
2025 年 12 月,OpenAI 正式發佈 GPT-5.2 大模型,以 “職場效率革新” 為核心,推出三版本細分策略,在編程、長文檔分析、多模態處理等專業知識工作場景中實現顯著突破,進一步推動大模型在企業級場景的深度應用。而隨着大模型在科研輔助、金融建模、內部知識庫搭建等私有文檔處理場景的需求激增,RAG(檢索增強生成)技術作為解決大模型私有數據訪問、降低幻覺風險的關鍵方案,其應用效果的優化成為行業關注焦點 —— 數據質量正是決定 RAG 系統能否適配新一代大模型能力、高效處理私有文檔的核心前提。
為什麼RAG的效果參差不齊?
RAG 技術通過 “檢索 + 生成” 的組合模式,讓大模型在回答問題時,先從私有知識庫中精準檢索相關信息,再結合自身知識生成答案,既解決了大模型訓練數據滯後的問題,又能安全處理未公開的私有文檔。但私有文檔往往以 PDF 報告、掃描件、圖文技術文檔、跨頁表格等非結構化形式存在,這些文檔的 “可理解性” 直接影響 RAG 系統的檢索效率與答案准確性。傳統 OCR 工具僅能機械提取文字,卻無法還原文檔的標題層級、段落邏輯、表格結構及跨頁關聯,導致語義斷裂的 “原料” 輸入 RAG 系統後,出現檢索低效、答案失真、信息殘缺等問題。
案例:RAG精度提升,解析的質量是重點!
在企業級私有文檔處理場景中,圖表識別與表格解析是高頻痛點。某團隊嘗試用 RAG 查詢全球工業機器人銷售額的圖表數據時,直接上傳 PDF 文檔的大模型因無法識別圖表結構,導致檢索完全失敗;而經 TextIn 文檔解析為結構化 Markdown 文件後,大模型精準提取了圖表中的關鍵數據,實現準確應答, TextIn文檔解析支持近20種文檔格式。
另一組對比案例更直觀展現了數據質量的影響:在項目進度表格識別測試中,大模型對含特殊字符的表格識別出現明顯錯別字(如 “鱖” 誤判為 “鰥”),且無法保持表格結構;而 TextIn 不僅實現零誤差識別,還能直接導出為 Excel 格式,為後續 RAG 檢索與大模型分析提供了高質量數據支撐。此外,針對財務密集少線表格、跨頁合同段落、多欄佈局論文等傳統 OCR 難以處理的場景,TextIn 均能實現高精度解析,有效解決了私有文檔處理中的結構還原難題;除此之外TextIn對100頁PDF文檔在線解析速度快至1.5秒,支持大規模文檔的批量離線處理,能在3天內高效完成500萬頁PDF的解析工作。

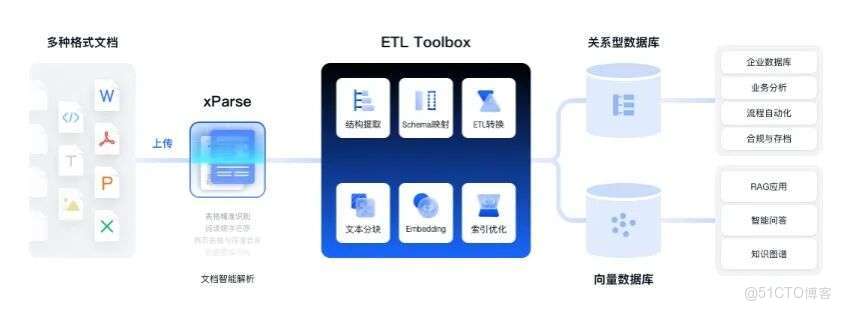
TextIn 文檔解析的核心優勢
● 多格式文檔全兼容:支持 PDF、Word、Excel、PPT、圖片、手寫筆記等十餘種非結構化文件格式,同時適配帶水印、彎曲圖像、掃描件、截屏等特殊載體,覆蓋企業科研文檔、合同文件、生產標準、售後資料等各類私有文檔類型。
● 結構化解析能力突出:能精準識別文本、圖表、公式、表單字段、頁眉頁腳等元素,以及印章、二維碼等子類型,還原標題層級、多欄佈局、跨頁段落與表格關聯,以標準 Markdown 或 JSON 格式輸出,附帶精確頁面元素座標信息。
● 識別精度行業領先:針對合併單元格、無線表格、密集表格等複雜表格,以及 50 + 種語言的文本內容,實現低誤差識別;集成圖像處理能力,可消除模糊、水印等干擾,確保手寫體、影印件等特殊文檔的解析準確性。
● 大模型與開發者友好:生成的數據可直接適配 RAG 分塊策略、向量檢索及 LLM 推理訓練,支持 API 調用及 Coze、Dify、FastGPT 等主流平台插件集成,適配企業自定義工作流程與 AI 應用搭建需求。
為什麼説TextIn文檔解析是大模型加速器?
