

我們在學習機器學習算法時,往往會被各種枯燥的數學公式所勸退。
今天,我將嘗試用結合實際生活的方式,來介紹一個非常經典,而且可能是最“懂你心意”的算法——決策樹 (Decision Tree)。。
別被這個術語嚇到了,其實你每天點外賣的時候都在用它。
想象一下,下午三點,你站在奶茶店門口(或者打開了外賣App),面對眼花繚亂的菜單,你的大腦為了保護你的體重,立刻啓動了一個“決策樹”程序:
- 這杯奶茶含糖嗎? -> 如果是全糖 -> 不喝,會胖死 ❌。
- -> 如果是無糖 -> 再看看。
- 加沒加小料? -> 沒加? -> 沒靈魂,不喝 ❌。
- -> 加了波霸/珍珠? -> 完美!買它! ✅
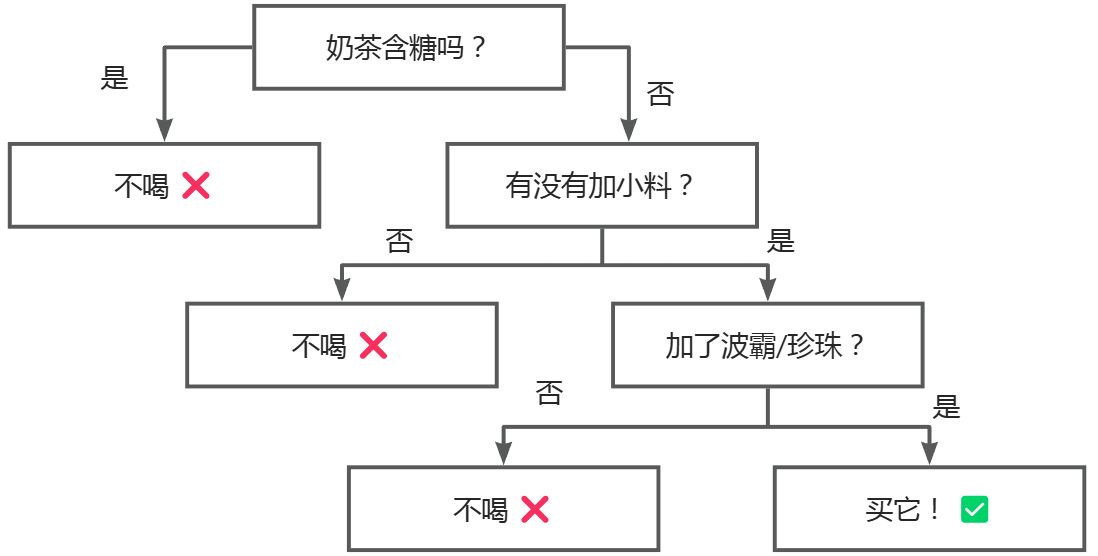
看,這就是一棵決策樹!把你腦海裏糾結的過程畫下來,它就是一個倒立的樹狀流程圖。
但在機器學習裏,我們不是自己畫圖,而是讓計算機通過學習歷史訂單數據,自己總結出這套“點單秘籍”。
它是怎麼做到的?別急,我們要用幾杯奶茶來教會你。🧋
🌲 第一部分:解剖決策樹
在深入之前,咱們先對齊一下 “行話”。雖然它叫樹,但在計算機科學裏,這棵樹通常是倒着長的(根在上面,葉子在下面)。
- 根節點 (
Root Node): 樹的最頂端。也就是最關鍵的那個問題(比如:甜度是多少?)。 - 決策節點 (
Decision Node): 中間的那些站點,負責根據某個特徵(比如小料、冷熱)把數據分流。 - 葉節點 (
Leaf Node): 樹的末端。到了這裏,不再問問題了,直接給出最終判決(比如:喝! 或者 快逃!)。
🧠 第二部分:樹是怎麼“長”出來的?
這才是最迷人的地方。如果你給模型一堆奶茶數據,它怎麼知道先看“甜度”還是先看“價格”?
這就涉及到兩個超級重要的概念:熵 (Entropy) 和 信息增益 (Information Gain)。
1. 什麼是熵 (Entropy)?
物理學裏説熵代表混亂程度。在決策樹裏,熵代表數據的 “不純度”(你也可以理解為** “糾結程度” **)。
- 場景 A: 你面前有10杯奶茶,全是無糖波霸奶茶。這數據太純了,熵 = 0。你閉着眼拿一杯都是你想喝的,完全不用糾結。
- 場景 B: 你面前有10杯奶茶,5杯是你最愛的無糖,5杯是甜到齁的全糖,混在一起。這太混亂了,熵 = 1(最高)。你完全猜不到下一杯是不是“雷”。
機器學習的目標就是:通過問問題(分裂),讓數據的熵越來越小,直到變成 0(完全純淨)。
2. 信息增益 (Information Gain)
這就是我們的 “篩選標準”。
- 信息增益 = 分裂前的熵 - 分裂後的熵
簡單説:如果我按“甜度”分,能讓這堆數據變得多“乾淨”? 哪個問題能幫我排除掉最多的干擾項,我們就選哪個問題當老大(根節點)!
📊 第三部分:手動算一算 (奶茶案例)
假設我們收集了你過去買的50次奶茶記錄,你的口味偏好非常明顯:只喝無糖。
數據分佈如下:
- 全糖:
25杯 -> 結果全是 不喝 (❌) - 無糖:
25杯 -> 結果是 喝 (✅)
我們要決定:先按“甜度”分,還是先按“加沒加冰”分?
