12 月 10 日,智譜 AI 正式開源最新多模態大模型 GLM-4.6V,其在圖像理解、圖表解析、細粒度視覺描述等領域的表現全面超越 GPT-4V、Qwen-VL 等主流模型,為基於文檔的智能問答、分析生成提供了更強大的技術支撐。
多模態大模型在處理含複雜表格、手寫批註、多元素融合的文檔時,長期存在因信息提取不精準、語義理解不充分而產生 “幻覺”—— 輸出與文檔實際信息脱節的虛構內容的問題,這也是眾多大模型持續優化升級的方向。這一問題削弱了大模型的應用價值,更可能給工作帶來潛在風險。
如何從源頭解決文檔理解環節的信息偏差,讓大模型的強大能力充分落地?合合信息的 TextIn 文檔解析工具給出了針對性解決方案。
大模型“幻覺”的隱患
大模型基於文檔回答時的 “幻覺” 問題,已成為制約工作效率與結果可靠性的核心痛點,其難點與連鎖影響集中體現在三方面:
● 文檔理解存在天然侷限:多模態模型雖具備圖像識別能力,但面對複雜表格(如合併單元格、跨頁表、框線殘缺表)、手寫批註、印章覆蓋的文檔,或融合文本、圖表、公式、簽名的多元素綜合體時,難以精準提取關鍵信息,無法完成基礎的 “信息讀懂” 環節,只能通過 “腦補” 填補信息空白,導致幻覺產生。
● 效率提升預期落空:當用户藉助大模型生成行業報告分析、論文數據解讀等建議性內容時,若輸出包含大量 “胡言亂語” 式的虛構信息,需額外增加校對環節,逐一核對原文與輸出結果的一致性,不僅未節省時間,反而增加了工作流程,違背了效率提升的初衷。
● 潛在風險隱患突出:在合規審核、數據核對等嚴肅場景中,人工校對的疏漏可能導致錯誤信息流入後續工作,引發合規風險或決策偏差,而幻覺帶來的信息失真,正是這類風險的核心源頭。
TextIn 文檔解析,讓文檔成為大模型可讀懂的語言
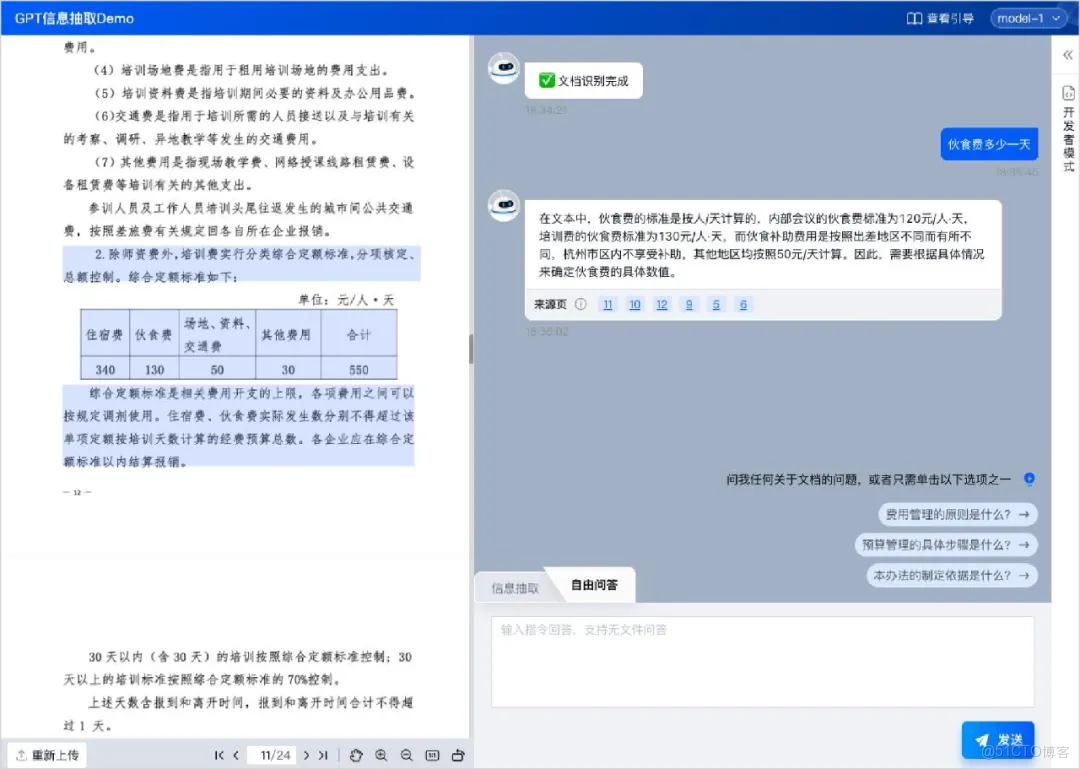
TextIn 文檔解析工具聚焦大模型 “讀不懂文檔” 的源頭矛盾,以 “精準解析 + 結構化輸出” 為核心,為大模型提供高質量輸入數據,從根本上減少幻覺產生。其核心定位是 “大模型加速器”,通過先進的深度學習技術,將非結構化文檔按邏輯與元素分離識別,精準提取文本、表格、圖表、公式、手寫體、印章等各類信息,並轉化為模型可直接理解的結構化格式,讓大模型能 “清晰讀懂” 文檔細節,避免 “腦補式” 回答。
