

在Python+FastAPI的後端項目中,我們往往很多時候需要對數據進行相關的處理,本篇隨筆介紹在Python+FastAPI項目中使用SqlAlchemy操作數據的幾種常見方式。
使用 FastAPI, SQLAlchemy, Pydantic構建後端項目的時候,其中數據庫訪問採用SQLAlchemy 的異步方式處理。一般我們在操作數據庫操作的時候,採用基類繼承的方式減少重複代碼,提高代碼複用性。不過我們在分析SQLAlchemy的時候,我們可以簡單的方式來剖析幾種常見的數據庫操作方式,來介紹SQLAlchemy的具體使用。
1、SQLAlchemy介紹
SQLAlchemy 允許開發者通過 Python 代碼與數據庫進行交互,而無需直接編寫 SQL 語句,同時也支持直接使用原生 SQL 進行復雜查詢。下面是SQLAlchemy和我們常規數據庫對象的對應關係説明。
Table 對象或 Declarative Base 中的類來表示。
declarative_base()。
from sqlalchemy import Column, Integer, String, create_engine from sqlalchemy.ext.declarative import declarative_base Base = declarative_base() class User(Base): __tablename__ = 'users' # 數據庫表名 id = Column(Integer, primary_key=True) name = Column(String) email = Column(String)
數據庫列 (Database Column):使用 Column 對象來表示。每個數據庫表中的列在SQLAlchemy中表示為 Column 對象,並作為類的屬性定義。
id = Column(Integer, primary_key=True)
name = Column(String(50))
數據庫行 (Database Row):每個數據庫表的一個實例(對象)代表數據庫表中的一行。在SQLAlchemy中,通過實例化模型類來表示數據庫表中的一行。
new_user = User(id=1, name='John Doe', email='john@example.com')
主鍵 (Primary Key):使用 primary_key=True 參數定義主鍵。
id = Column(Integer, primary_key=True)
外鍵 (Foreign Key): 使用 ForeignKey 對象來表示。
from sqlalchemy import ForeignKey from sqlalchemy.orm import relationship class Address(Base): __tablename__ = 'addresses' id = Column(Integer, primary_key=True) user_id = Column(Integer, ForeignKey('users.id')) user = relationship('User')
關係 (Relationships): 使用 relationship 對象來表示。數據庫中表與表之間的關係在SQLAlchemy中通過 relationship 來定義。
addresses = relationship("Address", back_populates="user")
2、常規的單表處理
下面我們通過異步處理的方式,介紹如何在單表中操作相關的數據庫數據。
async def get(self, db: AsyncSession, id: Any) -> Any: """根據主鍵獲取一個對象""" if isinstance(id, str): query = select(self.model).filter(func.lower(self.model.id) == id.lower()) else: query = select(self.model).filter(self.model.id == id) result = await db.execute(query) item = result.scalars().first() return item
如果我們需要強制對外鍵的類型進行匹配(如對於Postgresql的嚴格要求,數據比較的類型必須一致),那麼我們需要在基類或者CRUD類初始化的時候,獲得對應的主鍵類型。
