










🏆🏆🏆教程全知識點簡介:微服務保護、服務異步通信、消息中間件部署、分佈式事務、搜索引擎、緩存、數據同步以及相關組件的安裝配置等技術要點。在微服務保護方面,介紹了 Sentinel 的基礎知識,包括雪崩問題、超時處理、艙壁模式、斷路器機制,以及不同服務保護技術的對比;講解了流量控制(簇點鏈路、流控模式、熱點參數限流)、隔離與降級(FeignClient 整合 Sentinel、線程隔離)、授權規則(自定義異常結果)及規則持久化(規則管理模式與 pull 模式),並演示了基於 Nacos 的規則持久化改造。服務異步通信部分探討了消息可靠性(生產者消息確認、Return 回調、ConfirmCallback)、死信交換機、TTL 隊列等高級應用。RabbitMQ 部署指南涵蓋了單機部署、DelayExchange 插件安裝、集羣部署、鏡像模式等內容。分佈式事務部分介紹了 CAP 定理、BASE 理論、常見解決方案,Seata 的基礎與部署(TC 服務部署、Nacos 配置、數據庫表創建)、多種事務模式(XA 模式及優缺點、四種模式對比)和高可用架構。分佈式搜索引擎章節講解了 Elasticsearch 的原理(ELK 技術棧、倒排索引)、索引庫與文檔操作、RestAPI 與 RestClient 的使用、排序與高亮、酒店搜索案例(分頁、競價排名、ad標記、算分函數)、自動補全、數據同步(同步調用、監聽 binlog)、集羣搭建與腦裂問題、分片存儲測試,以及單點 ES、Kibana、IK 分詞器安裝。緩存部分介紹了 Redis 持久化(RDB 與 AOF 對比)、單機安裝 Redis、Redis 集羣、多級緩存(JVM 進程緩存、Caffeine)、請求參數處理、Tomcat 查詢、HTTP 工具與 CJSON 工具類、Redis 緩存查詢。數據同步與網關部分包括 Canal 安裝(開啓 MySQL 主從、設置權限)、OpenResty 安裝(開發庫、目錄結構、環境變量配置)及運行流程。

📚📚👉👉👉本站這篇博客: https://segmentfault.com/a/1190000047239876 中查看
📚📚👉👉👉本站這篇博客: https://segmentfault.com/a/1190000047239876 中查看
<!-- end:bj1 -->
✨ 本教程項目亮點
🧠 知識體系完整:覆蓋從基礎原理、核心方法到高階應用的全流程內容
💻 全技術鏈覆蓋:完整前後端技術棧,涵蓋開發必備技能
🚀 從零到實戰:適合 0 基礎入門到提升,循序漸進掌握核心能力
📚 豐富文檔與代碼示例:涵蓋多種場景,可運行、可複用
🛠 工作與學習雙參考:不僅適合系統化學習,更可作為日常開發中的查閲手冊
🧩 模塊化知識結構:按知識點分章節,便於快速定位和複習
📈 長期可用的技術積累:不止一次學習,而是能伴隨工作與項目長期參考
🎯🎯🎯全教程總章節