該工具支持 PDF、Word、Excel、圖片、手寫筆記等多種文檔格式,可適配行業報告、學術論文、合規文件、業務單據等各類應用場景,既適用於個人高效辦公,也能滿足企業級文檔處理的嚴苛需求,與主流多模態大模型形成完美協同。

操作步驟講解
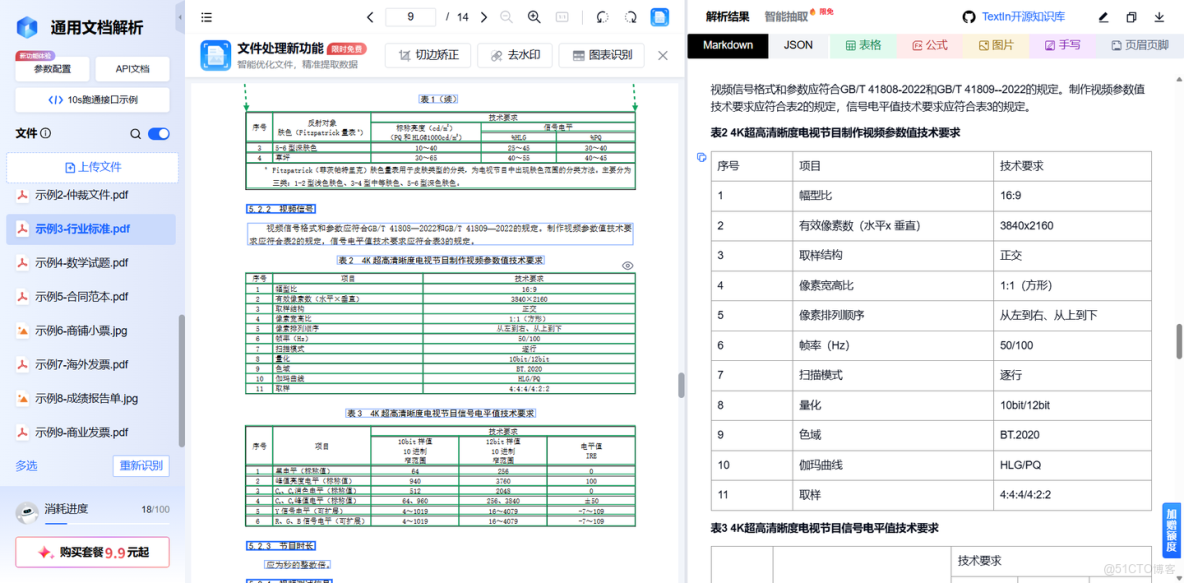
● 文檔上傳與初始識別:將含複雜表格、多元素的目標文檔(如行業報告、論文、合規文件等)上傳至 TextIn 平台,工具會自動啓動多模態元素掃描,快速定位文檔中的表格、文本、手寫體、印章、圖表、公式等核心元素,完成初步分類,為針對性解析奠定基礎。
● 針對性元素解析與數據抽取:針對不同類型元素啓動專項解析能力:
○ 複雜表格:精準切割單元格邊界,完整還原合併單元格、跨頁表、框線殘缺表的結構,將數據高保真抽取為 Markdown、JSON 等結構化格式;
○ 手寫體 / 印章覆蓋文字:自動分離背景印章干擾,清晰辨識覆蓋內容,對潦草連筆的手寫體保持高識別準確率;
○ 多元素組合文檔:額外分析元素間的上下文關聯,如圖表標題與對應圖表、表格數據與正文論點的對應關係,實現語義層面的深度解析。
● 結構化數據輸出與模型對接:解析完成後,工具輸出語義清晰、格式規範的結構化數據,用户可直接將該數據作為輸入傳遞給大模型,模型基於精準信息生成回答,無需再 “腦補” 缺失或錯誤信息,從源頭避免幻覺。
TextIn 文檔解析的優勢和亮點
● 複雜表格解析精準,杜絕數據 “失真”:針對行業報告、論文中常見的特殊表格,突破傳統 OCR 識別錯誤率高、人工錄入效率低的侷限,通過深度學習模型實現表格結構完整還原與數據高保真抽取,輸出的結構化格式可直接對接大模型,為回答提供 “無偏差” 的數據基礎,從核心場景減少幻覺。
