1、數倉建模平台基於開源項目kylin建設
AllData數據中台商業版集成Kylin後,提供超大規模數據的實時分析與數倉建模能力。通過Kylin的預計算技術,實現PB級數據的亞秒級查詢響應,支持高併發多維分析場景。
系統內置分佈式計算框架,可動態擴展資源,結合Kylin的列式存儲與高效壓縮算法,顯著降低存儲成本,適用於金融風控、零售精準營銷等複雜數據分析需求。
Kylin項目地址:https://kylin.apache.org/zh-Hans/docs/overview
2、數倉建模平台功能特點
Apache Kylin的Web界面菜單功能豐富,以下列舉了七點核心功能及其描述:
- 項目管理:創建和管理項目,定義數據源及存儲位置
- 模型設計:構建數據模型,選擇數據源表並定義維度與度量
- Cube構建:基於模型構建Cube,預計算多維數據集以加速查詢
- Cube管理:監控Cube狀態,執行構建、刷新、合併等操作
- 查詢界面:輸入SQL語句查詢Cube,支持聚合函數與分組操作
- 可視化分析:提供透視表與圖表工具,直觀展示查詢結果
- 任務監控:跟蹤Cube構建及查詢任務進度,查看執行日誌

💡部署步驟:

1、源碼獲取

2、編譯構建
💡安裝scala插件:
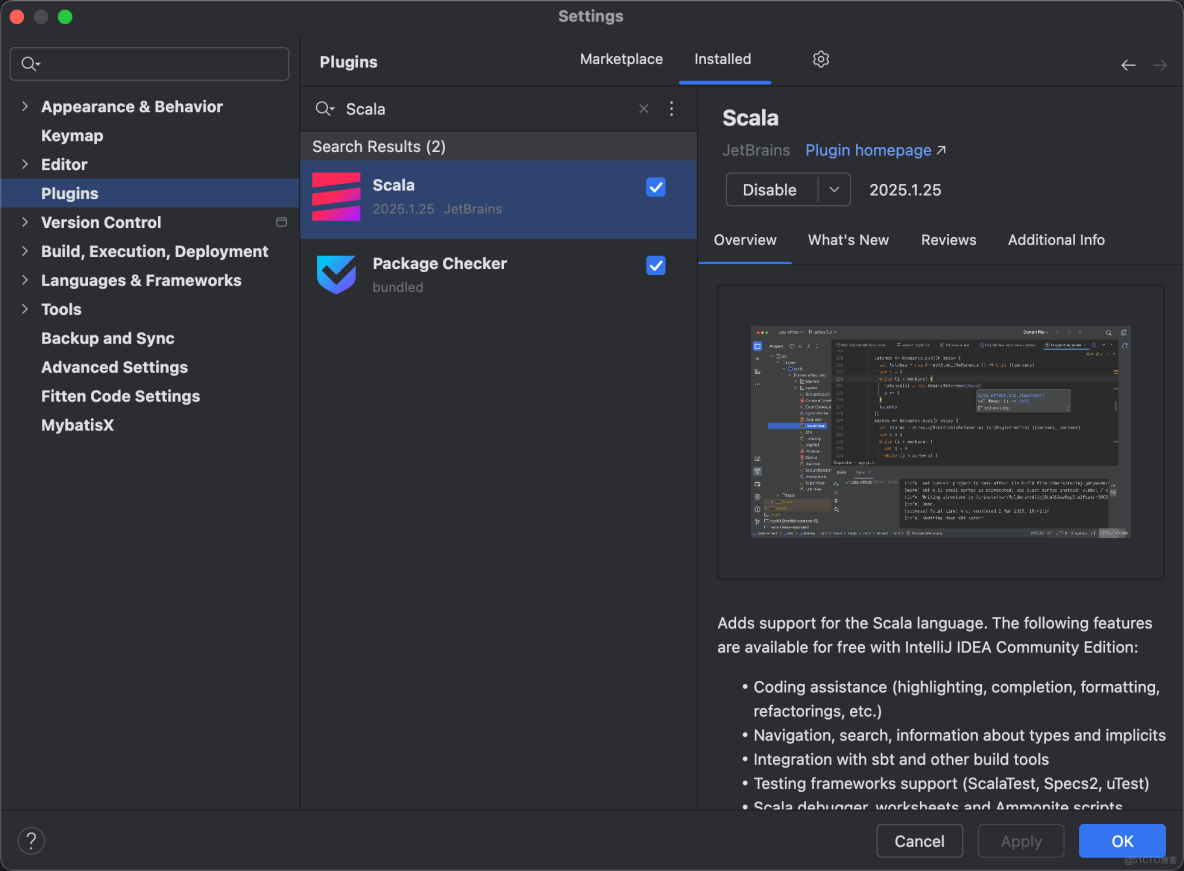
💡安裝JavaCC插件
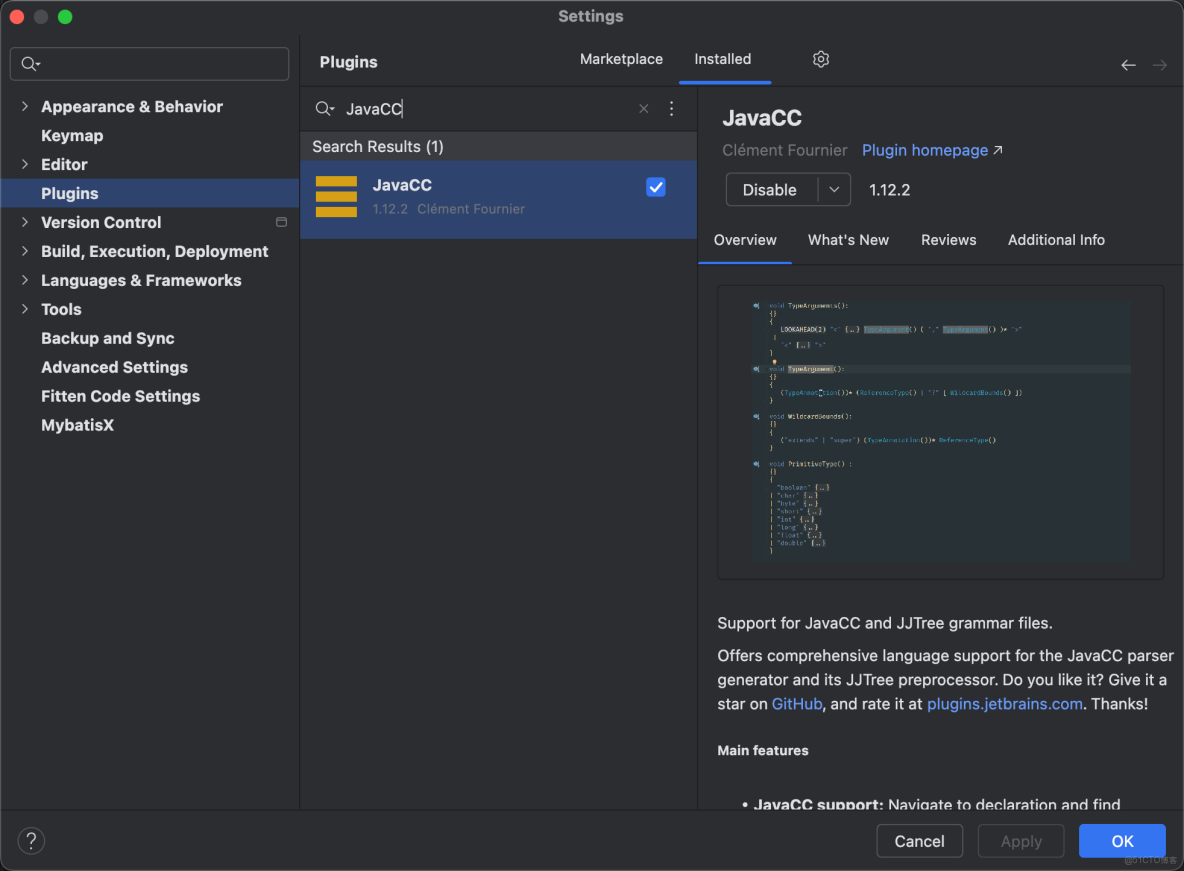
