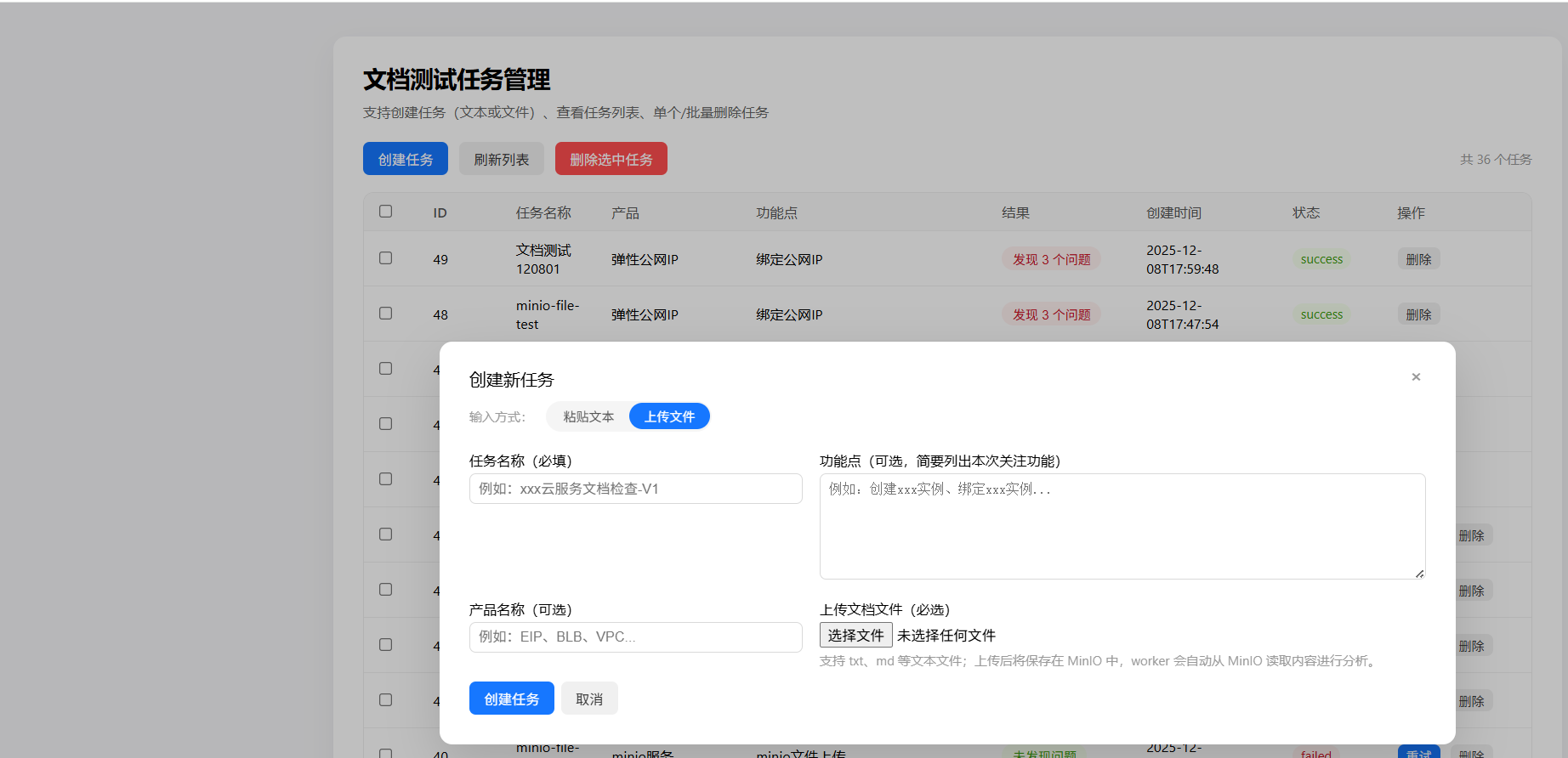
一、技術選型與功能設計
使用minio服務,進行文件的中轉與存儲。用户提交文件到doc-llm-controller,控制面將文件轉存到minio中,關聯此次任務id。然後doc-llm-worker輪詢redis發現有需要執行的任務,拿到id後,根據id從minio拿取文件,然後將文件解析成結構化信息,再提交到大模型,進行文檔測試。
那麼此部分功能流程圖大致如下:
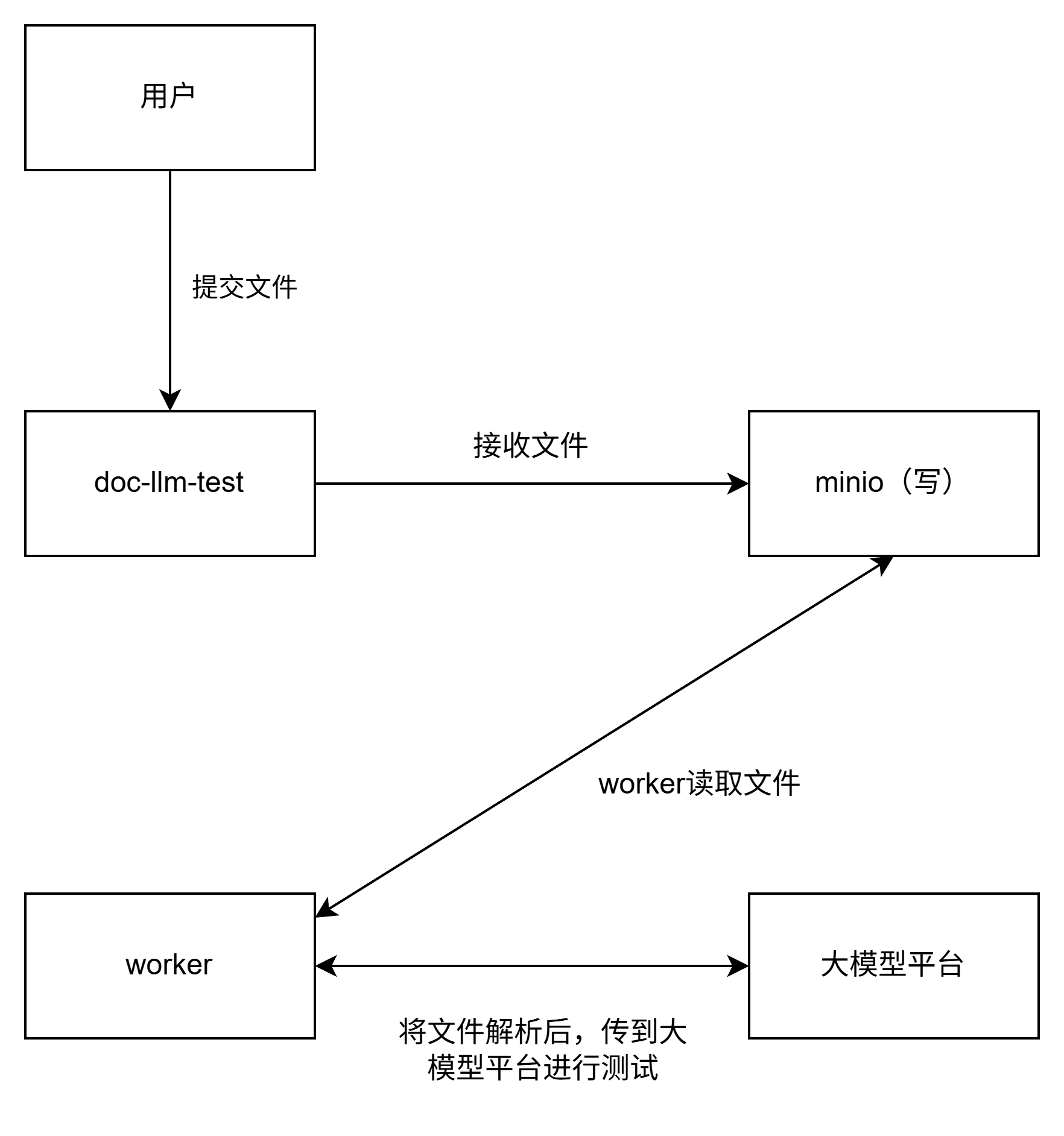
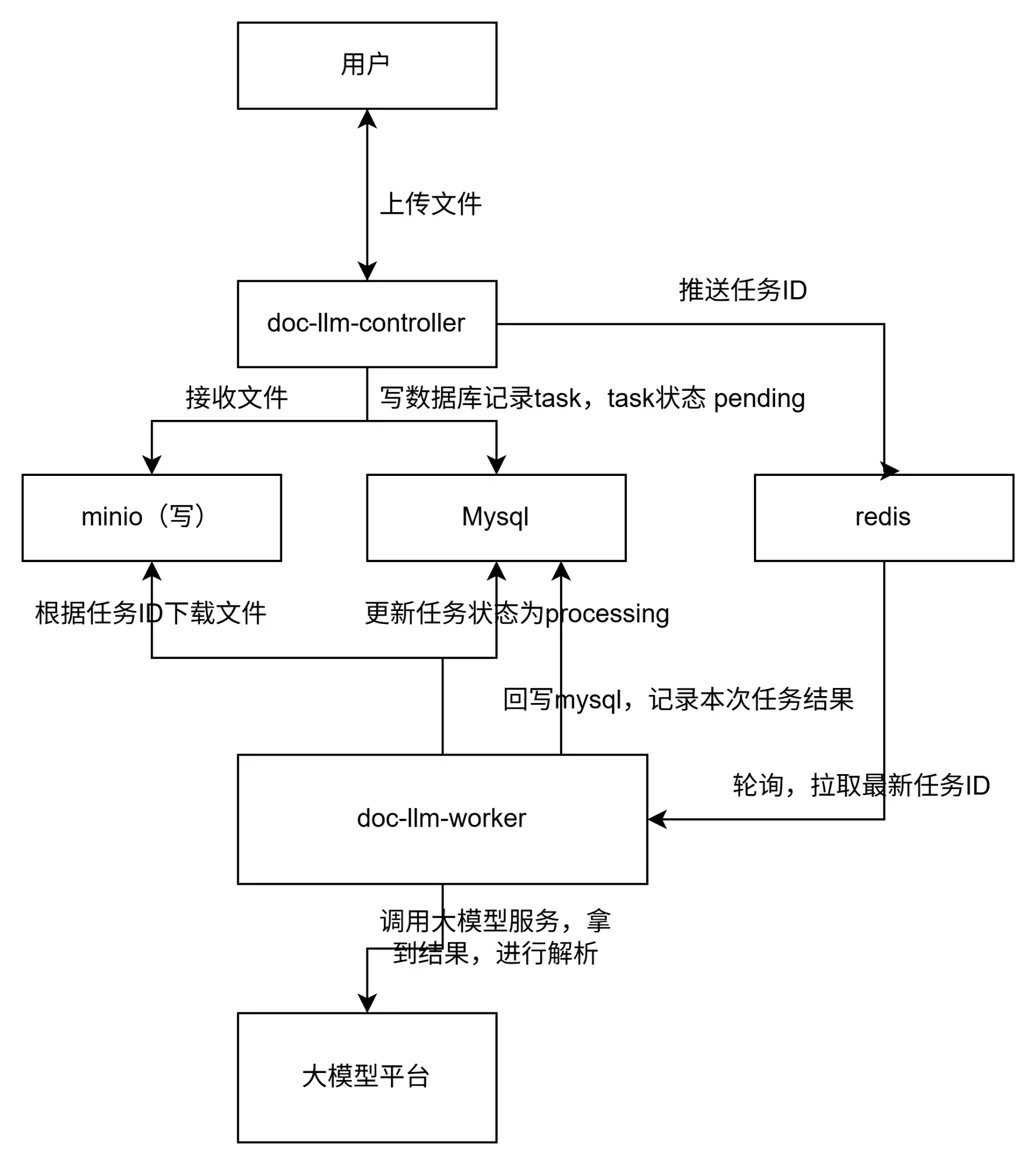
相對應的,在整體業務流程中補充文件存取步驟,最後如下:
二、minio配置與使用
minio安裝部署:我們使用docker鏡像來部署minio服務,暴露9000端口提供給我們自己服務使用:
docker run -d --name doc-llm-minio -p 9000:9000 -p 9001:9001 --restart=always -e MINIO_ROOT_USER=root -e MINIO_ROOT_PASSWORD=password -v /home/workspace/minio:/data minio/minio:latest server /data --console-address ":9001"
通過python來調用minio服務:
# minio下載 pip install minio
from minio import Minio from minio.error import S3Error import io # 配置minio client = Minio( "localhost:9000", access_key="root", secret_key="xiao1234", secure=False, ) bucket_name = "doc-llm-bucket" try: if not client.bucket_exists(bucket_name): client.make_bucket(bucket_name) else: print(f"Bucket '{bucket_name}' already exists.") except S3Error