

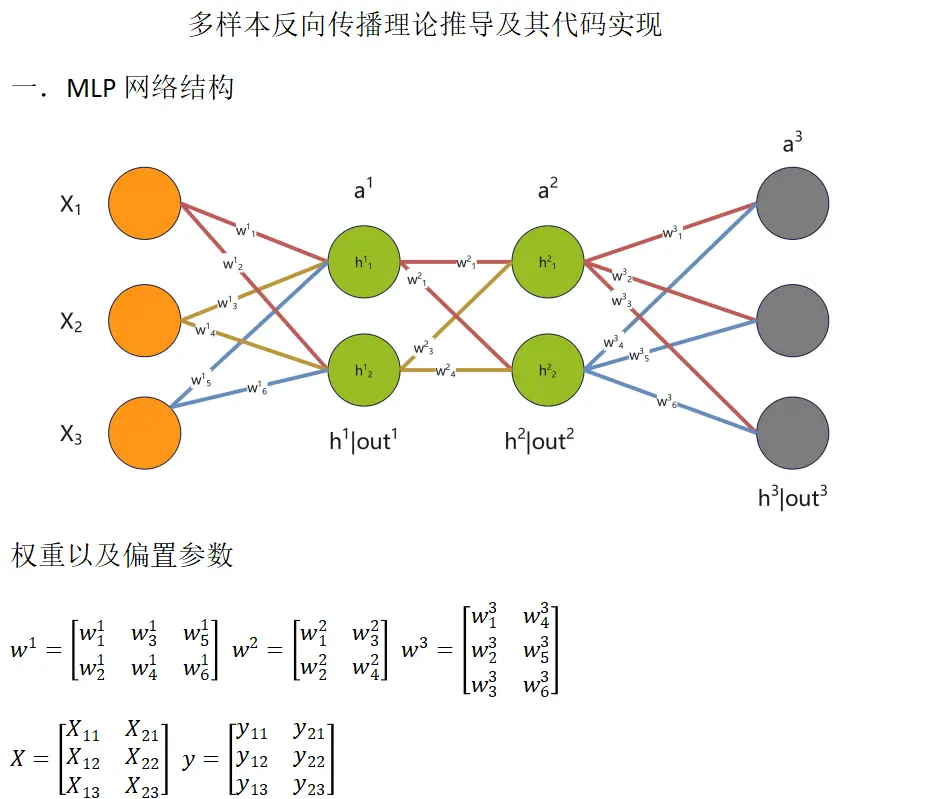
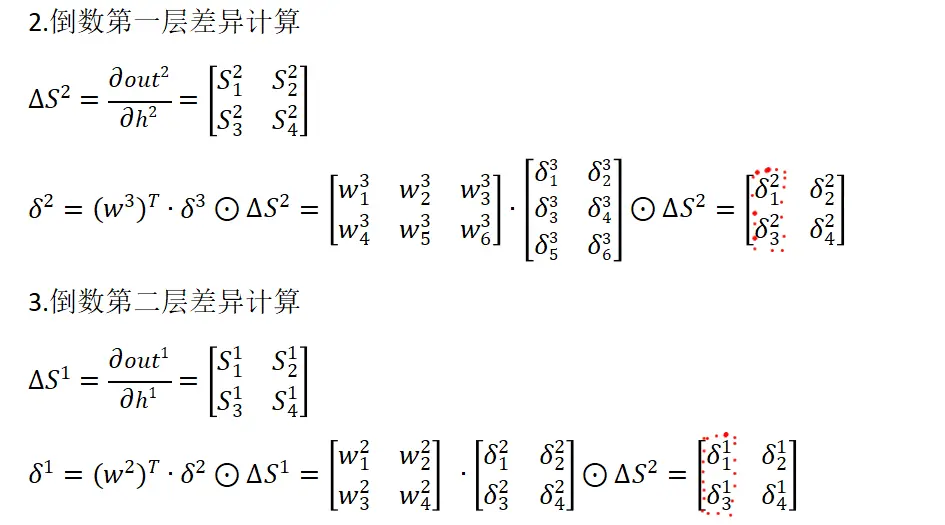
一.多樣本反向傳播矩陣推導



二.MLP代碼實現
# @time : 2025/1/8 10:53
# @author : specier
import numpy as np
import pandas as pd
import datetime
import pickle
class MultipleLayerPerception:
def __init__(self, num_feature, num_hidden_neuron, num_output_neuron, data_size,
activation_function="relu",
decay_step=10, decay_rate=0.5,
batch_size=10, learning_rate=0.1,
epoch=100,
num_hidden_layers=1):
"""
:param num_feature: 特徵數目
:param num_hidden_neuron: 隱藏層神經元個數
:param num_output_neuron: 輸出層神經元個數
:param data_size: 數據總數
:param activation_function: 激活函數
:param decay_step: 衰減步長
:param decay_rate: 衰減係數 0.1或0.5
:param batch_size: 訓練批次大小 20 30
:param learning_rate: 學習率
:param epoch: 迭代次數
:param num_hidden_layers: 隱藏層的層數
"""
self.data = None
self.labels_one_hot = None
self.std_list = []
self.num_feature = num_feature
self.num_hidden_neuron = num_hidden_neuron
self.num_output_neuron = num_output_neuron
self.activation_function = activation_function
self.data_size = data_size
self.decay_step = decay_step
self.decay_rate = decay_rate
self.batch_size = batch_size
self.learning_rate = learning_rate
self.epoch = epoch
self.num_hidden_layers = num_hidden_layers
self.hidden_layers = self.init_hidden_layer()
self.output_layer = self.init_output_layer()
def init_hidden_layer(self):
"""
初始化隱藏層
:return:
"""
hidden_layers = []
for layer_index in range(self.num_hidden_layers):
hidden_layer = None
if layer_index == 0:
# 第一個隱藏層的神經元特殊處理
hidden_layer = Layer(self.num_hidden_neuron, self.num_feature, self.batch_size)
else:
hidden_layer = Layer(self.num_hidden_neuron, self.num_hidden_neuron, self.batch_size)
hidden_layers.append(hidden_layer)
return hidden_layers
def init_output_layer(self):
"""
初始化輸出層
:return:
"""
output_layer = Layer(self.num_output_neuron, self.num_hidden_neuron, self.batch_size)
return output_layer
def train(self, data, labels, is_one_hot=True):
"""
順序訓練神經網絡
:param data:
:param labels:
:param is_one_hot:
:return:
"""
iteration = int(self.data_size / self.batch_size)
self.data_precessing(data, labels, is_one_hot)
loss_list = []
for epoch_index in range(self.epoch):
# 每結束一個epoch將數據索引置為0
init_index = 0
loss_sum = 0
for index in range(iteration):
batch_data = self.data[init_index:self.batch_size + init_index, :].T
batch_labels = self.labels_one_hot[init_index:self.batch_size + init_index, :].T
# 前向傳播
result = self.forward_propagation(batch_data)
loss = self.cross_entropy_loss(result, batch_labels)
loss_sum += loss
# 反向傳播
self.back_propagation(batch_labels)
# 更新數據索引
init_index += self.batch_size
if (epoch_index + 1) % self.decay_step == 0:
self.learning_rate *= self.decay_rate
