
本教程使用所有軟件版本:pycharm 25.2 ,spark 3.4.2 ,hadoop 3.3.3
一 確認虛擬環境中已安裝 pyspark
source /home/hadoop/.virtualenvs/PythonProject1/bin/activate
pip show pyspark運行結果如圖:
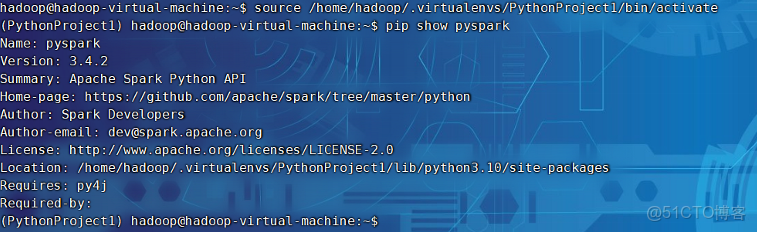
如果沒有安裝,則安裝百度進行完整安裝,安裝完成則到下一步。
二 使用Pycharm進行連接
2.1打開pycharm進行新建項目
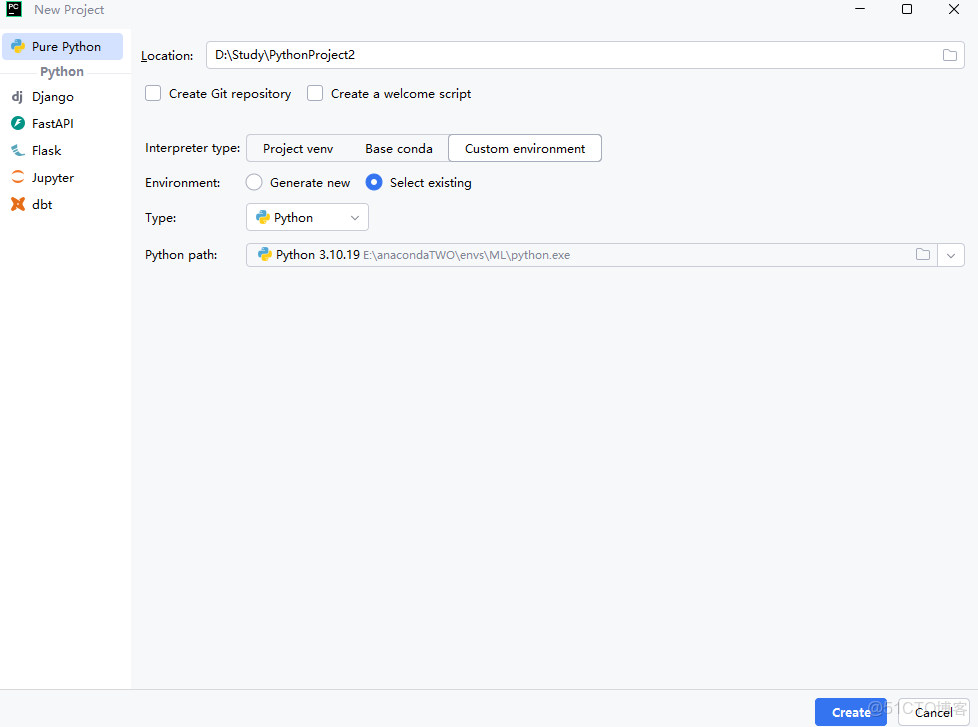
2.2 自行選一個python環境先將py項目建立起來,之後再做修改
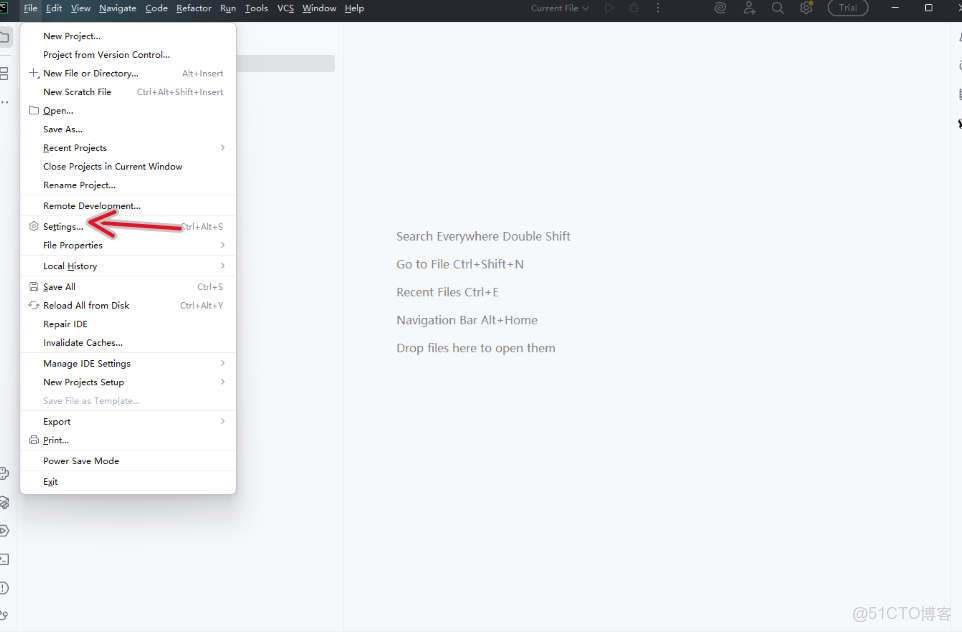
2.3 打開設置並且配置解釋器
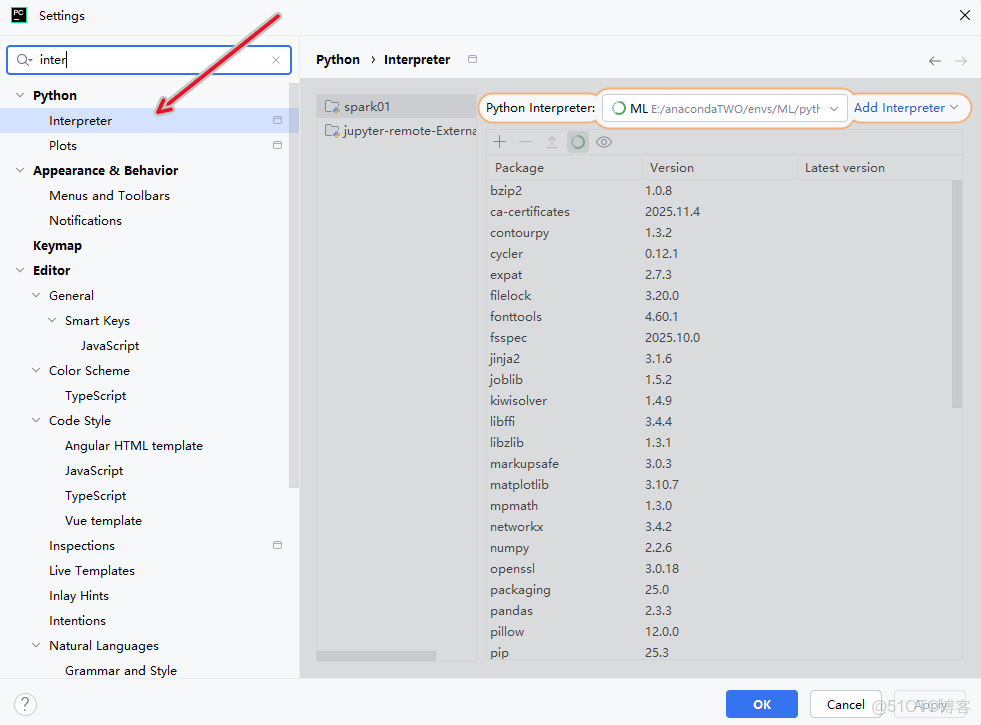
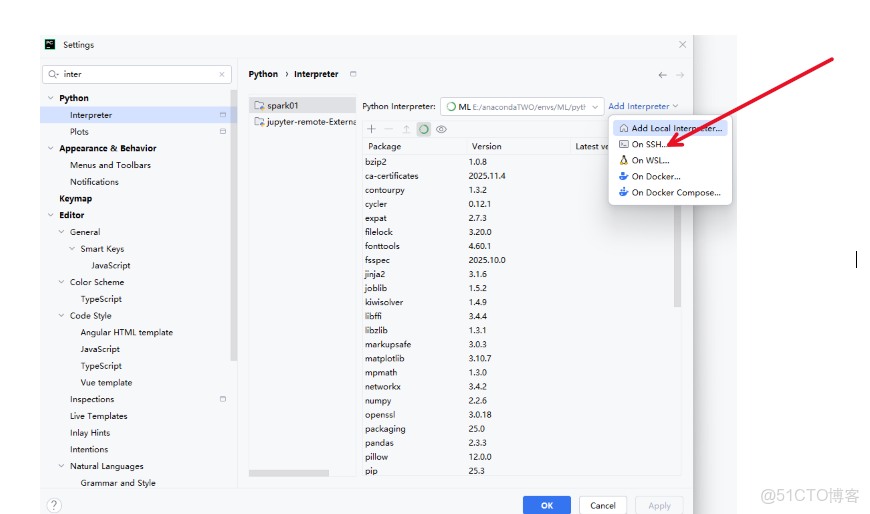
2.4 選擇ssh進行遠程連接
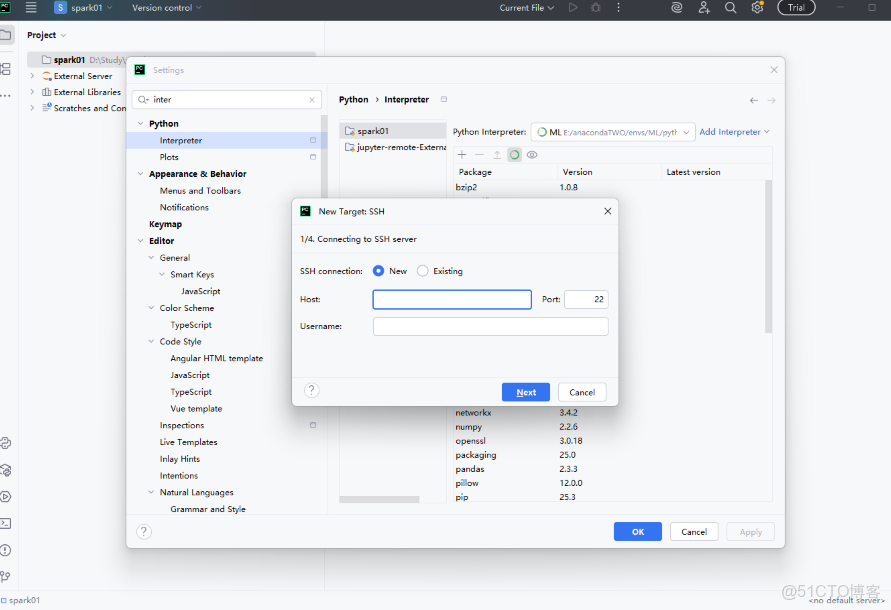