as e: print(f"Error occurred: {e}") # 通過python上傳文件到minio def upload_file(local_file_path, object_name): try: client.fput_object(bucket_name, object_name, local_file_path) print(f"'{local_file_path}' is successfully uploaded as '{object_name}' to bucket '{bucket_name}'.") except S3Error as e: print(f"Error occurred while uploading: {e}") # 文件下載 def download_file(object_name, local_file_path): try: client.fget_object(bucket_name, object_name, local_file_path) print(f"'{object_name}' is successfully downloaded to '{local_file_path}'.") except S3Error as e: print(f"Error occurred while downloading: {e}") # 列出所有文件 def list_files(): try: objects = client.list_objects(bucket_name) print(f"Objects in bucket '{bucket_name}':") for obj in objects: print(f"- {obj.object_name} (size: {obj.size} bytes)") except S3Error as e: print(f"Error occurred while listing objects: {e}") # 刪除指定文件 def delete_file(object_name): try: client.remove_object(bucket_name, object_name) print(f"'{object_name}' is successfully deleted from bucket '{bucket_name}'.") except S3Error as e: print(f"Error occurred while deleting: {e}")
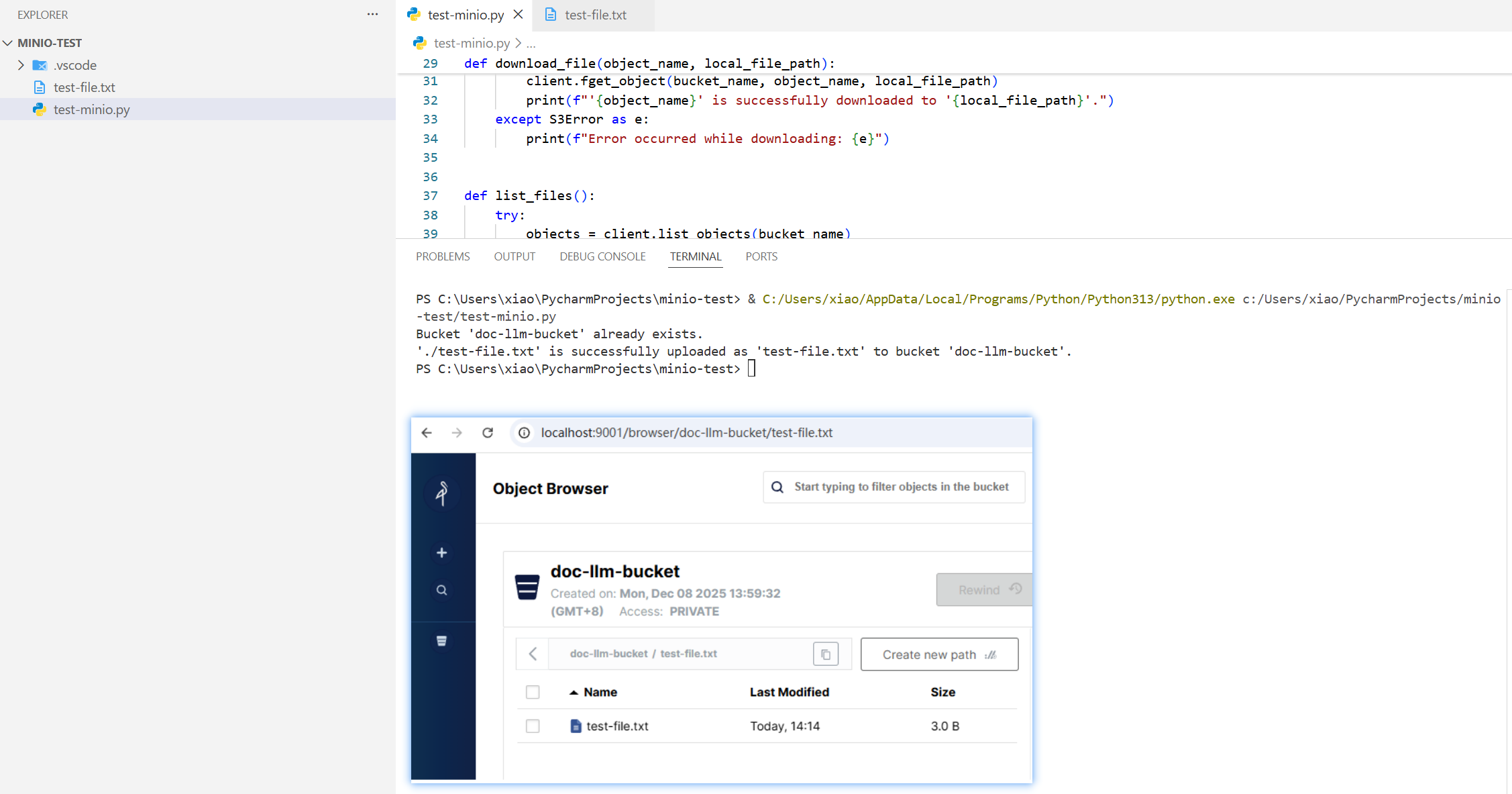
測試效果如下:
三、控制面doc-llm-controller服務適配
總體思路:
接口層接收到帶文件的創建任務請求,先新增一條任務數據到mysql,其中doc字段為__PENDING_FILE__。然後拿到任務id後,調用推送文件服務將文件關聯任務id一起推送到minio,結束後更新任務信息doc字段為:f"minio://{MINIO_BUCKET}/{object_name}"。
至此控制面業務結束。
services層:
新增file_service.py,提供minio服務的調用
# 代碼樣例 def _ensure_bucket(): """確保 bucket 存在""" if not _minio_client.bucket_exists(MINIO_BUCKET): _minio_client.make_bucket(MINIO_BUCKET) def save_task_file(task_id: int, file_obj: FileStorage) -> str: """ 把用户上傳的文件存到 MinIO,文件名格式:{task_id}_{orig_filename} 返回存入數據庫的 doc 字段值,例如:minio://doc-llm-bucket/123_xxx.docx ... doc_path = f"minio://{MINIO_BUCKET}/{object_name}" return doc_path
給doc_check_service, task_service 增加更新doc方法
# doc_check_service def update_task_doc(task_id: int, doc: str) -> None: """更新任務的 doc 字段""" task = task_service.get_task_by_id(task_id) if not task: raise TaskNotFoundError(f"任務 {task_id} 不存在") task_service.update_task_doc(task_id, doc) # task_service def update_task_doc(task_id: int, doc: str) -> None: """更新任務的 doc 字段""" with get_session() as session: task = session.scalar( select(TaskDocLLM).where(TaskDocLLM.task_id == task_id) ) if not task: raise ValueError(f"任務 {task_id} 不存在") task.doc = doc
更新接口函數,兼容傳文本信息、文本文件兩種方式:
@bp.route("/tasks/", methods=["POST"]) def create_doc_task(): # 判斷是不是文件上傳 if request.content_type and "multipart/form-data" in request.content_type: return _create_task_with_file() # 默認走老的 JSON 邏輯 return _create_task_with_json() def _create_task_with_json(): ... task_id = doc_check_service.submit_doc_task(task_name, doc, product, feature) ... def _create_task_with_file(): .... try: # 1. 先寫一條任務,doc 用佔位符,保證非空 placeholder_doc = "__PENDING_FILE__" task_id = doc_check_service.submit_doc_task( task_name=task_name, doc=placeholder_doc, product=product, feature=feature, ) doc_path = file_service.save_task_file(task_id, file_obj) # 3. 回寫 doc 字段 doc_check_service.update_task_doc(task_id, doc_path) ...
