









作者:vivo 互聯網大數據團隊- Chen Jianbo
本文是《vivo Pulsar萬億級消息處理實踐》系列文章第3篇。
Pulsar是Apache基金會的開源分佈式流處理平台和消息中間件,它實現了Kafka的協議,可以讓使用Kafka API的應用直接遷移至Pulsar,這使得Pulsar在Kafka生態系統中更加容易被接受和使用。KoP提供了從Kafka到Pulsar的無縫轉換,用户可以使用Kafka API操作Pulsar集羣,保留了Kafka的廣泛用户基礎和豐富生態系統。它使得Pulsar可以更好地與Kafka進行整合,提供更好的消息傳輸性能、更強的兼容性及可擴展性。vivo在使用Pulsar KoP的過程中遇到過一些問題,本篇主要分享一個分區消費指標缺失的問題。
系列文章:
- vivo Pulsar萬億級消息處理實踐(1)-數據發送原理解析和性能調優
- vivo Pulsar萬億級消息處理實踐(2)-從0到1建設Pulsar指標監控鏈路
文章太長?1分鐘看圖抓住核心觀點👇

一、問題背景
在一次版本灰度升級中,我們發現某個使用KoP的業務topic的消費速率出現了顯著下降,具體情況如下圖所示:
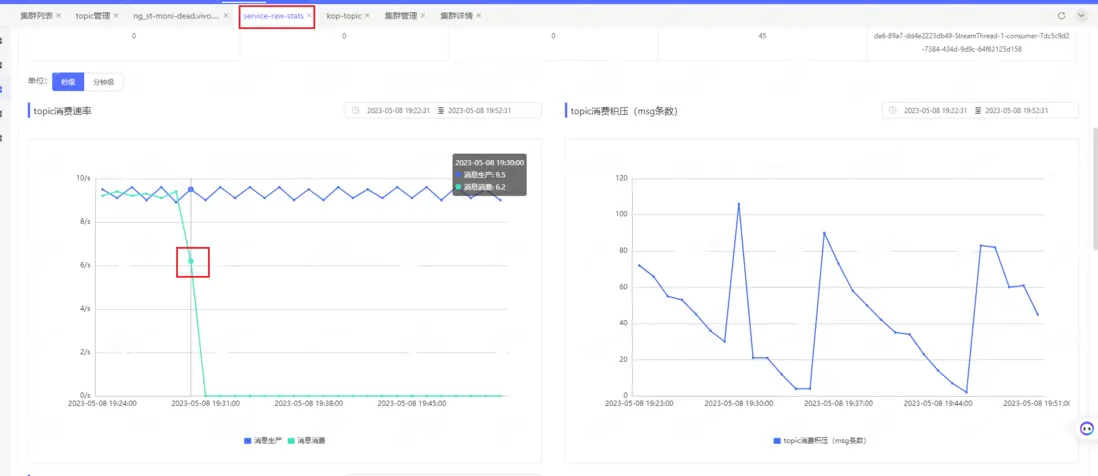
什麼原因導致正常的升級重啓服務器會出現這個問題呢?直接查看上報採集的數據報文:
kop_server_MESSAGE_OUT{group="",partition="0",tenant="kop",topic="persistent://kop-tenant/kop-ns/service-raw-stats"} 3
kop_server_BYTES_OUT{group="",partition="0",tenant="kop",topic="persistent://kop-tenant/kop-ns/service-raw-stats"} 188
我們看到,KoP消費指標kop\_server\_MESSAGE
\_OUT、kop\_server\_BYTES\_OUT是有上報的,但指標數據裏的group標籤變成了空串(缺少消費組名稱),分區的消費指標就無法展示了。是什麼原因導致了消費組名稱缺失?
