

想象一下夏日的花叢中,成羣的蜜蜂圍繞着花朵忙碌地飛舞。每隻蜜蜂都是一個獨立的數據點,它們既保持羣體聚集的形態,又不會完全重疊在一起。
這就是蜂羣圖(Swarm Plot)的核心理念——在有限的空間內展示所有數據點,讓每個點都能被清晰看見。
蜂羣圖是一種特殊的數據可視化圖表,它將分類數據與數值數據結合起來,展示數據的分佈情況。
與傳統的條形圖或箱線圖不同,蜂羣圖不進行任何數據聚合,而是展示每一個原始數據點,避免了信息丟失。
1. 蜂羣圖核心特點
蜂羣圖最巧妙的地方在於它的佈局算法。
當多個數據點具有相似數值時,它們不會簡單地重疊在一起,而是像有“排斥力”一樣,在垂直方向(或水平方向)上輕微偏移,形成一個類似蜂羣的分佈。
比如,下面是同一組數據在散點圖和蜂羣圖中展示的效果。
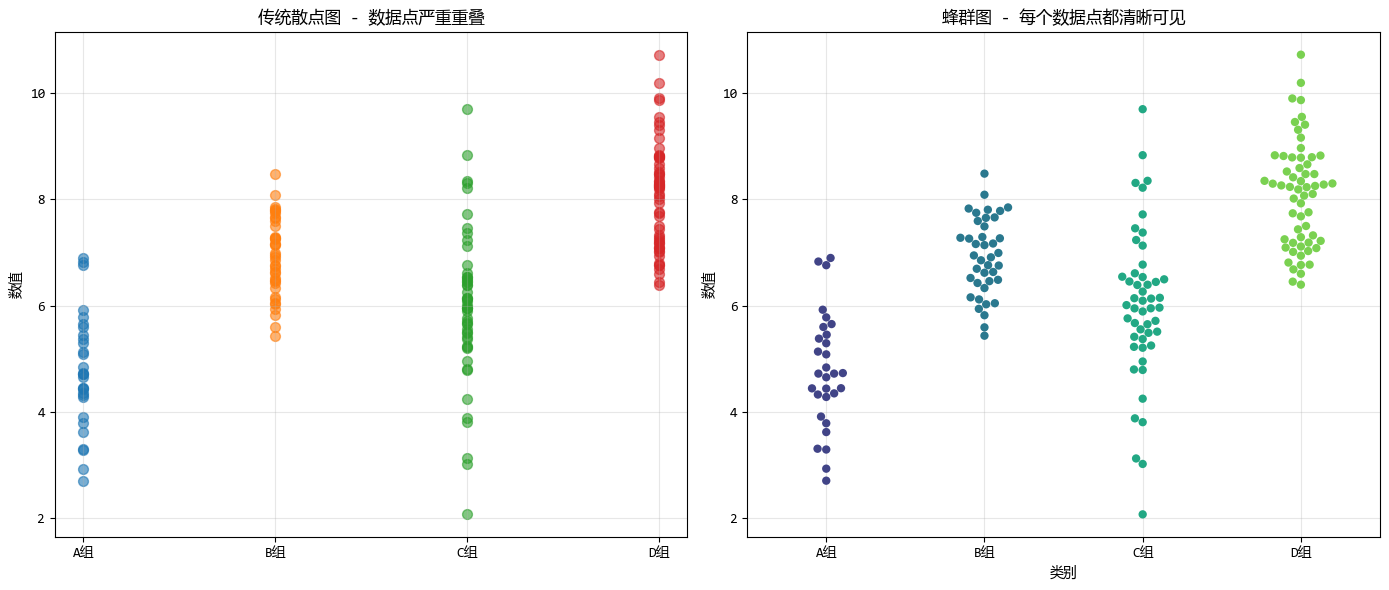
從中可以看出蜂羣圖的核心特點有:
- 絕不重疊: 它通過算法檢測數據點的重疊情況,一旦發現兩個點數值相近,就會自動把它們向水平方向推開。
- 保留分佈形態: 散開後的形狀,天然形成了一種類似“小提琴”或“山峯”的輪廓,直觀地展示了數據的密度。
- 參數調整: 我們可以調整點的大小(marker size)和排列的緊密程度。點越大,視覺衝擊力越強,但需要的水平空間也越多。
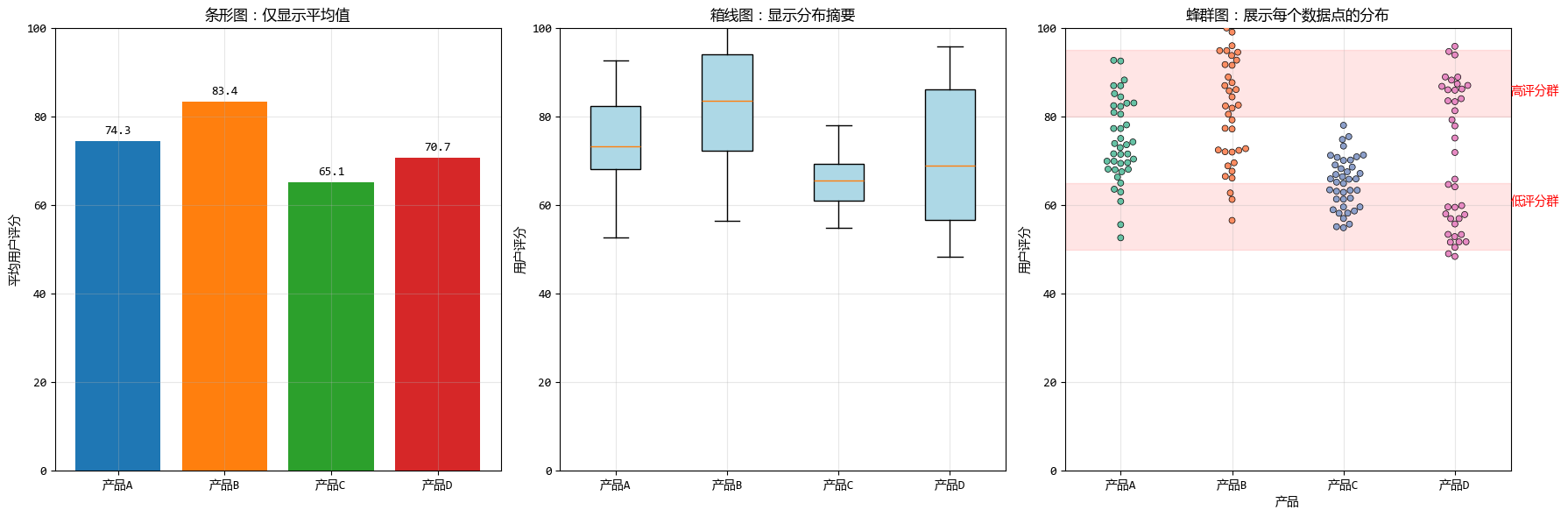
2. 蜂羣圖 vs. 條形圖:從摘要到細節
條形圖就像是一份數據摘要報告,它告訴我們每個類別的平均值或總計值,但隱藏了數據內部的分佈細節。
而蜂羣圖則像是一次數據點的全員大會,每個數據點都有發言的機會。
下面針對同一組數據,我們分別繪製了條形圖、箱線圖和蜂羣圖,一起來感受一下它們之間不同的展示效果。
# 生成示例數據
np.random.seed(123)
categories = ["產品A", "產品B", "產品C", "產品D"]
data_comparison = []
for category in categories:
n_points = 40
if category == "產品A":
values = np.random.normal(75, 8, n_points)
elif category == "產品B":
values = np.random.normal(82, 12, n_points)
elif category == "產品C":
values = np.random.normal(65, 5, n_points)
else: # 產品D
# 創建一個雙峯分佈
values1 = np.random.normal(55, 6, n_points // 2)
values2 = np.random.normal(85, 7, n_points // 2)
values = np.concatenate([values1, values2])
for value in values:
data_comparison.append({"產品": category, "用户評分": value})
# 1. 條形圖(平均值)
means = []
for category in categories:
cat_data = [d["用户評分"] for d in data_comparison if d["產品"] == category]
means.append(np.mean(cat_data))
bars = axes[0].bar(