用postman測試下接口效果,大致是OK的:
接口請求:
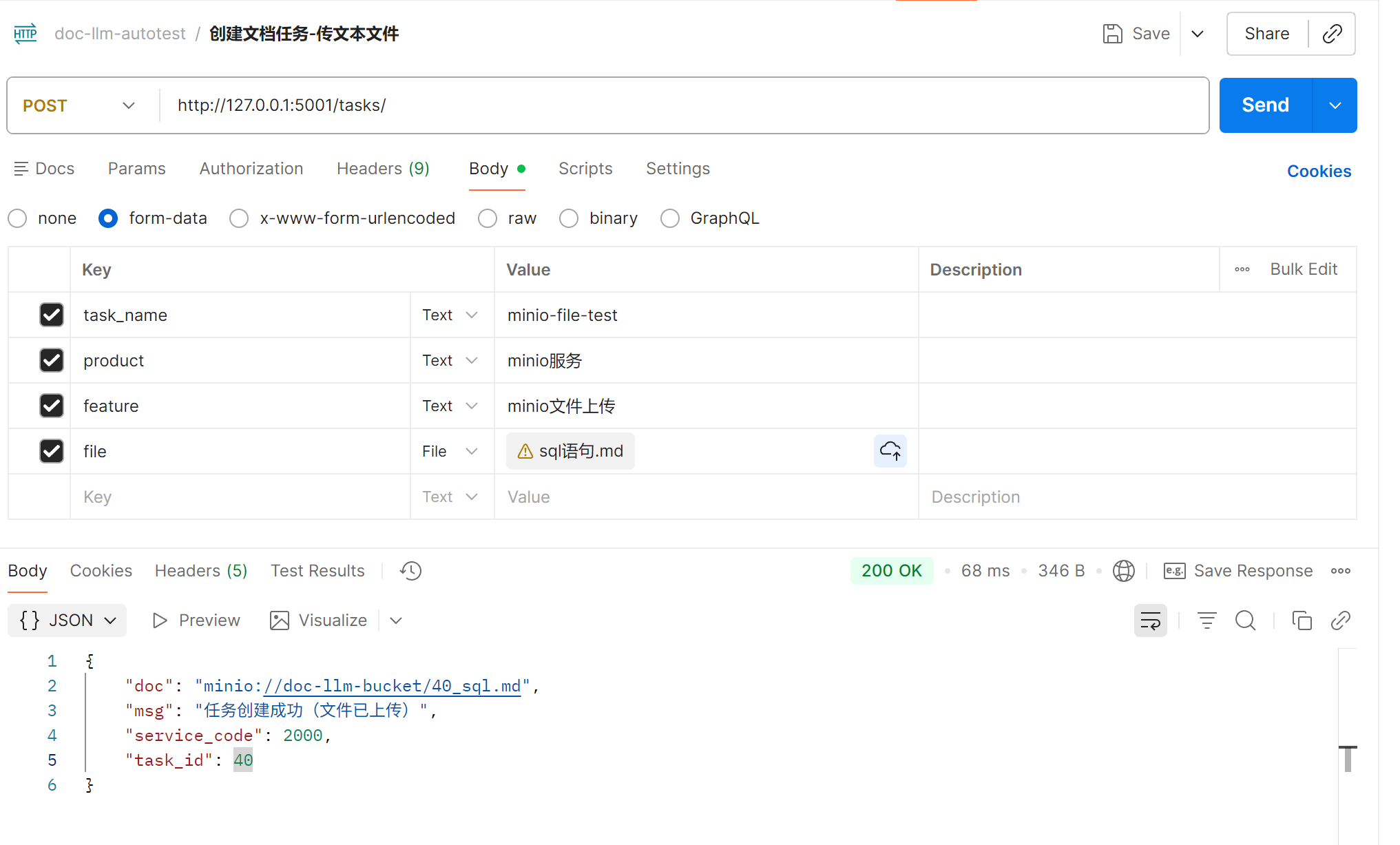
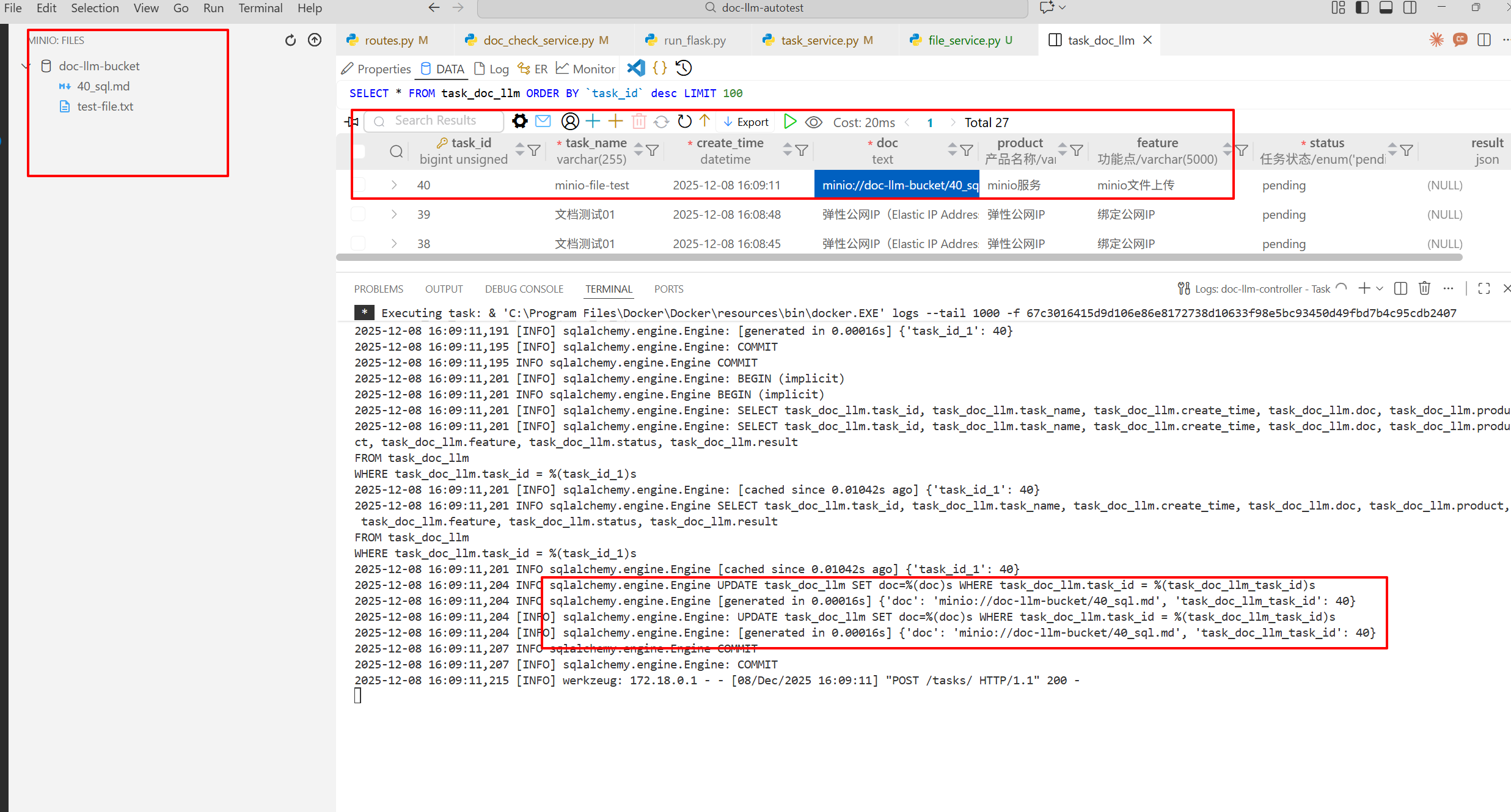
flask這邊日誌、數據庫、minio表現都OK,數據一致性有保障:
四、數據面doc-llm-worker服務適配
當前數據流的流轉:從時間先後順序,最先會寫入task到mysql,此時doc字段是pending字樣,然後寫入task_id到redis,再就是把文件傳給minio,最後更新mysql.doc為minio的文件路徑。
doc-llm-worker初始邏輯是:讀redis隊列找到需要執行的任務,讀mysql拿到doc文本信息,調用大模型進行測試。因此數據面doc-llm-worker要做一些適配:
1.新增文件任務的下載
從minio下載文件,在file_service層補充函數:
def download_file(bucket: str, object_name: str) -> bytes: """ 從 MinIO 下載文件並返回 bytes 內容。 調用方式: content = download_file("doc-llm-bucket", "15_readme.txt") text = content.decode("utf-8") """ try: response = _minio_client.get_object(bucket, object_name) data = response.read() return data except S3Error as e: raise RuntimeError(f"Download from minio failed: {e}") from e
2.將文件解析
其中如果doc是純文本的話走老邏輯;是minio格式的話,走文件下載,然後解析成文本;是pending的話,等待知道文件上傳ok
新增doc_loader.py
