

前言:
在國產大模型從技術迭代走向產業落地的關鍵階段,能夠適配真實複雜場景的穩定性能與高效運行能力,成為企業與開發者選型的核心標準。AI Ping 平台(作為專注於模型實測與對比的一站式服務入口,正為行業提供解決方案 —— 現已正式上線 GLM-4.7 與 MiniMax M2.1 兩大旗艦模型的服務,憑藉多供應商接入、性能可視化、統一調用等核心優勢,讓用户零門檻驗證模型價值。
速戳 註冊登錄,立享 30 元算力金,免費解鎖 GLM-4.7&MiniMax M2.1 旗艦模型實測!
一、AI Ping 平台:模型實測與調用的 “全能助手”
AI Ping 平台的核心定位是打破模型選型的信息差與接入壁壘,為用户提供 “可對比、可信賴、可高效調用” 的模型服務環境。其核心優勢集中在三點:
多供應商保障:已接入 6 家頭部供應商,覆蓋 GLM-4.7 與 MiniMax M2.1 的官方及優質渠道,在調用速度、穩定性上形成多重保障,可靠性均達 100%;
全維度性能透明:通過數據看板實時展示各供應商的吞吐量、延遲、上下文長度、價格等關鍵指標(數據截至 2025 年 12 月 23 日 18:00),用户無需自行測試即可直觀選型;
高效調用體驗:支持一套接口統一調用所有供應商模型,無需重複接入維護;同時配備智能路由功能,高峯時段自動切換更優供應商,確保業務連續運行。目前平台所有模型服務均免費開放,用户註冊即可零門檻體驗,快速跑通複雜工程與長時 Agent 任務。
目前 GLM-4.7、MiniMax-M2.1、DeepSeek-V3.2 等旗艦模型可,更有邀請好友雙方各得20元算力點的活動,上不封頂。




二、兩大旗艦模型:差異化的成熟技術路線
GLM-4.7 與 MiniMax M2.1 作為國產模型的代表性產品,均跳出單輪生成質量的競爭,聚焦真實場景的長期穩定運行,但其技術路線與核心優勢各有側重:
(一)GLM-4.7:複雜工程任務的 “穩定交付專家”