- 安裝插件完成後需要重啓 IDEA
- Maven窗口勾選 SkipTests
- 安裝 scala sdk
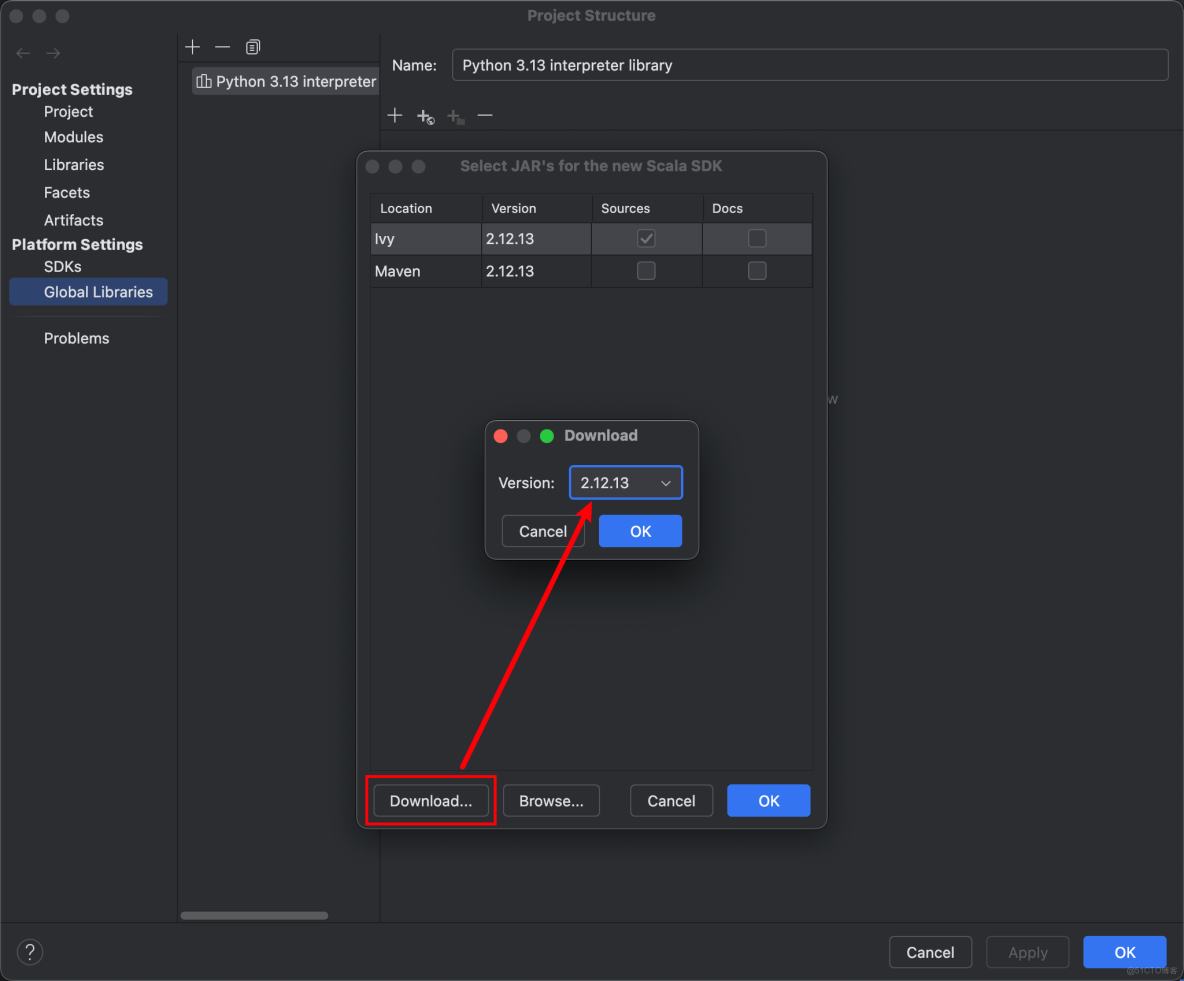
3、部署安裝
3.1 環境準備:
- zookeep 3.6
- Hadoop 3.2.1
- hive 3.1.2
- mysql 5.7 或 8
- jdk 1.8
3.2 打包:
- 打包完成
- 部署包路徑:dist/apache-kylin-5.0.2-bin.tar.gz
3.3 解壓到服務器:

3.4 啓動服務:

4、前端部署
- 編譯

- 打包

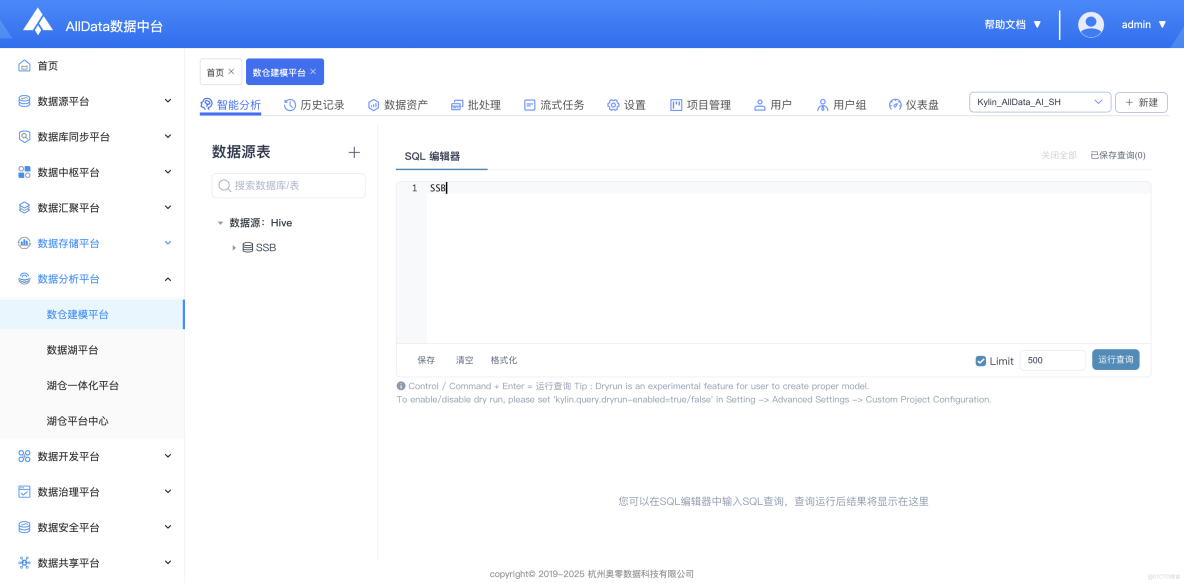
