

肖哥彈架構 跟大家“彈彈” MongoDB 設計與實戰應用,需要代碼關注
歡迎 關注,點贊,留言。
關注公號Solomon肖哥彈架構獲取更多精彩內容
歷史熱點文章
- MyCat應用實戰:分佈式數據庫中間件的實踐與優化(篇幅一)
- 圖解深度剖析:MyCat 架構設計與組件協同 (篇幅二)
- 一個項目代碼講清楚DO/PO/BO/AO/E/DTO/DAO/ POJO/VO
- 寫代碼總被Dis:5個項目案例帶你掌握SOLID技巧,代碼有架構風格
- 里氏替換原則在金融交易系統中的實踐,再不懂你咬我
⚠️ 原創不易 搬運必究
本文為你係統梳理從技術選型、副本集與分片集羣架構、千萬級訂單系統實戰,到容量規劃與遷移決策的完整知識體系!內含多張架構圖解、分片鍵設計原則、聚合管道優化、性能監控指標等硬核內容,助你構建高可用、可擴展的 MongoDB 生產級架構!
一、技術選型:為什麼選擇 MongoDB?
1.1 架構演進視角
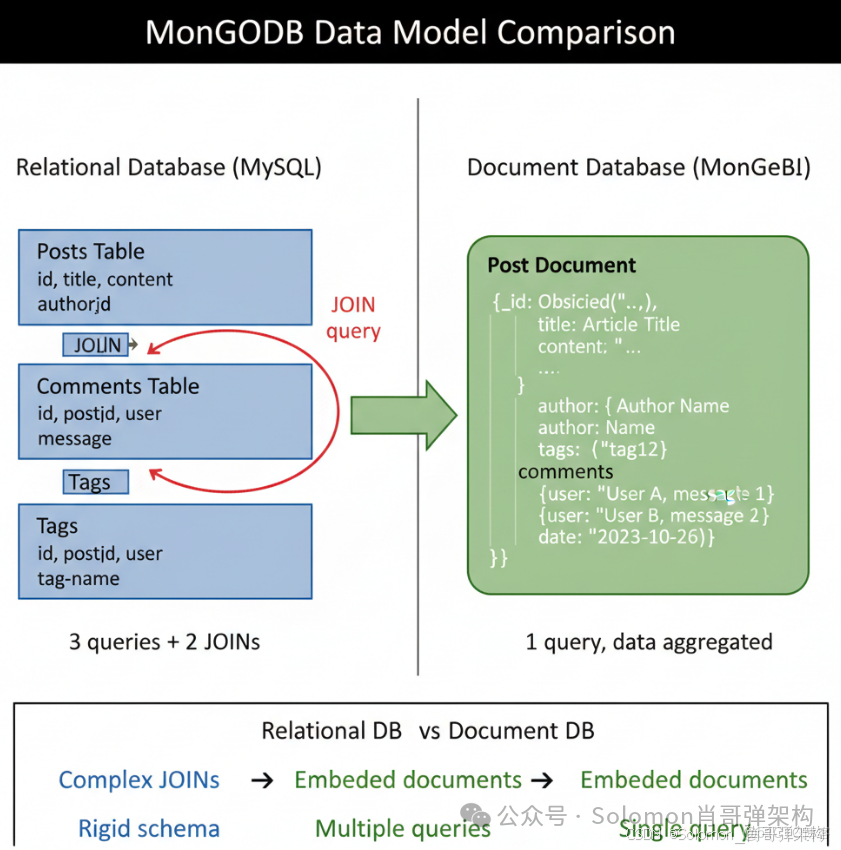
傳統關係型架構的痛點:
- 垂直擴展瓶頸:單機性能上限明顯(CPU、內存、磁盤 I/O)
- JOIN 操作開銷:多表關聯查詢在大數據量下性能急劇下降
- Schema 剛性:業務需求變化時需要執行 DDL 操作(ALTER TABLE),停機風險高
- ORM 阻抗不匹配:對象模型與關係模型之間需要複雜的映射層
MongoDB 的架構優勢:
- 文檔模型天然適配對象:JSON/BSON 格式與應用層 DTO 直接對應
- 無需 JOIN:通過嵌入式文檔和數組實現數據聚合
- 動態 Schema:支持字段級別的靈活擴展,無需全局鎖表
- 水平擴展能力:通過分片(Sharding)實現線性擴展
1.2 適用場景矩陣
| 業務場景 | 推薦度 | 原因 |
|---|---|---|
| 內容管理系統(CMS) | ⭐⭐⭐⭐⭐ | 文檔結構靈活,支持富文本、標籤、評論嵌套 |
| 實時日誌分析 | ⭐⭐⭐⭐⭐ | 高寫入吞吐量,時序數據天然契合 |
| 物聯網數據存儲 | ⭐⭐⭐⭐⭐ | 海量設備數據,支持地理位置索引 |
| 用户畫像系統 | ⭐⭐⭐⭐ | 靈活的屬性擴展,支持數組查詢 |
| 電商商品目錄 | ⭐⭐⭐⭐ | SKU 屬性差異大,需要動態字段 |