GLM-4.7 以 “工程交付能力” 為核心,專為複雜多步驟任務設計:
- 編碼能力上,強調複雜任務的穩定完成與落地交付,確保每一步推理都能貼合工程需求,避免中途失效;
- Agent 與工具調用方面,通過獨特的可控思考機制,大幅提升多步任務的執行穩定性,減少流程中斷風險;
- 長期運行優化上,支持推理強度按需調節,用户可根據任務重要性在準確率與成本之間靈活取捨,適配不同預算與質量需求。
AI Ping 內有各個廠商當日的模型供應數據
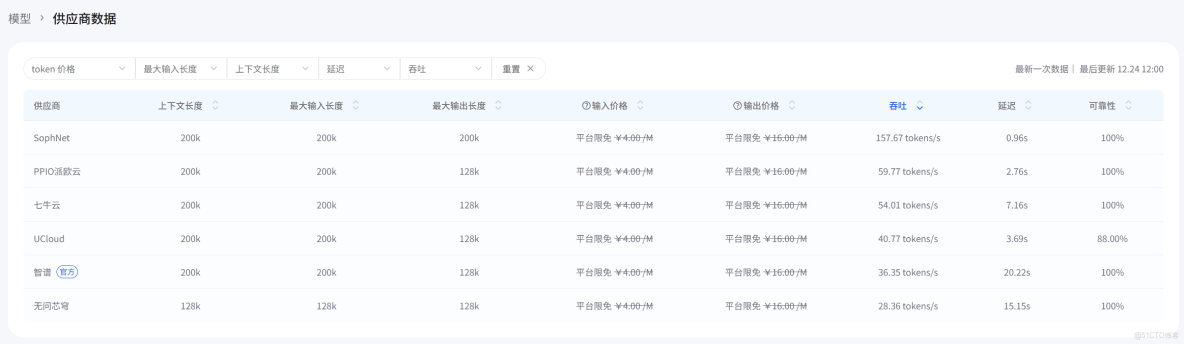
下方還有API調用示例
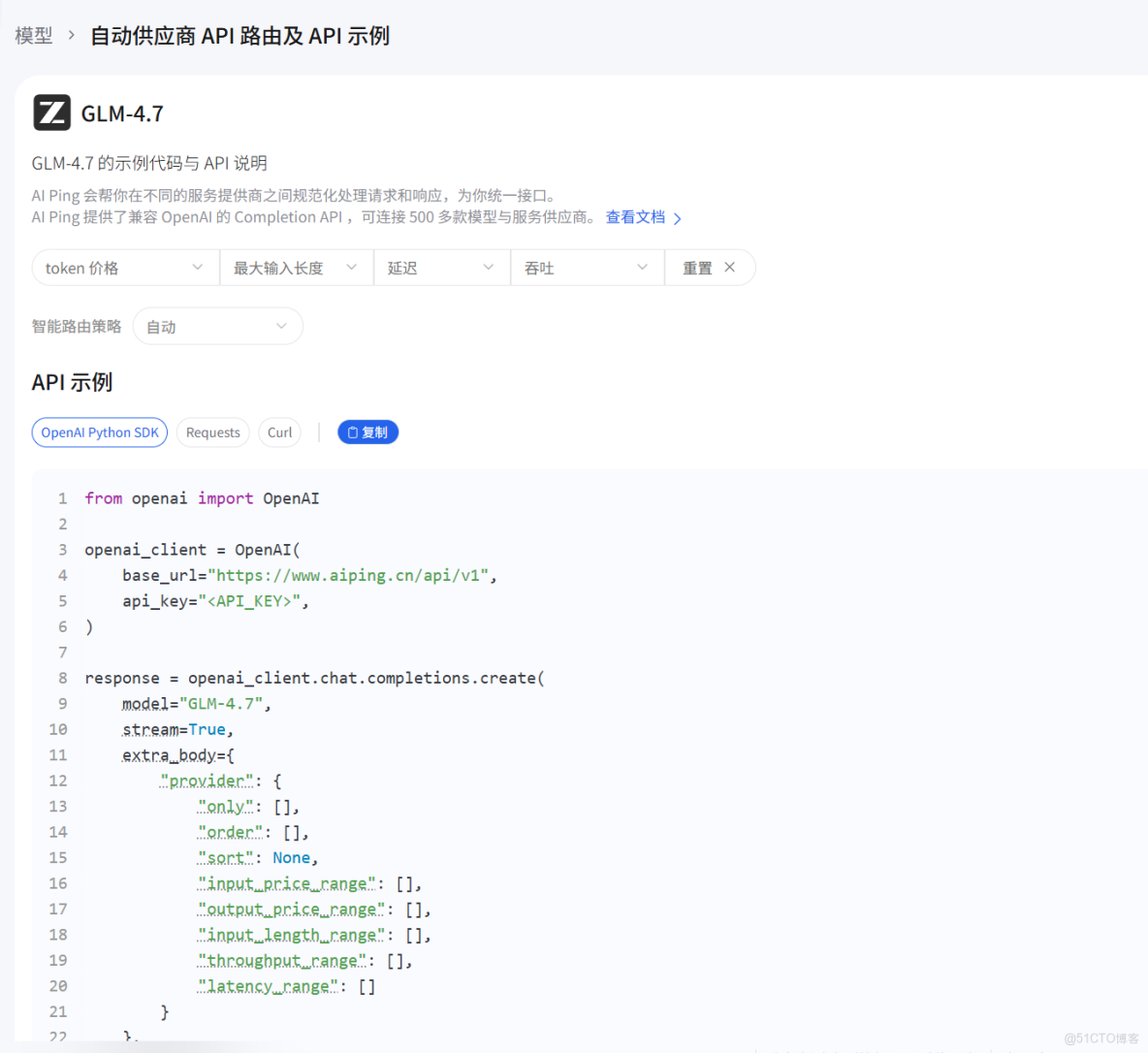
from openai import OpenAI
openai_client = OpenAI(
base_url="https://www.aiping.cn/api/v1",
api_key="QC-4765ed5382195ffdfcf1fad6ddf5c597-9f089d5740fbb06ec22cd0fd581d550c",
)
response = openai_client.chat.completions.create(
model="GLM-4.7",
stream=True,
extra_body={
"provider": {
"only": [],
"order": [],
"sort": None,
"input_price_range": [],
"output_price_range": [],
"input_length_range": [],
"throughput_range": [],
"latency_range": []
}
},
messages=[
{"role": "user", "content": "Hello"}
]
)
for chunk in response:
if not getattr(chunk, "choices", None):