● 抗干擾識別能力強,保障關鍵信息完整:面對手寫簽名、批註、印章覆蓋等干擾因素,具備強大的圖像處理與文字識別能力,確保簽字頁、手寫備註等關鍵信息不遺漏、不誤讀,既滿足監管對文件 “清晰、準確” 的要求,也避免大模型因關鍵信息缺失而產生幻覺。
● 多元素語義關聯,實現深度結構化:不同於僅能識別單個元素的普通工具,TextIn 能理解文檔中文本、表格、圖表、公式等元素間的上下文邏輯關係,讓輸出的結構化數據不僅 “有內容”,更 “有邏輯”,幫助大模型 “理解” 而非 “猜測” 元素關聯,進一步降低虛構內容的生成概率。
● 適配性廣,協同性強:支持多種文檔格式與主流多模態大模型對接,尤其能發揮 GLM-4.6V 等先進模型在圖表解析、細粒度視覺描述上的優勢,形成 “精準解析 + 高效生成” 的閉環,最大化提升文檔問答的準確性與效率。

TextIn 文檔解析的應用場景
TextIn 文檔解析工具已服務金融、法律、學術、製造等多個行業的企業與個人用户,在減少大模型幻覺、提升工作效率方面取得顯著成效:
● 學術研究場景:某高校科研團隊在使用大模型分析含大量複雜表格的行業調研數據時,未使用 TextIn 解析前,模型對錶格數據的解讀幻覺率達 35%,需花費 2-3 小時校對單篇報告;接入 TextIn 後,表格數據解析準確率提升至 99.2%,模型回答的幻覺率降至 2.8%,單篇報告校對時間縮短至 15 分鐘以內,整體研究效率提升 60%。
● 企業合規審核場景:某金融機構利用大模型處理含手寫批註與印章的合同文件,傳統方式下,模型因無法識別手寫備註和印章覆蓋文字,幻覺導致的審核錯誤率達 18%;使用 TextIn 解析後,手寫體與印章覆蓋文字的識別準確率達 98.5%,模型回答的錯誤率降至 1.2%,合規審核的人工複核成本降低 75%,同時滿足了監管對文件信息準確性的嚴苛要求。
● 市場分析場景:某諮詢公司藉助大模型生成行業報告,涉及多類跨頁表格與圖表,未解析前報告中數據虛構、邏輯矛盾等幻覺問題頻發,客户投訴率達 12%;通過 TextIn 完成文檔結構化處理後,報告數據準確率達 99.5%,幻覺相關投訴率降至 0.8%,報告交付週期縮短 40%,客户滿意度顯著提升。