

摘要:本文整理自淘寶閃購(餓了麼)大數據架構師王沛斌老師在 Flink Forward Asia 2025 城市巡迴上海站的分享。
引言
在數字化轉型的浪潮中,企業對實時數據處理的需求日益增長。傳統的實時數倉架構在面對業務快速變化和數據規模爆炸性增長時,逐漸暴露出數據孤島、成本高企、研發效率低下等問題。淘寶閃購(餓了麼)作為阿里巴巴集團重要的本地生活服務平台,在數據架構演進過程中積累了豐富的實踐經驗。
本文將從三個維度深入分析淘寶閃購(餓了麼)基於 Apache Flink 和 Paimon的 Lakehouse 生產實踐:回顧實時數倉的演進歷程(前世),深入解析湖倉應用的落地實踐(今生),並展望未來的技術發展方向(未來)。
一、實時數倉演進之路:從煙囱式架構到統一平台
1.1 淘寶閃購(餓了麼)大數據架構現狀
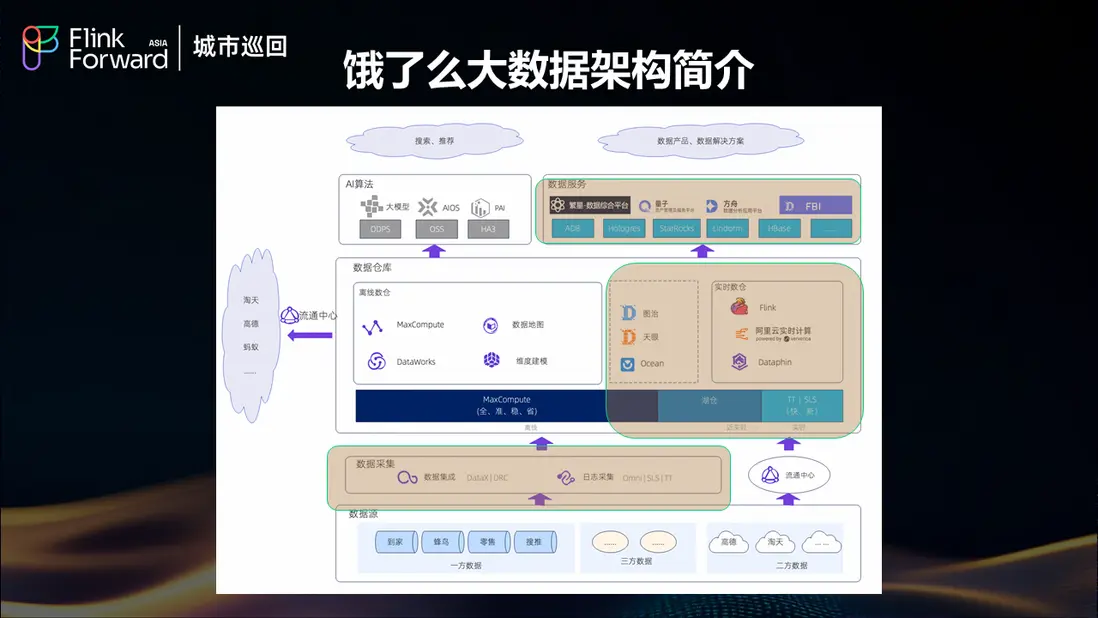
淘寶閃購(餓了麼)的大數據架構經歷了從分散到集中、從煙囱式到平台化的發展歷程。作為服務億萬用户的本地生活平台,餓了麼每天產生海量的訂單、用户行為、商户運營等多維度數據,這些數據的實時處理和分析直接影響着平台的運營效率和用户體驗。
1.2 實時數倉架構的三個發展階段
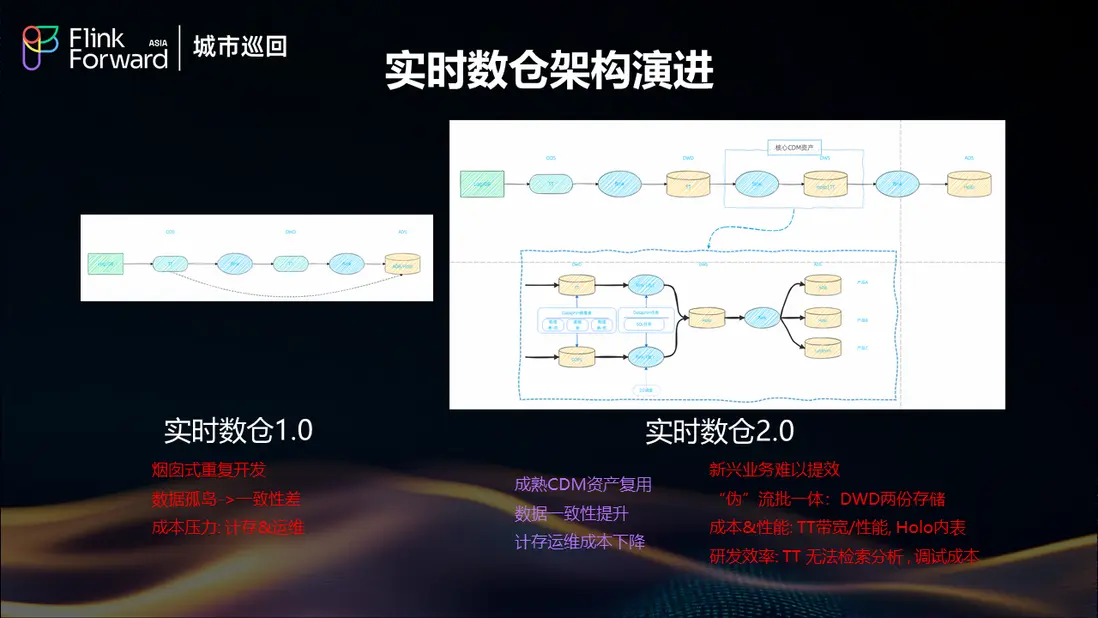
實時數倉 1.0:煙囱式重複開發時代
在早期階段,餓了麼面臨着典型的煙囱式開發問題。各業務線獨立構建實時處理鏈路,導致了嚴重的數據孤島現象。由於缺乏統一的數據標準和處理規範,不同系統間數據一致性差異顯著,給業務決策帶來了困擾。同時,重複的基礎設施建設和運維工作帶來了巨大的成本壓力,包括計算存儲資源的重複投入和運維人力的分散投入。
實時數倉 2.0:初步整合與新挑戰
為了解決 1.0 時代的問題,餓了麼開始推進數據中台建設,通過成熟的 CDM 資產複用,顯著提升了數據一致性,降低了計算存儲和運維成本。然而,隨着業務的快速發展,新的挑戰開始顯現。