continue
reasoning_content = getattr(chunk.choices[0].delta, "reasoning_content", None)
if reasoning_content:
print(reasoning_content, end="", flush=True)
content = getattr(chunk.choices[0].delta, "content", None)
if content:
print(content, end="", flush=True)
(二)MiniMax M2.1:長時 Agent 運行的 “高效標杆”
MiniMax M2.1 依託高效 MoE(混合專家)架構,聚焦 “Agent 長期運行效率”:
- 編碼能力上,系統強化 Rust、Go、Java、C++ 等多語言工程支持,深度適配真實生產級代碼開發,滿足專業編程場景需求;
- Agent 與工具調用方面,通過高效 MoE 架構與收斂推理路徑,特別適合連續編碼、長鏈 Agent 執行等需要持續運行的場景,避免長流程中的效率衰減;
- 長期運行優化上,憑藉低激活參數與長上下文優勢(最高支持 200k),在提升吞吐效率的同時,降低持續運行的資源消耗,兼顧速度與成本。
AI Ping 內有各個廠商當日的模型供應數據

下方還有API調用示例
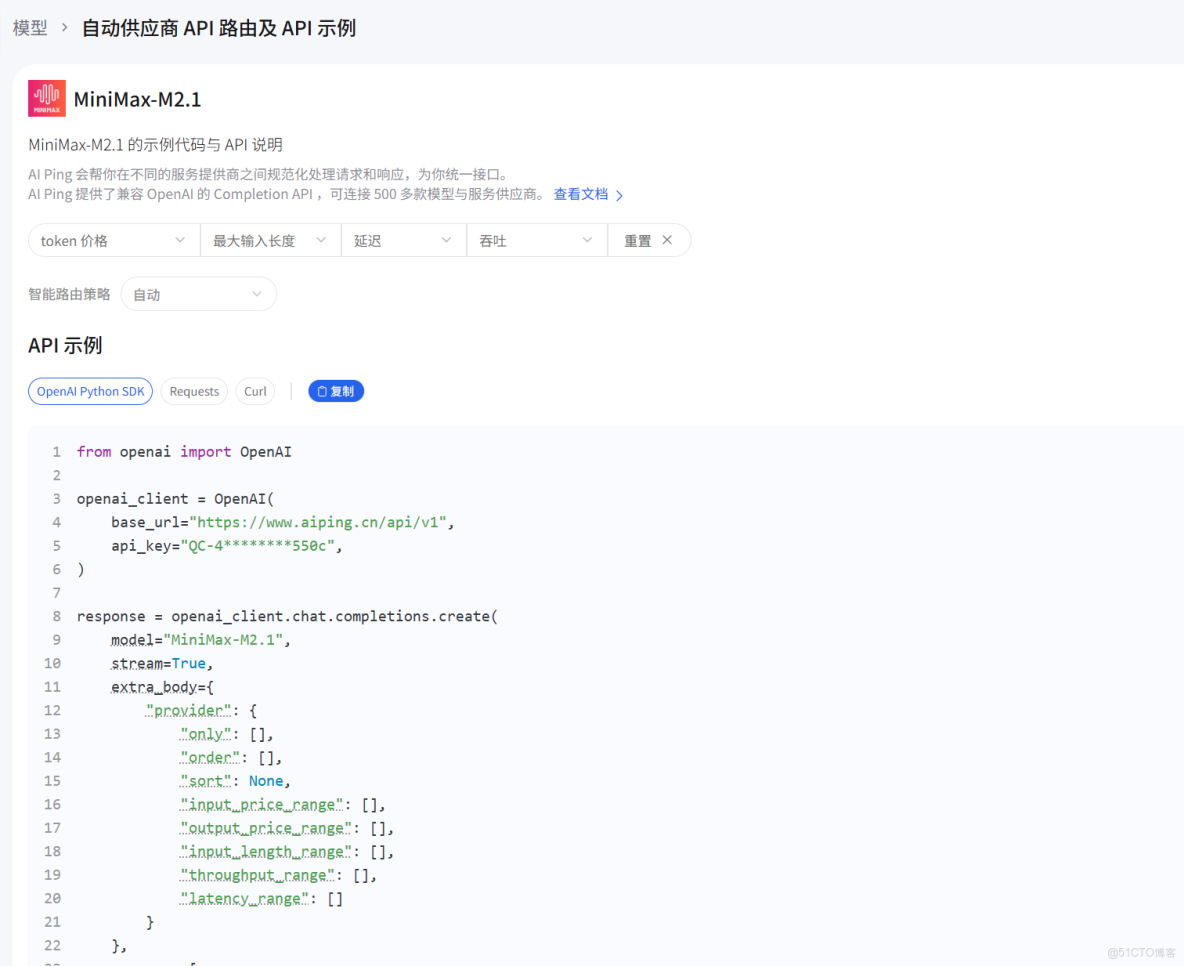
from openai import OpenAI
openai_client = OpenAI(
base_url="https://www.aiping.cn/api/v1",
api_key="QC-4765ed5382195ffdfcf1fad6ddf5c597-9f089d5740fbb06ec22cd0fd581d550c",
)
response = openai_client.chat.completions.create(
