

導語
在 RocketMQ 的日常運維中,我們經常需要訪問不同的數據源來獲取診斷信息。傳統的方式往往需要編寫複雜的查詢語句,或者在多個系統之間切換,效率低下。為了解決這個問題,我們使用 LLM 結合 MCP 來實現高效的數據訪問。通過這種方式,可以用自然語言一站式查詢所需的信息,提高運維效率。
前言
在騰訊雲消息隊列團隊日常運維 TDMQ RocketMQ 版的過程中,經常需要訪問不同的數據源來獲取診斷信息。一般來説運維人員如果想要獲取某個數據源的信息,通常需要先登錄到對應的系統,然後編寫查詢語句,最後再解析返回的結果。這不但需要運維人員熟悉每個數據源的查詢語法,還需要在不同的系統之間切換,效率低下。
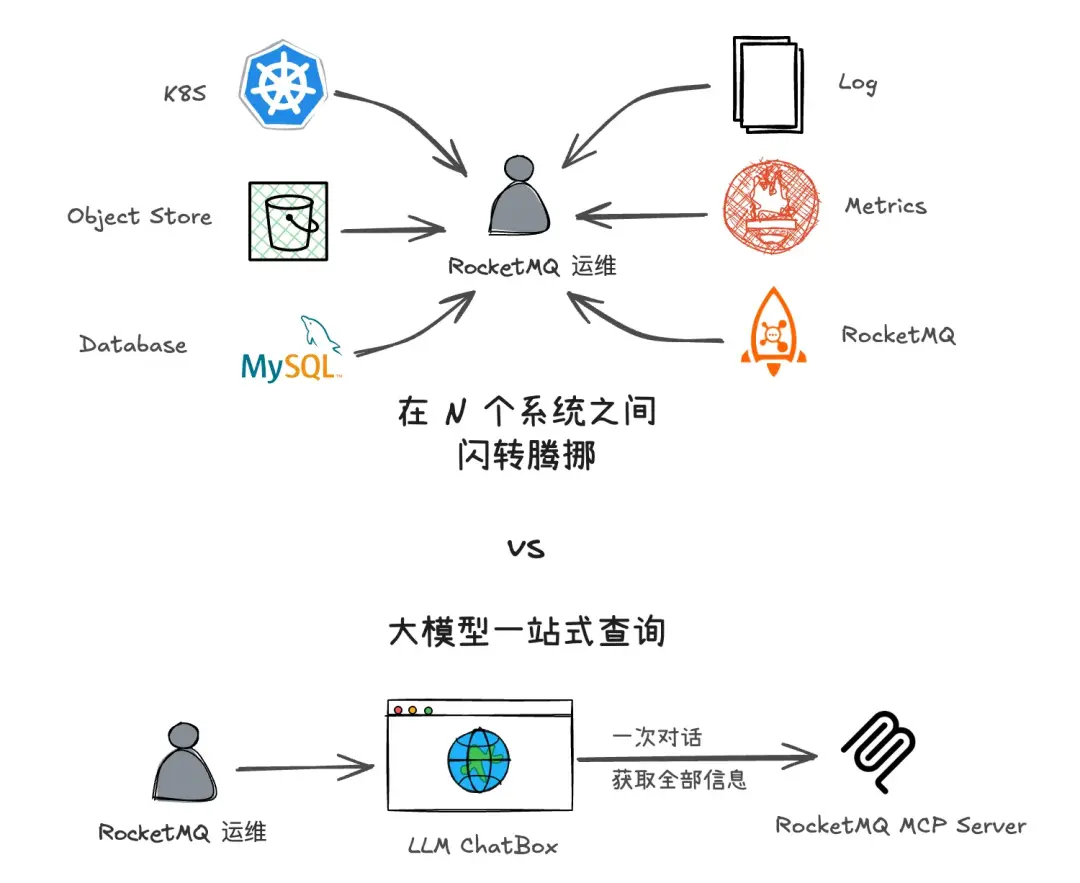
為了解決這個問題,我們可以使用 LLM 結合 MCP 來實現高效的數據訪問。通過這種方式,用自然語言一站式查詢所需的信息,提高問題診斷的效率。
Talk is cheap, show me the demo!