🚀🚀🚀本篇主要內容
3.文檔操作
3.1.新增文檔
語法:
POST /索引庫名/_doc/文檔id
{
"字段1": "值1",
"字段2": "值2",
"字段3": {
"子屬性1": "值3",
"子屬性2": "值4"
},
// ...
}示例:
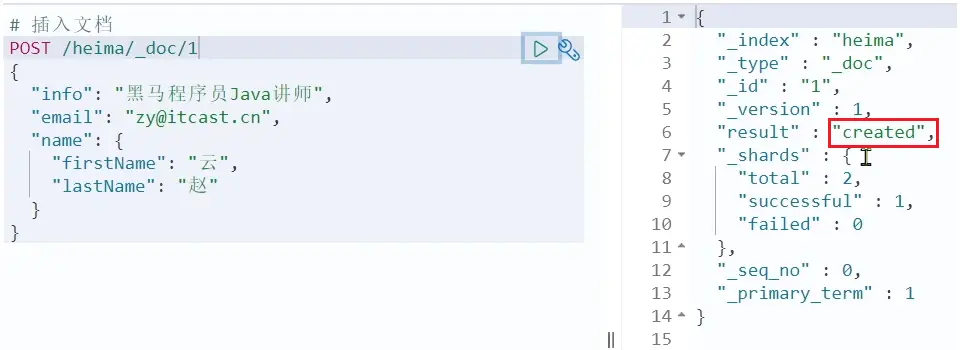
POST /heima/_doc/1
{
"info": "黑馬程序員Java講師",
"email": "zy@itcast.cn",
"name": {
"firstName": "雲",
"lastName": "趙"
}
}響應:
3.2.查詢文檔
根據rest風格,新增是post,查詢應該是get,不過查詢一般都需要條件,這裏 把文檔id帶上。
語法:
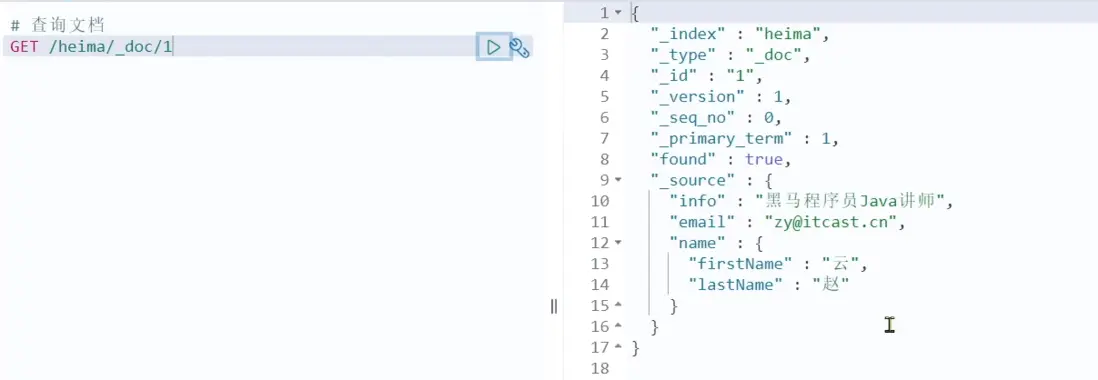
GET /{索引庫名稱}/_doc/{id}通過kibana查看數據:
GET /heima/_doc/1查看結果:
3.3.刪除文檔
刪除使用DELETE請求,同樣,需要根據id進行刪除:
語法:
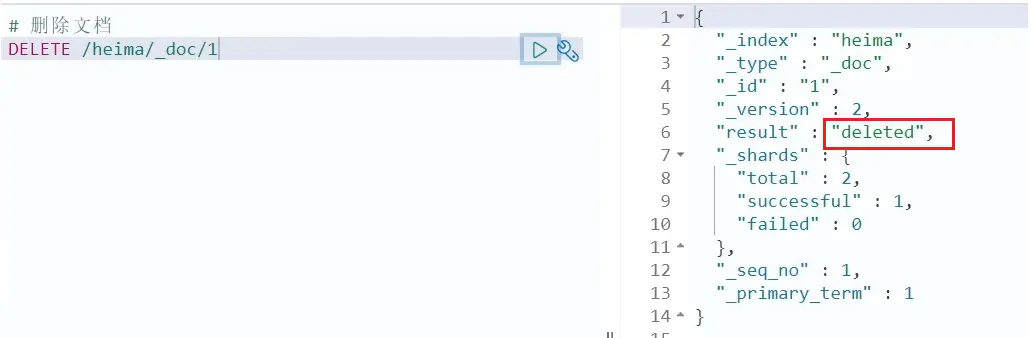
DELETE /{索引庫名}/_doc/id值示例:
# 根據id刪除數據
DELETE /heima/_doc/1結果:
3.4.修改文檔
修改有兩種方式:
- 全量修改:直接覆蓋原來的文檔
- 增量修改:修改文檔中的部分字段
3.4.1.全量修改
全量修改是覆蓋原來的文檔,其本質是:
- 根據指定的id刪除文檔
- 新增一個相同id的文檔
注意:如果根據id刪除時,id不存在,第二步的新增也會執行,也就從修改變成了新增操作了。
語法:
PUT /{索引庫名}/_doc/文檔id
{
"字段1": "值1",
"字段2": "值2",
// ... 略
}
示例:
PUT /heima/_doc/1
{
"info": "黑馬程序員高級Java講師",
"email": "zy@itcast.cn",
"name": {
"firstName": "雲",
"lastName": "趙"
}
}3.4.2.增量修改
增量修改是隻修改指定id匹配的文檔中的部分字段。
語法:
POST /{索引庫名}/_update/文檔id
{
"doc": {
"字段名": "新的值",
}
}示例:
POST /heima/_update/1
{
"doc": {
"email": "ZhaoYun@itcast.cn"
}
}3.5.總結
文檔操作有哪些?
- 創建文檔:POST /{索引庫名}/_doc/文檔id { json文檔 }
- 查詢文檔:GET /{索引庫名}/_doc/文檔id
- 刪除文檔:DELETE /{索引庫名}/_doc/文檔id
-
修改文檔:
- 全量修改:PUT /{索引庫名}/_doc/文檔id { json文檔 }
- 增量修改:POST /{索引庫名}/_update/文檔id { "doc": {字段}}
4.RestAPI
ES官方提供了各種不同語言的客户端,用來操作ES。這些客户端的本質就是組裝DSL語句,通過http請求發送給ES。官方文檔地址:https://www.elastic.co/guide/en/elasticsearch/client/index.html
其中的Java Rest Client又包括兩種:
- Java Low Level Rest Client
- Java High Level Rest Client