| 金融交易系統 | ⭐⭐ | 強一致性要求高,建議用 PostgreSQL + 事務 |
| 複雜關聯報表 | ⭐⭐ | 需要複雜聚合,建議用 ClickHouse 或數倉 |
二、核心架構解析
2.1 副本集架構(Replica Set)
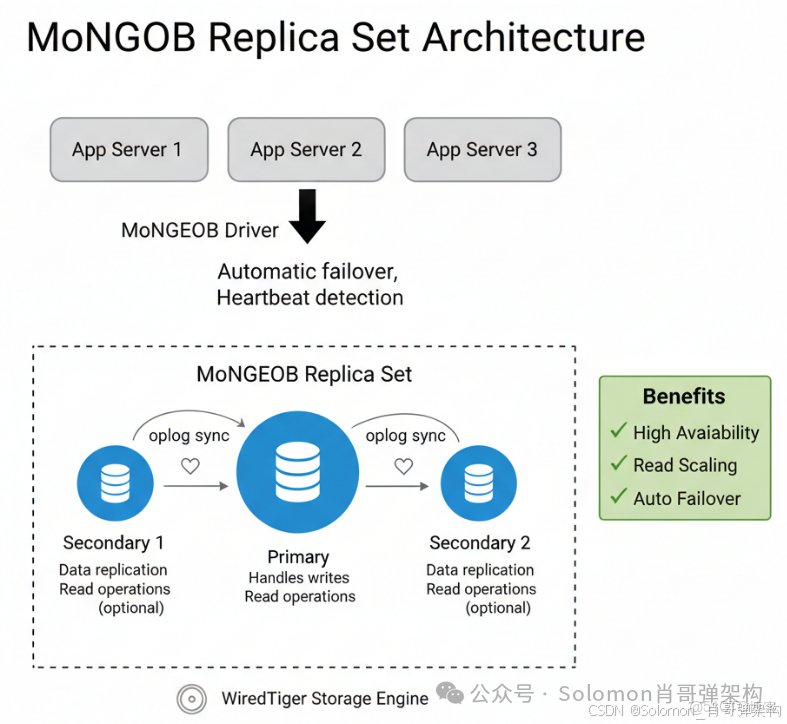
架構組件:
- Primary 節點:處理所有寫操作,記錄 oplog(操作日誌)
- Secondary 節點:從 Primary 同步數據,可配置為只讀節點
- Arbiter 節點(可選):僅參與選舉投票,不存儲數據(節省資源)
關鍵技術點:
// 副本集配置示例
rs.initiate({
_id: "myReplicaSet",
members: [
{ _id: 0, host: "mongo1:27017", priority: 2 }, // Primary 優先級高
{ _id: 1, host: "mongo2:27017", priority: 1 }, // Secondary
{ _id: 2, host: "mongo3:27017", priority: 1 } // Secondary
]
})
讀寫分離策略:
// 設置讀偏好(Read Preference)
db.collection.find().readPref("secondaryPreferred")
| 策略 | 説明 | 適用場景 |
|---|---|---|
primary |
只讀主節點 | 強一致性要求 |
primaryPreferred |
主節點優先,主節點不可用時讀從節點 | 默認推薦 |
secondary |
只讀從節點 | 分析查詢、報表生成 |
nearest |
讀取延遲最低的節點 | 地理分佈式部署 |
故障轉移機制:
- 心跳檢測:節點間每 2 秒發送心跳
- 選舉算法:基於 Raft 協議,多數派(N/2 + 1)投票通過
- 自動切換時間:通常在 10-30 秒內完成(取決於
electionTimeoutMillis配置)
2.2 分片集羣架構(Sharding)
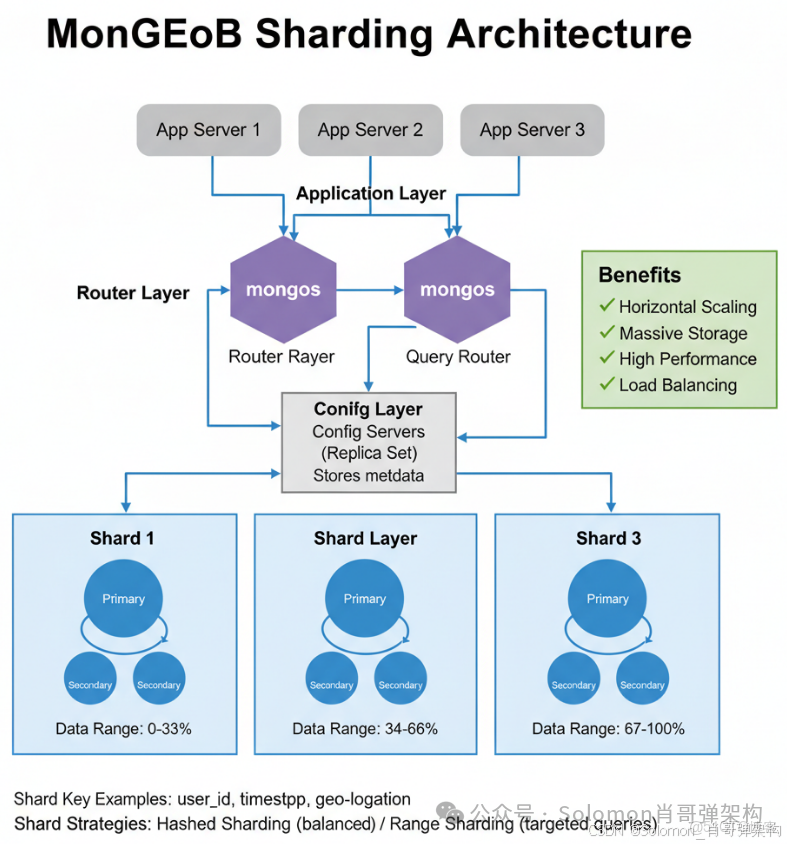
為什麼需要分片?
