

hadoop 大數據主要生態組成架構圖以及描述
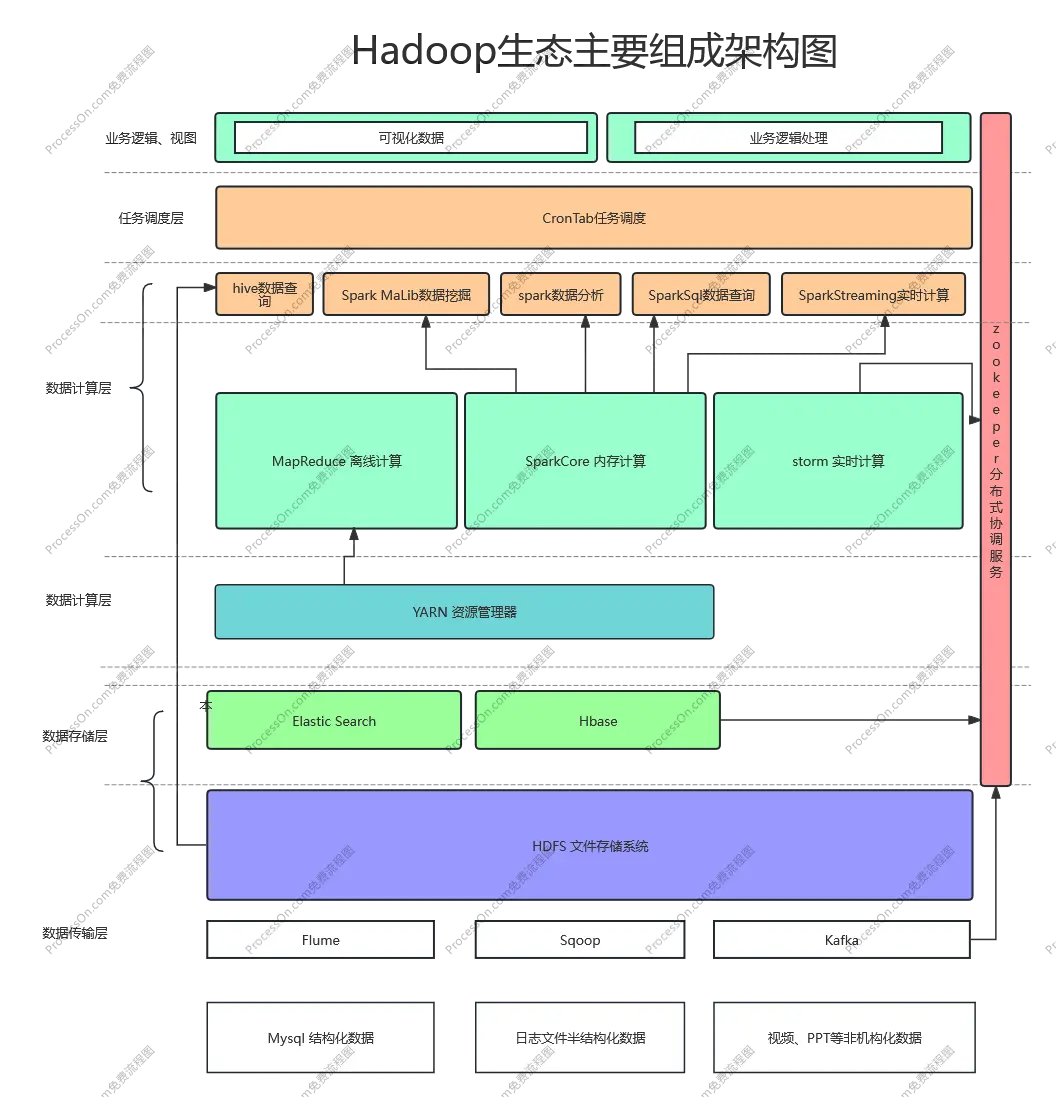
- HDFS 高吞吐量的分佈式文件系統
- YARN 用於任務調度和資源管理及分配的框架
- MapReduce 運行與YARN之上,用於並行處理大數據的框架
- Zookeeper 高性能的分佈式應用協調服務
- Flume 日誌收集服務,用於將大量日誌數據衝不同的來源收集、聚合、最終移動到一個具體中心進行存續
- Sqoop 用於將關係型數據庫與hadoop文件系統進行導入導出的工具
- Kafka 高吞吐量的分佈式消息發佈和訂閲系統
- Hbase 一個可伸縮的分佈式數據庫,支持大型的表結構化存儲,底層有HDFA支持
同時依賴zookeeper進行集羣協調服務 - Elastic Search 分佈式全文索引引擎
- Hive 給予Hadoop 的數據倉庫,可以將結構化的數據隱射為一張數據庫表,並提供簡單的查詢,可以使用MapReduce 運行任務
- Storm 一個分佈式實時計算框架
- Spark 一個快速通用的hadoop數據計算引擎,提供了簡單而又強大的編程模型,支持廣泛的應用程序包括ETL,機器學習,流處理,圖形計算等
YARN 的基本架構

YARN 各個角色的作用
- client 客户端提交任務
- ResourceManager 接受客户端請求
啓動和管理各個應用程序的1ApplicationMaster
接受ApplicationMaster 的資源申請,併為其分配Container
管理NodeManager ,接受2來自NodeManager 的資源和節點的監控情況彙報 - NodeManager 是集羣中資源和任務的管理器,負責彙報節點上的資源使用情況,同時會接受來自ApplicationMaster 的對Container 的啓動或者停止請求
- Task 應用程序具體執行的任務一個應用程序可以有多個任務,如一個MapReduce程序可以包含·多個map任務和多個reduce 任務
- Container 是yarn 中資源分配·的基本單位。是封裝了內存和cpu 等的一個容器,相當於一個Task 運行環境的抽象
- ApplicationMaster 負責應用程序的管理,它為應用程序項ResourceManager申請資源,並將資源分配給相應的應用程序的task,一個應用程序對應一個ApplicationMaster
Hadoop 3.x 非高可用集羣搭建

1:在/home/hadoop 下新建兩個文件夾 softwares 存放安裝包 modules保存安裝的模塊
mkdir softwares
mkdir modules
下載 hadoop 的壓縮包
分別上傳到
hadoop001
hadoop002
hadoop003
的 /home/hadoop/softwares
2:在三個機器上都執行解壓命令
tar -zxf hadoop-3.3.6.tar.gz -C ../modules
3:在三個機器上都修改 /etc/profile 文件,添加環境變量(/home/hadoop/modules/hadoop-3.3.6/sbin)
sudo vim /etc/profile
在文件末尾加上
export HADOOP_HOME=/home/hadoop/modules/hadoop-3.3.6
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
保存之後 刷新配置文件
sudo source /etc/profile
輸入 hadoop 命令檢查環境變量安裝是否成功
4:三台機器都修改 hadoop 的配置文件
hadoop-env.sh
mapred-env.sh
yarn-env.sh
在其中分別加上 JAVA_HOME 環境變量
export JAVA_HOME=/usr/local/jdk17
5:修改 HDFS 配置文件
修改 core-site.xml 加入以下的內容
6:修改yarn 配置文件
7: 格式化NameNode
8:啓動hadoop
9:測試 wordCount