
- etcd Raft 算法是比較核心的
Raft 選舉
- leader 一個 修改操作
- follower
- candidate
etcd Server
etcdctl Client
127.0.0.1:2380 2380是server之間互相通信
127.0.0.1:2379 2379是客户端訪問服務器用的端口Client > Server

etcdctl 訪問 Server 127.0.0.1:2379
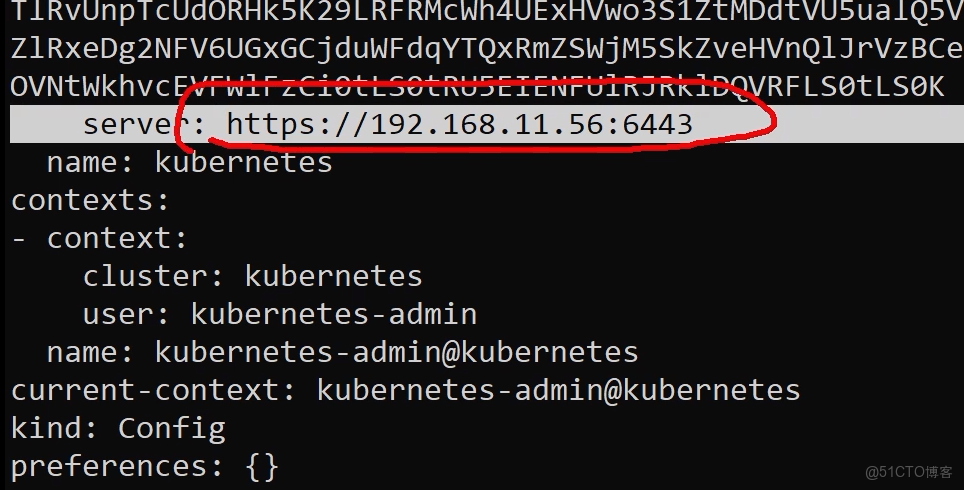
kubectl 尋找api server 是如何實現的? 答: /root/.kube/config

直接找下圖server中的端口
etcdctl --endpoints=127.0.0.1:2379
監控 etcd 狀態
etcdctl --endpoints=127.0.0.1:2379 member list --write-out=table

安裝
|
Bash
ETCD_VER=v3.4.28
# choose either URL
GITHUB_URL=https://github.com/etcd-io/etcd/releases/download
DOWNLOAD_URL=${GOOGLE_URL}
rm -f /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz
rm -rf /tmp/etcd-download-test && mkdir -p /tmp/etcd-download-test
curl -L ${DOWNLOAD_URL}/${ETCD_VER}/etcd-${ETCD_VER}-linux-amd64.tar.gz -o /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz
tar xzvf /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz -C /tmp/etcd-download-test --strip-components=1
/tmp/etcd-download-test/etcd --version
/tmp/etcd-download-test/etcdctl version
|
啓動服務
|
Bash
[root@worker-01 etcd-v3.4.28-linux-amd64]# ./etcd
WARNING: Package "github.com/golang/protobuf/protoc-gen-go/generator" is deprecated.
A future release of golang/protobuf will delete this package,
which has long been excluded from the compatibility promise.