- 單個副本集的存儲上限約為 5TB(受限於 oplog 同步壓力)
- 單節點 QPS 上限約 10 萬(受限於 CPU 和網絡帶寬)
分片架構組件:
| 組件 | 數量建議 | 職責 |
|---|---|---|
| mongos | ≥2(無狀態,可水平擴展) | 查詢路由、結果聚合 |
| Config Servers | 3(副本集) | 存儲集羣元數據和分片配置 |
| Shard | ≥2(每個 Shard 是一個副本集) | 存儲實際數據分片 |
分片鍵選擇原則:
// 錯誤示例:單調遞增的 _id
sh.shardCollection("mydb.orders", { _id: 1 })
// 問題:所有新數據寫入最後一個分片,導致熱點
// 推薦示例:複合分片鍵
sh.shardCollection("mydb.orders", { user_id: 1, order_date: 1 })
// 優勢:數據分佈均勻,支持範圍查詢
分片鍵設計檢查清單:
- ✅ 高基數(Cardinality):字段值的唯一性越高越好(如 user_id 優於 status)
- ✅ 查詢頻率:分片鍵應該是查詢條件的常用字段
- ✅ 寫入分散:避免單調遞增鍵(時間戳、自增 ID)
- ✅ 避免孤兒文檔:不要頻繁修改分片鍵字段的值
三、實戰案例:電商訂單系統
3.1 業務需求
構建一個支持千萬級用户、日訂單百萬級的電商訂單系統,要求:
- 訂單查詢響應時間 < 100ms
- 支持按用户維度的歷史訂單查詢
- 支持按商品維度的銷量統計
- 數據保留 3 年
3.2 數據模型設計
// 訂單文檔(Order Document)
{
_id: ObjectId("..."),
order_id: "ORD20231027001", // 業務主鍵
user_id: 123456, // 分片鍵之一
order_date: ISODate("2023-10-27T10:30:00Z"),
status: "completed", // pending | paid | shipped | completed | cancelled
// 嵌入式文檔:收貨地址
shipping_address: {
province: "廣東省",
city: "深圳市",
district: "南山區",
detail: "科技園XXX號"
},
// 嵌入式數組:訂單商品明細
items: [
{
product_id: 789,
product_name: "iPhone 15 Pro",
quantity: 1,
price: 7999.00,
snapshot: { // 商品快照,防止商品信息變更
color: "鈦金色",
storage: "256GB"
}
}
],
// 支付信息
payment: {
method: "alipay",
amount: 7999.00,
transaction_id: "2023102722001...",
paid_at: ISODate("2023-10-27T10:32:15Z")
},
// 審計字段
created_at: ISODate("2023-10-27T10:30:00Z"),
updated_at: ISODate("2023-10-27T15:20:00Z")
}
3.3 索引策略
// 1. 分片鍵索引(自動創建)
db.orders.createIndex({ user_id: 1, order_date: 1 })
// 2. 訂單狀態查詢索引
db.orders.createIndex({ status: 1, created_at: -1 })
// 3. 業務主鍵唯一索引
db.orders.createIndex({ order_id: 1 }, { unique: true })
// 4. 商品銷量統計索引(注意:數組字段會創建多鍵索引)
db.orders.createIndex({ "items.product_id": 1, status: 1 })
// 5. 部分索引優化(只索引已完成的訂單,節省空間)
db.orders.createIndex(
{ user_id: 1, created_at: -1 },
{ partialFilterExpression: { status: "completed" } }
)
3.4 聚合管道查詢(Aggregation Pipeline)
場景:統計每個商品的月度銷量 TOP 10
db.orders.aggregate([
// 階段1:過濾條件
{
$match: {
status: "completed",
order_date: {
$gte: ISODate("2023-10-01"),
$lt: ISODate("2023-11-01")
}
}
},
// 階段2:展開商品數組
{ $unwind: "$items" },
// 階段3:分組統計
{
$group: {
_id: "$items.product_id",
total_quantity: { $sum: "$items.quantity" },