print(f"第{epoch_index + 1}輪的學習率為:{self.learning_rate}")
avg_loss = loss_sum / iteration
print(f"第{epoch_index + 1}次的損失為:{avg_loss}")
loss_list.append(avg_loss)
return loss_list
def train_shuffle(self, data, labels, is_one_hot=True):
"""
每個epoch將數據打亂,來訓練神經網絡
:param data:
:param labels:
:param is_one_hot:
:return:
"""
iteration = round(self.data_size / self.batch_size)
self.data_precessing(data, labels, is_one_hot)
loss_list = []
for epoch_index in range(self.epoch):
loss_sum = 0
for index in range(iteration):
indices = np.random.choice(np.arange(self.data.shape[0]), self.batch_size, replace=False)
batch_data = self.data[indices].T
batch_labels = self.labels_one_hot[indices].T
# 前向傳播
result = self.forward_propagation(batch_data)
loss = self.cross_entropy_loss(result, batch_labels)
loss_sum += loss
# 反向傳播
self.back_propagation(batch_labels)
# 學習率衰減
# if (epoch_index + 1) % self.decay_step == 0:
# self.learning_rate *= self.decay_rate
# print(f"第{epoch_index + 1}輪的學習率為:{self.learning_rate}")
avg_loss = loss_sum / iteration
print(f"第{epoch_index}次的損失為:{avg_loss}")
loss_list.append(avg_loss)
return loss_list
def forward_propagation(self, data):
"""
矩陣前向傳播
:param data:
:return:
"""
# 隱藏層的傳播
hidden_output = None
for index, layer in enumerate(self.hidden_layers):
inputs = hidden_output if index != 0 else data
hidden_output = np.dot(layer.weights, inputs)
hidden_output += layer.bias
hidden_output_activation = self.activate(hidden_output)
self.hidden_layers[index].inputs = inputs
self.hidden_layers[index].outputs = hidden_output
self.hidden_layers[index].outputs_activation = hidden_output_activation
hidden_output = hidden_output_activation
# 輸出層的傳播
output_layer_outputs = np.dot(self.output_layer.weights, hidden_output)
output_layer_outputs += self.output_layer.bias
output_layer_outputs_activation = self.softmax(output_layer_outputs)
self.output_layer.inputs = hidden_output
self.output_layer.outputs = output_layer_outputs
self.output_layer.outputs_activation = output_layer_outputs_activation
return output_layer_outputs_activation
def back_propagation(self, label):
"""
矩陣反向傳播
:param label:
:return:
"""
# # 計算輸出層差異
outputs_activation = self.output_layer.outputs_activation
# # 均方誤差的導數
# mse_pd = outputs_activation - label
# # sigmoid函數的導數,multiply:將數組對應位置相乘
# sigmoid_pd = np.multiply(outputs_activation, (1 - outputs_activation))
# self.output_layer.deltas = np.multiply(mse_pd, sigmoid_pd)
# ============================================ 修改
# 將交叉熵損失函數與softmax結合求導的結果
self.output_layer.deltas = outputs_activation - label
# 計算各個隱藏層的差異
last_deltas = self.output_layer.deltas
# 隱藏層層數
num_hidden = len(self.hidden_layers)