class BaseCrud(Generic[ModelType, PrimaryKeyType, PageDtoType, DtoType]): """ 基礎CRUD操作類,傳入參數説明: * `ModelType`: SQLAlchemy 模型類 * `PrimaryKeyType`: 限定主鍵的類型 * `PageDtoType`: 分頁查詢輸入類 * `DtoType`: 數據傳輸對象類,如新增、更新的單個對象DTO """ def __init__(self, model: Type[ModelType]): """ 數據庫訪問操作的基類對象(CRUD). * `model`: A SQLAlchemy model class """ self.model = model # 模型類型 # 運行期獲取主鍵字段類型 pk_column = inspect(model).primary_key[0] self._pk_type = pk_column.type.python_type # int / str
因此對於單表的Get方法,我們修改下,讓他匹配主鍵的類型進行比較,這樣過對於嚴格類型判斷的Postgresql也正常匹配了。
async def get(self, db: AsyncSession, id: PrimaryKeyType) -> Optional[ModelType]: """根據主鍵獲取一個對象""" #對id的主鍵進行類型轉換,self._pk_type在構造函數的初始化中獲取 try: id = self._pk_type(id) except Exception: raise ValueError(f"Invalid primary key type: {id}") if isinstance(id, str): query = select(self.model).filter(func.lower(self.model.id) == id.lower()) else: query = select(self.model).filter(self.model.id == id) result = await db.execute(query) item = result.scalars().first() return item
對於刪除的數據,我們也可以類似的處理對比進行了。
from sqlalchemy.orm import Session, Query from sqlalchemy.ext.asyncio import AsyncSession from sqlalchemy import delete as sa_delete, update as sa_update async def delete_byid(self, db: AsyncSession, id: PrimaryKeyType) -> bool: """根據主鍵刪除一個對象 :param id: 主鍵值 """ #對id的主鍵進行類型轉換,self._pk_type在構造函數的初始化中獲取 try: id = self._pk_type(id) except Exception: raise ValueError(f"Invalid primary key type: {id}") del_query: sa_delete if isinstance(id, str): del_query = sa_delete(self.model).where( func.lower(self.model.id) == id.lower() ) else: del_query = sa_delete(self.model).where(self.model.id == id) result = await db.execute(del_query) await db.commit() return result.rowcount > 0
對於提供多條件的查詢或者過濾,我們可以使用where函數或者filter函數,在 SQLAlchemy 中,select(...).where(...) 和 select(...).filter(...) 都用於構造查詢條件,如下所示等效。
query = select(self.model).where(self.model.id == id)
query = select(self.model).filter(self.model.id == id)
我們可以通過sqlAlchemy的and_和or_函數來進行組合多個條件。
from sqlalchemy import ( Table,Column,and_,or_,asc,desc,select,func,distinct,text, Integer) .... match expression: case "and": query = await db.execute( select(self.model) .filter(and_(*where_list)) .order_by(*order_by_list) ) case "or": query = await db.execute( select(self.model).filter(or_(*where_list)).order_by(*order_by_list) )