|
列出集羣成員
|
Bash
[root@worker-01 etcd-v3.4.28-linux-amd64]# ./etcdctl --endpoints=localhost:2379 member list --write-out=table
+------------------+---------+---------+-----------------------+-----------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+---------+-----------------------+-----------------------+------------+
| 8e9e05c52164694d | started | default | http://localhost:2380 | http://localhost:2379 | false |
+------------------+---------+---------+-----------------------+-----------------------+------------+
|

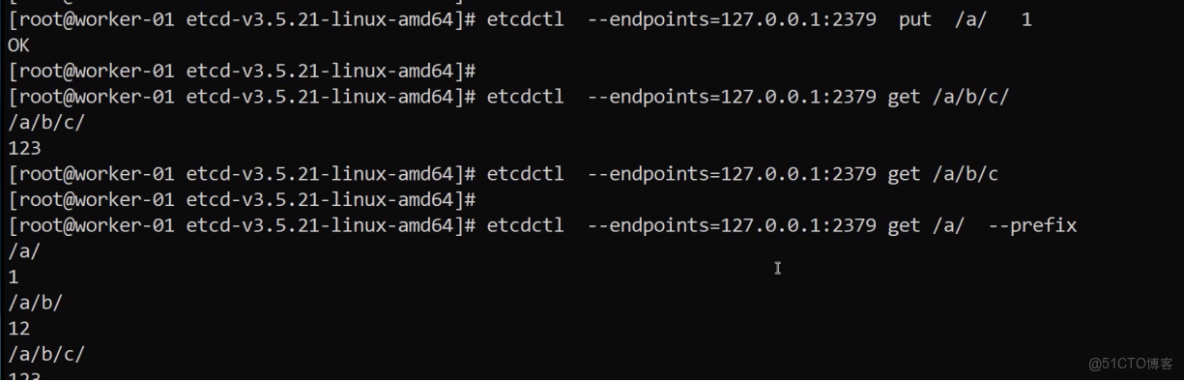
寫入操作
|
Bash
# 寫入數據
./etcdctl --endpoints=localhost:2379 put /key1 val1
OK
# 讀取數據
./etcdctl --endpoints=localhost:2379 get /key1
/key1
val1
# 按 Key 的前綴查詢數據
./etcdctl --endpoints=localhost:2379 get --prefix /
/key1
val1
# 只顯示鍵值
./etcdctl --endpoints=localhost:2379 get --prefix / --keys-only
/key1
# watch key 變化
./etcdctl --endpoints=localhost:2379 watch --prefix /
|
list-watch機制:
watch是持續監聽的意思,是K8S中的通知機制,當數據庫有增刪改查的操作時都會通知,這個機制是list-watch機制
Kubernetes 中的 List-Watch 機制就像是整個集羣的“神經系統”。它允許各個組件(比如調度器、節點代理等)實時感知到集羣資源(如 Pod、Service 等)的變化,而不需要頻繁地去“問”API Server“有什麼變化嗎?”。下面我用一個簡單的比喻幫你理解:
一個雜誌訂閲的比喻
想象一下你訂閲了一份雜誌(在 Kubernetes 中,這相當於一個組件,比如 kubelet,想要監聽 Pod 的變化):
- List(列表):拿到過刊合集 當你第一次訂閲時,雜誌社(相當於 API Server)會先寄給你一套迄今為止已經出版的所有過刊合集。這樣你手頭就有了完整的資料,知道了“當前狀態”。這個過程就是 List,它是一次性的,獲取的是資源的完整列表 。
- Watch(監聽):等待新刊送達 從下一期開始,你不再需要主動打電話問雜誌社“新雜誌到了沒”,而是雜誌社每出一期新刊,就會自動通過郵遞(相當於一個 HTTP 長連接)寄到你家裏。你只需要在家裏的郵箱旁等待即可。這個郵遞員會一直保持這條送貨通道,只要有新雜誌(相當於資源變更事件),就會立刻送過來。這個過程就是 Watch,它是持續的、事件驅動的 。
list-watch機制在kubernetes中是如何工作的?
• 核心角色:
◦ API Server:集羣信息的唯一入口,就像雜誌社的“總編輯部”。
◦ Etcd:集羣數據的核心數據庫,可以理解為雜誌社的““檔案庫””,所有最終數據都存儲在這裏。
◦ 客户端組件(如 Scheduler, Controller Manager, Kubelet):就像各個“訂閲者”。
• 基本工作流程:
1. 初始化(List):一個組件(比如負責調度的 Scheduler)啓動時,會先向 API Server 發起一個 List 請求,獲取當前所有未被調度的 Pod 的完整列表,建立自己的初始狀態 。
2. 持續監聽(Watch):緊接着,該組件會向 API Server 發起一個 Watch 請求,建立一個長連接。之後,一旦有新的 Pod 被創建、更新或刪除,API Server 就會通過這個長連接,將事件(ADDED, MODIFIED, DELETED)像推送消息一樣實時地推送給 Scheduler 。
3. 事件處理:Scheduler 收到這些事件後,就會觸發相應的處理邏輯(比如為新增的 Pod 尋找一個合適的節點。
為什麼 List-Watch 如此重要?它的精妙之處在哪?