for layer_index in reversed(range(num_hidden)):
hidden_layer = self.hidden_layers[layer_index]
next_weights = (
self.output_layer.weights
if layer_index == num_hidden - 1
else self.hidden_layers[layer_index + 1].weights
)
# 計算差異
hidden_deltas = np.dot(next_weights.T, last_deltas)
hidden_derivative = self.derivative(hidden_layer.outputs_activation)
hidden_deltas = np.multiply(hidden_deltas, hidden_derivative)
hidden_layer.deltas = hidden_deltas
self.hidden_layers[layer_index] = hidden_layer
last_deltas = hidden_deltas
# 更新輸出層權重參數
output_layer_weights = self.output_layer.weights
output_layer_bias = self.output_layer.bias
output_layer_weights -= self.learning_rate * (1 / self.batch_size) * np.dot(self.output_layer.deltas,
self.output_layer.inputs.T)
output_mean_deltas = np.mean(self.output_layer.deltas, axis=1).reshape(-1, 1)
output_layer_bias -= self.learning_rate * output_mean_deltas
self.output_layer.weights = output_layer_weights
self.output_layer.bias = output_layer_bias
# 更新隱藏層權重參數
for layer_index in range(len(self.hidden_layers) - 1, -1, -1):
hidden_layer = self.hidden_layers[layer_index]
hidden_weights = hidden_layer.weights
hidden_bias = hidden_layer.bias
hidden_weights -= self.learning_rate * (1 / self.batch_size) * np.dot(hidden_layer.deltas,
hidden_layer.inputs.T)
hidden_mean_deltas = np.mean(hidden_layer.deltas, axis=1).reshape(-1, 1)
hidden_bias -= self.learning_rate * hidden_mean_deltas
hidden_layer.bias = hidden_bias
hidden_layer.weights = hidden_weights
self.hidden_layers[layer_index] = hidden_layer
def cross_entropy_loss(self, inputs, labels):
loss = np.multiply(labels, np.log(inputs))
average_loss = np.mean(np.sum(loss, axis=0))
return -average_loss
def sigmoid(self, inputs):
"""
sigmoid激活函數
:param inputs:
:return:
"""
return 1 / (1 + np.exp(-inputs))
def relu(self, inputs):
"""
relu激活函數
:param inputs:
:return:
"""
return np.maximum(0, inputs)
def sigmoid_derivative(self, inputs):
return np.multiply(inputs, 1 - inputs)
def relu_derivative(self, inputs):
return (inputs > 0).astype(np.float32)
def derivative(self, inputs):
"""
激活函數導數
:param inputs:
:return:
"""
derivative_result = None
if self.activation_function == "relu":
derivative_result = self.relu_derivative(inputs)
elif self.activation_function == "sigmoid":
derivative_result = self.sigmoid_derivative(inputs)
return derivative_result
def activate(self, inputs):
"""
激活函數類別
:param inputs:
:return:
"""
activate_result = None
if self.activation_function == "relu":
activate_result = self.relu(inputs)
elif self.activation_function == "sigmoid":
activate_result = self.sigmoid(inputs)
return activate_result
def softmax(self, inputs):
"""