二、問題分析
1、找到問題代碼
我們去找下這個消費組名稱是在哪裏獲取的,是否邏輯存在什麼問題。根據druid中的kop\_subscription對應的消費指標kop\_server_
MESSAGE\_OUT、kop\_server\_BYTES\_OUT,找到相關代碼如下:
private void handleEntries(final List<Entry> entries,
final TopicPartition topicPartition,
final FetchRequest.PartitionData partitionData,
final KafkaTopicConsumerManager tcm,
final ManagedCursor cursor,
final AtomicLong cursorOffset,
final boolean readCommitted) {
....
// 處理消費數據時,獲取消費組名稱
CompletableFuture<String> groupNameFuture = requestHandler
.getCurrentConnectedGroup()
.computeIfAbsent(clientHost, clientHost -> {
CompletableFuture<String> future = new CompletableFuture<>();
String groupIdPath = GroupIdUtils.groupIdPathFormat(clientHost, header.clientId());
requestHandler.getMetadataStore()
.get(requestHandler.getGroupIdStoredPath() + groupIdPath)
.thenAccept(getResultOpt -> {
if (getResultOpt.isPresent()) {
GetResult getResult = getResultOpt.get();
future.complete(new String(getResult.getValue() == null
? new byte[0] : getResult.getValue(), StandardCharsets.UTF_8));
} else {
// 從zk節點 /client_group_id/xxx 獲取不到消費組,消費組就是空的
future.complete("");
}
}).exceptionally(ex -> {
future.completeExceptionally(ex);
return null;
});
returnfuture;
});
// this part is heavyweight, and we should not execute in the ManagedLedger Ordered executor thread
groupNameFuture.whenCompleteAsync((groupName, ex) -> {
if (ex != null) {
log.error("Get groupId failed.", ex);
groupName = "";
}
.....
// 獲得消費組名稱後,記錄消費組對應的消費指標
decodeResult.updateConsumerStats(topicPartition,
entries.size(),
groupName,
statsLogger);
代碼的邏輯是,從requestHandler的currentConnectedGroup(map)中通過host獲取groupName,不存在則通過MetadataStore(帶緩存的zk存儲對象)獲取,如果zk緩存也沒有,再發起zk讀請求(路徑為/client\_group\_id/host-clientId)。讀取到消費組名稱後,用它來更新消費組指標。從復現的集羣確定走的是這個分支,即是從metadataStore(帶緩存的zk客户端)獲取不到對應zk節點/client\_group\_id/xxx。
2、查找可能導致zk節點/client\_group\_id/xxx節點獲取不到的原因
有兩種可能性:一是沒寫進去,二是寫進去但是被刪除了。
@Override
protected void handleFindCoordinatorRequest(KafkaHeaderAndRequest findCoordinator,
CompletableFuture<AbstractResponse> resultFuture) {
...
// Store group name to metadata store for current client, use to collect consumer metrics.
storeGroupId(groupId, groupIdPath)
.whenComplete((stat, ex) -> {
if (ex != null) {
// /client_group_id/xxx節點寫入失敗
log.warn("Store groupId failed, the groupId might already stored.", ex);
}
findBroker(TopicName.get(pulsarTopicName))
.whenComplete((node, throwable) -> {
....
});
});
...
從代碼看到,clientId與groupId的關聯關係是通過handleFindCoordinatorRequest(FindCoordinator)寫進去的,而且只有這個方法入口。由於沒有找到warn日誌,排除了第一種沒寫進去的可能性。看看刪除的邏輯:
protected void close(){
if (isActive.getAndSet(false)) {
...
currentConnectedClientId.forEach(clientId -> {
String path = groupIdStoredPath + GroupIdUtils.groupIdPathFormat(clientHost, clientId);
// 刪除zk上的 /client_group_id/xxx 節點
metadataStore.delete(path, Optional.empty())
.whenComplete((__, ex) -> {
if (ex != null) {
if (ex.getCause() instanceof MetadataStoreException.NotFoundException) {
if (log.isDebugEnabled()) {
log.debug("The groupId store path doesn't exist. Path: [{}]", path);
}
return;
}
log.error("Delete groupId failed. Path: [{}]", path, ex);
return;
}
if (log.isDebugEnabled()) {
log.debug("Delete groupId success. Path: [{}]", path);
}
});
});
}
}
刪除是在requsetHandler.close方法中執行,也就是説連接斷開就會觸發zk節點刪除。
但有幾個疑問:
- /client\_group\_id/xxx 到底是幹嘛用的?消費指標為什麼要依賴它
- 為什麼要在handleFindCoordinatorRequest寫入?