1、數倉建模平台首頁-智能分析
- 可自動挖掘數據價值,提供可視化洞察與精準決策支持。
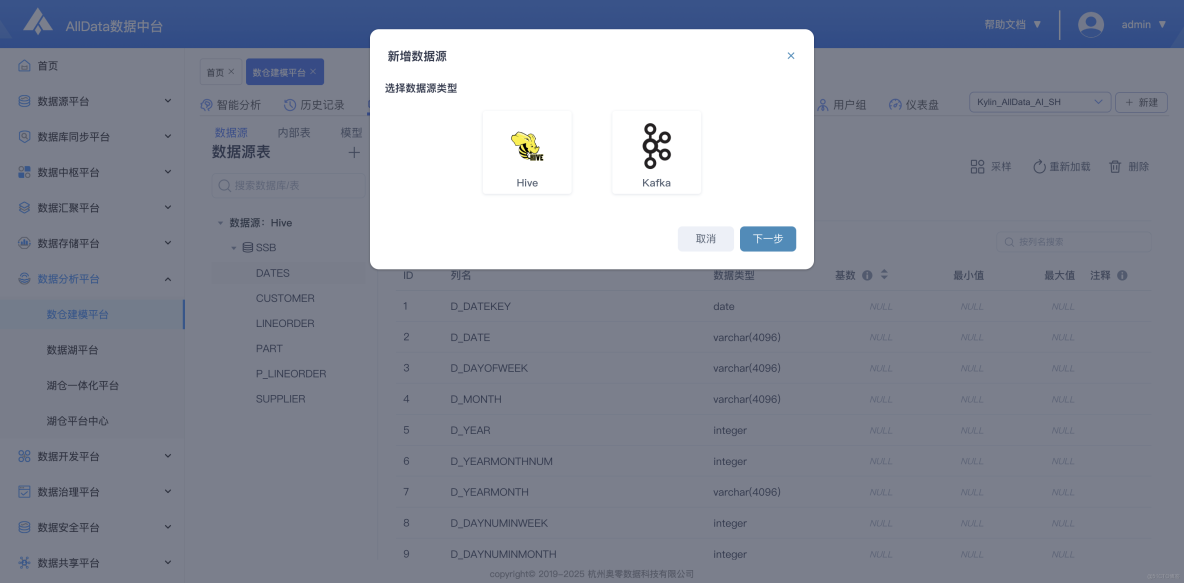
2、智能分析-新增數據源
- 智能分析模塊支持便捷新增數據源,可快速接入多類型數據,拓展分析維度與數據覆蓋範圍。
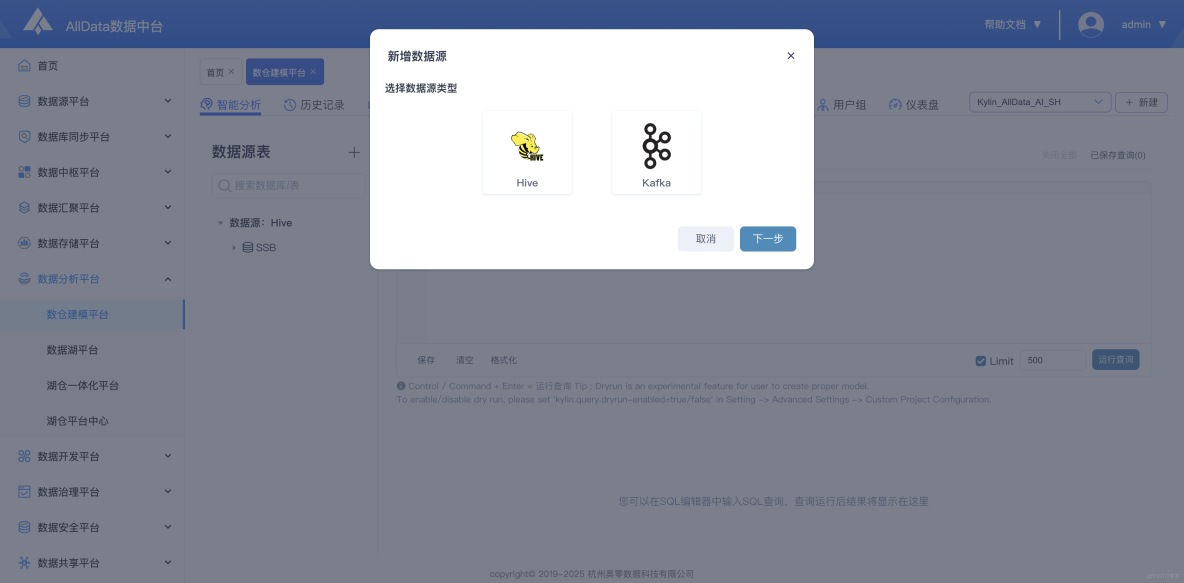
3、數倉建模平台-新建項目
- 支持一鍵新建項目,可自定義配置數據模型與指標,快速搭建個性化數據分析環境。
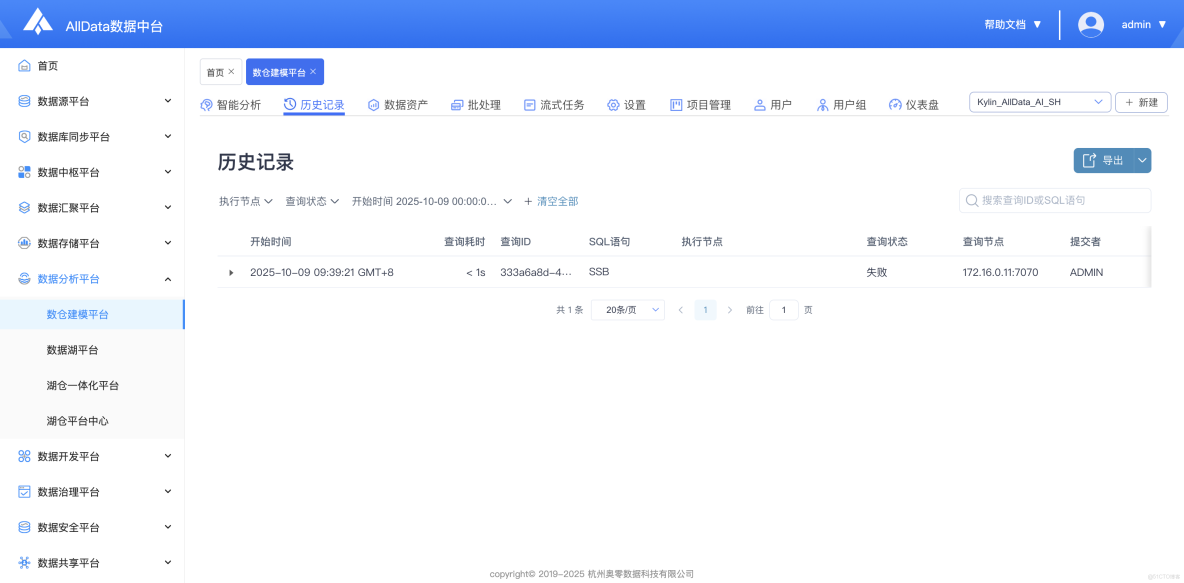
4、歷史記錄
- 自動記錄操作歷史,支持按時間、類型篩選查看,便於追溯修改軌跡與審計覆盤。