2.5 輸入自己的虛擬機主機名以及密碼,ip地址然後一路next
如果不知道主機名可以採用如下命令進行查看
ip addr show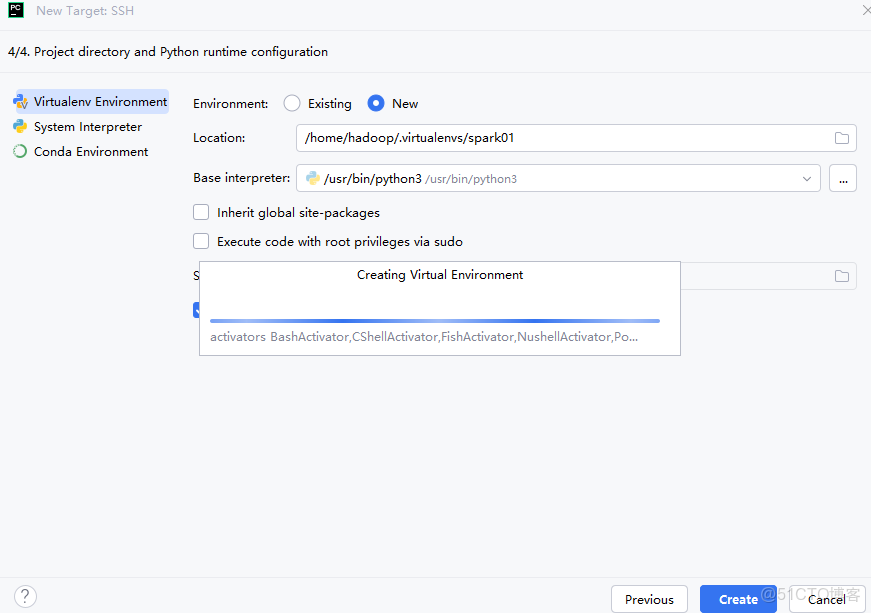
點擊create創建
注意:若是連接不上,卡在第三步的service,首先檢查主機名,密碼是否輸入正確,若還是不行,確保虛擬機允許ssh連接:
sudo apt install openssh-server -y
sudo systemctl start ssh
sudo systemctl enable ssh2.6 再次點擊解釋器查看是否連接成功(2.3)
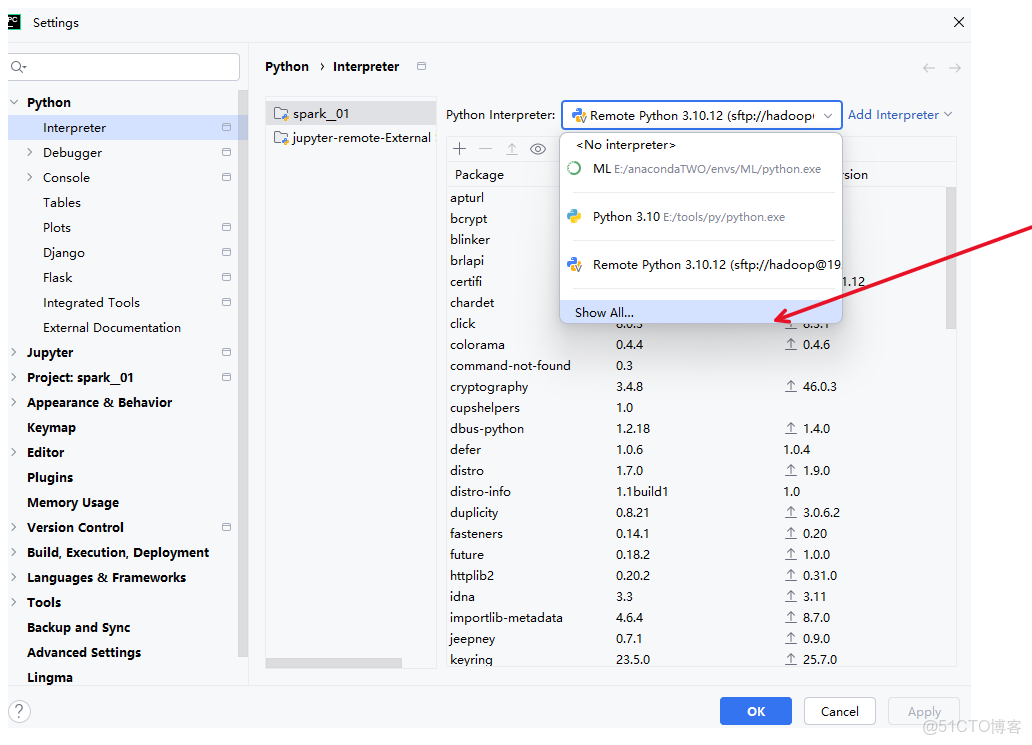
如下圖連接成功
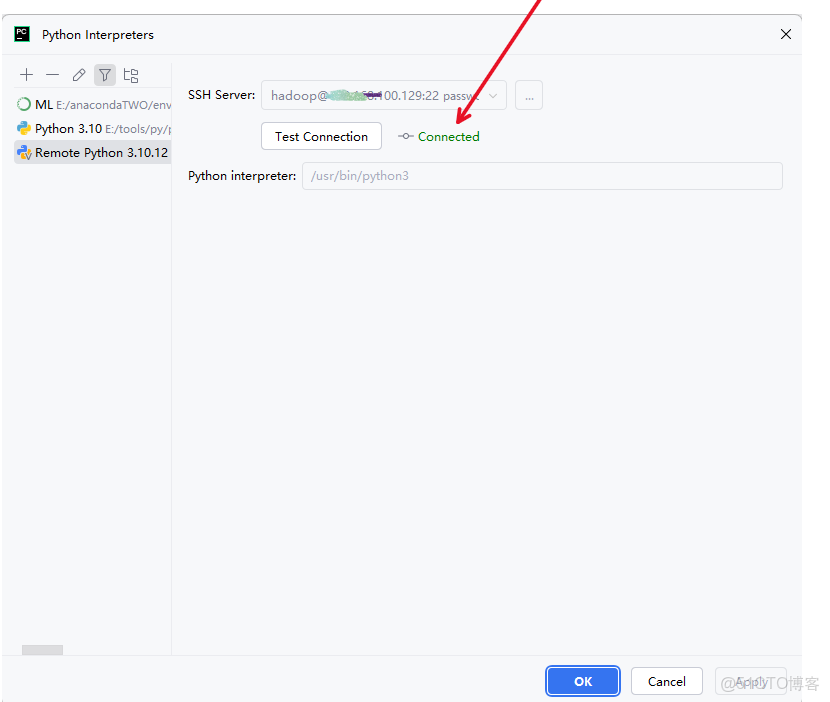
三 檢驗是否連接成功
- 打開 PyCharm。
- 點擊底部工具欄 → Python Console(如果沒有,可通過
View → Tool Windows → Python Console打開)。 - 在 Console 中逐行輸入以下代碼:
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("ConsoleTest") \