2.0 架構雖然在一定程度上實現了數據複用,但仍然面臨"偽"流批一體的問題。DWD 層需要維護兩份存儲,分別支持流式和批處理場景,這種重複存儲不僅增加了成本,也帶來了數據同步的複雜性。在成本和性能方面,TT(消息隊列服務)存在帶寬和性能瓶頸,而 Hologres 內表的性能優化也面臨限制。研發效率方面,TT 無法支持檢索分析功能,調試成本居高不下,新興業務難以快速響應。
1.3 Lakehouse探索與技術選型
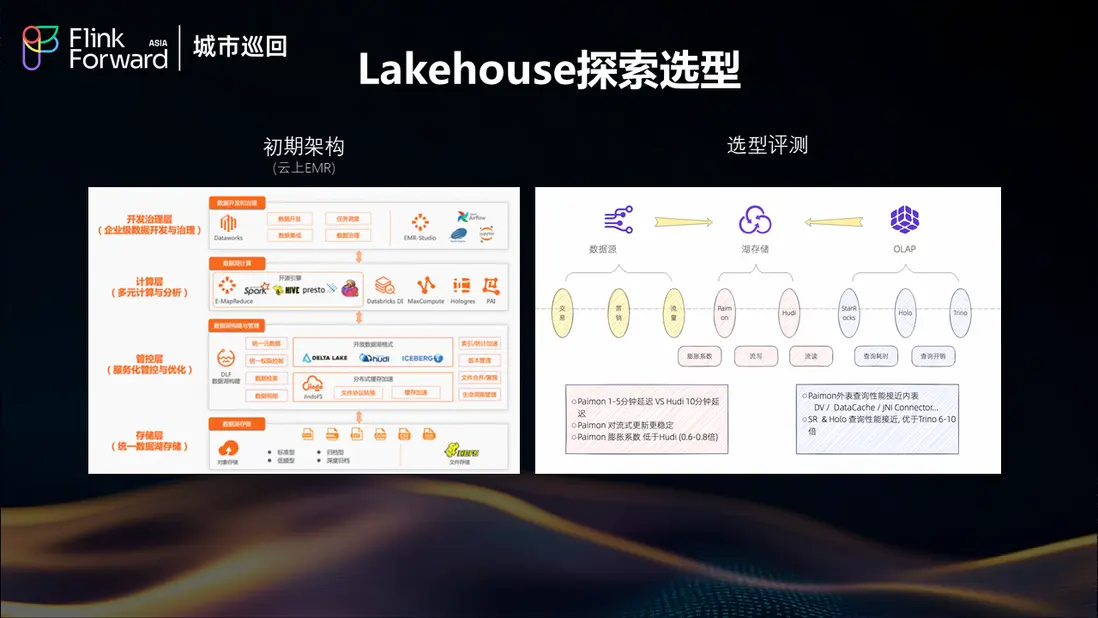
面對 2.0 架構的侷限性,餓了麼開始探索 Lakehouse 架構。初期基於雲上 EMR 進行了大量的選型評測工作,重點對比了不同湖存儲格式和 OLAP 引擎的性能表現。
關鍵技術選型對比
經過大約十輪的深度測試,餓了麼得出了幾個重要結論:
湖存儲格式對比:Paimon vs Hudi
從對比測試結果來看,Paimon 在多個關鍵指標上顯著優於 Hudi。首先是端到端延遲表現,Paimon 能夠提供更低的數據處理延遲,這對於實時業務場景至關重要。在流式更新的穩定性方面,Paimon 表現出更好的一致性和可靠性。此外,在寫放大控制方面,Paimon 的優化策略更加有效,能夠顯著降低存儲系統的負載壓力。
OLAP 引擎性能評估
在 OLAP 層面的測試中,StarRocks 和 Hologres 各有千秋,兩者的查詢性能表現接近,但都顯著優於 Trino。特別值得注意的是,通過引入 Deletion Vector 和 Data Cache 等性能特性,StarRocks 和 Hologres 查詢 Paimon 外表的性能能夠接近內表水平,這樣基本能夠滿足現階段的 OLAP 查詢需求。
架構兼容性挑戰