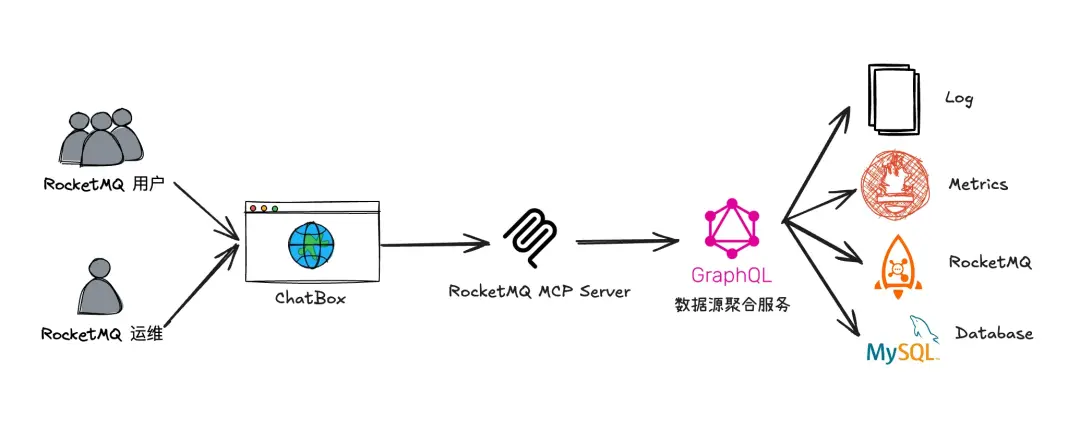
藉助 LLM + Chatbox + MCP + GraphQL 的組合,可以用自然語言查詢 RocketMQ 集羣的狀態、Topic 的信息、消息的內容等。理論上只要是在我們系統內的信息,都可以通過一次自然語言交互查出來,並且可以連續追問直到找到問題根因。再也不需要訪問一大堆服務,編輯命令行參數/SQL 或者在前端界面之間跳來跳去。