categories, means, color=["#1f77b4", "#ff7f0e", "#2ca02c", "#d62728"]
)
# 在條形上標註平均值
# 省略...
# 2. 箱線圖
box_data = []
for category in categories:
cat_data = [d["用户評分"] for d in data_comparison if d["產品"] == category]
box_data.append(cat_data)
boxplot = axes[1].boxplot(
box_data, tick_labels=categories, patch_artist=True, boxprops=dict(facecolor="lightblue")
)
# 省略...
# 3. 蜂羣圖
data_df = pd.DataFrame(data_comparison)
sns.swarmplot(
x="產品",
y="用户評分",
hue="產品",
data=data_df,
ax=axes[2],
size=5,
palette="Set2",
edgecolor="black",
linewidth=0.5,
)
# 省略...
plt.tight_layout()
plt.show()
繪製蜂羣圖可以用seaborn這個庫中的swarmplot函數。
從上面的對比可以看出:
- 條形圖告訴我們產品D的平均分約為70分
- 箱線圖提示產品D的數據分佈範圍很廣
- 但只有蜂羣圖清晰地揭示了產品D實際上有兩個明顯的用户羣體:一個低評分羣體和一個高評分羣體
3. 蜂羣圖 vs. 散點圖:從混亂到有序
傳統散點圖在處理分類數據時,常常導致數據點大量重疊,形成"黑團",我們無法看清數據點的真實分佈。
蜂羣圖通過智能佈局算法解決了這個問題。
下面構造一個不同密度的數據,看看蜂羣圖和散點圖的展示效果。
# 比較散點圖與蜂羣圖的視覺效果
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# 生成具有不同密度的數據
np.random.seed(42)
density_data = []
categories = ["低密度", "中等密度", "高密度"]
for i, category in enumerate(categories):
n_points = 20 + i * 30 # 不同密度
if category == "低密度":
values = np.random.normal(50, 15, n_points)
elif category == "中等密度":
values = np.random.normal(50, 8, n_points)
else: # 高密度
values = np.random.normal(50, 4, n_points)
for value in values:
density_data.append({"類別": category, "數值": value})
# 左側:傳統散點圖
for i, category in enumerate(categories):
cat_data = [d["數值"] for d in density_data if d["類別"] == category]
x_positions = np.full(len(cat_data), i)
axes[0].scatter(x_positions, cat_data, alpha=0.6, s=60, label=category)
#省略...