明確了 Flink+Paimon+StarRocks/Hologres 這三大 lakehouse 引擎,由於我們原有的大數據架構主要做阿里彈內內部部署 與雲上 EMR 的生態還是難以完美兼容,這對我們內部快速應用帶來了一定障礙.所以我們亟需一套好用的研發平台
二、Alake 平台賦能:一站式湖倉開發的關鍵轉折
2.1 Alake項目背景與價值
幸運的是,在這個關鍵時刻餓了麼遇到了阿里內部的 Alake 項目。Alake 是阿里巴巴內部從 Data Warehouse 向 Lakehouse 轉變,並在後期逐步演進到 Data +AI 的大數據平台架構的關鍵載體。
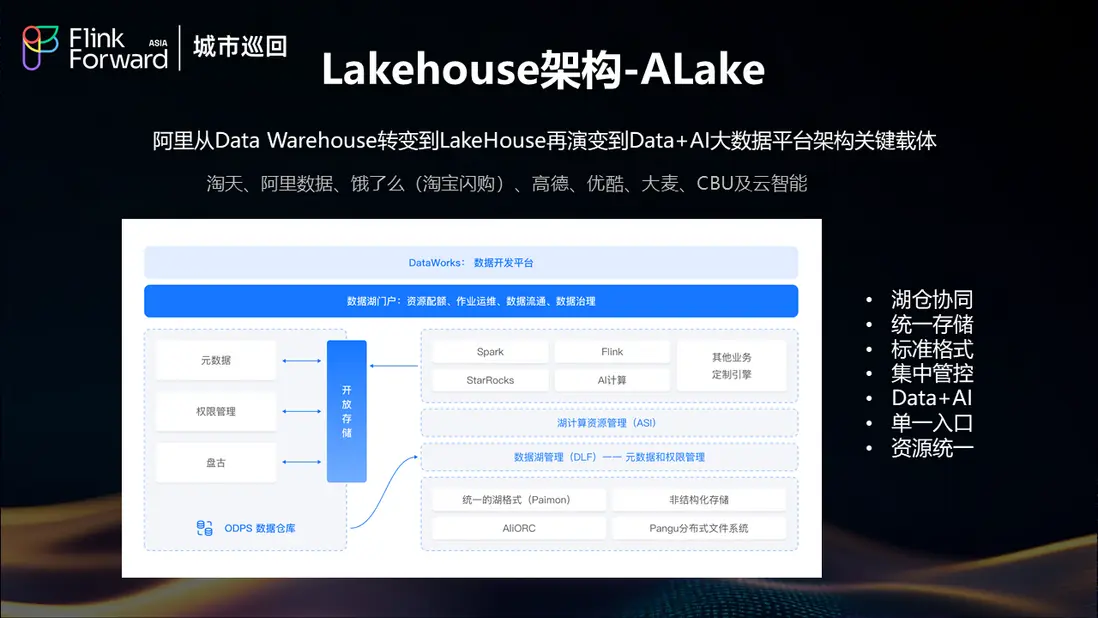
Alake 目前已在淘寶、天貓、阿里雲、餓了麼、高德等多個業務單元得到廣泛應用,其成熟度和穩定性經過了大規模生產環境的驗證。
2.2 Alake平台核心能力
一站式開發平台
Alake 為餓了麼提供了基於 DataWorks 的一站式湖倉開發平台。由於餓了麼此前的離線數倉也是基於 DataWorks 開發,這種技術棧的一致性使得研發團隊能夠快速、便捷地遷移到湖倉架構,顯著降低了遷移門檻和學習成本。
湖計算資源統一管理
Alake的一個核心優勢是實現了湖計算資源的統一管理。Spark、StarRocks、Flink 等所有計算相關的資源都可以在 Alake 平台上進行統一管理和調度。這種資源池化的設計支持靈活的資源調度,例如今天 Spark 使用 1000 個 CU,明天可以快速調整挪出 500 個 CU 給 Flink 使用,這種動態資源分配能力大大提升了資源利用效率。
統一湖存儲格式
Alake在底層構建了統一的湖存儲格式,基於Paimon和Pangu實現了無限擴展的存儲能力。這種統一存儲架構的最大價值在於消除了數據搬遷的需求,避免了因存儲容量限制導致的數據孤島問題。所有數據都存儲在統一的湖存儲中,不同計算引擎可以直接訪問,實現了真正的存儲與計算分離。