場景一:查詢集羣信息
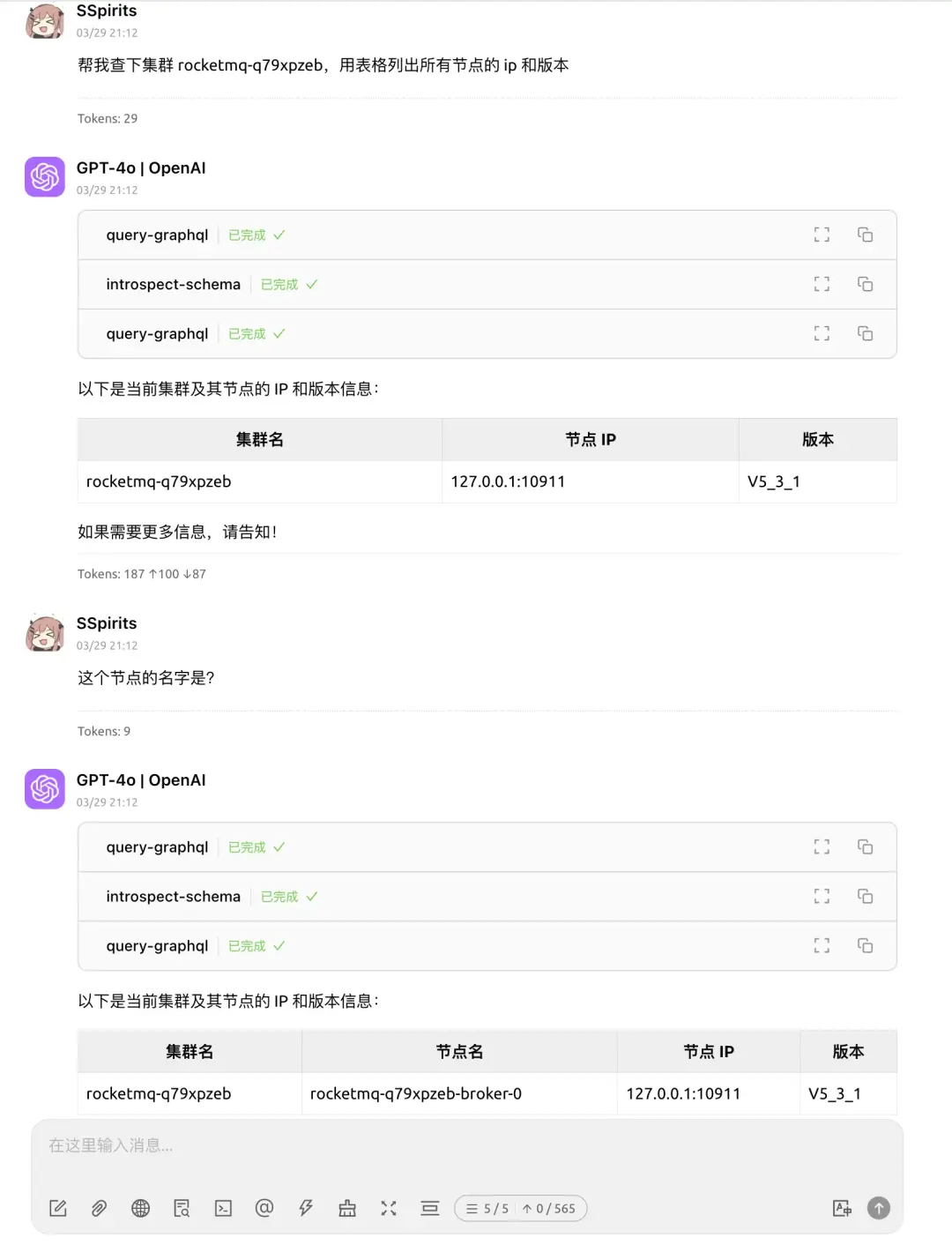
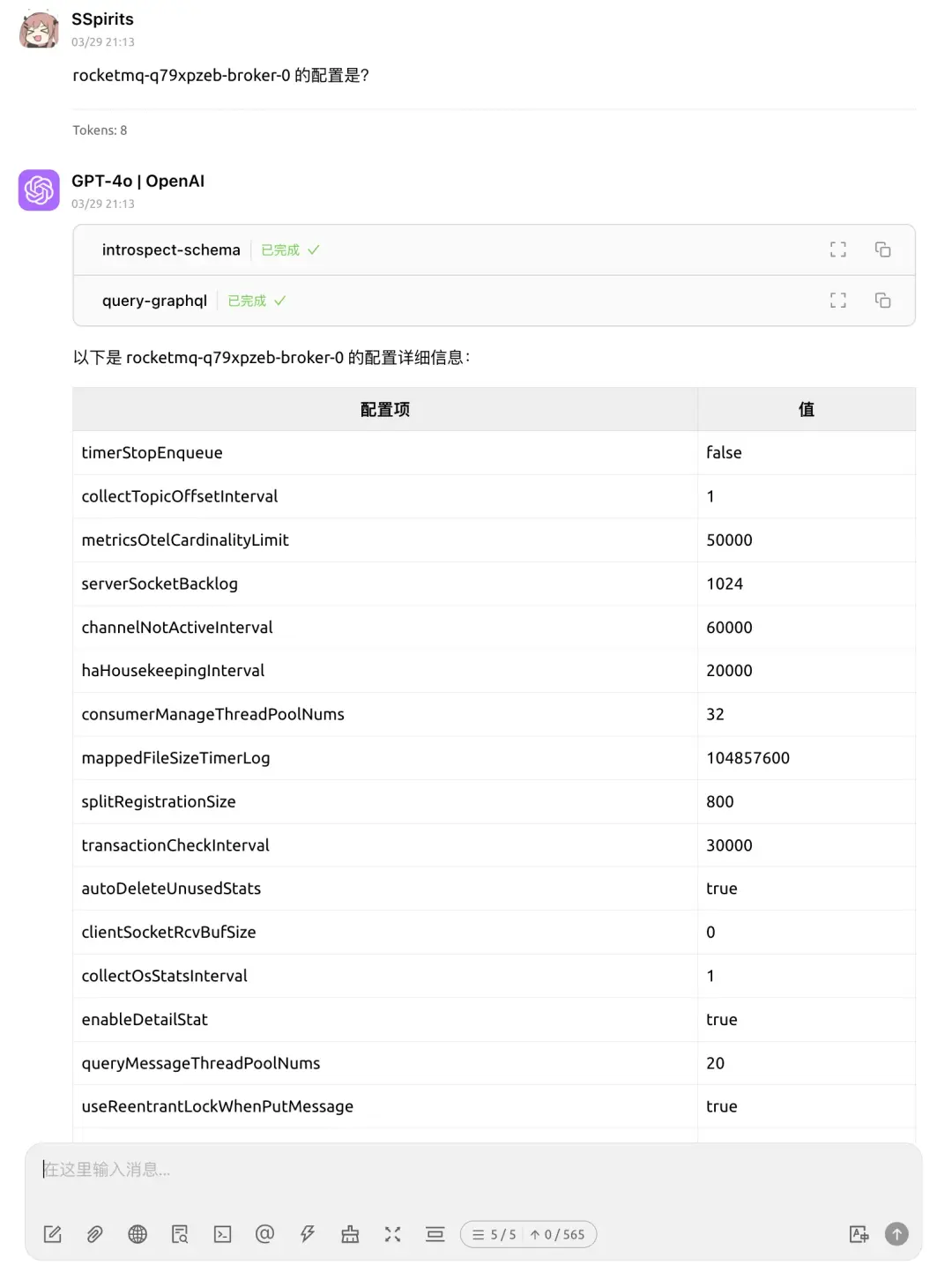
場景二:查詢主題信息
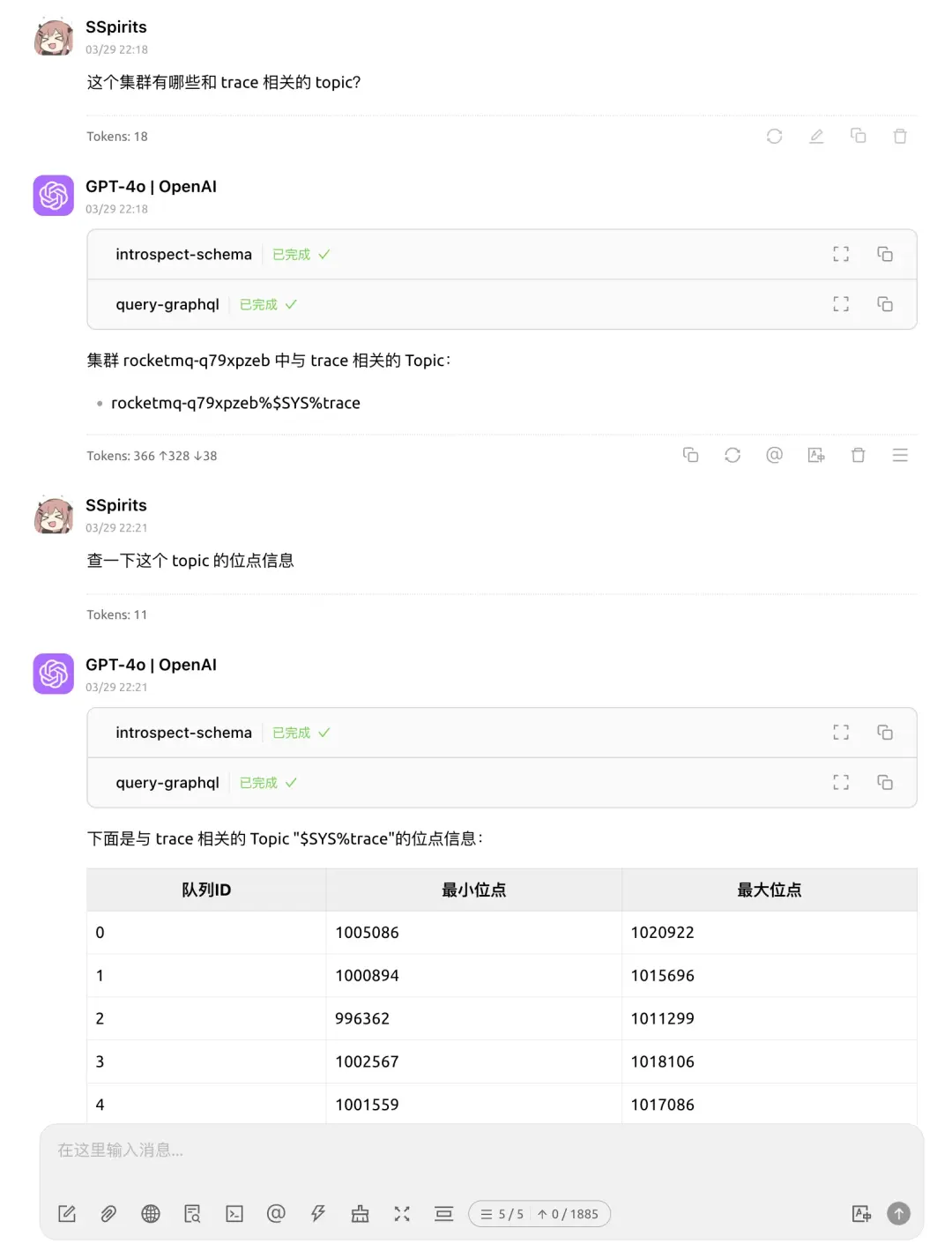
場景三:查詢消息軌跡
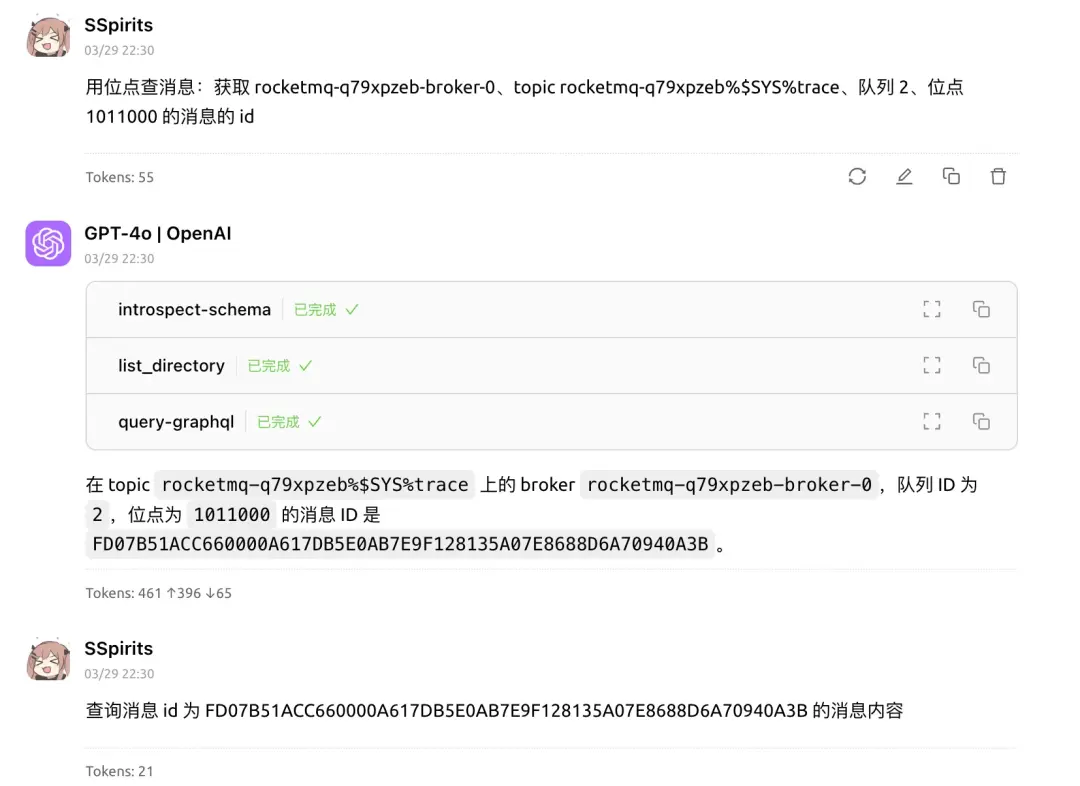