# 右側:蜂羣圖
density_data_df = pd.DataFrame(density_data)
sns.swarmplot(
x="類別",
y="數值",
hue="類別",
data=density_data_df,
ax=axes[1],
size=6,
palette="coolwarm",
edgecolor="black",
linewidth=0.5,
)
#省略...
plt.tight_layout()
plt.show()
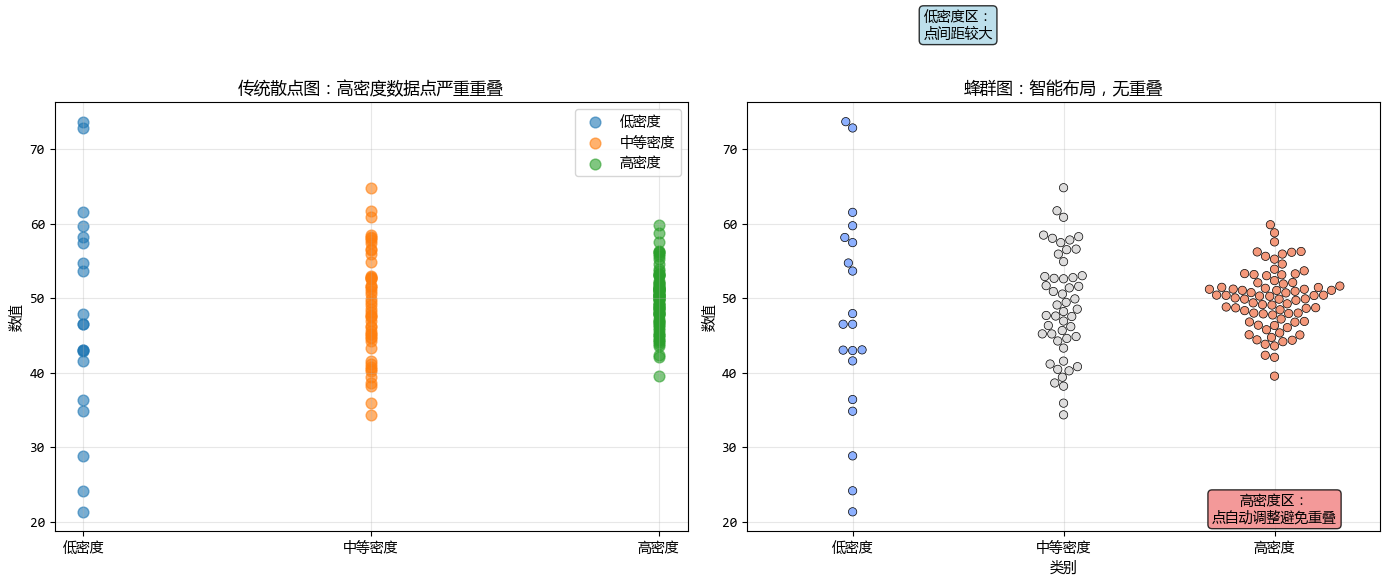
蜂羣圖解決了 “重疊(Overplotting)” 的問題。在數據量適中(幾百到幾千個點)時,它是展示分佈密度的最佳選擇。
4. 蜂羣圖的適用場景
蜂羣圖並不是為了取代條形圖或散點圖,它有自己的適用場景和侷限性。
適合使用蜂羣圖的場景:
- 樣本量適中(通常少於幾百個點)時,展示完整數據分佈
- 需要同時看到整體趨勢和個體數據點
- 數據有多個分類變量,需要比較不同類別分佈
- 希望發現異常值或特殊模式(如雙峯分佈)
蜂羣圖的侷限性主要有:
- 大數據集可能導致圖表過於擁擠
- 對於非常大規模數據,箱線圖或小提琴圖可能更合適
- 精確的數值比較不如條形圖直觀
5. 總結
蜂羣圖就像數據可視化領域的"顯微鏡",它讓我們既能觀察到數據的整體分佈形態,又能看到每一個數據點的具體位置。
與只能顯示摘要信息的條形圖和容易產生重疊的散點圖相比,蜂羣圖在顯示中小型數據集的完整分佈信息方面具有獨特優勢。
在數據可視化實踐中,選擇正確的圖表類型就像選擇正確的工具一樣重要。
當下一次你需要展示分類數據的分佈時,不妨嘗試一下蜂羣圖,它可能會揭示出你從未注意到的數據秘密。
文中的完整代碼共享在:蜂羣圖.ipynb (訪問密碼: 6872)