數據湖元數據管理(DLF)
Alake 在數據湖層面提供了優秀的 DLF(Data Lake Formation)元數據管理服務。通過 DLF,湖倉的元數據可以與原有的數據安全和權限管理系統無縫對接,同時支持與 ODPS 元數據的互通,實現了跨系統的數據流通能力。
三、湖倉架構落地實踐:分鐘級實時數據Pipeline
3.1 整體架構設計
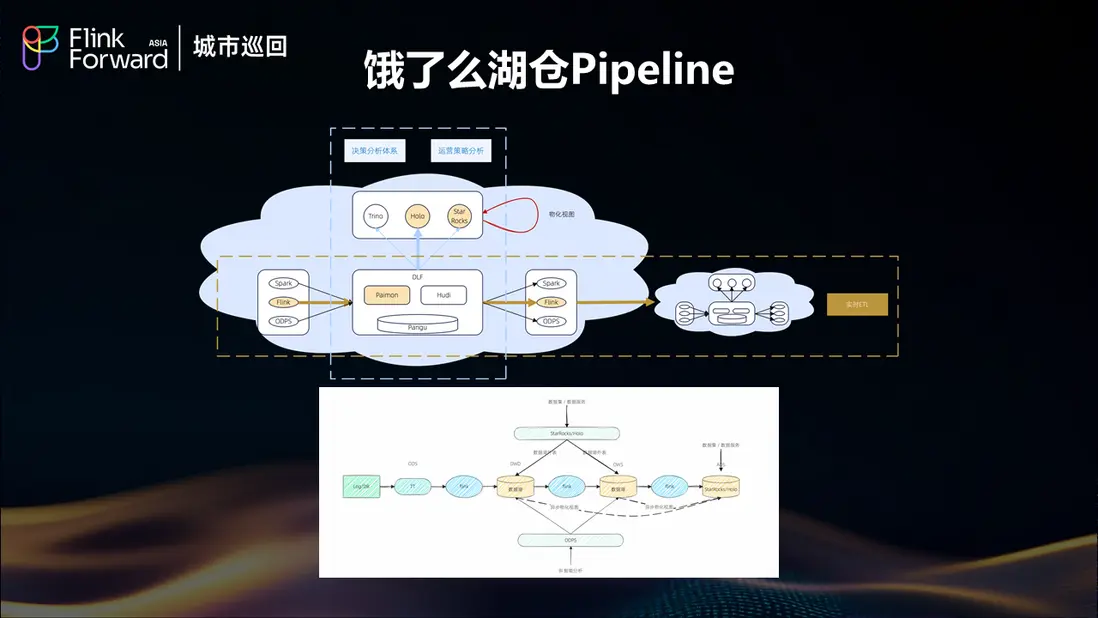
有了強大的引擎+人性化的研發平台後, 我們就在 24 年下半年就基於 ALake 結合具體業務場景開始規模化的構建了自己的 Streaming Lakehouse pipeline, 大致方案如下:
- 基於Paimon流讀流寫的ETL鏈路:實現分鐘級的端到端流式處理能力
- SR/Holo外表/MV的數據服務鏈路:提供低延遲的即席分析能力
- Spark/ODPS的離線批處理:支持傳統的BI智能分析範式
3.2 傳統實時數倉vs湖倉架構對比
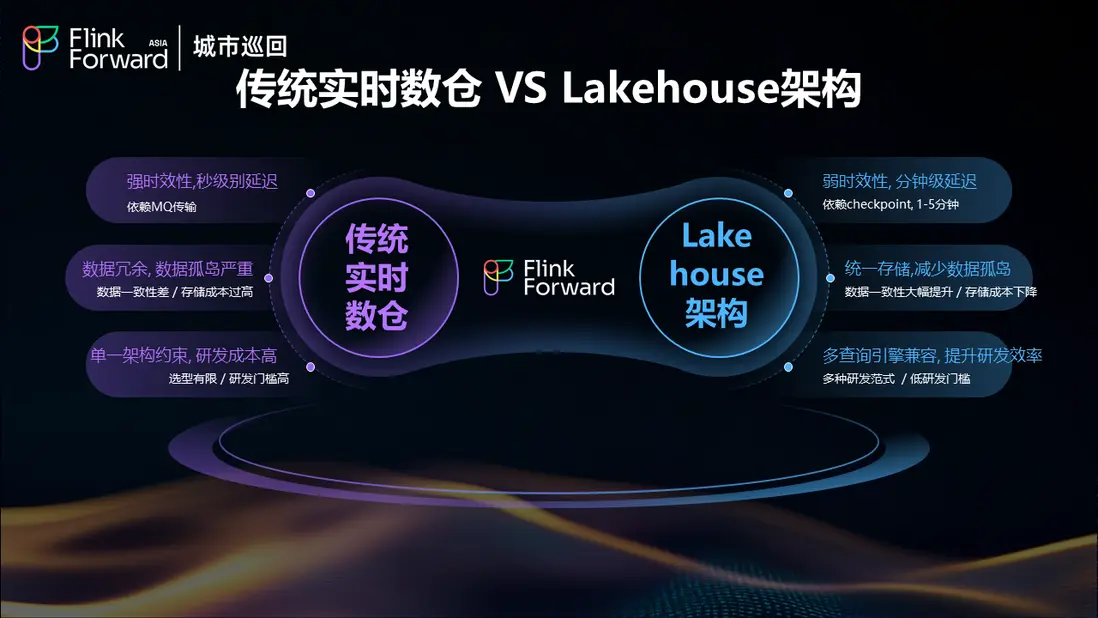
數據一致性與存儲優化
傳統實時數倉架構面臨數據冗餘和數據孤島嚴重的問題,不同系統間數據一致性差,存儲成本過高。湖倉架構通過統一存儲顯著減少了數據孤島,數據一致性得到大幅提升,存儲成本明顯下降。
時效性與研發效率平衡
傳統架構雖然能夠提供強時效性的秒級延遲,但受限於單一架構約束,研發成本高,技術選型有限,研發門檻較高。湖倉架構雖然在時效性上有所妥協,實現分鐘級延遲(依賴 checkpoint 機制,通常為1-5分鐘),但通過多查詢引擎兼容性,顯著提升了研發效率,提供多種研發範式,大幅降低了研發門檻。
3.3 生產規模與穩定性驗證
規模化運行成果
從湖倉的整體規模來看,餓了麼實現了十倍以上的規模增長。目前大約有 15 萬以上的 CU 在運行,包括湖倉的流處理和批處理工作負載。這種規模化的部署驗證了湖倉架構的可擴展性和實用性。