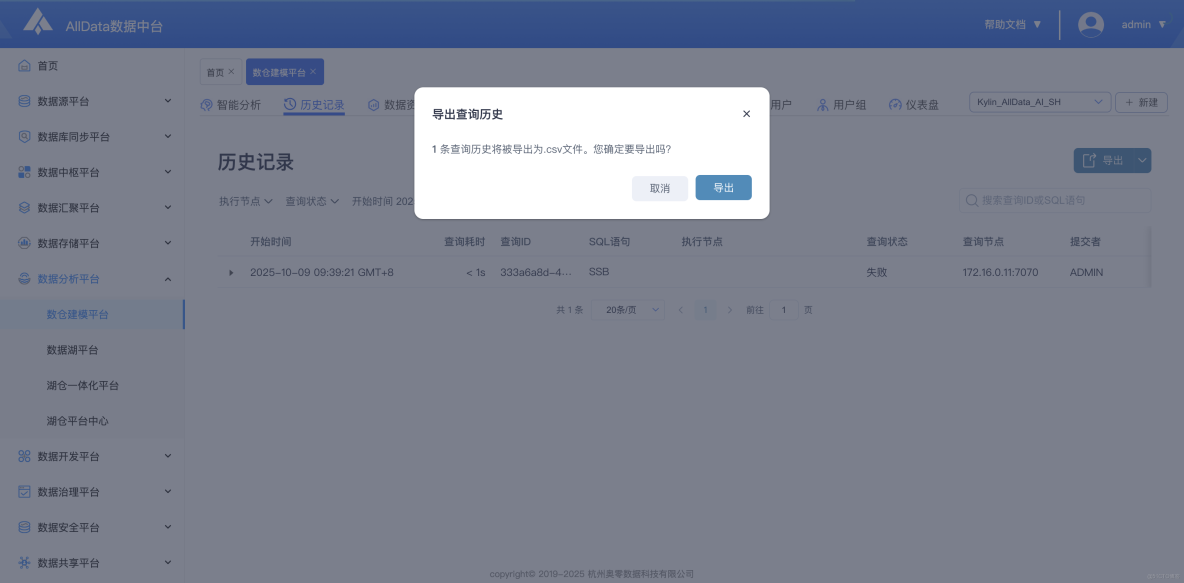
5、歷史記錄-導出
6、數據資產-數據源
- 數據資產模塊可集中管理數據源,支持多類型接入、元數據查看及權限靈活配置。
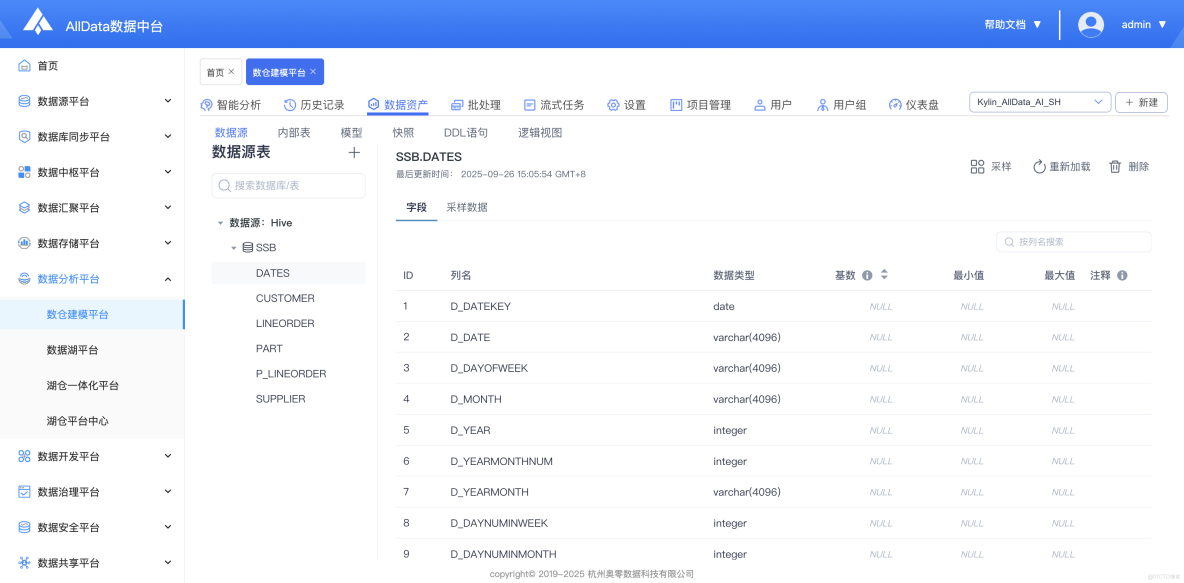
7、數據資產-數據源-新增數據源
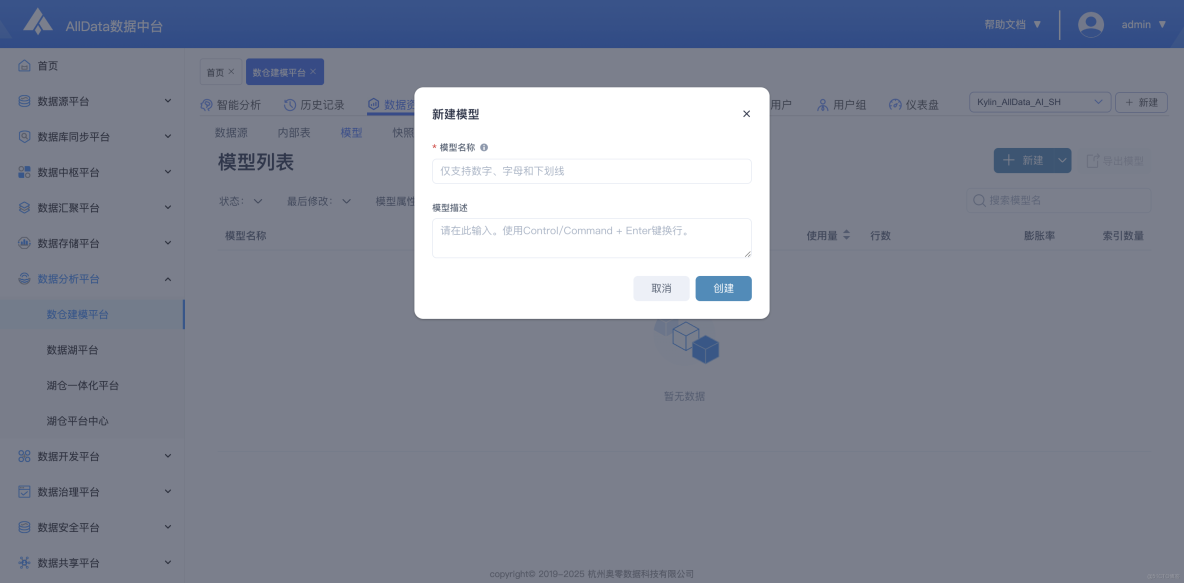
8、數據資產-模型列表-新建模型
- 可自定義維度指標,快速構建適配業務場景的數據分析模型。
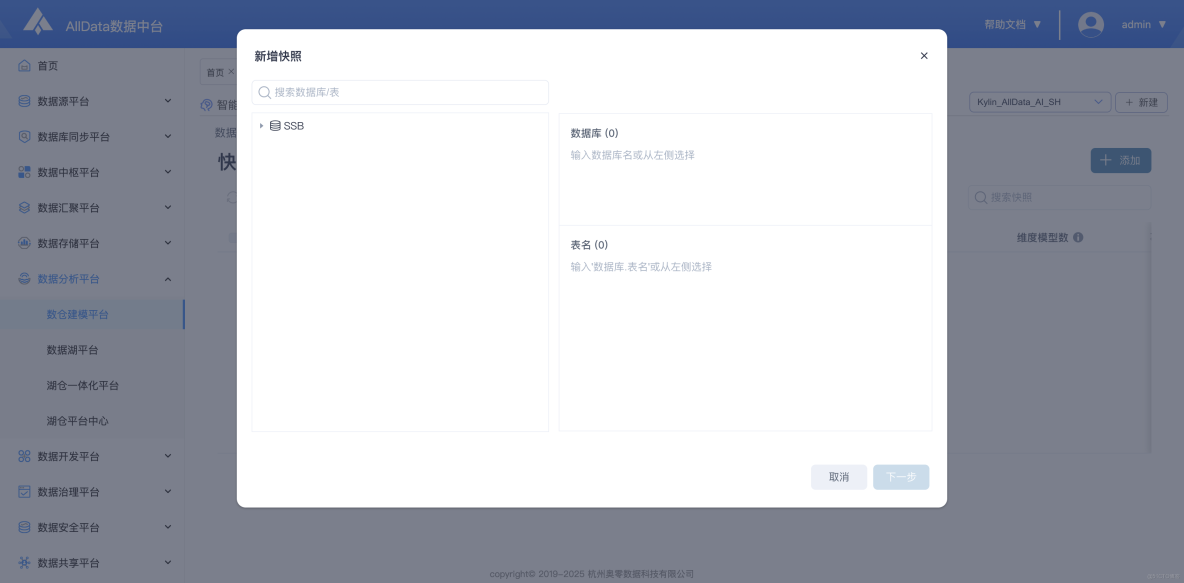
9、數據資產-快照-新建快照