- 節點/client\_group\_id/xxx為什麼要刪除,而且是在連接斷開時刪除,刪除時機是否有問題?
首先回答第1個問題,通過閲讀代碼可以知道,/client\_group\_id/xxx 這個zk節點是用於在不同broker實例間交換數據用的(相當redis cache),用於臨時存放IP+clientId與groupId的映射關係。由於fetch接口(拉取數據)的request沒有groupId的,只能依賴加入Group過程中的元數據,在fetch消費時才能知道當前拉數據的consumer是哪個消費組的。
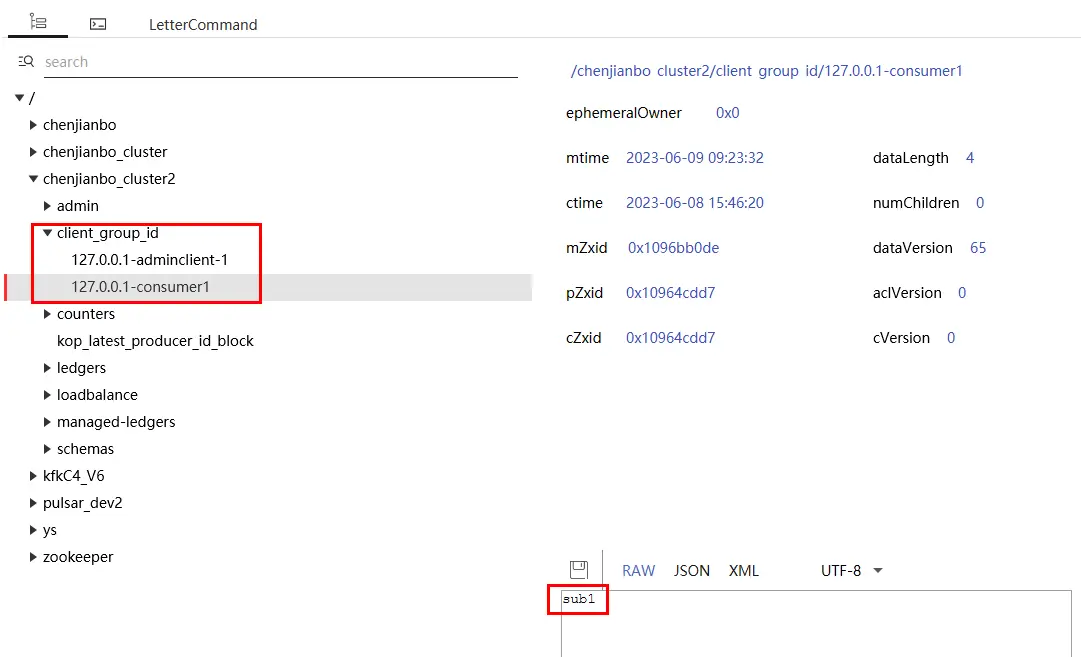
3、復現
若要解決問題,最好能夠穩定地復現出問題,這樣才能確定問題的根本原因,並且確認修復是否完成。
因為節點是在requsetHandle.close方法中執行刪除,broker節點關閉會觸發連接關閉,進而觸發刪除。假設:客户端通過brokerA發起FindCoordinator請求,寫入zk節點/client_group
\_id/xxx,同時請求返回brokerB作為Coordinator,後續與brokerB進行joinGroup、syncGroup等交互確定消費關係,客户端在brokerA、brokerB、brokerC都有分區消費。這時重啓brokerA,分區均衡到BrokerC上,但此時/client\_group_id/xxx因關閉broker而斷開連接被刪除,consumer消費剛轉移到topic1-partition-1的分區就無法獲取到groupId。
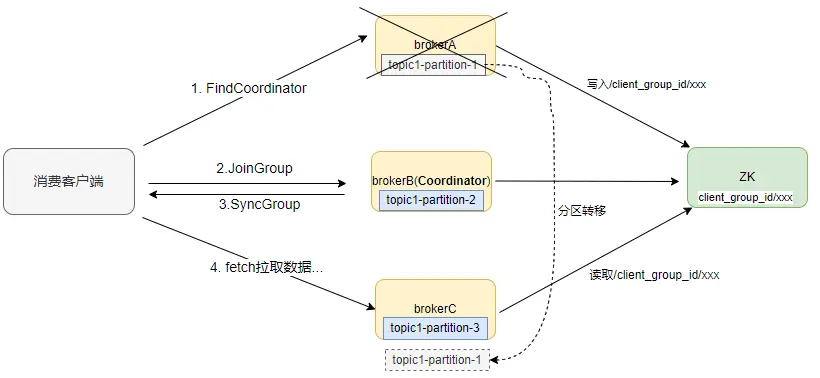
按照假設,有3個broker,開啓生產和消費,通過在FindCoordinator返回前獲取node.leader()的返回節點BrokerB,關閉brokerA後,brokerC出現斷點復現,再關閉brokerC,brokerA也會復現(假設分區在brokerA與brokerC之間轉移)。

復現要幾個條件:
- broker數量要足夠多(不小於3個)
- broker內部有zk緩存metadataCache默認為5分鐘,可以把時間調小為1毫秒,相當於沒有cache
- findCoordinator返回的必須是其他broker的IP
- 重啓的必須是接收到findCoordinator請求那台broker,而不是真正的coordinator,這時會從zk刪除節點
- 分區轉移到其他broker,這時新的broker會重新讀取zk節點數據
到此,我們基本上清楚了問題原因:連接關閉導致zk節點被刪除了,別的broker節點需要時就讀取不到了。那怎麼解決?
三、問題解決
方案一
既然知道把消費者與FindCoordinator的連接進行綁定不合適的,那麼是否應該把FindCoordinator寫入zk節點換成由JoinGroup寫入,斷連即刪除。