total_revenue: { $sum: { $multiply: ["$items.quantity", "$items.price"] } },
order_count: { $sum: 1 }
}
},
// 階段4:排序
{ $sort: { total_quantity: -1 } },
// 階段5:限制結果
{ $limit: 10 },
// 階段6:關聯商品表($lookup 相當於 LEFT JOIN)
{
$lookup: {
from: "products",
localField: "_id",
foreignField: "product_id",
as: "product_info"
}
}
])
3.5 性能優化實踐
1. 使用 Explain 分析執行計劃
db.orders.find({ user_id: 123456 }).explain("executionStats")
關鍵指標:
executionTimeMillis:執行時間totalDocsExamined:掃描文檔數(應接近nReturned)stage: "IXSCAN":表示使用了索引掃描(好)stage: "COLLSCAN":表示全表掃描(差)
2. 寫入優化:批量操作
// 錯誤示例:循環單條插入(RTT 開銷大)
for (let order of orders) {
db.orders.insertOne(order); // 1000 次網絡往返
}
// 推薦示例:批量插入
db.orders.insertMany(orders, { ordered: false }); // 1 次網絡往返
3. 使用 Change Streams 實現實時同步
// 監聽訂單狀態變化,推送到消息隊列
const changeStream = db.orders.watch([
{ $match: { "updateDescription.updatedFields.status": { $exists: true } } }
]);
changeStream.on("change", (change) => {
console.log("訂單狀態變更:", change.documentKey, change.updateDescription);
// 發送到 Kafka/RabbitMQ
});
四、架構治理
4.1 容量規劃
計算公式:
單文檔大小 ≈ 2KB(訂單)
工作集大小 = 活躍數據量(近 3 個月)≈ 1 億條 × 2KB = 200GB
推薦內存配置 = 工作集大小 × 1.5 = 300GB
磁盤空間 = 總數據量 × 3(副本集) × 1.2(索引開銷)= 3.6TB
4.2 監控指標
| 指標 | 閾值 | 説明 |
|---|---|---|
| 連接數 | < 80% | 默認最大連接數 65536 |
| 工作集內存佔比 | > 70% | 低於此值説明頻繁訪問磁盤 |
| 主從延遲 | < 3s | 超過 10s 需告警 |
| 鎖等待時間 | < 10ms | 高併發寫入時需關注 |
| 慢查詢 | < 100ms | 記錄到 system.profile |
推薦監控工具:
- MongoDB Atlas(雲原生)
- Prometheus + Grafana
- Percona Monitoring and Management(PMM)
4.3 備份策略
# 1. 邏輯備份(適用於小數據量)
mongodump --uri="mongodb://localhost:27017/mydb" --out=/backup/
# 2. 物理備份(推薦)
# 使用 Percona Backup for MongoDB(支持增量備份)
pbm backup --type=physical
# 3. 時間點恢復(PITR)
pbm restore --time="2023-10-27T10:00:00Z"
五、從 MySQL 遷移到 MongoDB
5.1 遷移決策樹
是否需要複雜事務?
├─ 是 → 保留 MySQL 或使用 MongoDB 4.0+ 多文檔事務
└─ 否 → 繼續評估
├─ 是否有大量 JOIN 查詢?
│ ├─ 是 → 考慮反範式化設計
│ └─ 否 → 適合 MongoDB
└─ 是否需要動態 Schema?
├─ 是 → 強烈推薦 MongoDB
└─ 否 → 根據性能需求選擇
5.2 數據遷移工具
// 使用 MongoDB Connector for BI(將 MongoDB 映射為 SQL)
// 或使用 ETL 工具:Apache NiFi、Talend
六、常見架構反模式
| 反模式 | 問題 | 解決方案 |
|---|---|---|
| 大數組無限增長 | 文檔大小超過 16MB 限制 | 拆分為獨立集合 + 引用 |
| 頻繁的全表掃描 | 未創建索引 | explain() 分析 + 創建複合索引 |
| 分片鍵選擇不當 | 數據傾斜,熱點分片 | 使用哈希分片或複合鍵 |
| 過度嵌套 | 文檔層級超過 100 層 | 扁平化設計 |
| 在 MongoDB 中實現複雜 JOIN | 性能差 | 改用聚合管道或拆分查詢 |