減去最大值表示維持數值穩定性
:param inputs:
:return:
"""
result = np.exp(inputs - np.max(inputs, axis=0))
return result / np.sum(result, axis=0)
def data_precessing(self, data, labels, is_one_hot):
"""
:param data:
:param labels: 是一個二維數組 [[1],[3]]
:param is_one_hot:
:return:
"""
# 製作one-hot標籤 data.shape[0]:60000,num_output_neuron:10
self.labels_one_hot = np.zeros((data.shape[0], self.num_output_neuron))
for index in range(self.labels_one_hot.shape[0]):
self.labels_one_hot[index][labels[index][0]] = 1
self.data = data.astype("float32") / 255
def predict(self, data):
data = data.astype("float32") / 255
remainder = data.shape[0] % self.batch_size
number_iter = data.shape[0] // self.batch_size
iteration = number_iter if remainder == 0 else number_iter + 1
predictions = np.array([], dtype=int)
init_index = 0
for index in range(iteration):
batch_data = data[init_index:self.batch_size + init_index, :].T
# 前向傳播
result = self.forward_propagation(batch_data)
# 沿列方向拼接
predictions = np.hstack((predictions, np.argmax(result, axis=0)))
# 更新數據索引
init_index += self.batch_size
return predictions
class Layer:
def __init__(self, num_neuron, last_num_neuron, batch_size):
# 當前層的輸入
self.inputs = None
# 當前層神經元的數量
self.num_neuron = num_neuron
# 前一層神經元的數量
self.last_num_neuron = last_num_neuron
# 隨機初始化權重項
self.weights = np.random.randn(num_neuron, last_num_neuron) * np.sqrt(1 / last_num_neuron)
# 偏置項
self.bias = np.zeros((num_neuron, 1))
# 沒有經過激活函數的輸出
self.outputs = None
# 經過激活函數的輸出
self.outputs_activation = None
# 每一層的差異
self.deltas = None
def test_model():
# 60000條數據
time_start = datetime.datetime.now()
mnist_train_data = pd.read_csv("./mnist/mnist_train.csv", header=None)
data = mnist_train_data
labels = data.iloc[:, 0].values.reshape(-1, 1)
data = data.iloc[:, 1:].values
mlp = MultipleLayerPerception(784, 256, 10, data.shape[0], batch_size=64, num_hidden_layers=1, epoch=300)
# mlp.train(data, labels, is_one_hot=True)
mlp.train_shuffle(data, labels, is_one_hot=True)
time_end = datetime.datetime.now()
print(f"\n訓練完成,耗時{(time_end - time_start).total_seconds() / 60}分鐘")
with open("mlp_plus_shuffle_relu.pkl", "wb") as file:
pickle.dump(mlp, file)
print("----------------")
def test_load_model():
# mlp_plus_one.pkl(順序訓練) :98.18%
# mlp_plus_shuffle_relu.pkl :98.31%
with open("mlp_plus_shuffle_relu.pkl", "rb") as file:
loaded_mlp = pickle.load(file)
test_data = pd.read_csv("./mnist/mnist_test.csv", header=None)
test_labels = test_data.iloc[:, 0].values
pred_data = test_data.iloc[:, 1:].values
pred = loaded_mlp.predict(pred_data).flatten()
accuracy = np.sum(test_labels == pred) / pred_data.shape[0]
print("------------------")
print(f"預測準確率為:{accuracy * 100}%")