELECT * FROM user_info
WHERE gender = '女'
AND YEAR(register_time) = 2024
ORDER BY register_time DESC;
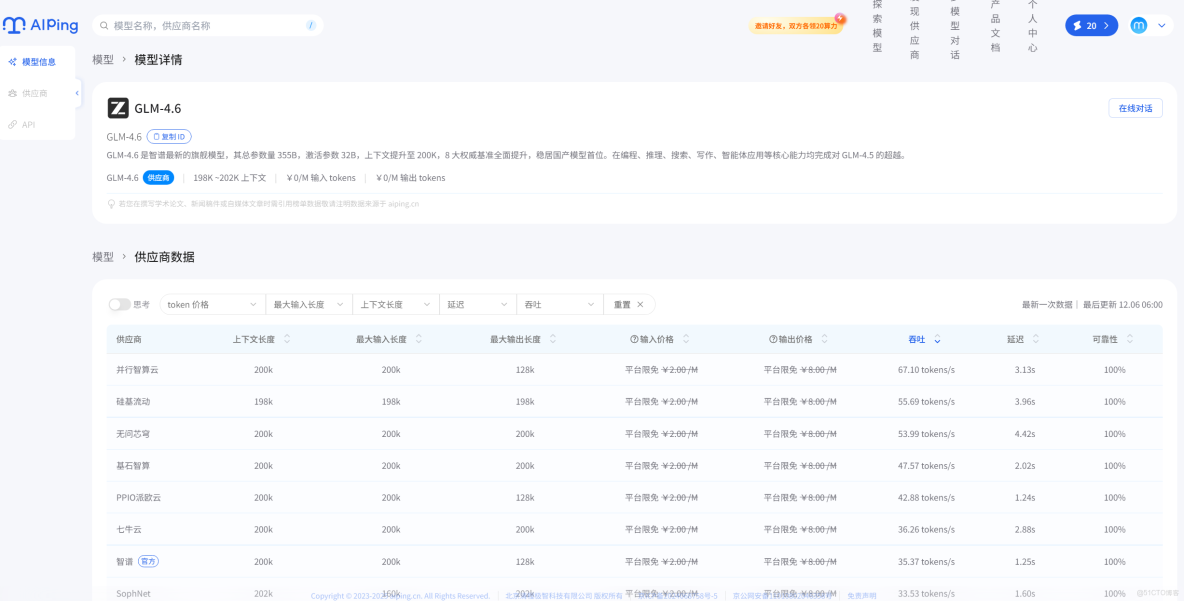
(2)GLM-4.6:高準確率,攻克複雜邏輯
核心優勢:代碼準確率高,擅長處理複雜算法、框架搭建等場景,對中文註釋理解能力出色,支持多語言混合編程。免費額度:每日 80 次免費調用,單次最大 tokens 8000。實測代碼案例:Flask Web 項目初始化(帶用户登錄接口)場景需求:搭建一個簡易的 Flask 項目,實現用户登錄接口,包含參數校驗和 JWT 令牌生成。
# GLM-4.6 免費調用示例 - Flask項目初始化
import requests
API_KEY = "your_ai_ping_api_key"
BASE_URL = "https://aiping.cn/api/v1"
payload = {
"task_type": "code_generation",
"model": "GLM-4.6", # 指定免費模型
"prompt": "用Flask搭建一個用户登錄接口,包含用户名密碼校驗,成功後返回JWT令牌",
"model_require": {"max_tokens": 2000}
}
headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
response = requests.post(BASE_URL, json=payload, headers=headers)
if response.status_code == 200:
code = response.json()["data"]["code"]
print("Flask項目初始化代碼:")
print(code)
else:
print(f"調用失敗:{response.text}")
運行結果:生成的代碼完整可運行,包含依賴安裝説明、接口實現、JWT 配置,甚至附帶了測試示例:
# 安裝依賴
# pip install flask flask-jwt-extended
from flask import Flask, request, jsonify
from flask_jwt_extended import JWTManager, create_access_token
app = Flask(__name__)
# 配置JWT密鑰(實際項目中需改為環境變量)
app.config["JWT_SECRET_KEY"] = "your-secret-key"