Python的SqlAlchemy提供 InstrumentedAttribute 對象來操作多個條件,如我們對於一些多條件的處理,可以利用它來傳遞多個參數。
async def get_all_by_attributes( self, db: AsyncSession, *attributes: InstrumentedAttribute, sorting: str = "" ) -> List[ModelType] | None: """根據列名稱和值獲取相關的對象列表 :param sorting: 格式:name asc 或 name asc,age desc :param attributes: SQLAlchemy InstrumentedAttribute objects,可以輸入多個條件 例子:User.id != 1 或者 User.username == "JohnDoe" """ order_by_list = parse_sort_string(sorting, self.model) query = select(self.model).filter(and_(*attributes)).order_by(*order_by_list) result = await db.execute(query) return result.scalars().all()
例如,對於 模型 Material 對象,我們對它進行多個條件的查詢處理,如下所示,紅色部分為 *attributes: InstrumentedAttribute 參數。
items = await super().get_all_by_attributes( db, Material.id == vercol.id, Material.vercol == vercol.vercol, Material.ischecked == 0, Material.status == 0, )
同樣我們可以利用它來獲取數量,或者判斷多條件的記錄是否存在。
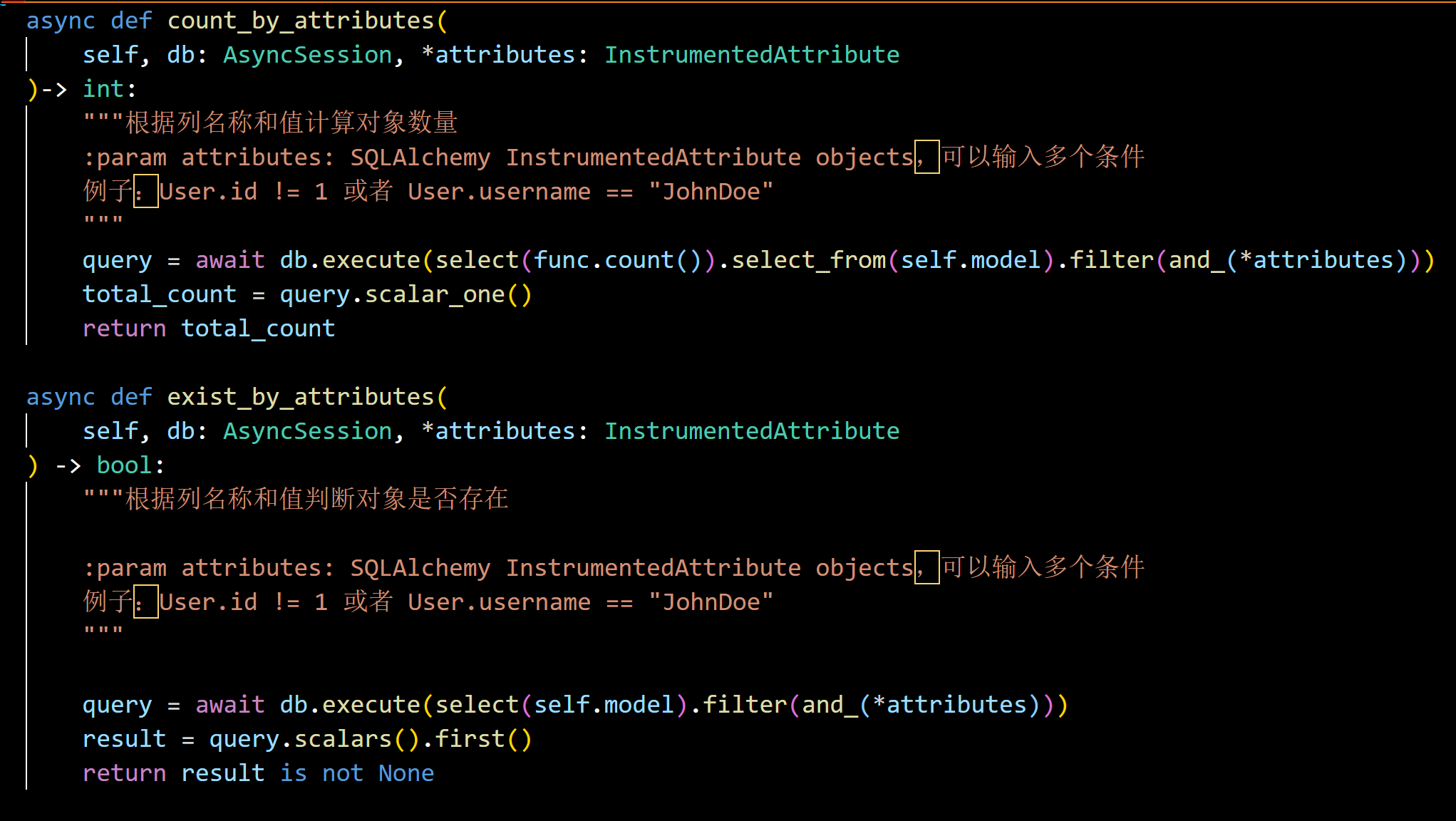
在數據插入或者更新的操作中,我們可以接受對象類型或者字典類型的參數對象,因此方法如下所示。
async def update(self, db: AsyncSession, obj_in: DtoType | dict[str, Any]) -> bool: """更新對象 :param obj_in: 對象輸入數據,可以是 DTO 對象或字典 """ try: if isinstance(obj_in, dict): obj_id = obj_in.get("id") if obj_id is None: raise ValueError("id is required for update") update_data = obj_in else: obj_id = obj_in.id # update_data = vars(obj_in) update_data = obj_in.model_dump(exclude_unset=True) query = select(self.model).filter(self.model.id == obj_id) result = await db.execute(query) db_obj = result.scalars().first() if db_obj: # 更新對象字段 for field, value in update_data.items(): # 跳過以 "_" 開頭的私有屬性 if field.startswith("_"): continue setattr(db_obj, field, value) # 處理更新前的回調處理 self.on_before_update(update_data, db_obj) # 提交事務 await db.commit() return True else: return False except SQLAlchemyError as e: self.logger.error(f"update 操作出現錯誤: {e}") await db.rollback() # 確保在出錯時回滾事務 return False
我們在插入或者更新數據的時候,一般會默認更新一些字段,如創建人,創建日期、編輯人,編輯日期等信息,我們可以把它單獨作為一個可以給子類重寫的函數,基類做一些默認的處理。
def on_before_update(self, update_data: dict[str, Any], db_obj: ModelType) -> None: """更新對象前的回調函數,子類可以重寫此方法 可通過 setattr(db_obj, field, value) 設置字段值 """ setattr(db_obj, "edittime", datetime.now()) user :CurrentUserIns = get_current_user() if user: setattr(db_obj, "editor", user.fullname) setattr(db_obj, "editor_id", user.id) setattr(db_obj, "company_id", user.company_id) setattr(db_obj, "companyname", user.companyname)