學習的是Java HighLevel Rest Client客户端API
4.0.導入Demo工程
4.0.1.導入數據
首先導入課前資料提供的數據庫數據:

數據結構如下:
CREATE TABLE `tb_hotel` (
`id` bigint(20) NOT NULL COMMENT '酒店id',
`name` varchar(255) NOT NULL COMMENT '酒店名稱;例:7天酒店',
`address` varchar(255) NOT NULL COMMENT '酒店地址;例:航頭路',
`price` int(10) NOT NULL COMMENT '酒店價格;例:329',
`score` int(2) NOT NULL COMMENT '酒店評分;例:45,就是4.5分',
`brand` varchar(32) NOT NULL COMMENT '酒店品牌;例:如家',
`city` varchar(32) NOT NULL COMMENT '所在城市;例:上海',
`star_name` varchar(16) DEFAULT NULL COMMENT '酒店星級,從低到高分別是:1星到5星,1鑽到5鑽',
`business` varchar(255) DEFAULT NULL COMMENT '商圈;例:虹橋',
`latitude` varchar(32) NOT NULL COMMENT '緯度;例:31.2497',
`longitude` varchar(32) NOT NULL COMMENT '經度;例:120.3925',
`pic` varchar(255) DEFAULT NULL COMMENT '酒店圖片;例:/img/1.jpg',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;4.0.2.導入項目
然後導入課前資料提供的項目:

項目結構如圖:
4.0.3.mapping映射分析
創建索引庫,最關鍵的是mapping映射,而mapping映射要考慮的信息包括:
- 字段名
- 字段數據類型
- 是否參與搜索
- 是否需要分詞
- 如果分詞,分詞器是什麼?
其中:
- 字段名、字段數據類型,可以參考數據表結構的名稱和類型
- 是否參與搜索要分析業務來判斷,例如圖片地址,就無需參與搜索
- 是否分詞呢要看內容,內容如果是一個整體就無需分詞,反之則要分詞
- 分詞器, 可以統一使用ik_max_word
來看下酒店數據的索引庫結構:
PUT /hotel
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "all"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword",
"copy_to": "all"
},
"starName":{
"type": "keyword"
},
"business":{
"type": "keyword"
},
"location":{
"type": "geo_point"
},
"pic":{
"type": "keyword",
"index": false
},
"all":{
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}幾個特殊字段説明:
- location:地理座標,裏面包含精度、緯度
- all:一個組合字段,其目的是將多字段的值 利用copy_to合併,提供給用户搜索
地理座標説明:

copy_to説明:

4.0.4.初始化RestClient
在elasticsearch提供的API中,與elasticsearch一切交互都封裝在一個名為RestHighLevelClient的類中,必須先完成這個對象的初始化,建立與elasticsearch的連接。
分為三步:
1)引入es的RestHighLevelClient依賴:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-h
🚀✨ (未完待續)項目系列下一章
📚下一篇 將進入更精彩的環節!
🔔 記得收藏 & 關注,第一時間獲取更新!
🍅 一起見證整個系列逐步成型的全過程。
