

Flink 流式 Join 的範式轉變:Delta Join 解決了什麼問題?
Apache Flink 一直以來都擅長有狀態流處理,但傳統流式 Join 在面對海量數據和高基數 Key 時卻遇到了瓶頸。問題在於為了保證正確性,你必須將所有歷史數據永久保存在 Flink 狀態中——這顯然不可持續。
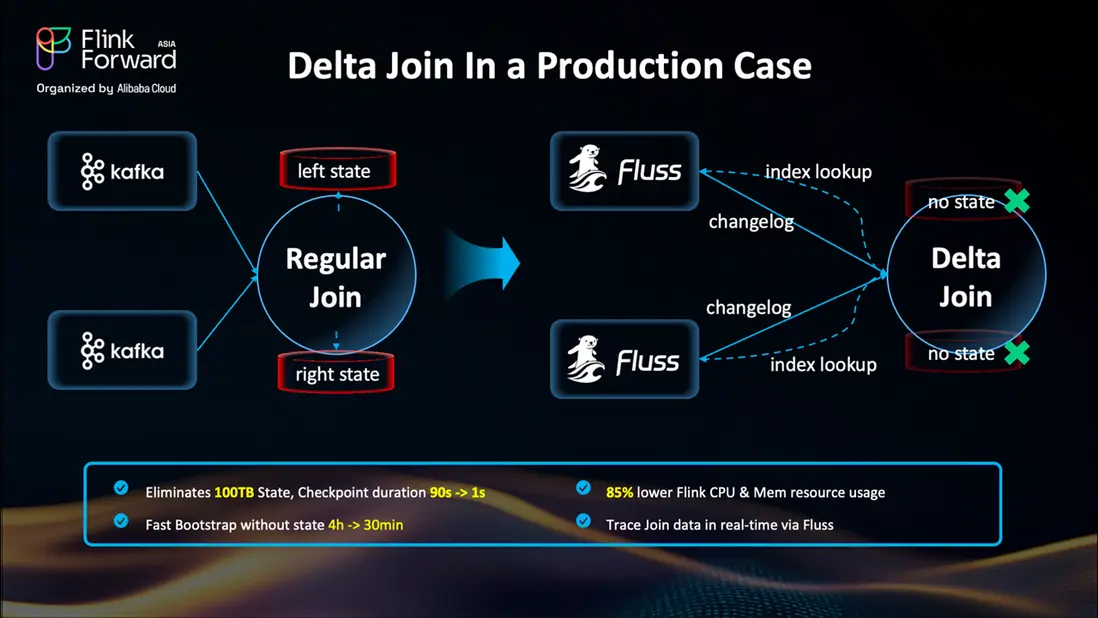
Delta Join(FLIP-486)徹底改變了這一局面。它不再將所有數據緩存在內部,而是將 Join 轉變為一種無狀態的查詢機制,直接從 Apache Fluss 或 Apache Paimon 等外部表中實時獲取所需數據。
Delta Join 帶來的實際影響
Delta Join 的核心思想很簡單:將計算與歷史數據解耦。算子不再將全部歷史數據存於 Flink 狀態,而是在需要時才去外部存儲查詢。從此告別狀態爆炸式增長。
效果如何?看一組來自淘寶天貓團隊生產環境的真實數據:
- 消除 50TB 的 Join 狀態——難以想象吧?
- 成本降低 10 倍:計算資源從 2300 CU 降至 200 CU,吞吐量卻保持不變
- CPU 和內存節省超 80%
- 作業恢復速度提升 87%
- Checkpoint 從“等到天荒地老”變為秒級完成
這不僅是漸進式優化,更是超大規模流處理的一次範式革命。
無界狀態危機:為何傳統 Join 難以規模化?
傳統 Join 為何在規模擴大時失效?
Flink 的常規 Join 功能強大,能完美處理 Insert、Update、Delete 操作。但代價是:你必須將兩個流的所有歷史數據永久保留在 Flink 狀態中。
由於流作業永不停止,狀態會無限增長。在高基數場景下,這無異於一場災難。