- 支持在數據資產快照模塊新建快照,可定時刻錄數據狀態,保障數據安全與歷史版本回溯。
10、批處理
- AllData數倉建模平台依託Kylin,支持大規模批處理,可高效處理海量數據,實現批量分析與計算任務。
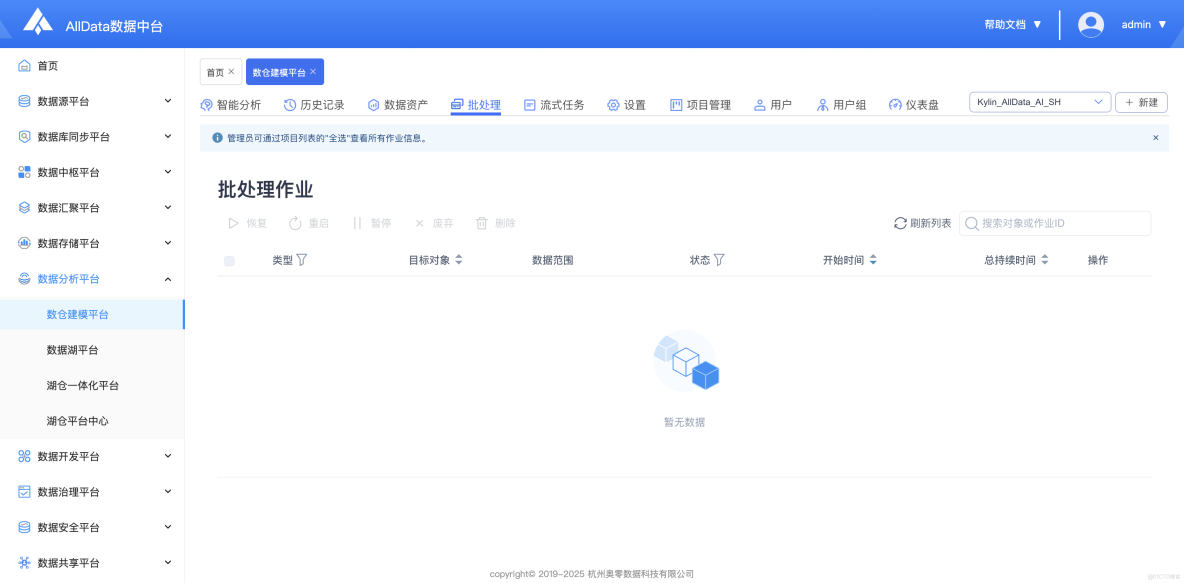
11、流式任務
- 支持實時流式任務處理,可高效捕獲、分析動態數據流並即時響應。
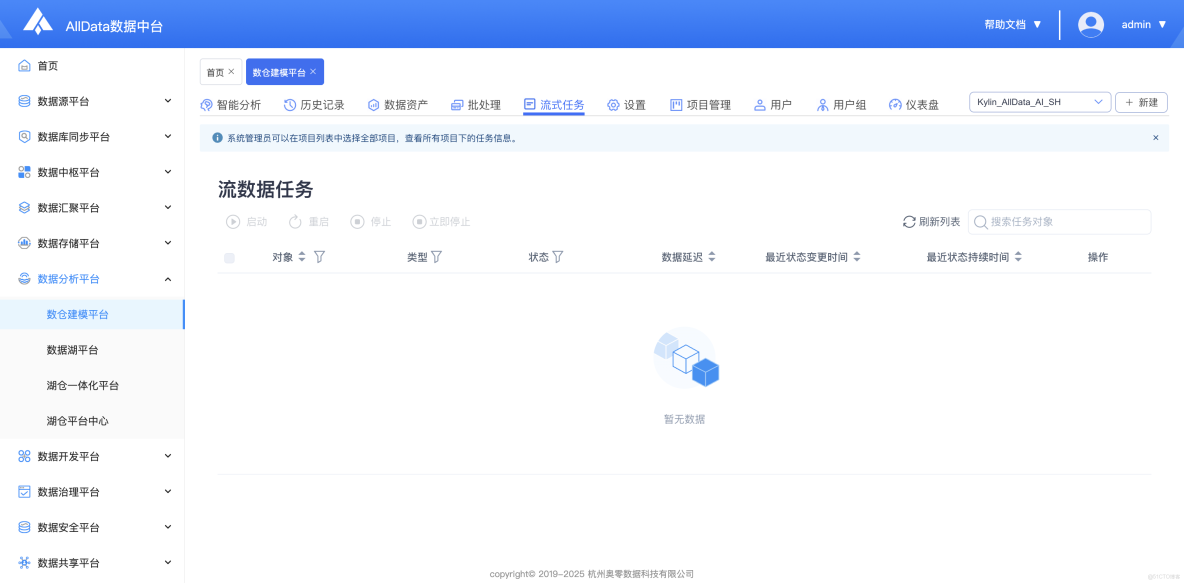
12、設置-基礎設置
- 基礎設置模塊,可配置系統參數、權限及數據連接,靈活適配多樣化業務場景需求。
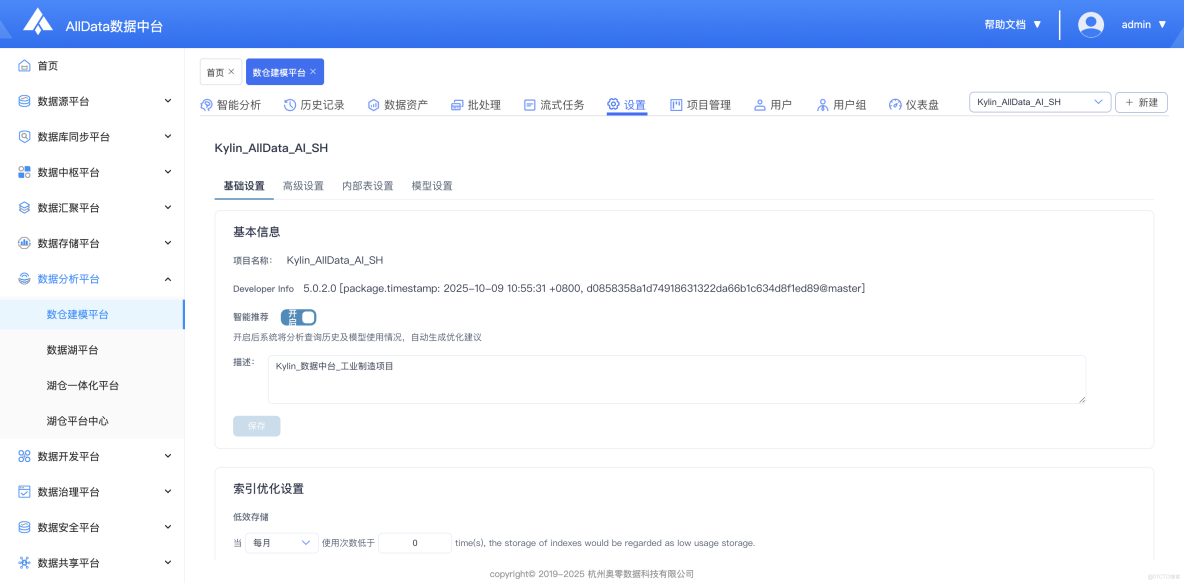