大促穩定性認證
在每週一次累計十多次的大促活動過程中,湖倉的穩定性得到了充分驗證和認證。這種高強度、大併發的業務場景對系統穩定性提出了極高要求,湖倉架構能夠在這種壓力下保持穩定運行,證明了其在生產環境中的可靠性。
技術棧多樣化發展
對於數倉團隊而言,整體的數據鏈路現在實現了非常多樣化的發展。團隊不再侷限於以前單一的離線鏈路或 Flink 流處理鏈路,現在擁有多種技術選型可供使用,這種技術棧的豐富性為不同業務場景提供了更好的適配能力。
四、典型應用場景:淘寶閃購業務實踐
4.1 業務背景與挑戰
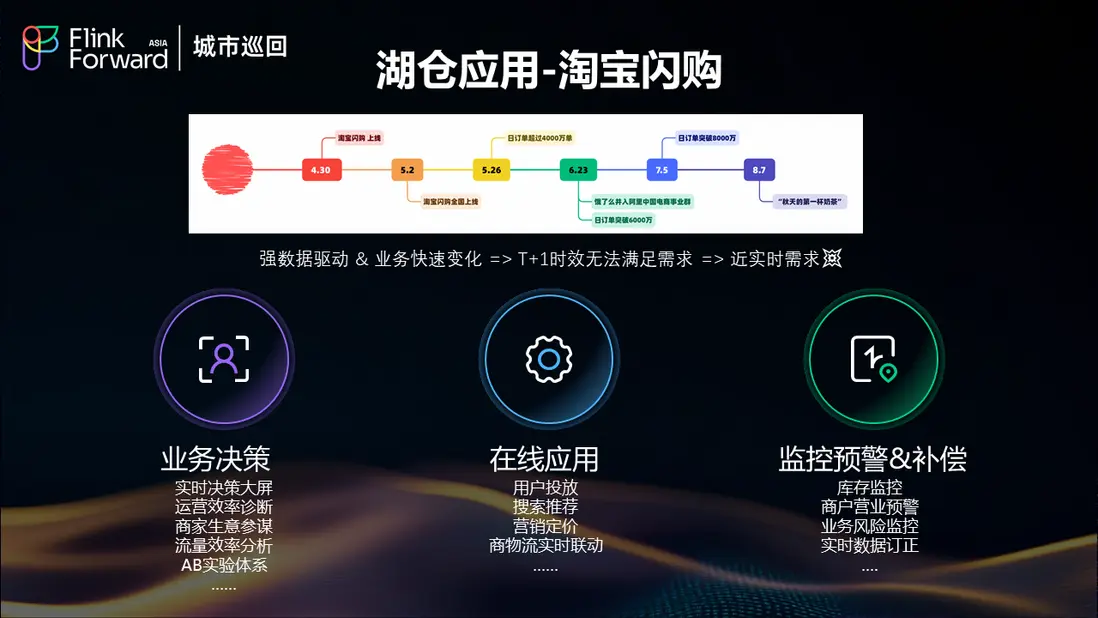
淘寶閃購作為餓了麼湖倉架構的重要應用場景,具有強數據驅動特徵和業務快速變化的特點。傳統的T+1時效已無法滿足業務需求,近實時的數據處理能力成為業務成功的關鍵因素。
在線應用需求
在線應用場景包括用户投放、搜索推薦、營銷定價、商物流實時聯動等多個維度。這些場景都需要基於最新的數據狀態進行決策,任何延遲都可能影響用户體驗和業務效果。
業務決策支持
業務決策層面需要實時決策大屏、運營效率診斷、商家生意參謀、流量效率分析、AB實驗體系等多種數據產品。這些應用要求數據不僅要實時,還要準確、一致。
監控預警體系
監控預警方面涵蓋了庫存監控、商户營業預警、業務風險監控、實時數據訂正等關鍵場景。這些場景對數據的時效性和準確性都有極高要求。
4.2 解決方案設計思路
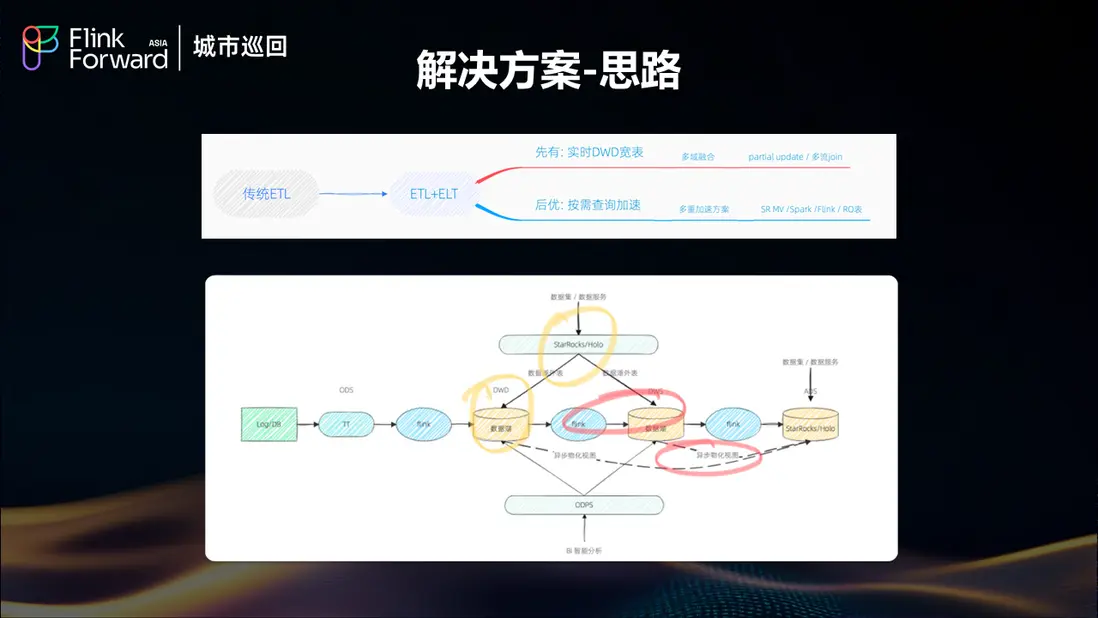
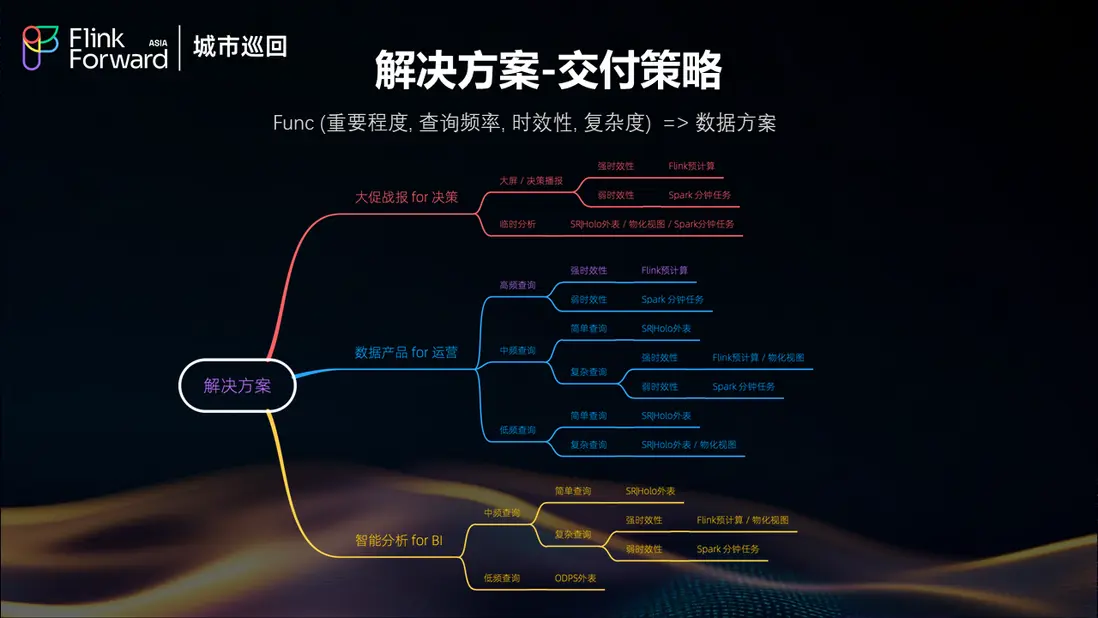
面對多樣化的業務需求,餓了麼採用了基於功能重要程度、查詢頻率、時效性要求、複雜度等多維度評估的交付策略。通過 Func(重要程度, 查詢頻率, 時效性, 複雜度)函數來確定最適合的數據解決方案。
4.3 典型案例分析
UV統計場景優化