有時候,如果我們需要獲取某個字段非重複的列表,用來做為動態下拉列表的數據,那麼我們可以通過下面函數封裝下。
async def get_field_list(self, db: AsyncSession, field_name: str) -> Iterable[str]: """獲取指定字段值的唯一列表 :param field_name: 字段名稱 """ field = getattr(self.model, field_name) query = select(distinct(field)) result = await db.execute(query) return result.scalars().all()
3、多表聯合的處理操作
多表操作,也是我們經常碰到的處理方式,如對於字典類型和字典項目,他們是兩個表,需要聯合起來獲取數據,那麼就需要多表的聯合操作。
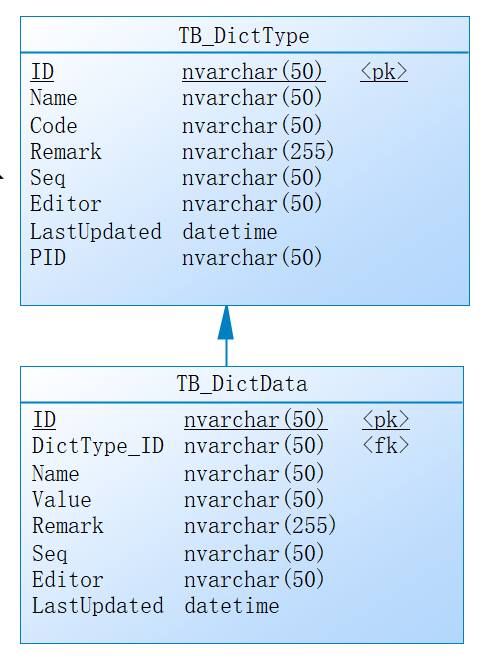
如下是字典CRUD類中,聯合字典類型獲取數據的記錄處理。
async def get_dict_by_typename(self, db: AsyncSession, dicttype_name: str) -> dict: """根據字典類型名稱獲取所有該類型的字典列表集合""" result = await db.execute( select(self.model) .join(DictType, DictType.id == self.model.dicttype_id) # 關聯字典類型表 .filter(DictType.name == dicttype_name) # 過濾字典類型名稱 .order_by(DictData.seq) # 排序 ) items = result.scalars().all() dict = {} for info in items: if info.name not in dict: dict[info.name] = info.value return dict
如果我們需要對某個表的遞歸獲取樹列表,可以如下處理
async def get_tree(self, db: AsyncSession, pid: str) -> list[DictType]: """獲取字典類型一級列表及其下面的內容""" # 使用三元運算符將 pid 設為 "-1"(如果 pid 是 null 或空白)或保持原值 pid = "-1" if not pid or pid.strip() == "" else pid result = await db.execute( select(self.model) .filter(self.model.pid == pid) .options(selectinload(DictType.children)) ) nodes = result.scalars().all() return nodes
我們來假設用户和文章的示例表結構(ORM 模型,如下所示。
class User(Base): __tablename__ = "users" id = Column(Integer, primary_key=True, index=True) name = Column(String) email = Column(String) articles = relationship("Article", back_populates="author") class Article(Base): __tablename__ = "articles" id = Column(Integer, primary_key=True, index=True) title = Column(String) content = Column(Text) user_id = Column(Integer, ForeignKey("users.id")) author = relationship("User", back_populates="articles")
我們可以通過下面函數處理獲得相關的記錄集合。
async def get_user_articles(db: AsyncSession): stmt = ( select(User, Article) .join(Article, Article.user_id == User.id) ) result = await db.execute(stmt) return result.all() # [(User(), Article()), ...]