13、設置-高級設置
- 高級設置支持Kylin引擎調優、資源分配定製及複雜計算規則配置,滿足精細化管控需求。
14、設置-內部表設置
- 內部表設置模塊,可自定義表結構、索引及存儲策略,優化Kylin底層數據組織與查詢效率。
15、設置-模型設置
- 支持定義維度、指標及聚合方式,靈活適配Kylin模型,優化數據分析性能。
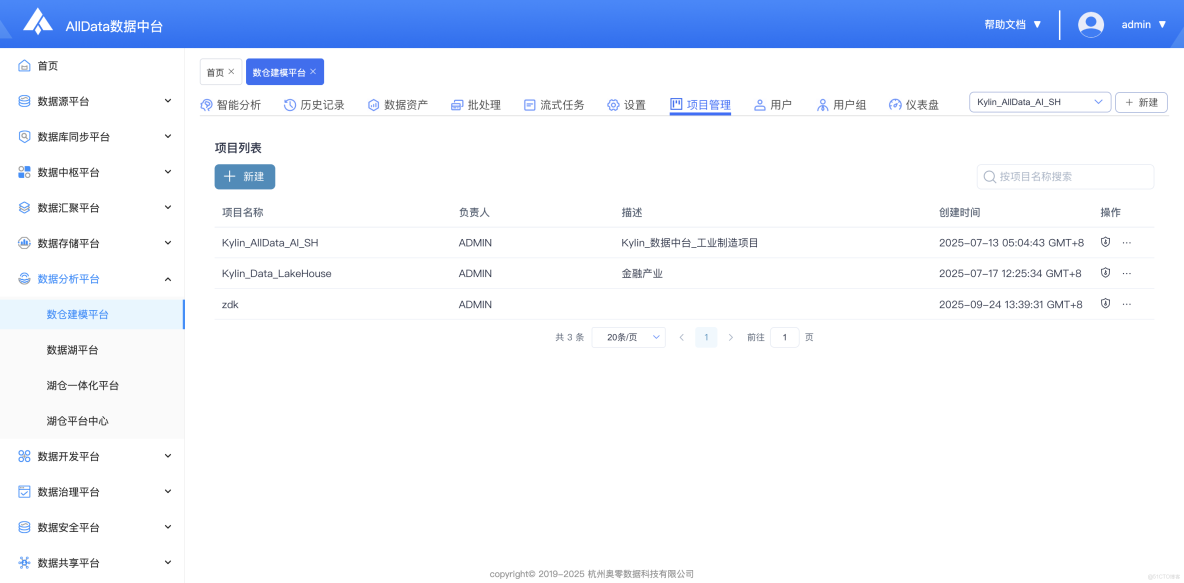
16、項目管理
- 支持多項目創建、權限分配與資源隔離,助力團隊高效協作與數據資產管控。
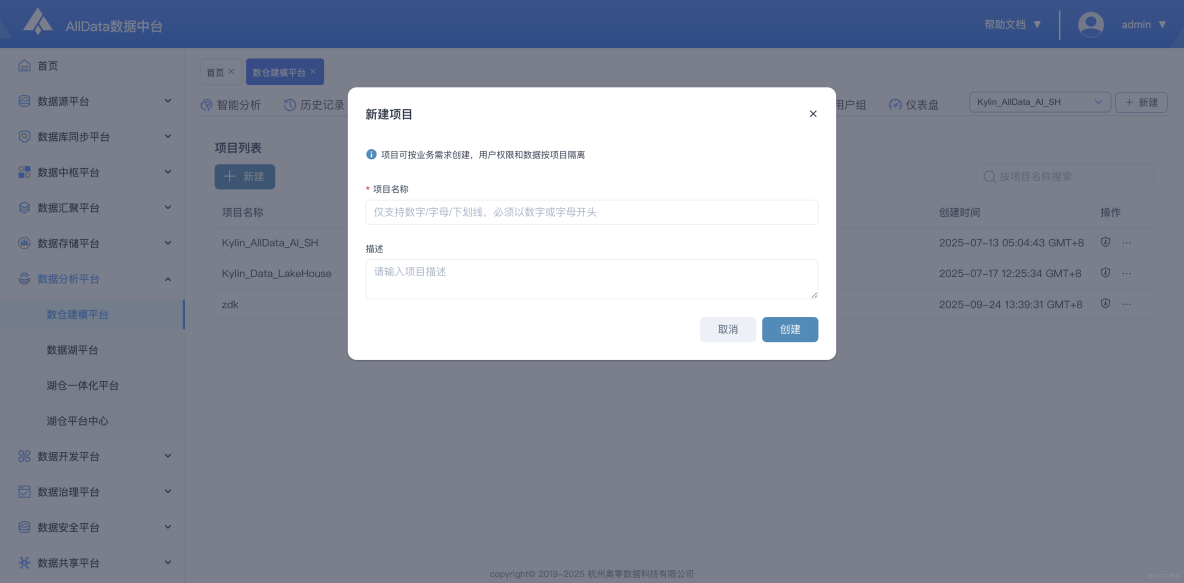
17、項目管理-新建項目
