
傳統OCR工具處理表格數據的相關痛點
信息化工作會議強調推動信息化與工業化深度融合,推進“人工智能+製造”專項行動,培育重點行業智能體,深化中小企業數字化賦能,需依託高質量數據支撐轉型落地。
數據作為數字化轉型的核心要素,其結構化處理效率直接影響轉型成效。但在製造、辦公、企業運營等真實場景中,文檔元素普遍缺乏標準化與格式化特徵,雙欄表格、無線表格等複雜元素高頻出現,表格數據解析混亂成為突出難題。傳統OCR工具在應對這類複雜文檔時,能力短板尤為顯著,具體痛點可梳理為以下兩方面:
痛點一:結構與順序邏輯判斷失效。傳統OCR工具無法準確識別複雜表格的核心結構邏輯,比如跨行合併單元格、嵌套表格的層級關係,同時難以判斷表格內容的順序邏輯,常常直接出現解析失敗的情況,導致文檔核心數據無法提取,無法為數字化轉型提供有效數據支撐。
痛點二:解析內容嚴重失真。即便傳統OCR工具嘗試解析,提取出的表格數據也多與文檔原意“牛頭不對馬嘴”,信息偏差極大。這不僅無法幫助用户高效獲取數據,反而造成大量時間浪費,拖慢工作進度;對於需要批量處理海量生產報表、業務單據等文檔的企業而言,該問題更會放大人力成本損耗,成為制約數字化轉型效率的關鍵瓶頸。
TextIn文檔解析工具的突破
針對傳統OCR工具解析複雜表格易出現結構混亂、內容失真的核心問題,TextIn文檔解析工具提供了極具針對性的替代方案。作為專注於複雜文檔解析的AI工具,其核心目標是解決複雜表格數據的結構化難題,為企業數字化轉型提供高質量數據支撐。
該工具的核心能力具體包括:其一,精準梳理非結構化表格數據,可高效處理跨行合併表格、嵌套表格、無線表格、帶註釋表格等複雜類型,同時兼容手寫筆記、圖片印章等難解析元素,能將混亂的表格數據轉化為大模型友好的結構化格式;其二,全要素精準識別歸類,可精準識別文檔版面內的章節、標題、列表、公式等各類信息要素,按類型篩選提取核心數據,保障數據完整性與準確性;其三,多場景適配性強,支持多種格式文檔處理,提供靈活的輸入輸出方式,適配中小企業到大型企業的不同批量處理需求。
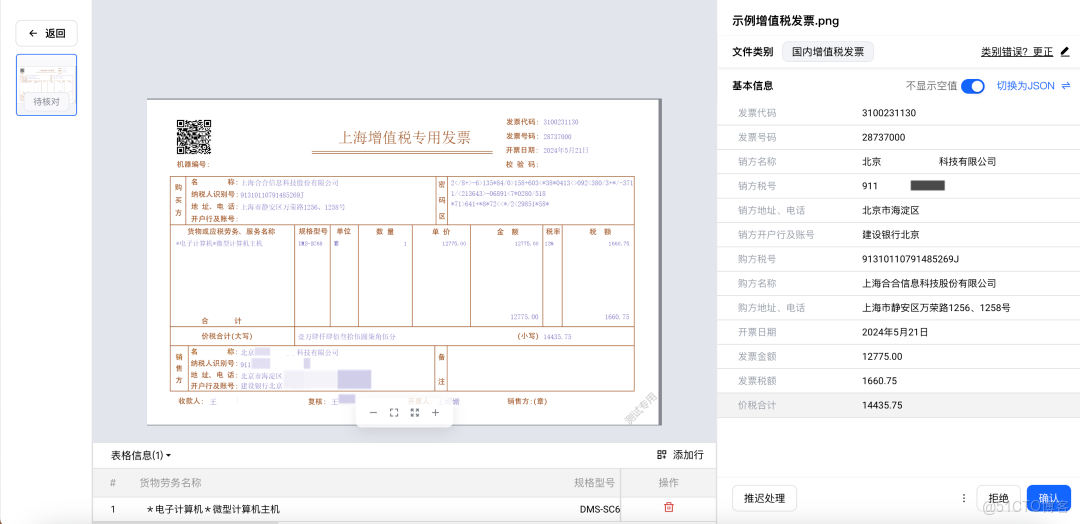
操作步驟講解
TextIn文檔解析工具的操作流程以“零手動干預、高適配性”為核心,針對表格數據解析需求,具體操作步驟如下:
● 步驟1:全類型文檔上傳。無需提前篩選或轉換文檔格式,直接上傳包含有線/無線表格、跨行合併表格、嵌套表格等複雜元素的文檔,支持PDF、Word、DOCX、HTML、JPG、PNG等多種格式,單文檔最高可支持100頁,同時兼容手寫體、掃描件等特殊形式的表格文檔。
● 步驟2:複雜表格精準解析。上傳完成後,工具將自動觸發專屬表格解析算法,無需用户手動設置任何參數或調整表格結構,即可自動識別表格的跨行合併、嵌套等複雜邏輯,完成數據提取與結構化整理。