model="MiniMax-M2.1",
stream=True,
extra_body={
"provider": {
"only": [],
"order": [],
"sort": None,
"input_price_range": [],
"output_price_range": [],
"input_length_range": [],
"throughput_range": [],
"latency_range": []
}
},
messages=[
{"role": "user", "content": "Hello"}
]
)
for chunk in response:
if not getattr(chunk, "choices", None):
continue
reasoning_content = getattr(chunk.choices[0].delta, "reasoning_content", None)
if reasoning_content:
print(reasoning_content, end="", flush=True)
content = getattr(chunk.choices[0].delta, "content", None)
if content:
print(content, end="", flush=True)
(三)模型核心差異對比:找準適配你的業務場景
|
對比維度
|
GLM-4.7
|
MiniMax M2.1
|
|
核心定位
|
複雜工程任務的穩定交付
|
長時 Agent 工作流的高效運行
|
|
編碼適配場景
|
通用複雜工程任務,側重交付穩定性
|
多語言生產級編碼,側重專業編程支持
|
|
Agent 運行優勢
|
多步任務穩定,可控性強
|
長鏈連續執行,效率高、衰減低
|
|
長期運行策略
|
推理強度可調,靈活平衡準確率與成本
|
低激活參數 + 長上下文,高吞吐、低消耗
|
|