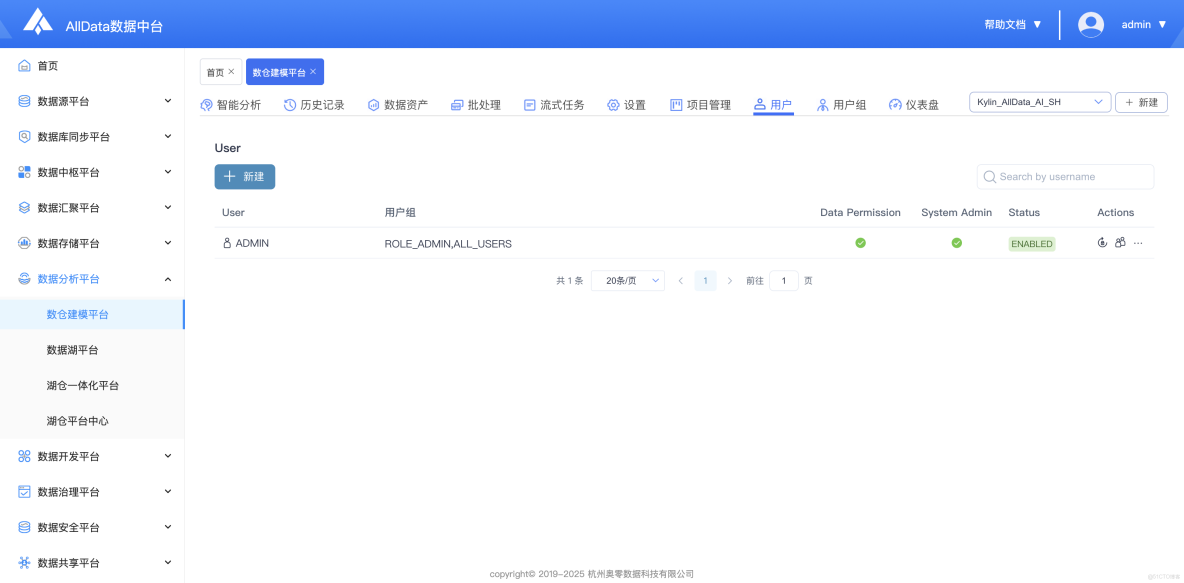
18、用户
- 提供用户管理功能,支持角色分配、權限細控,保障不同用户安全訪問Kylin相關數據資源。
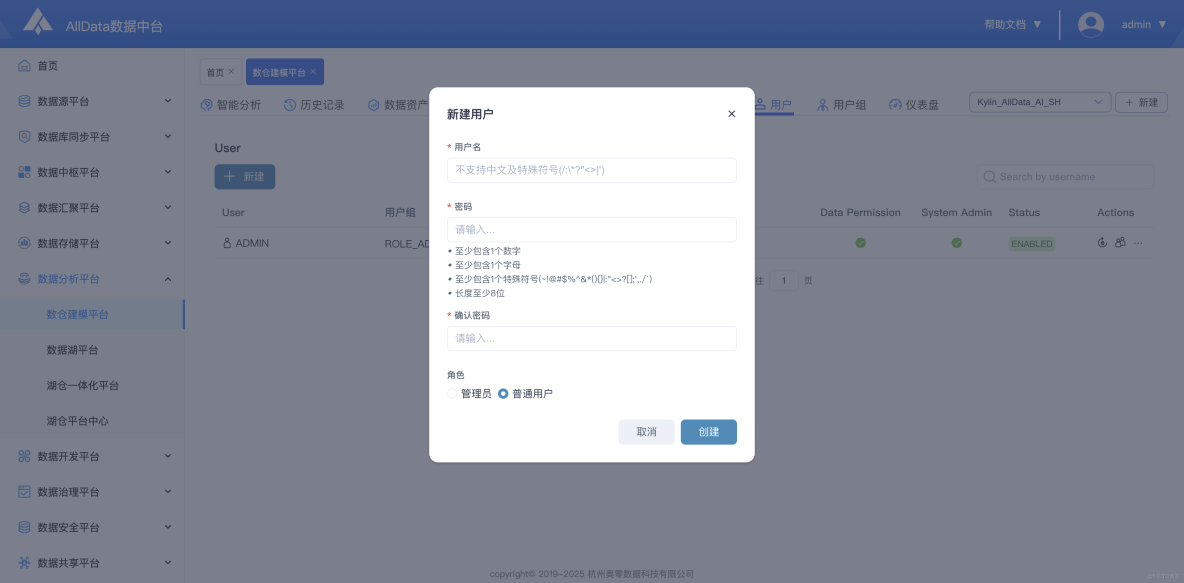
19、用户-新建用户
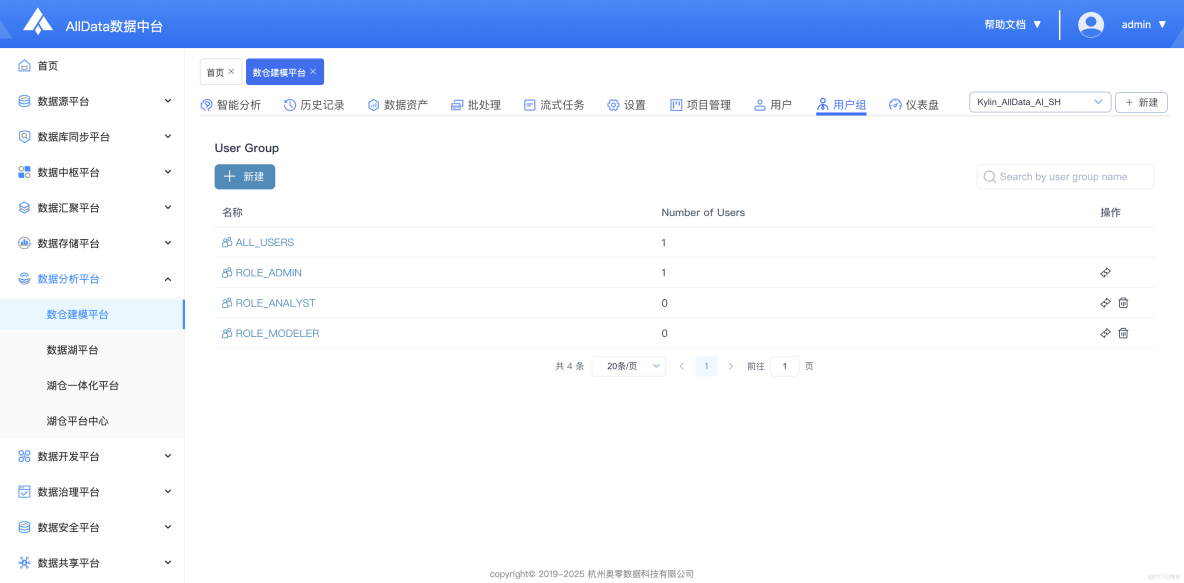
20、用户組
- 支持用户組管理,可批量分配權限、資源,實現用户分類管控,提升Kylin數據操作協作效率。
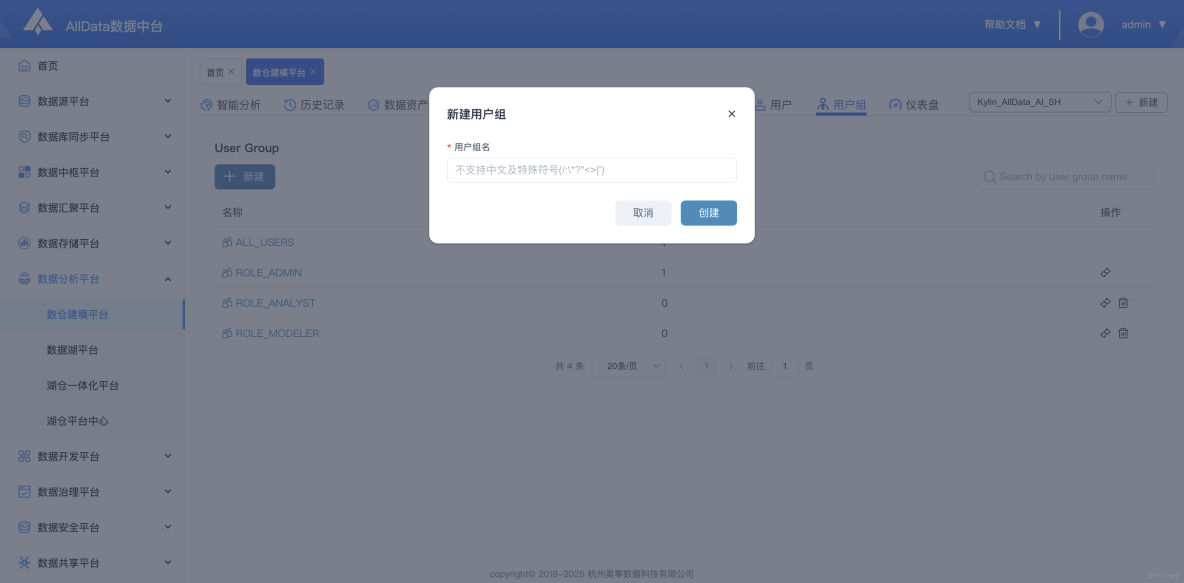
21、用户組-新建用户組
22、儀表盤
- 提供可視化圖表,支持實時監控與交互式數據分析。