.master("local[*]") \
.getOrCreate()
print("Spark version:", spark.version)3.1若出現版本號,則連接成功,如圖:

3.2 (沒錯直接跳到3.3.)若是顯示缺少spark模塊,可能是在使用虛擬機安裝spark時使用了pip命令,沒有下載完整的包,建議重新下載spark完整包,並解壓在指定目錄下,以下是我解決方案(也可以按照書上來):
使用華為雲鏡像:
wget https://mirrors.huaweicloud.com/apache/spark/spark-3.4.2/spark-3.4.2-bin-hadoop3.tgz解壓到 /opt
sudo tar -xzf spark-3.4.2-bin-hadoop3.tgz -C /opt/配置環境變量
nano ~/.bashrc在文件末尾添加:
# Spark 完整安裝
export SPARK_HOME=/opt/spark
export PATH=$SPARK_HOME/bin:$PATH
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.9.7-src.zip:$PYTHONPATH✅ 第五步:生效配置 & 驗證
source ~/.bashrc
spark-submit --version你應該看到:
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.4.2
/_/
Using Scala version 2.12.18, OpenJDK 64-Bit Server VM, 11.0.xx3.3若是前面都沒錯,則創建一個test項目跑一下如下代碼,右鍵點擊run:
# test_spark_console.py 或直接在 PyCharm Console 中運行
from pyspark.sql import SparkSession
# 創建 SparkSession(本地模式)
spark = SparkSession.builder \
.appName("PyCharm-Spark-Test") \
.master("local[*]") \
.getOrCreate()
# 打印基本信息
print("🟢 Spark 連接成功!")
print(f"✅ Spark 版本: {spark.version}")