這種機制的設計非常精妙,解決了幾個核心問題:
• 實時性:基於事件推送(Watch),變化一旦發生,組件幾乎能立刻感知,無需等待輪詢間隔 。
• 可靠性:即使網絡短暫中斷,組件在恢復後也可以通過 ResourceVersion(一個全局單調遞增的版本號)從斷點重新開始監聽,避免事件丟失 。
• 順序性:每個事件都帶有 ResourceVersion,確保了事件發生的先後順序,避免了狀態混亂 。
• 高性能:避免了客户端頻繁輪詢給 API Server 帶來巨大壓力。Watch 利用 HTTP 長連接和分塊傳輸編碼 技術,服務器可以持續發送數據,而無需預先知道數據的總大小 。
簡單小結
你可以這樣記住
• List 是 問一次,拿全量(獲取當前快照)。
• Watch 是 掛個電話,等通知(監聽後續變化)。
正是這套機制,使得 Kubernetes 的各個組件能夠高效、可靠地協同工作,共同維護集羣的期望狀態,它是 Kubernetes 聲明式 API 和控制器模式能夠順暢運行的基石 。
|
Bash
./etcdctl --endpoints=localhost:2379 put /name k1s
./etcdctl --endpoints=localhost:2379 put /name k2s
./etcdctl --endpoints=localhost:2379 put /name k3s
./etcdctl --endpoints=localhost:2379 put /name k4s
./etcdctl --endpoints=localhost:2379 get /name -wjson
./etcdctl --endpoints=localhost:2379 watch --prefix /name --rev 1
PUT
/name
k1s
PUT
/name
k2s
PUT
/name
k3s
PUT
/name
k4s
#這裏可以看出kubernetes中key的變更都是有歷史記錄的,所以數據可以回滾;
|
災備etcd非常重要 需要數據備份
因為Raft算法,etcd集羣就像一個小團隊做決策,至少需要3個人,這樣即使其中1人請假,剩下的2人也能代表多數做出有效決定。如果團隊只有1人或2人,缺一個就徹底癱瘓了。
|
Bash
# 備份命令
export ETCDCTL_API=3
ENDPOINTS=localhost:2379
$ etcdctl --endpoints=${ENDPOINTS} snapshot save /data/etcd_backup_dir/etcd-snapshot.db
$ etcdctl --endpoints=${ENDPOINTS} snapshot restore snapshot.db
|

備份 :
做一個快照工作中一般每隔離 30m 1h 做一個快照:
etcdctl --endpoints=127.0.0.1:2379 snapshot save /data/etcd_backup/etcd-snapshot.db
恢復 快照
etcdctl --endpoints=127.0.0.1:2379 snapshot restore snapshot.db
|
k8s 配置數據 保存到 etcd 中:
export ETCDCTL_API=3
etcdctl --endpoints https://localhost:2379 --cert /etc/kubernetes/pki/etcd/server.crt --key /etc/kubernetes/pki/etcd/server.key --cacert /etc/kubernetes/pki/etcd/ca.crt get --keys-only --prefix /
etcdctl --endpoints https://localhost:2379 --cert /etc/kubernetes/pki/etcd/server.crt --key /etc/kubernetes/pki/etcd/server.key --cacert /etc/kubernetes/pki/etcd/ca.crt get --keys-only --prefix /registry/pods/default/redis-pv-sts-0
etcdctl --endpoints https://localhost:2379 --cert /etc/kubernetes/pki/etcd/server.crt --key /etc/kubernetes/pki/etcd/server.key --cacert /etc/kubernetes/pki/etcd/ca.crt get /registry/pods/default/redis-pv-sts-0
etcdctl --endpoints https://localhost:2379 --cert /etc/kubernetes/pki/etcd/server.crt --key /etc/kubernetes/pki/etcd/server.key --cacert /etc/kubernetes/pki/etcd/ca.crt get /registry/configmaps/default/info