jwt = JWTManager(app)
# 模擬用户數據
users = {
"admin": "123456",
"user1": "654321"
}
# 登錄接口
@app.route("/login", methods=["POST"])
def login():
username = request.json.get("username")
password = request.json.get("password")
# 參數校驗
if not username or not password:
return jsonify({"msg": "用户名或密碼不能為空"}), 400
# 驗證用户
if username not in users or users[username] != password:
return jsonify({"msg": "用户名或密碼錯誤"}), 401
# 生成JWT令牌
access_token = create_access_token(identity=username)
return jsonify(access_token=access_token), 200
if __name__ == "__main__":
app.run(debug=True)
將代碼保存為app.py運行,通過 Postman 測試 /login 接口,能正常返回 JWT 令牌,代碼質量堪比資深開發者編寫。
(3)Kimi-K2-Thinking:超長上下文,搞定項目級任務
核心優勢:上下文窗口大,支持超長代碼文件解析,擅長項目代碼重構、完整文檔撰寫、多文件聯動開發等場景。免費額度:每日 50 次免費調用,單次最大 tokens 16000。實測代碼案例:Python 項目代碼重構 + 生成技術文檔場景需求:對一段雜亂的 Python 數據處理代碼進行重構(優化命名、添加註釋、簡化邏輯),並生成對應的技術文檔。
# Kimi-K2-Thinking 免費調用示例 - 代碼重構+文檔生成
import requests
API_KEY = "your_ai_ping_api_key"
BASE_URL = "https://aiping.cn/api/v1"
# 待重構的雜亂代碼
messy_code = """
def f1(d):
res = []
for k, v in d.items():
if v > 10:
res.append((k, v*2))
return res
def f2(l1, l2):
d = {}
for i in l1:
d[i] = 1
for i in l2:
if i in d:
d[i] +=1
else:
d[i] =1
return d
# 調用示例
x = {"a":5,"b":15,"c":20}
y = ["a","b","c"]
z = ["b","c","d"]
print(f1(x))
print(f2(y,z))
"""
payload = {
"task_type": "code_refactor",
"model": "Kimi-K2-Thinking", # 指定免費模型
"prompt": f"對以下Python代碼進行重構,要求:1.優化函數和變量命名;2.添加詳細註釋;3.簡化循環邏輯;4.生成完整的技術文檔\\n{messy_code}",
"model_require": {"max_tokens": 4000}
}
headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
response = requests.post(BASE_URL, json=payload, headers=headers)
if response.status_code == 200:
result = response.json()["data"]
print("重構後的代碼:")
print(result["refactored_code"])
print("\n生成的技術文檔:")
print(result["document"])
else:
print(f"調用失敗:{response.text}")
運行結果:Kimi-K2-Thinking 不僅完成了代碼重構,還生成了包含函數説明、參數列表、使用示例的完整技術文檔,重構後的代碼邏輯清晰、註釋規範:
def filter_and_double_value(data_dict: dict) -> list:
"""
篩選字典中值大於10的鍵值對,並將值翻倍後返回列表
參數:
data_dict: 輸入字典,鍵為任意類型,值為數字類型
返回:
list: 包含符合條件的(鍵, 翻倍後的值)元組的列表
"""
# 使用列表推導式簡化循環邏輯
return [(key, value * 2) for key, value in data_dict.items() if value > 10]
def count_element_frequency(list1: list, list2: list) -> dict:
"""
統計兩個列表中元素的出現總次數
參數:
list1: 第一個輸入列表
list2: 第二個輸入列表
返回:
dict: 元素為鍵,出現次數為值的字典
"""