● 突破傳統 OCR 侷限:相較於僅能 “搬運文字” 的傳統工具,TextIn 通過自研文檔樹引擎,基於語義提取段落 embedding 值、預測標題層級關係,讓文檔解析從 “字符提取” 升級為 “語義理解”,為 RAG 系統提供真正可複用的高質量數據燃料。
● 適配新一代大模型能力:GPT-5.2 等先進大模型在複雜結構化任務中展現出強大潛力,而 TextIn 的高精度解析能力恰好彌補了私有文檔與大模型之間的 “數據鴻溝”,讓大模型的專業處理能力在科研、金融、企業管理等私有文檔場景中充分釋放。
● 降低企業落地門檻:提供免費 1000 次解析服務,搭配簡潔的在線 web 平台與清晰的 API 文檔,企業無需投入大量研發成本,即可快速完成私有文檔的結構化處理與知識庫搭建,顯著提升 RAG 技術的落地效率與應用效果。
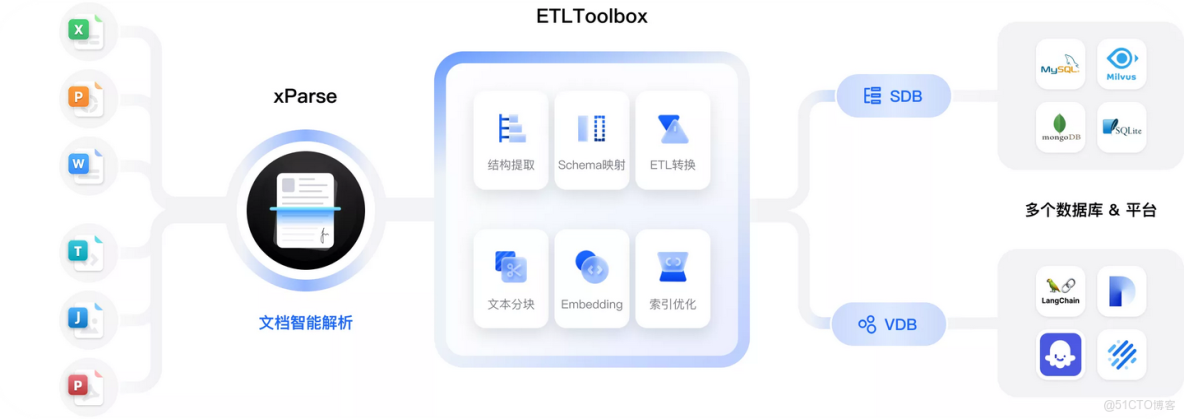
當前,大模型在私有文檔處理領域的應用深度,正取決於 RAG 技術的優化水平。而以 TextIn 為代表的智能文檔解析工具,通過解決數據質量這一核心痛點,讓 RAG 系統真正具備處理複雜私有文檔的能力,為企業在 AI 時代盤活知識資產、提升職場效率提供了可靠支撐。