#下面是命令的拆解,其實就是加了三條安全認證:
etcdctl --endpoints https://localhost:2379
--cert /etc/kubernetes/pki/etcd/server.crt
--key /etc/kubernetes/pki/etcd/server.key
--cacert /etc/kubernetes/pki/etcd/ca.crt
get --keys-only --prefix /
雙向認證:客户端和服務器互相檢驗對方的身份,這裏kubernetes存數據就是雙向認證;
單向認證:僅客户端驗證服務器的身份即可;
數據存儲在/registry/類型/對象的名字:
/registry/poddisruptionbudgets/kube-system/calico-kube-controllers
#這個是key值 value就是這個目錄下對應的YAML文件,但是這個文件中存儲的格式跟YAML不同
/registry/pods/default/busy-dep-7f9b565d88-hqljb
|
在工作中可以用第三方軟件來備份:Kubernetes 集羣備份 - Velero
Velero目前包含以下特性:
1.支持Kubernetes集羣數據備份和恢復;
2.支持複製當前Kubernetes集羣的資源到其它 Kubernetes 集羣;
3.支持複製生產環境到開發以及測試環境。
velero使用場景:
災備場景:提供備份恢復Kubernetes集羣的能力;
遷移場景:提供拷貝集羣資源到其他集羣的能力(複製同步開發,測試,生產環境的集羣配置,簡化環境配置)。
Velero 組件介紹 :
Velero CLI : 提供 Velero 組件的安裝、備份和恢復命令。
Velero 服務器(The Velero server) :負責執行備份和恢復過程。
存儲提供者插件(Storage provider plug-ins) :這些插件用於備份和還原到特定存儲系統
Etcd 備份腳本
|
Bash
#!/bin/bash
ETCDCTL_PATH='/usr/local/bin/etcdctl'
ENDPOINTS='https://192.168.200.153:2379'
ETCD_DATA_DIR="/var/lib/etcd"
BACKUP_DIR="/var/backups/kube_etcd/etcd-$(date +%Y-%m-%d-%H-%M-%S)"
KEEPBACKUPNUMBER='5'
ETCDBACKUPPERIOD='30'
ETCDBACKUPSCIPT='/usr/local/bin/kube-scripts'
ETCDBACKUPHOUR=''
ETCDCTL_CERT="/etc/ssl/etcd/ssl/admin-master1.pem"
ETCDCTL_KEY="/etc/ssl/etcd/ssl/admin-master1-key.pem"
ETCDCTL_CA_FILE="/etc/ssl/etcd/ssl/ca.pem"
[ ! -d $BACKUP_DIR ] && mkdir -p $BACKUP_DIR
export ETCDCTL_API=2;$ETCDCTL_PATH backup --data-dir $ETCD_DATA_DIR --backup-dir $BACKUP_DIR
sleep 3
{
export ETCDCTL_API=3;$ETCDCTL_PATH --endpoints="$ENDPOINTS" snapshot save $BACKUP_DIR/snapshot.db \
--cacert="$ETCDCTL_CA_FILE" \
--cert="$ETCDCTL_CERT" \
--key="$ETCDCTL_KEY"
} > /dev/null
sleep 3
cd $BACKUP_DIR/../;ls -lt |awk '{if(NR > '$KEEPBACKUPNUMBER'){print "rm -rf "$9}}'|sh
if [[ ! $ETCDBACKUPHOUR ]]; then
time="*/$ETCDBACKUPPERIOD * * * *"
else
if [[ 0 == $ETCDBACKUPPERIOD ]];then
time="* */$ETCDBACKUPHOUR * * *"
else
time="*/$ETCDBACKUPPERIOD */$ETCDBACKUPHOUR * * *"
fi
fi
crontab -l | grep -v '#' > /tmp/file
echo "$time sh $ETCDBACKUPSCIPT/etcd-backup.sh" >> /tmp/file && awk ' !x[$0]++{print > "/tmp/file"}' /tmp/file
crontab /tmp/file
rm -rf /tmp/file
|