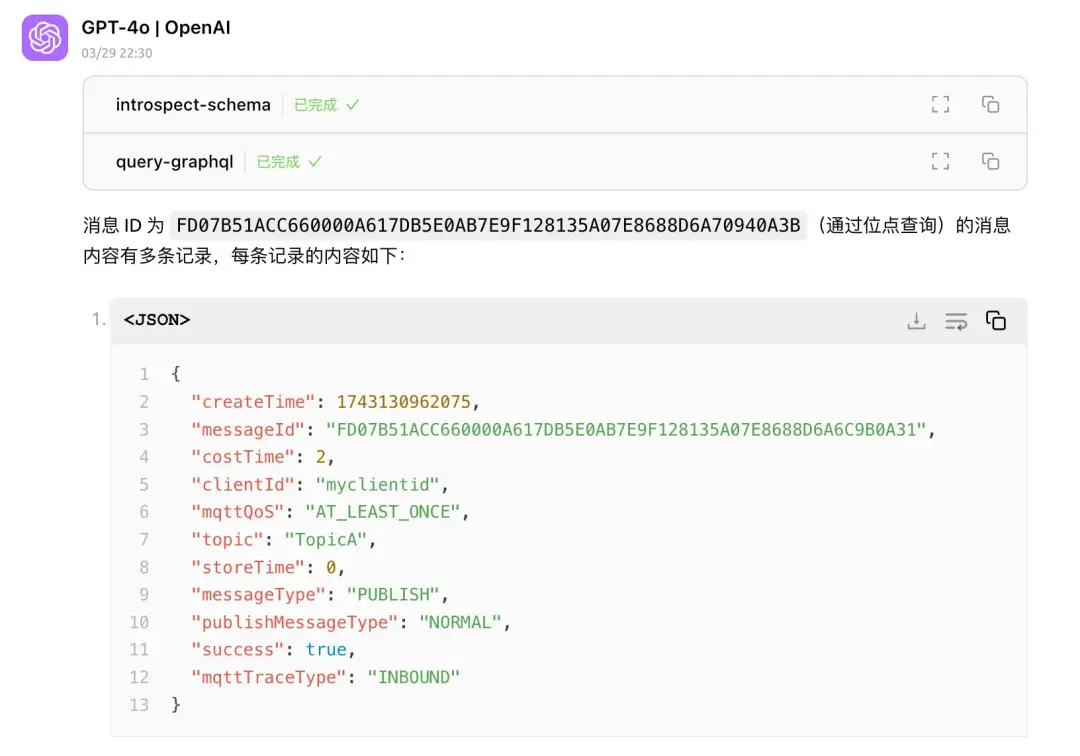
實現原理
LLM 大語言模型
在這個組合(LLM + Chatbox + MCP + GraphQL)中,LLM 充當了自然語言處理的核心組件。用户通過 Chatbox 輸入自然語言查詢,LLM 將其轉換為 GraphQL 查詢語句,並通過 MCP (大模型調用工具的協議,這裏可以認為是 GraphQL 客户端)提交到後端服務。