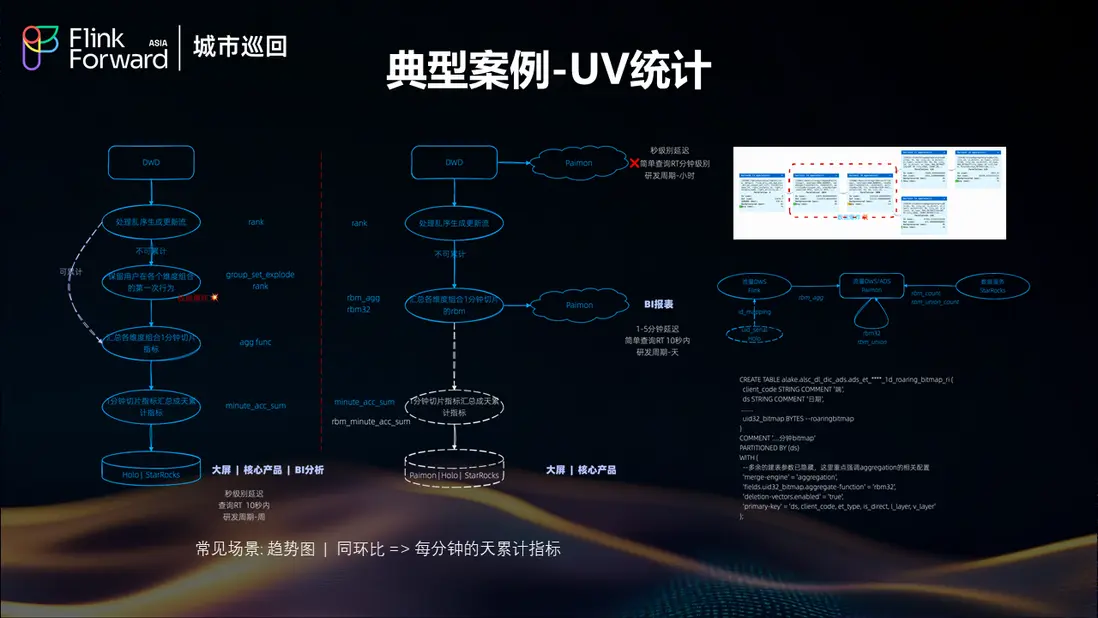
UV 統計是一個典型的實時分析場景,常見於趨勢圖和同環比分析。挑戰在於需要計算每分鐘的天累計指標,這要求系統既要處理增量數據,又要維護準確的累計狀態。
湖倉架構通過 Flink 的狀態管理能力和 Paimon 的增量更新機制,實現了高效的 UV 去重和累計計算,既保證了計算的準確性,又滿足了分鐘級的時效性要求。
近實時AB實驗
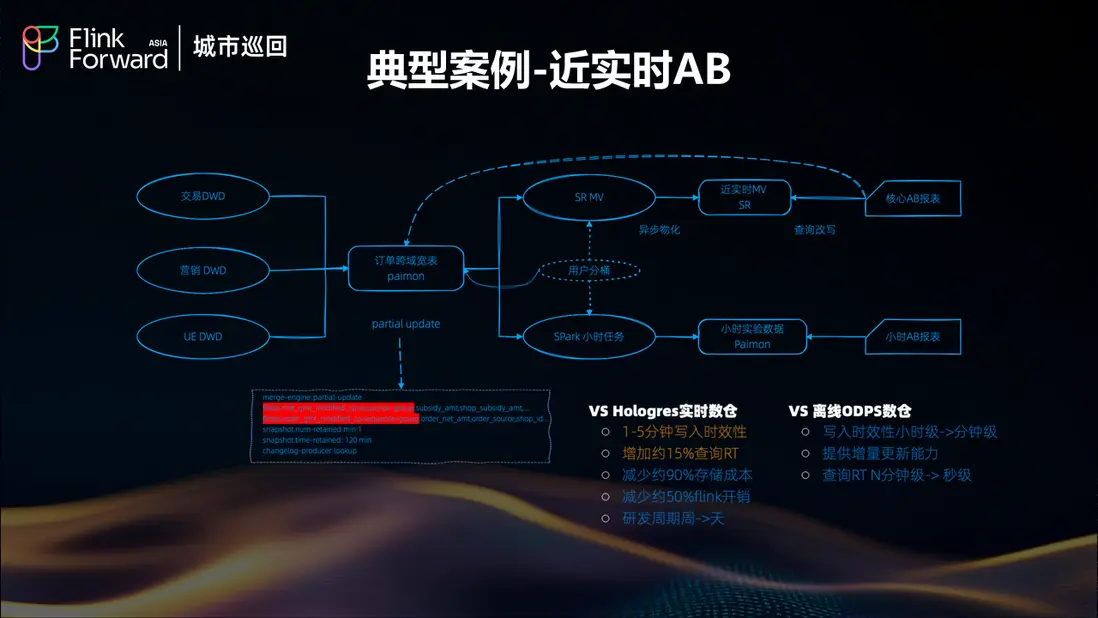
AB 實驗系統對數據的實時性和準確性都有極高要求。傳統架構下,實驗數據的延遲可能影響實驗效果的及時評估。湖倉架構通過實時數據流和統一存儲,實現了 AB 實驗數據的近實時處理,使得實驗效果能夠快速反饋,大大提升了產品迭代效率。
4.4 應用實踐小結
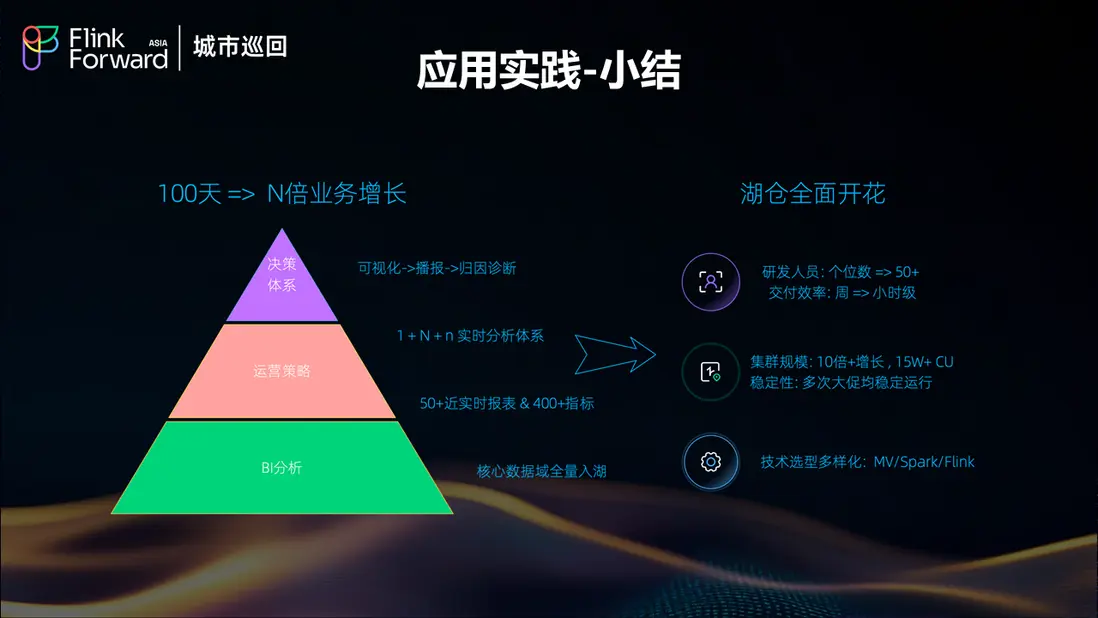
通過淘寶閃購等業務場景的實踐驗證,湖倉架構在支持多樣化業務需求方面表現出色。無論是在線應用的實時響應,還是業務決策的數據支持,或是監控預警的及時性,都得到了有效保障。
五、未來規劃與技術展望
5.1 核心技術發展方向
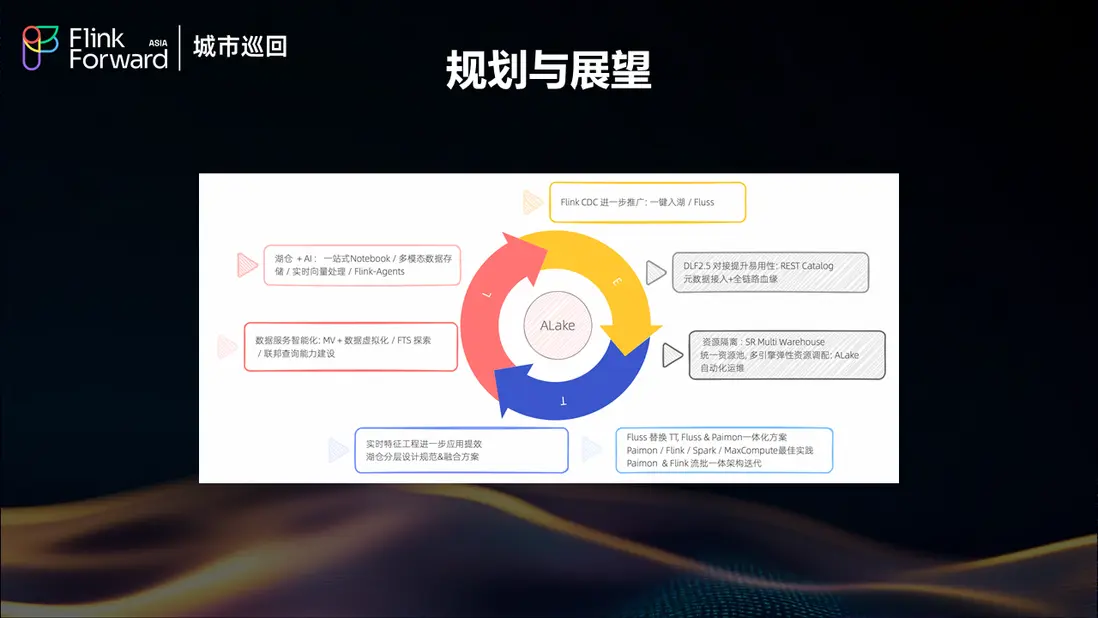
餓了麼的湖倉架構未來規劃主要聚焦於三個核心技術鏈路和基礎架構的持續優化。在眾多可能的發展方向中,團隊最關心和最想推進的重點項目是引入 Fluss 技術。
Fluss 技術引入計劃
引入 Fluss 的主要動機有兩個方面:首先是希望能夠替換現有的 TT 方案;其次,Fluss 已經為團隊勾勒了一個美好的技術藍圖。Fluss 與 Paimon 的結合能夠實現熱數據與温數據的一體化融合,這種融合將使得之前的"偽"流批一體方案升級為"真流批一體"方案,這是團隊非常期待落地探索的技術方向。
湖倉與AI能力融合