consumer統一由Coordinator管理,由於FindCoordinator接口不一定是Coordinator處理的,如果換成由Coordinator處理的JoinGroup接口是否就可以了,這樣consumer斷開與Coordinator的連接就應該刪除數據。但實現驗證時卻發現,客户端在斷連後也不會再重連,所以沒法重新寫入zk,不符合預期。
方案二
還是由FindCoordinator寫入zk節點,但刪除改為GroupCoordinator監聽consumer斷開觸發。
因為consumer統一由Coordinator管理,它能監聽到consumer加入或者離開。GroupCoordinator的removeMemberAndUpdateGroup方法是coordinator對consumer成員管理。
private void removeMemberAndUpdateGroup(GroupMetadata group,
MemberMetadata member) {
group.remove(member.memberId());
switch (group.currentState()) {
case Dead:
case Empty:
return;
case Stable:
case CompletingRebalance:
maybePrepareRebalance(group);
break;
case PreparingRebalance:
joinPurgatory.checkAndComplete(new GroupKey(group.groupId()));
break;
default:
break;
}
// 刪除 /client_group_id/xxx 節點
deleteClientIdGroupMapping(group, member.clientHost(), member.clientId());
}
調用入口有兩個,其中handleLeaveGroup是主動離開,onExpireHeartbeat是超時被動離開,客户端正常退出或者宕機都可以調用removeMemberAndUpdateGroup方法觸發刪除。
public CompletableFuture<Errors> handleLeaveGroup(
String groupId,
String memberId
) {
return validateGroupStatus(groupId, ApiKeys.LEAVE_GROUP).map(error ->
CompletableFuture.completedFuture(error)
).orElseGet(() -> {
return groupManager.getGroup(groupId).map(group -> {
return group.inLock(() -> {
if (group.is(Dead) || !group.has(memberId)) {
return CompletableFuture.completedFuture(Errors.UNKNOWN_MEMBER_ID);
} else {
...