後端服務返回的 JSON 格式查詢結果又會被 LLM 轉換為人類更易懂的格式,從而實現了自然語言與數據源之間的高效交互。
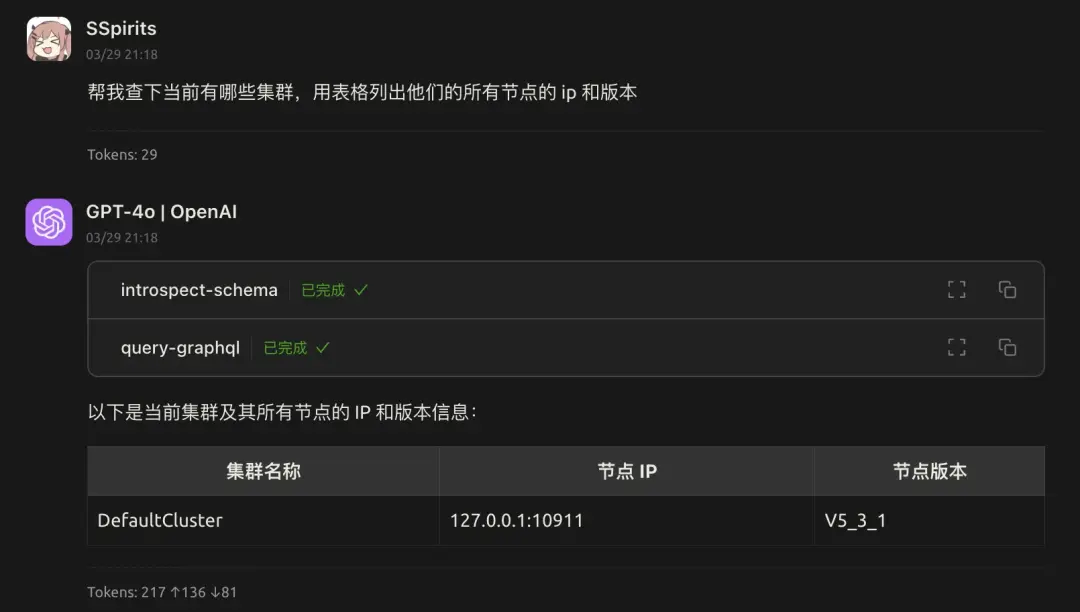
圖中的 introspect-schema 用來獲取 GraphQL 的 schema 信息,幫助 LLM 理解數據結構和字段。
實際上只需要在開始對話的時候調用一次即可,這裏每次交互都調用是因為博主使用的 Chatbox 沒有正確使用 MCP 協議,換成支持 MCP Resources 的工具例如 Claude Desktop 就可以避免多次請求 schema。
通過 LLM 來組織查詢相比於傳統的運營系統,可以節約開發大量頁面的成本,能夠按需獲取想要查詢的字段,並且自適應數據結構的演進。為了最大化利用 LLM 的查詢靈活性,我們引入了 GraphQL 作為數據查詢的中間層。

道理我都懂,為什麼是 GraphQL?