# app/worker/doc_loader.py import logging from typing import Tuple from app.services import file_service PENDING_MARK = "__PENDING_FILE__" def _is_minio_path(doc: str) -> bool: """ 判斷 doc 是否為 MinIO 路徑: - /bucket/object_name - minio://bucket/object_name """ ... def _parse_minio_path(doc: str) -> Tuple[str, str]: """解析 doc 字段為 (bucket, object_name)""" ... def load_doc_for_task(task) -> str: """ 根據任務對象,返回真正要給 LLM 的 doc 文本(str) 1. doc == "__PENDING_FILE__" -> 拋 DocPendingError 2. doc 是 MinIO 路徑 (/bucket/obj) -> 從 MinIO 下載並 decode 3. 其他 -> 當作普通文本直接返回 """ doc = (task.doc or "").strip() if not doc: raise DocPathError(f"task {task.id} doc is empty") if doc == PENDING_MARK: raise DocPendingError(f"task {task.id} doc is still pending file upload") if _is_minio_path(doc): bucket, object_name = _parse_minio_path(doc) logging.info( f"task {task.id} doc is minio path, bucket={bucket}, object={object_name}" ) content_bytes = file_service.download_file(bucket, object_name) return content_bytes.decode("utf-8", errors="replace") return doc
3.worker的處理
讀redis隊列,根據任務id找到這條task,但當文件任務doc字段還是"__PENDING_FILE__"時,做阻塞等待,直到doc字段更新為"minio://{bucket}/{object_name}",從minio下載文件再處理,適配doc_llm_test_worker
新增阻塞等待函數
def wait_for_doc_ready(task_id: int): """ 當 doc == "__PENDING_FILE__" 時,等待 doc 字段被控制面更新。 超過最大重試次數仍未更新則拋出異常。 """ PENDING_RETRY_INTERVAL = 2 PENDING_RETRY_MAX = 5 for i in range(PENDING_RETRY_MAX): time.sleep(PENDING_RETRY_INTERVAL) task = task_service.get_task_by_id(task_id) if not task: raise RuntimeError(f"task {task_id} disappeared during pending wait") doc = (task.doc or "").strip() if doc != doc_loader.PENDING_MARK: logging.info(f"task {task_id} doc is ready after {i+1} retries: {doc}") return task logging.info(f"task {task_id} doc still pending (retry {i+1}/{PENDING_RETRY_MAX})") raise RuntimeError(f"task {task_id} doc still pending after max retries")