// 觸發刪除消費者consumer
removeMemberAndUpdateGroup(group, member);
return CompletableFuture.completedFuture(Errors.NONE);
}
});
})
....
});
}
void onExpireHeartbeat(GroupMetadata group,
MemberMetadata member,
long heartbeatDeadline) {
group.inLock(() -> {
if (!shouldKeepMemberAlive(member, heartbeatDeadline)) {
log.info("Member {} in group {} has failed, removing it from the group",
member.memberId(), group.groupId());
// 觸發刪除消費者consumer
removeMemberAndUpdateGroup(group, member);
}
return null;
});
}
但這個方案有個問題是,日誌運維關閉broker也會觸發一個onExpireHeartbeat事件刪除zk節點,與此同時客户端發現Coordinator斷開了會馬上觸發FindCoordinator寫入新的zk節點,但如果刪除晚於寫入的話,會導致誤刪除新寫入的節點。我們乾脆在關閉broker時,使用ShutdownHook加上shuttingdown狀態防止關閉broker時刪除zk節點,只有客户端斷開時才刪除。
這個方案修改上線半個月後,還是出現了一個客户端的消費指標無法上報的情況。後來定位發現,如果客户端因FullGC出現卡頓情況,客户端可能會先於broker觸發超時,也就是先超時的客户端新寫入的數據被後監聽到超時的broker誤刪除了。因為寫入與刪除並不是由同一個節點處理,所以無法在進程級別做併發控制,而且也無法判斷哪次刪除對應哪次的寫入,所以用zk也是很難實現併發控制。
方案三
其實這並不是新的方案,只是在方案二基礎上優化:數據一致性檢查。
既然我們很難控制好寫入與刪除的先後順序,我們可以做數據一致性檢查,類似於交易系統裏的對賬。因為GroupCoordinator是負責管理consumer成員的,維護着consumer的實時狀態,就算zk節點被誤刪除,我們也可以從consumer成員信息中恢復,重新寫入zk節點。
private void checkZkGroupMapping(){
for (GroupMetadata group : groupManager.currentGroups()) {
for (MemberMetadata memberMetadata : group.allMemberMetadata()) {
String clientPath = GroupIdUtils.groupIdPathFormat(memberMetadata.clientHost(), memberMetadata.clientId());
String zkGroupClientPath = kafkaConfig.getGroupIdZooKeeperPath() + clientPath;
// 查找zk中是否存在節點
metadataStore.get(zkGroupClientPath).thenAccept(resultOpt -> {
if (!resultOpt.isPresent()) {
// 不存在則進行補償修復
metadataStore.put(zkGroupClientPath, memberMetadata.groupId().getBytes(UTF\_8), Optional.empty())
.thenAccept(stat -> {
log.info("repaired clientId and group mapping: {}({})",
zkGroupClientPath, memberMetadata.groupId());
})
.exceptionally(ex -> {
log.warn("repaired clientId and group mapping failed: {}({})",
zkGroupClientPath, memberMetadata.groupId());
return null;
});
}
}).exceptionally(ex -> {
log.warn("repaired clientId and group mapping failed: {} ", zkGroupClientPath, ex);
return null;
});
}
}
}
經過方案三的優化上線,即使是歷史存在問題的消費組,個別分區消費流量指標缺少group字段的問題也得到了修復。具體效果如下圖所示:

四、總結
經過多個版本的優化和線上驗證,最終通過方案三比較完美的解決了這個消費指標問題。在分佈式系統中,併發問題往往難以模擬和復現,我們也在嘗試多個版本後才找到有效的解決方案。如果您在這方面有更好的經驗或想法,歡迎提出,我們共同探討和交流。