GraphQL 是一種用於提供 API 的查詢語言,它允許客户端指定所需的數據結構和字段。我們使用 GraphQL 作為連接 LLM 和所有數據源的橋樑: LLM 使用 GraphQL 描述要查詢的數據,在一次查詢中訪問多種數據源。
回憶一下本文開頭列出的多種數據源,我們取其中 Runtime Data 中的 RocketMQ Broker 數據源為例,它的數據模型大致如下所示:
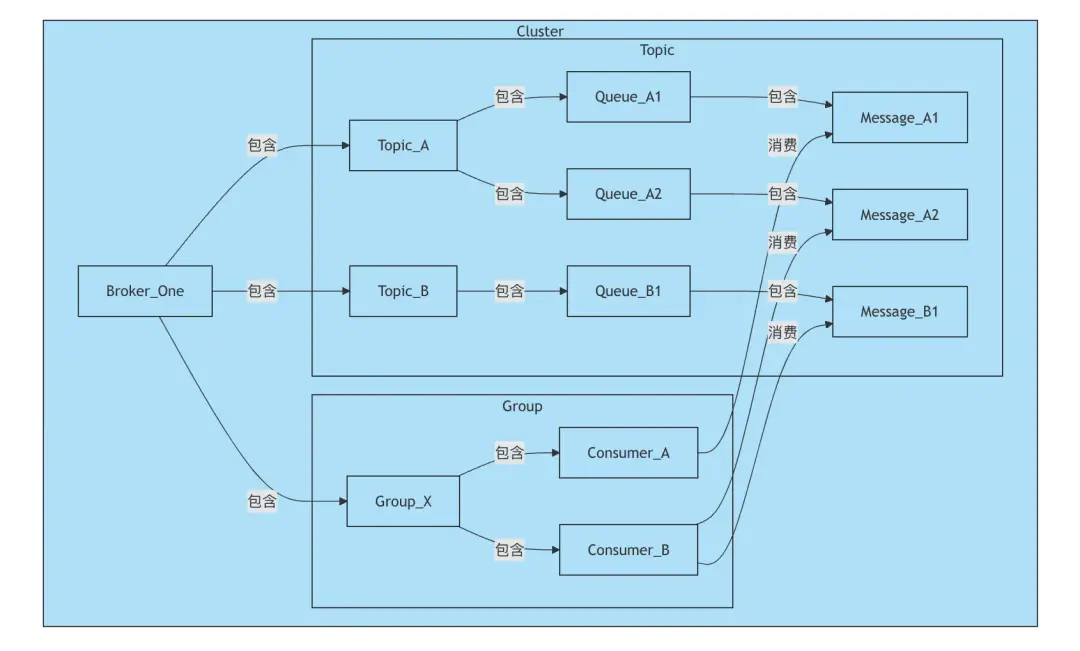
我們將這個數據模型組織成一個樹狀的結構,GraphQL 的查詢語法非常適合這種樹狀結構的查詢:可以通過 GraphQL 的嵌套查詢來獲取 Broker、Topic、Queue 和 Message 之間的關係。
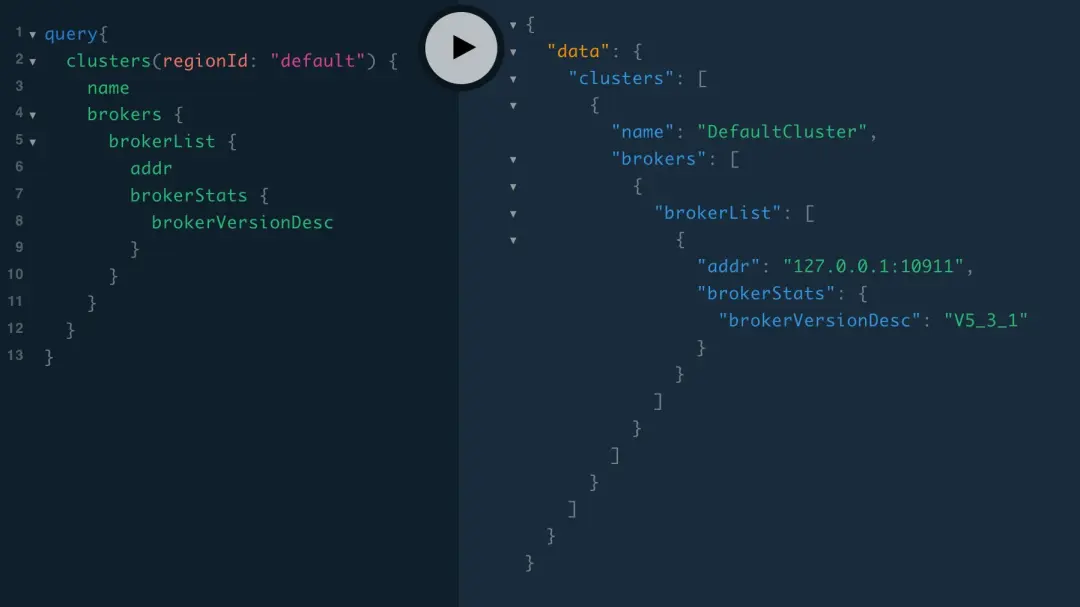
例如,我們可以通過以下的 GraphQL 查詢語句來獲取 Broker\_One 中 Topic\_A 的隊列 0 的相關信息:
query {
# 查詢 Broker節點 Broker_One
brokers(name: "Broker_One") {
# 查詢該 Broker 節點的接入點
addr
# 查詢 Broker 節點的配置項 messageIndexEnable
config(name: "messageIndexEnable") {
name
value
}
# 查詢該 Broker 節點的 Topic 信息:Topic_A
topics(name: "Topic_A") {
# 查詢該 Topic 的隊列 0
queues(id: 0) {
# 查詢該隊列的消息數(maxOffset - minOffset)
minOffset
maxOffset
# 查詢該隊列的第 100 條消息
messages(offset: 100) {
id
payload
}
}
}
}
}這個查詢會被翻譯成對 RocketMQ Broker 數據源以下接口的調用:
- Broker 信息(接入點)
- Broker 配置項(messageIndexEnable)
- Topic 信息(隊列數)
- Topic 隊列的信息(minOffset、maxOffset)
- Topic 的消息(該隊列第 100 條消息)