方案一:按“甜度”切一刀 🔪
- 左邊(全糖堆): 25杯全是❌。完美!這堆數據的熵直接變成0了!(不用再問別的了,直接扔掉)。
- 右邊(無糖堆): 25杯全是✅。完美!熵也是0!
方案二:按“加冰”切一刀 🧊
假設全糖和無糖裏都有加冰和去冰的情況。
- 左邊(加冰堆): 混雜着全糖(❌)和無糖(✅)。還是很亂,熵很高。
- 右邊(去冰堆): 同樣混雜。
很明顯,按甜度分的信息增益最大,因為它能幫我們瞬間把“絕對不喝”的那部分挑出來。
所以,機器會選擇 甜度 作為根節點!
💻 第四部分:Python 代碼實戰
光説不練假把式。作為工程師,我們要用代碼説話。我們會使用 Python 的 scikit-learn 庫。
假設我們整理好了數據 milktea.csv:
| Sugar (甜度) | Topping (小料) | Decision (喝嗎?) |
|---|---|---|
| Full (全糖) | Pearls (珍珠) | 0 (No) |
| Zero (無糖) | None (無) | 0 (No - 太寡淡) |
| Zero (無糖) | Pearls (珍珠) | 1 (Yes) |
| ... | ... | ... |
1. 預處理與訓練
機器看不懂中文或單詞,我們要把它翻譯成數字。
import pandas as pd
from sklearn import tree
import matplotlib.pyplot as plt
# 1. 模擬一點奶茶數據
# 假設我們的邏輯是:只有"無糖(Zero)"且"加珍珠(Pearls)"才喝
data = pd.DataFrame({
'Sugar': ['Full', 'Zero', 'Full', 'Zero', 'Half', 'Zero'],
'Topping': ['Pearls', 'None', 'None', 'Pearls', 'Pearls', 'Pudding'],
'Drink': [0, 0, 0, 1, 0, 1] # 1=喝, 0=不喝 (假設只要是無糖且有小料就喝)
})
# 2. 數據預處理:把文字變成數字 (Mapping)
# 甜度: Full=0, Zero=1, Half=2
# 小料: Pearls=0, None=1, Pudding=2
data['Sugar_Code'] = data['Sugar'].map({'Full': 0, 'Zero': 1, 'Half': 2})
data['Topping_Code'] = data['Topping'].map({'Pearls': 0, 'None': 1, 'Pudding': 2})
features = ['Sugar_Code', 'Topping_Code']
X = data[features]
Y = data['Drink']
# 3. 訓練模型
# criterion='entropy' 表示我們使用“熵”來作為分裂標準
clf = tree.DecisionTreeClassifier(criterion='entropy')
clf = clf.fit(X, Y)
print("🤖 奶茶鑑定模型訓練完畢!")
2. 可視化這棵樹
讓我們看看機器腦子裏想的圖長什麼樣。
# 4. 畫出決策樹
plt.figure(figsize=(10,6))
tree.plot_tree(clf,
feature_names=['Sugar', 'Topping'],
class_names=['Pass', 'Drink'], # Pass=不喝, Drink=喝
filled=True, # 顏色越深代表機器越確信
rounded=True)
plt.show()
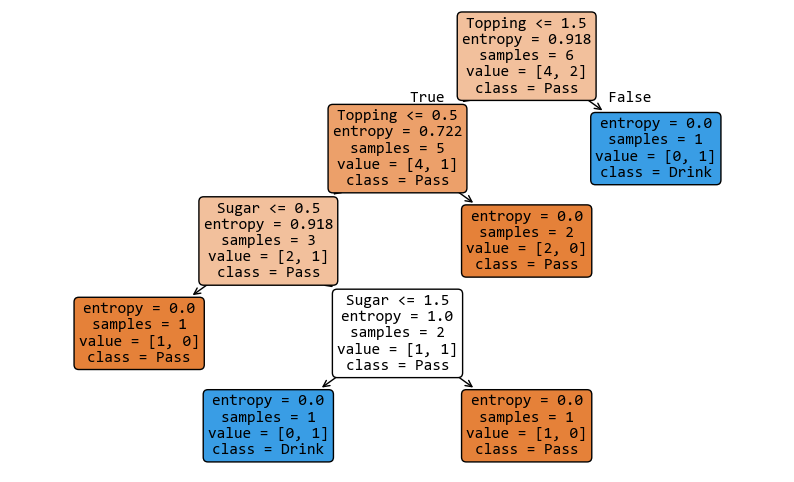
3. 預測新數據
這時候,老闆推出了一款新品:無糖 + 珍珠。你要不要嚐嚐?
- 無糖 = 1
- 珍珠 = 0
# 預測 [Sugar=1, Topping=0]
new_tea = [[1, 0]]
prediction = clf.predict(new_tea)
if prediction[0] == 1:
print("決策結果:買它!🧋😋")
else:
print("決策結果:噠咩!❌")
## 運行結果:
'''
決策結果:買它!🧋😋
'''
🚀 總結
今天我們通過一杯奶茶學習了:
- 決策樹就是一套幫你做選擇的“流程圖”。
- 機器利用熵(亂不亂)和信息增益(變乾淨了嗎)來尋找最佳的篩選條件。
- 用
scikit-learn幾行代碼就能搞定。
機器學習其實離生活很近。希望這棵“樹”能幫你不僅選對模型,還能選對最適合你的那杯下午茶!