問題迅速累積:
- 資源壓垮:TaskManager 被龐大的狀態壓得喘不過氣
- Checkpoint 地獄:Checkpoint 耗時極長,作業頻繁超時、不穩定
- 恢復噩夢:從存儲中恢復上百 TB 狀態?準備好泡幾壺咖啡吧
Delta Join 之前,我們有什麼?
在 Delta Join 出現前,Flink 只有一些有限的替代方案:
- Interval Join:僅適用於帶時間窗口的追加流,現實場景大多不滿足
- Temporal / Lookup Join:適合流與維表關聯,但無法用於雙流 Join(雙方都需要歷史訪問)
根本問題在於:傳統 Join 迫使 Flink 重複存儲本已存在於外部的數據——就像為了以防萬一,把整個數據庫拷貝到內存裏,既低效又不可持續。
Delta Join 架構深度解析
核心理念:計算 vs 歷史
Delta Join(FLIP-486)的核心是關注點分離。其原則非常清晰:
“按需查詢,最小作業狀態,最終一致性”
當事件到達 Join 的任意一側時,算子不會翻查內部歷史,而是實時查詢外部索引。不再囤積數據,用時再取。
StreamingDeltaJoinOperator 如何工作?
StreamingDeltaJoinOperator 是實現這一切的引擎,關鍵組件包括:
- 雙側 LRU 緩存:查詢前先查緩存,熱數據駐留內存,冷數據自動淘汰
- 異步探查(Async Probing):緩存未命中時立即發起查詢,不阻塞處理流水線
- AsyncDeltaJoinRunner:每側一個實例,負責管理緩存與外部 I/O
注意:Delta Join 並非完全無狀態,而是一種混合模型。算子仍保留 LRU 緩存和協調狀態以保證一致性。性能表現取決於緩存命中率和外部查詢延遲。
正確性保障:異步順序控制
異步查詢的一大挑戰是:同一 Key 的更新可能亂序到達,破壞結果正確性。
Delta Join 通過 FLIP-519 引入的 **KeyedAsyncWaitOperator** 解決此問題:
- 同一 Key 的操作嚴格串行執行
- 不同 Key 仍可並行處理
既保留了高吞吐優勢,又確保了結果正確性。
外部狀態存儲:與實時湖倉生態集成
為何 Fluss 是 Delta Join 的理想搭檔?
Apache Fluss(孵化中) 正是為這類場景而生——它是一個專為 Apache Flink 設計的解耦式表存儲引擎。
關鍵特性:
- 分佈式架構:Coordinator + 基於 RocksDB 的 Tablet Server
- 雙結構設計:KV 存儲 + 日誌 Tablet = 支持任意時間點查詢 + CDC 流輸出
- 前綴查詢(Prefix Lookups):殺手級功能!支持使用複合主鍵的部分字段查詢(例如僅用
customer_id,而非完整的(customer_id, order_id, item_id))。多數系統要求精確匹配,Fluss 則靈活得多。
未來方向:Apache Paimon 集成
雖然 Fluss 是 Delta Join 的初始載體,但 Flink 社區正積極推動其與開源湖倉格式的融合。Flink SQL 路線圖已明確計劃支持 Apache Paimon,以實現更廣泛的近實時 Delta Join 能力。
Paimon 的優勢:
- 支持主鍵表與實時流式更新
- 分鐘級可查
- 靈活的 Merge 引擎(去重、部分更新、聚合)
- 與 Spark、Hive、Trino 無縫集成
目標很明確:讓 Delta Join 成為整個湖倉生態的通用能力,而不僅限於 Fluss。
量化收益與運維穩定性提升
數據不會説謊——Delta Join 帶來了實實在在的運維改善。
核心收益
- 狀態歸零:告別上百 TB 狀態文件、Checkpoint 超時和作業崩潰
- 資源節省:CPU/內存消耗降低 80%+;某場景 CU 從 2300 降至 200,成本直降 10 倍,吞吐不變
運維穩定性飛躍
- Checkpoint 秒級完成:再也不用苦等
- 恢復提速 87%:故障後快速回血
額外紅利:由於 Join 歷史存於外部存儲,還可複用於其他場景。有團隊通過對外部表執行 Sort-Merge Join,將數據重處理時間從 4 小時縮短至 30 分鐘。
實踐指南:配置、使用與適用場景
在 SQL 中使用 Delta Join
最棒的是:Delta Join 完全兼容標準 SQL,無需特殊語法。只需像平常一樣寫 JOIN:
SELECT * FROM orders
INNER JOIN Product ON orders.productId = Product.id
只要滿足條件,Flink 優化器會自動將其轉換為 Delta Join:
- SQL 模式支持 Regular Join → Delta Join 轉換
- 已配置合適的外部存儲
在較新 Flink 版本中,這一轉換通常自動發生。
關鍵配置參數
table.optimizer.delta-join.strategy='AUTO'
# 自動決策是否啓用 Delta Join(默認)
table.exec.delta-join.cache-enabled='true'
# 啓用緩存(默認開啓)
table.exec.delta-join.left.cache-size=10000
# 左表緩存大小
table.exec.delta-join.right.cache-size=10000
# 右表緩存大小
table.exec.async-lookup.buffer-capacity=100
# 異步查詢併發上限
何時使用 Delta Join?
Delta Join 在以下場景大放異彩:
- 高基數流式 enrichment:將海量事件流(點擊、交易)與大型、高頻更新的維表(用户畫像、商品目錄)關聯,避免狀態爆炸
- 實時可追溯性:所有 Join 歷史存於外部存儲,可精準審計任意計算所用數據
- 複雜變更追蹤:在維表頻繁增刪改的同時,保持 Flink 內部狀態極小化
總結與展望
Delta Join(FLIP-486)遠不止是一個新功能,它是大規模流處理思維方式的根本轉變。
權衡非常清晰:用少量外部查詢延遲,換取 Flink Checkpoint 域內狀態管理的巨大簡化。對於企業級實時應用而言,這是顯而易見的選擇。你將獲得:
- 運維穩定性質的飛躍
- 成本降低 10 倍,資源效率提升 80%+
- 作業恢復速度飛昇
目前,Delta Join 在 Fluss(尤其是其強大的前綴查詢能力)上表現卓越。未來,隨着對 Apache Paimon 等湖倉格式的支持落地,Delta Join 將成為整個流處理生態的標準能力。
延伸閲讀
- Apache Flink 2.1.0: 面向實時 Data + AI 全面升級,開啓智能流處理新紀元
- Fluss 在淘天搜推的落地實踐:更適合實時OLAP的消息隊列
更多內容

活動推薦
複製下方鏈接或者掃描二維碼
即可快速體驗 “一體化的實時數倉聯合解決方案”
瞭解活動詳情:https://www.aliyun.com/solution/tech-solution/flink-hologres