print(f"📍 運行模式: {spark.sparkContext.master}")
# 創建一個簡單 DataFrame
data = [("Alice", 25), ("Bob", 30), ("Cathy", 35)]
columns = ["Name", "Age"]
df = spark.createDataFrame(data, columns)
# 顯示數據
print("\n📊 示例 DataFrame:")
df.show()
# 執行一個簡單計算
avg_age = df.selectExpr("avg(Age) as AverageAge").collect()[0]["AverageAge"]
print(f"\n📈 平均年齡: {avg_age:.2f}")
# 停止 Spark(如果是在腳本中運行;Console 中可不加)
# spark.stop()執行結果如下:
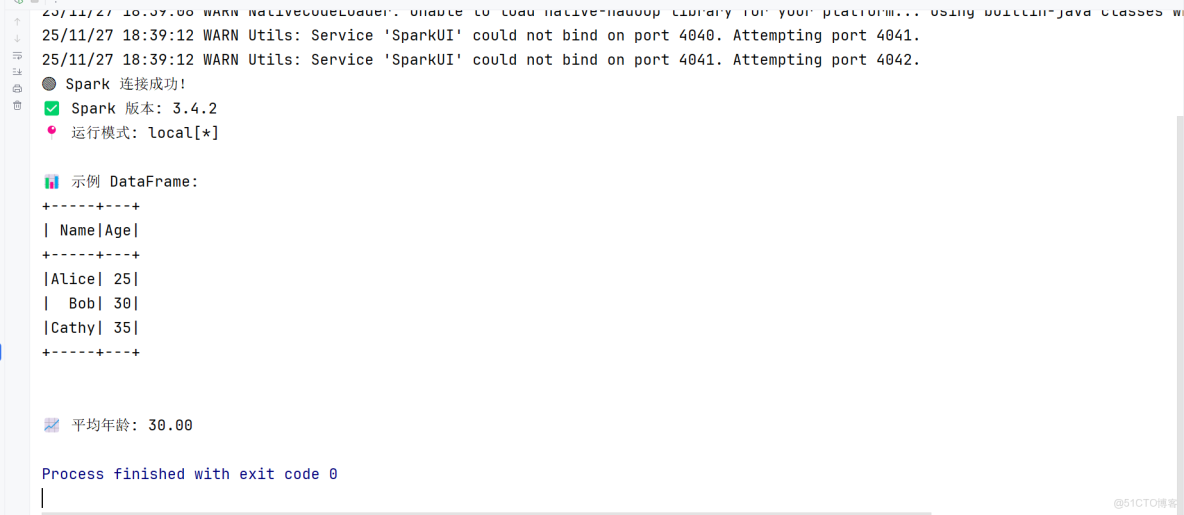
到這一步,🎉 恭喜你!現在你可以開始用 PyCharm + Spark 做數據分析、機器學習等任務了!
本文章為轉載內容,我們尊重原作者對文章享有的著作權。如有內容錯誤或侵權問題,歡迎原作者聯繫我們進行內容更正或刪除文章。