● 步驟3:靈活輸入輸出選擇。輸入端可根據需求選擇適配方式:在線上傳適合小批量表格處理,API調用適合實時響應的業務場景,本地部署可滿足企業數據安全需求,且支持一次性處理萬頁以上大規模表格數據;輸出端默認生成Markdown/JSON格式文件,無需額外格式轉換,可直接用於下游模型調用、數據統計分析等工作。
● 步驟4:內容溯源與交互校驗。解析完成後,若需校驗表格數據準確性,可通過工具內“原文關聯”功能,直接跳轉至數據在原文中的對應位置,快速完成核對;也可在工具內直接輸入針對表格的疑問(如“表格中某產品的月度產量數據是多少”),工具將基於解析後的準確數據實時響應,輔助快速理解信息。

TextIn文檔解析工具的優勢亮點
● 亮點一:複雜表格識別範圍廣且精準。相較於傳統OCR工具,識別覆蓋範圍大幅拓展,不僅能處理常規表格,還可精準識別手寫體、掃描件對應的表格數據,以及嵌套表格、跨行合併表格等各類複雜表格,從根本上解決“解析結構混亂、內容失真”的核心問題,保障數據質量。
● 亮點二:處理速度極快,適配批量需求。批量解析100頁含複雜表格的文檔最快僅需1.5秒,遠超傳統OCR工具效率;面對企業級大規模需求(如500萬頁+含表格的PDF文檔),可在3天內完成全量解析,大幅縮短表格數據處理週期,適配製造、金融等行業高頻批量處理場景。
● 亮點三:輸入輸出靈活便捷,銜接下游工作。輸入端三種方式兼顧不同場景需求,可滿足不同規模企業的批量處理要求;輸出端標準化格式無需二次轉換,直接銜接大模型輸入、數據統計、業務系統錄入等下游工作,簡化整體工作流程,提升數據利用效率。
● 亮點四:具備溯源與交互能力,降低校驗成本。內容溯源功能為表格數據準確性提供直接核對依據,避免錯誤數據流入下游環節;內置問答交互功能無需手動翻閲文檔,可快速定位特定表格數據,減少信息獲取的時間成本。
TextIn在實踐場景中的應用
案例一:小批量複雜表格快速解析場景。在100頁含跨行合併、無線表格的文檔批量解析場景中,TextIn文檔解析工具最快僅需1.5秒完成解析,且表格數據結構清晰、無失真;相較於傳統OCR工具(平均需30-60秒/100頁,且解析後結構混亂需人工調整),處理速度提升20-40倍,單批文檔處理時間大幅縮短,同時省去人工調整成本。
案例二:企業級大規模表格文檔處理場景。某製造企業需解析500萬頁+含複雜生產報表的PDF文檔,用於後續產能數據分析與數字化運營優化。使用TextIn文檔解析工具後,3天內完成全量處理,解析後的表格數據結構規範、準確率高,可直接導入企業數據分析系統;而傳統OCR工具處理同類任務平均耗時15-30天,且需大量人工修正結構混亂的表格數據。該工具為企業節省80%-90%的時間成本,避免大量人力投入,為數字化運營優化提供了高效的數據支撐。
案例三:長期穩定解析保障案例。某連鎖企業長期需處理每日海量的銷售報表(含各類複雜表格),使用TextIn文檔解析工具後,整體識別穩定率高達99.99%,在百萬級表格文檔解析任務中,幾乎無因解析錯誤導致的返工情況,有效保障了銷售數據統計的質量與效率,為企業庫存管理、營銷策略制定提供了可靠的數據基礎。