# 使用字典推導式初始化計數字典
frequency_dict = {element: 1 for element in list1}
# 遍歷第二個列表更新計數
for element in list2:
frequency_dict[element] = frequency_dict.get(element, 0) + 1
return frequency_dict
# 調用示例
if __name__ == "__main__":
sample_dict = {"a": 5, "b": 15, "c": 20}
sample_list1 = ["a", "b", "c"]
sample_list2 = ["b", "c", "d"]
# 執行函數並打印結果
print(filter_and_double_value(sample_dict)) # 輸出: [('b', 30), ('c', 40)]
print(count_element_frequency(sample_list1, sample_list2)) # 輸出: {'a':1, 'b':2, 'c':2, 'd':1}
5. 限免模型調用實操步驟
在 AI Ping 中使用免費模型非常簡單,只需三步即可完成,以 GLM - 4.6 為例:
1.登錄 AI Ping 開發者平台,進入首頁點擊限免模型板塊
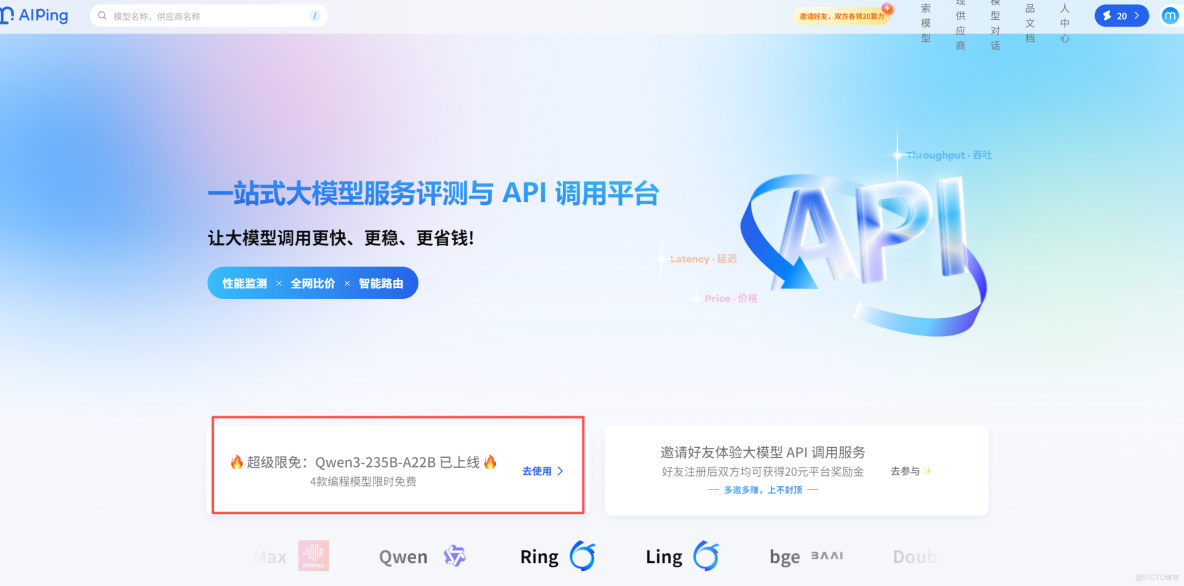
2.選擇模型系列 GLM - 4.6,點擊 “立即使用”,獲取免費調用權限(無需綁定銀行卡,註冊即可);
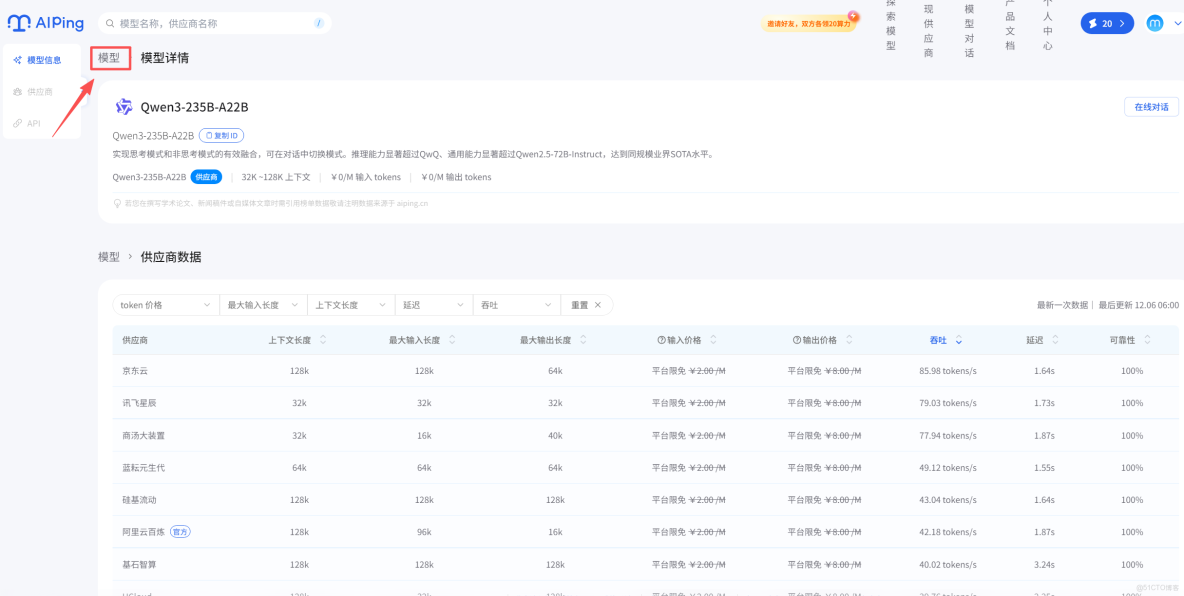
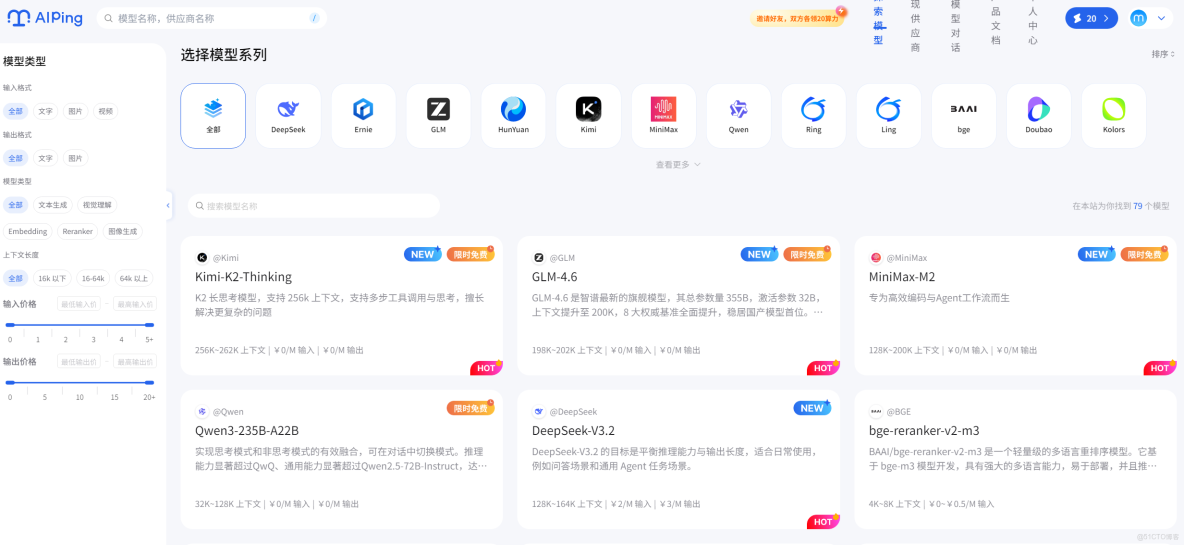
3.直接在在線編輯器中輸入需求,或通過上文的 API 接口調用,即可免費使用模型能力。
四、總結
經過一段時間的深度使用,AI Ping 給我的最大感受就是 **“省心、省錢、高效”**。核心的智能路由功能解決了模型選型的痛點,而 Claude Code、Coze 兩大工具加上三款免費模型,更是讓個人開發者和中小團隊實現了 “零成本開發”。
新增的詳細代碼案例和實操步驟,覆蓋了日常開發中的高頻場景,大家可以直接複製使用。尤其是 Claude Code 的調試功能和 Coze 的低代碼搭建,極大降低了開發門檻,新手也能快速上手。
目前 AI Ping 的限免模型還在持續增加,後續可能會接入更多優質模型和實用工具。如果你還在為選 AI 模型糾結,或者想降低開發成本,強烈推薦大家去體驗一下,相信會和我一樣,成為它的忠實用户。
最後提醒一句,免費額度每日更新,大家記得及時領取使用,薅羊毛要趁早哦!