實測關鍵性能(最優供應商)
|
延遲 P90 0.61s(智譜官方),吞吐量 50.47 tokens/s(PPIO 派歐雲)
|
延遲 P90 0.54s(七牛雲),吞吐量 99.75 tokens/s(七牛雲)
|
從實測數據來看,MiniMax M2.1 在吞吐量上優勢顯著,最高達 99.75 tokens/s,延遲更低至 0.54s,適合對速度要求高的長時任務;GLM-4.7 則在多供應商選擇上更豐富,且推理強度可調的特性更適配對質量與成本有靈活需求的複雜任務。
三、如何使用AI Ping
現在我們需要調用api接口,給我們的項目進行ai賦能,給遊戲添加ai對戰功能。
首先打開我們的AI Ping 官網,找到MiniMax模型的API頁面,點擊複製
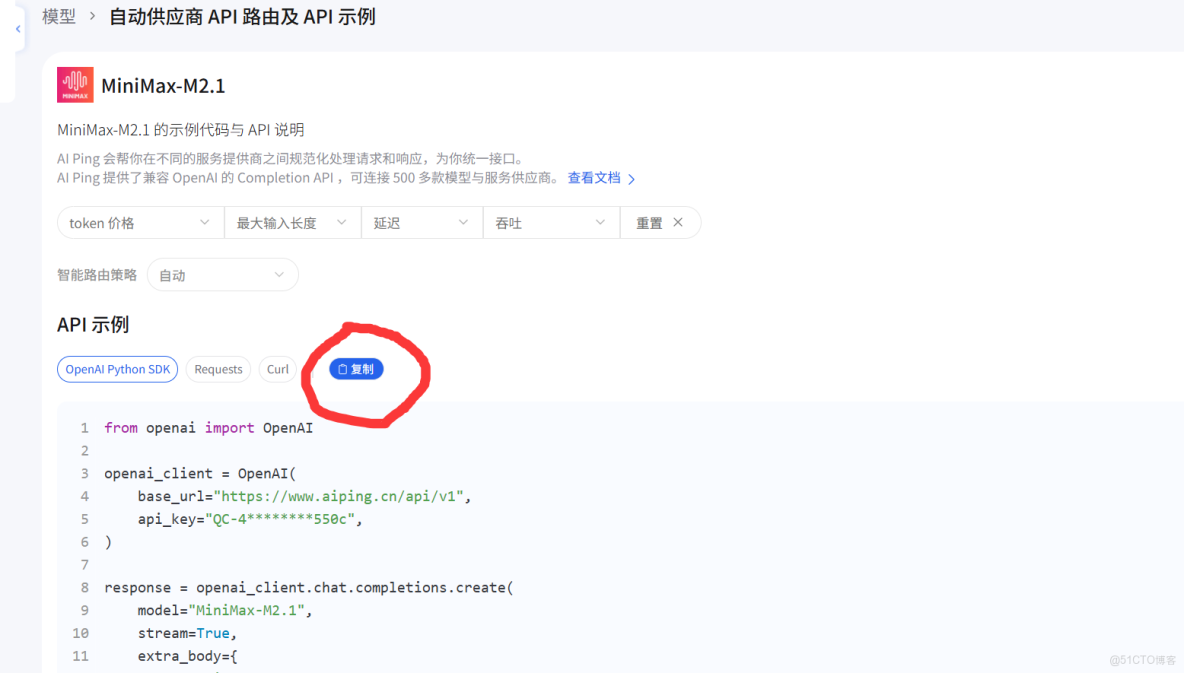
接着我們打開Trae
像trae提出我們的需求,並且把剛剛複製的api給它
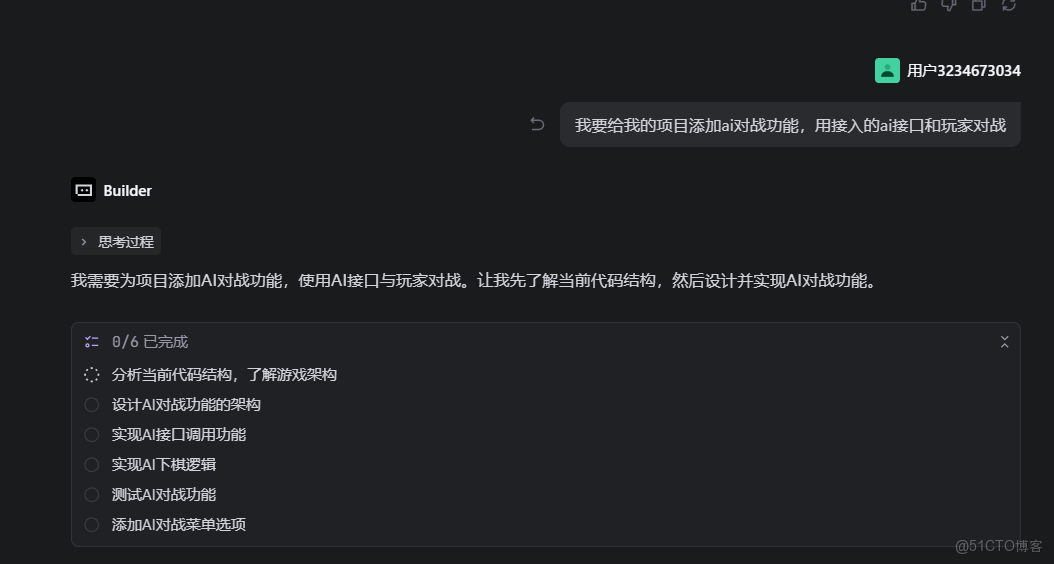

接着trae就開始思考了,我們耐心等待即可


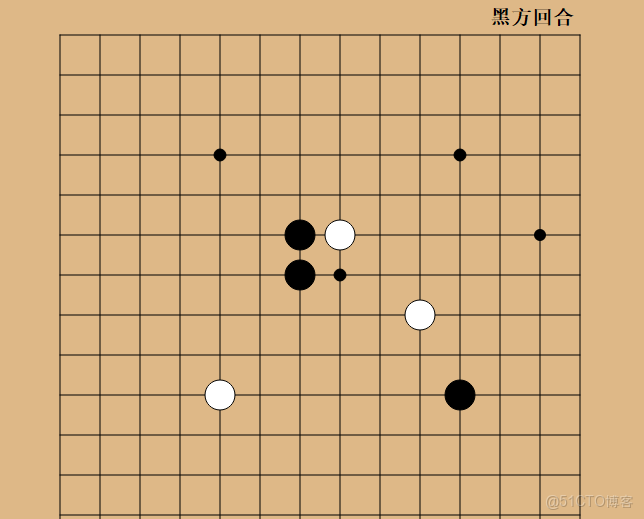
最後展示結果
此時我們每下一顆棋子,AI就會下一顆棋子,這樣就完成了對戰
四、總結:快速鎖定最優模型方案
AI Ping 平台的上線,讓 GLM-4.7 與 MiniMax M2.1 這兩款差異化旗艦模型的實測對比變得簡單高效。無論你是需要穩定交付複雜工程任務,還是追求長時 Agent 運行的高效性,都能在平台上通過透明的性能數據、零成本,快速驗證哪種模型與供應商方案更適配你的業務。
更具吸引力的是,平台當前推出 “邀請好友領算力” 活動:邀請好友註冊 AI Ping 賬號,雙方均可獲得 20 元平台算力點,全場模型與供應商通用,邀請無上限!現在登錄 註冊即可解鎖權限,藉助平台的統一調用與智能路由功能,省去接入麻煩,專注於業務創新。國產模型的真實實力,等你來親自驗證!