適配文檔處理函數process_task
def process_task(task_id: int): """處理文檔檢查任務""" logging.info(f"start process task {task_id}") ... try: try: doc_text = doc_loader.load_doc_for_task(task) except doc_loader.DocPendingError as e: logging.info(f"task {task_id} doc pending, waiting...") try: task = wait_for_doc_ready(task_id) doc_text = doc_loader.load_doc_for_task(task) except Exception as e2: logging.error(f"task {task_id} pending wait failed: {e2}") task_service.mark_task_failed(task_id, str(e2)) return except doc_loader.DocPathError as e: logging.error(f"task {task_id} invalid doc path: {e}") task_service.mark_task_failed(task_id, str(e)) return
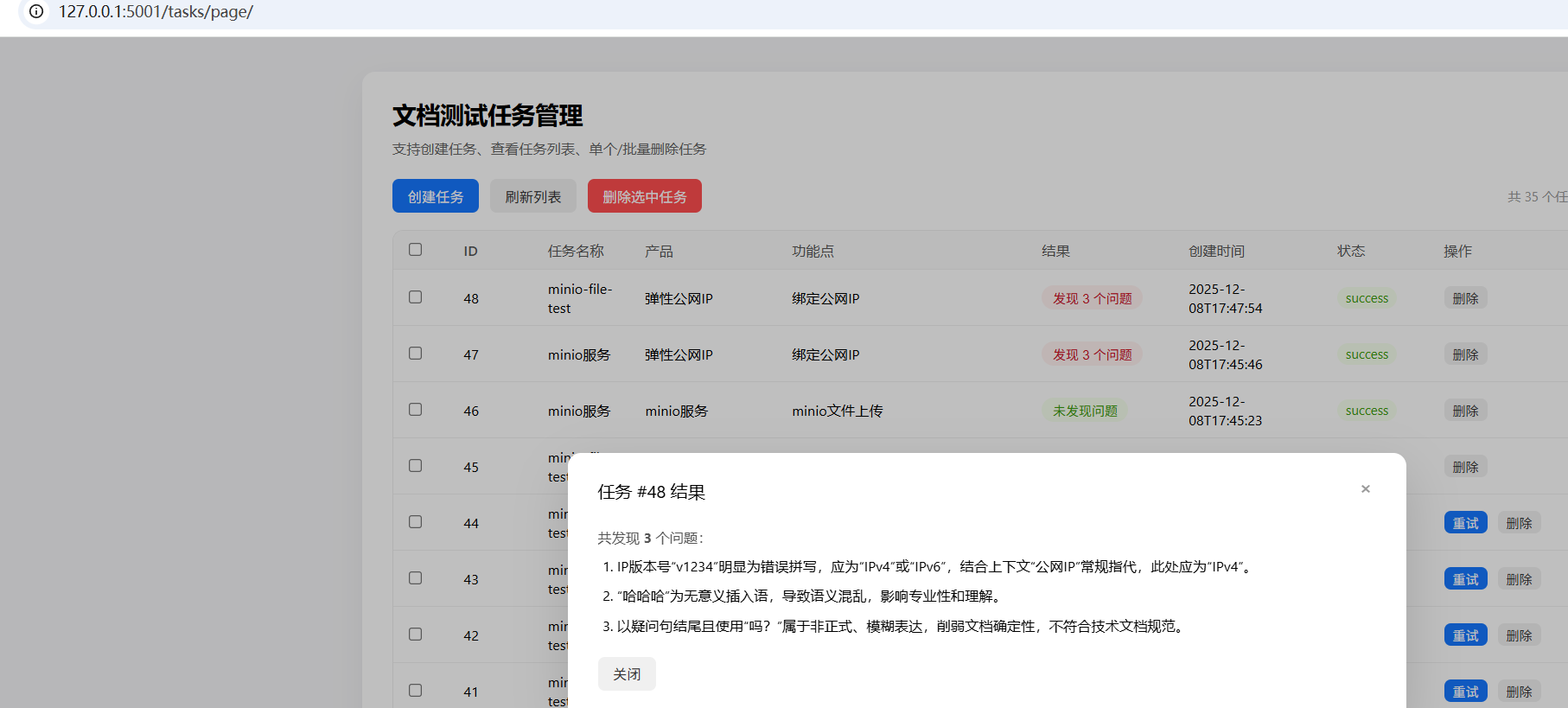
測試效果:
數據庫數據

worker處理日誌:

最終效果:
五、前端界面適配接口
補充文本上傳的操作方式,適配
舊的文本輸入方式:
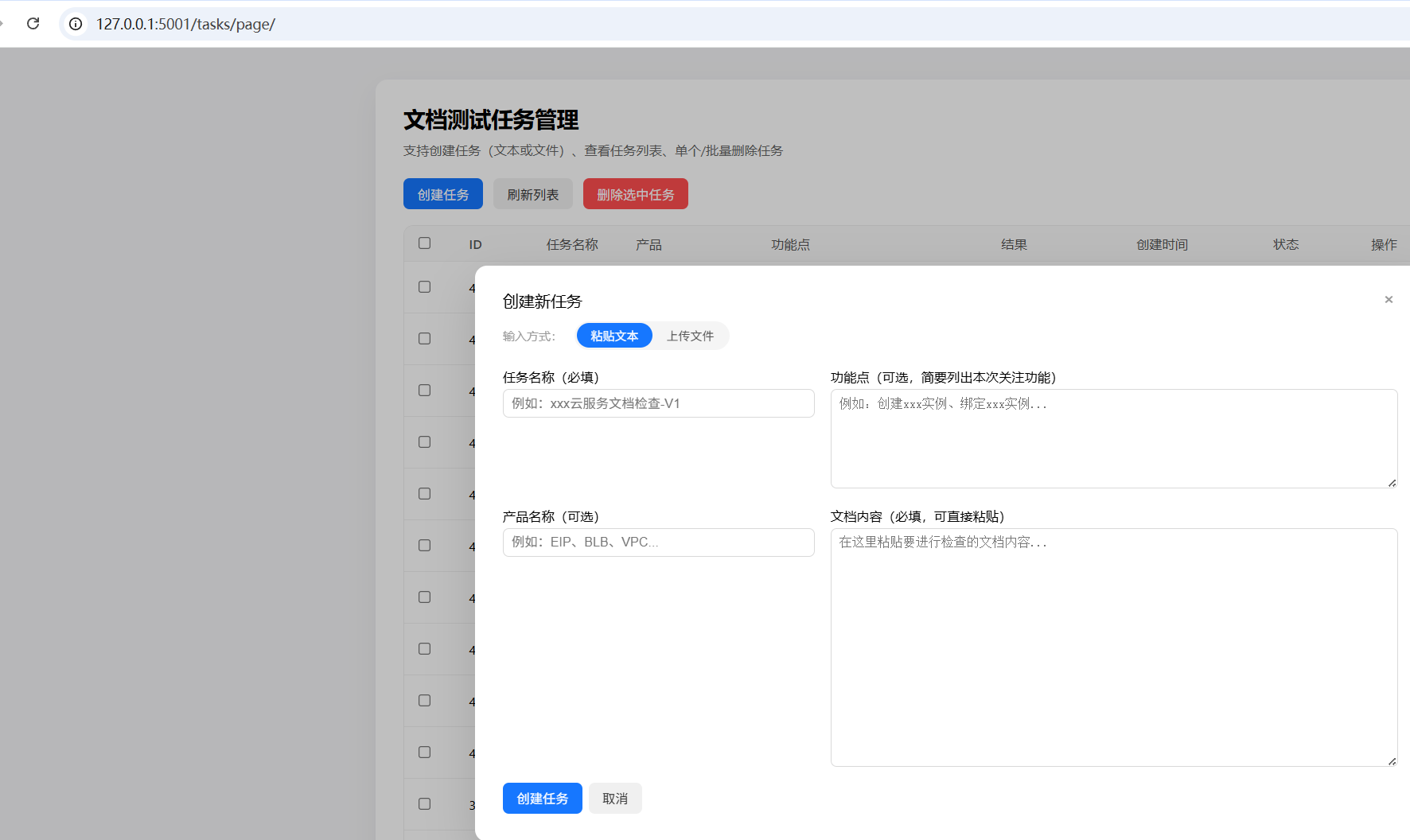
新支持的文件輸入方式