湖倉與 AI 的結合一直是團隊想要探索的重要方向。目前在 Alake 平台上已經有一些簡單的 notebook 環境,可以支持基礎的數據科學和簡單的 AI 能力。但是更深層次的AI能力整合仍需要進一步發掘,特別是需要找到更多的落地場景來驗證和完善這種結合的價值。
5.2 未來願景與目標
餓了麼對湖倉架構未來發展提出了四個重要願景:

真正的流批一體
實現真正的流批一體架構,讓數據流動像血液一樣自然,消除批處理和流處理之間的界限。這不僅是技術架構的統一,更是數據處理範式的根本性變革。
智能化數據服務
構建智能化的數據服務體系,讓數據工程師從"數據搬運工"轉變為"智囊團"。通過自動化和智能化的數據處理流程,釋放工程師的創造力,專注於更高價值的數據洞察和業務創新。
湖倉AI深度融合
推動湖倉與AI的深度融合,讓數據不僅被分析,更能主動"思考"和"預測"。這種融合將為業務決策提供更加智能的支持,實現從被動響應到主動預判的轉變。
開放生態體系
擁抱更加開放的生態體系,讓不同的技術能夠和諧共存,發揮各自優勢。避免技術棧的單一化,通過開放的架構設計支持多樣化的業務需求。
5.3 基於 Fluss & Paimon 的流批一體暢想
在具體的技術實現路徑上,餓了麼特別關注基於 Fluss 和 Paimon 的流批一體解決方案。這種組合有望實現真正意義上的流批統一,為未來的數據架構發展奠定堅實基礎。
結論
餓了麼基於 Flink 和 Paimon 的 Lakehouse 生產實踐,不僅是一次成功的技術架構升級,更是企業數字化轉型過程中的重要里程碑。從實時數倉的演進歷程,到湖倉架構的落地實踐,再到未來技術發展的前瞻規劃,這個完整的實踐案例為行業提供了寶貴的參考價值。
核心成果總結
通過湖倉架構的實施,餓了麼實現了多個重要突破:數據一致性得到大幅提升,存儲成本顯著下降,研發效率明顯改善,系統穩定性經受了大促考驗。特別是 15 萬以上 CU 規模的穩定運行,證明了湖倉架構在大規模生產環境中的可行性。