也就是説,我們通過 GraphQL 的嵌套查詢語法將 5 個查詢組合在一起。上面只是一個簡單的例子,實際上可以組合面向不同數據源的查詢。不管他們提供的是 REST API 還是 Binary Protocol 都可以合併到一個 GraphQL 查詢中。對於 LLM 來説這樣做尤其有意義:
簡化開發:不需要為每種數據源編寫單獨的 MCP Server,統一使用 GraphQL 作為數據查詢的中間層,用 GraphQL 的 schema 來幫助 LLM 理解數據結構。
簡化查詢:LLM 只需要理解 GraphQL 的查詢語法,而不需要了解每個數據源的具體實現細節。對於複雜的查詢可以有效降低 LLM 的理解難度,減少出錯的概率。
減少查詢次數:通過一次 GraphQL 查詢,可以獲取多個數據源的信息,減少了多次 LLM 調用的 Token 開銷。
降低上下文開銷:不需要組織多次查詢,也不需要輸入多種 MCP tools 的參數和用法。可以將 LLM 有限的上下文用於描述問題的本質。
靈活變更數據結構:GraphQL 自帶 schema,對於 LLM 來説可以通過 schema 來獲取數據的字段和不同數據結構之間的關係。簡而言之我們提供的查詢接口是自描述的,可以隨時增加新的數據結構,LLM 也能自動適應。
總結與後續展望
通過 LLM + Chatbox + MCP + GraphQL 的組合,我們實現了對多個異構數據源的高效查詢。用户不需要具備大量的排查經驗和對系統的深入理解,只需要用自然語言描述所需的信息,系統就能自動生成查詢語句並返回結果。這種方式不僅提高了排查問題效率,還降低了對運維人員的技術要求。
目前我們實現了 LLM 高效訪問數據,並且通過 GraphQL 的 Schema 能夠理解多種數據結構之間的關聯。下一步我們將繼續迭代這個系統,將我們問題排查的專家經驗以知識庫的形式輸入到 LLM 中,不僅能幫助 LLM 理解數據,更能理解問題的本質,最終實現一個一站式問題排查系統,讓 LLM 能夠自動化地完成問題排查的工作。
後續騰訊雲消息隊列團隊會將這套 MCP Server 方案貢獻到 Apache RocketMQ 社區,致力於與 RocketMQ 社區共建 MCP 標準,共同打造業內最好的業務消息中間件。