如果需要可以使用outer_join函數處理
async def get_users_with_articles(db: AsyncSession): stmt = ( select(User, Article) .outerjoin(Article, Article.user_id == User.id) ) result = await db.execute(stmt) return result.all() # 用户即便沒有文章也會出現
如果我們需要獲取有文章的所有用户,如下所示。
async def get_users_with_articles(db: AsyncSession): stmt = select(User).options(selectinload(User.articles)) # 自動 load 關聯 result = await db.execute(stmt) return result.scalars().all()
selectinload 會執行兩次 SQL,但效率高,不會產生笛卡爾積,非常適合集合查詢。
多表鏈式 Join的處理,可以獲得兩個表的不同信息進行組合。
async def get_articles_with_author(db: AsyncSession): stmt = ( select(Article.title, User.name.label("author")) .join(User, Article.user_id == User.id) ) rows = await db.execute(stmt) return rows.mappings().all() # 以 dict 形式返回 [{'title':..., 'author':...}]
帶篩選條件與分頁的處理實現,如下所示
async def search_articles(db: AsyncSession, keyword: str, page: int = 1, size: int = 10): stmt = ( select(Article, User.name.label("author")) .join(User) .filter(Article.title.contains(keyword)) .offset((page - 1) * size) .limit(size) ) result = await db.execute(stmt) return result.mappings().all()
對於權限管理系統來説,一般有用户、角色,以及用户角色的中間表,我們來看看這個在SQLAlchemy最佳實踐是如何的操作。
from sqlalchemy import Table, Column, Integer, ForeignKey from sqlalchemy.orm import relationship, Mapped, mapped_column from database import Base # --- 中間表寫法 --- role_user = Table( "role_user", Base.metadata, Column("user_id", ForeignKey("users.id"), primary_key=True), Column("role_id", ForeignKey("roles.id"), primary_key=True) ) class User(Base): __tablename__ = "users" id: Mapped[int] = mapped_column(primary_key=True) username: Mapped[str] = mapped_column() roles: Mapped[list["Role"]] = relationship( secondary=role_user, back_populates="users", lazy="selectin" ) class Role(Base): __tablename__ = "roles" id: Mapped[int] = mapped_column(primary_key=True) name: Mapped[str] = mapped_column() users: Mapped[list[User]] = relationship( secondary=role_user, back_populates="roles", lazy="selectin" )
在 SQLAlchemy 聲明多對多關係時,secondary 參數既可以填 字符串形式的表名,也可以填 已經定義好的中間表對象(Table 對象)。
① econdary="role_user" —— 使用字符串表名
roles = relationship("Role", secondary="role_user", back_populates="users")
② secondary=role_user —— 傳入中間表對象(推薦方式)
role_user = Table( "role_user", Base.metadata, Column("user_id", ForeignKey("users.id"), primary_key=True), Column("role_id", ForeignKey("roles.id"), primary_key=True) ) roles = relationship("Role", secondary=role_user, back_populates="users")
對於如果獲取對應角色的用户記錄,我們可以通過下面方式獲取(通過連接中間表的方式)
async def get_users_by_role(db: AsyncSession, role_id: int) -> list[User]: stmt = ( select(User) .join(role_user, role_user.c.user_id == User.id) .where(role_user.c.role_id == role_id) ) result = await db.execute(stmt) return result.scalars().all()
也可以下面的方式進行處理(使用 relationship any()),效果是一樣的。
select(User).filter(User.roles.any(id=role_id))
如果需要寫入用户、角色的關聯關係,我們可以使用下面方法來通過中間表進行判斷並寫入記錄。
from sqlalchemy import select, insert async def add_users_to_role(db: AsyncSession, role_id: int, user_ids: list[int]): # 1️⃣ 查詢已有關聯 user_id stmt = select(role_user.c.user_id).where(role_user.c.role_id == role_id) res = await db.execute(stmt) existing_user_ids = {row[0] for row in res.fetchall()} # 2️⃣ 過濾出新的 user_id new_user_ids = [uid for uid in user_ids if uid not in existing_user_ids] if not new_user_ids: return 0 # 沒有新增 # 3️⃣ 批量插入 values = [{"user_id": uid, "role_id": role_id} for uid in new_user_ids] stmt = insert(role_user).values(values) await db.execute(stmt) await db.commit() return len(new_user_ids)
如果只是單個記錄的插入,可以利用下面的方式處理。
from sqlalchemy import select, insert async def add_user_to_role(db: AsyncSession, role_id: int, user_id: int) -> bool: # 1️⃣ 檢查是否已存在關聯 stmt = select(role_user).where( role_user.c.role_id == role_id, role_user.c.user_id == user_id ) res = await db.execute(stmt) exists = res.first() if exists: return False # 已存在,不再插入 # 2️⃣ 插入記錄 stmt = insert(role_user).values(user_id=user_id, role_id=role_id) await db.execute(stmt) await db.commit() return True
以上就是對於在Python+FastAPI的後端項目中使用SqlAlchemy操作數據的幾種常見方式,包括單表處理,多表關聯、中間表的數據維護和定義等內容,是我們在操作常規數據的時候,經常碰到的幾種方式。
希望上文對你有所啓發和幫助,感謝閲讀。