技術選型經驗
在技術選型方面,Paimon 相對於 Hudi 在端到端延遲、流式更新穩定性、寫放大控制等關鍵指標上的優勢,為湖倉架構的成功奠定了基礎。同時,Alake 平台的一站式開發環境和統一資源管理能力,大大降低了遷移成本和運維複雜度。
業務價值驗證
通過淘寶閃購等典型業務場景的應用驗證,湖倉架構在支持實時決策、在線應用、監控預警等多樣化需求方面表現出色,真正實現了技術服務業務的價值轉化。
未來發展方向
面向未來,餓了麼的湖倉架構將繼續朝着真正的流批一體、智能化數據服務、湖倉AI深度融合、開放生態體系等方向發展。特別是Fluss技術的引入和湖倉AI能力的深度融合,將為數據架構的下一輪創新提供強勁動力。
這個實踐案例表明,湖倉架構不僅是技術趨勢,更是企業數據能力提升的重要路徑。隨着技術的不斷成熟和應用場景的日益豐富,湖倉架構必將在更多企業的數字化轉型中發揮關鍵作用。
關於阿里雲DLF
阿里雲數據湖構建(Data Lake Formation,簡稱 DLF)是一款全託管的統一元數據和數據存儲及管理平台,為淘寶閃購(餓了麼)提供元數據管理、權限管理、存儲管理、存儲優化、版本管理、冷熱分層等功能。DLF 基於 Lakehouse 湖倉一體架構,以 Paimon 為核心 Lakehouse Format,兼容 Iceberg,構建統一多模態湖表存儲服務,支持結構化、半結構化、非結構化等多模態數據存儲、管理、優化,通過智能算法和存儲結構優化大幅提升數據讀寫及存儲效率,如果大家對這個產品感興趣,也歡迎到阿里雲官網搜索新版 DLF 進行體驗。
關於演講者
王沛斌 現任餓了麼大數據架構師,專注於大數據平台架構設計和湖倉技術實踐。在實時數倉架構演進、流批一體化技術、湖倉生產落地等領域具有豐富的實戰經驗。主導了餓了麼從傳統實時數倉向現代湖倉架構的完整轉型,在大規模生產環境下驗證了湖倉技術的可行性和價值。
