
導讀
【重磅】阿里雲 Tair KVCache 團隊聯合阿里巴巴智能引擎、基礎設施與穩定性工程團隊即將開源企業級全局 KVCache 管理服務 Tair KVCache Manager,本文詳細介紹該服務的架構設計與實現細節。
隨着 Agentic AI興起,以推理引擎為中心的傳統單機分層方案已無法滿足新時代的 KVCache 存儲需求。隨着 KVCache 池化存儲在大規模 Agent 推理場景中走向落地,需要構建具備容量精準評估、動態彈性伸縮、多租户隔離、高可用保障及版本協同管理能力的企業級 KVCache 管理系統,以支撐PB級存儲下的成本效益優化與服務可靠性需求。為了解決這些問題,我們設計並實現了一套專為大模型推理場景服務的全局 KVCache 管理服務,支持了阿里巴巴集團 RTP-LLM推理服務加速,並且擴展支持到 vLLM、SGLang 等眾多開源引擎,兼容 Sparse Attention、Sliding Window Attention 等在內的多種注意力機制。
本文將從Agent場景下的KVCache存儲需求出發,在之前文章的基礎上進一步分析該場景下KVCache存儲所面對的挑戰,並介紹Tair KVCache Manager針對這些挑戰所做的架構設計選擇和相關實現。
本系列技術文章將系統性拆解面向智能體推理的 KVCache 技術演進路徑:
1. 智能體式推理對 KVCache 的挑戰與 SGLang HiCache 技術深度剖析
2. 3FS-KVCache 工程化落地:企業級部署、高可用運維與性能調優實踐
3. Hybrid Model Support:SGLang 對 Mamba-Transformer 等混合架構模型的支持方案
4. 本文 | Tair KVCache Manager:企業級全局 KVCache 管理服務的架構設計與實現
5. KVCache 仿真分析:高精度的計算和緩存模擬設計與實現
6. Hierarchical Sparse Attention:分層稀疏注意力框架下的 KV 分層管理與按需加載
7. 展望:KVCache驅動的軟硬結合演進
Tair KVCache 作為阿里雲數據庫Tair產品能力的延伸,本質是緩存範式的三次躍遷:
🔹 從 Redis 的 “緩存數據 → 減少 I/O”
🔹 到 GPU KVCache 的 “緩存計算中間態 → 減少重複計算”
🔹 再到 Tair KVCache 的 “規模化、智能化的注意力狀態管理 → 重構大模型推理成本模型”它標誌着緩存正從輔助組件升級為 AI 基礎設施層的核心能力——讓“狀態”可存儲、可共享、可調度,支撐智能體時代的規模化推理底座。
1.KVCache服務的三重升級挑戰
1.1 Agent興起重塑KVCache存儲範式
Agent 的興起不僅拉長了推理會話上下文,也讓會話模式發生了明顯變化。這些變化對傳統單機分層+親和性調度方案提出了嚴峻挑戰:
(1)單個會話的輪數和持續時間不斷增加:相較於傳統短時間、低頻的交互模式(如單輪或少數幾輪即結束的請求),Agent 會話往往貫穿任務全生命週期,包含多輪推理請求,持續時間顯著延長。這種“長生命週期”特性使得調度對象事實上從“請求”轉變為“會話”(雖然可能仍以請求為粒度進行調度),調度器需在數十分鐘甚至更長的時間窗口內努力維持 KVCache 和計算的親和性。
(2)併發會話數進一步提升:隨着 Vibe Coding 等範式普及,以及高延遲工具和複雜 MCP(如代碼編譯執行、數倉查詢等)的廣泛集成,單個 Agent 會話中 LLM 推理時長佔比持續下降,等待非推理環節的時間顯著增加。為維持推理集羣的高利用率,系統需要更多併發會話以“填滿”算力間隙。這也顯著增加了調度器的調度難度。
(3)會話間的模式差異擴大:不同 Agent 任務在上下文規模、推理頻次、工具調用模式和延遲敏感度上差異顯著(例如,一個代碼評審Agent可能頻繁小輪次交互,而數據分析Agent則傾向少輪次、大上下文推理),導致固定的算力和存儲配比難以滿足不同場景的差異化需求。
以上幾點導致傳統模式下調度難度不斷增大,KVCache命中率和算力SLO調度目標的衝突日益尖鋭。例如當請求量升高時,調度器需要進行更多的會話遷移以保證SLO,進而導致 KVCache 命中率下降;這又會進一步推高 Prefill 算力需求,導致Prefill負載非線性增長甚至雪崩。
這也使得單機分層方案雖然打破VRAM的限制,進一步擴展了KVCache容量,但卻依然難以完全滿足Agent場景下的KVCache存儲需求。為了進一步解決該問題,我們需要直面該架構下的根本問題:算力資源與KVCache存儲的過緊耦合。
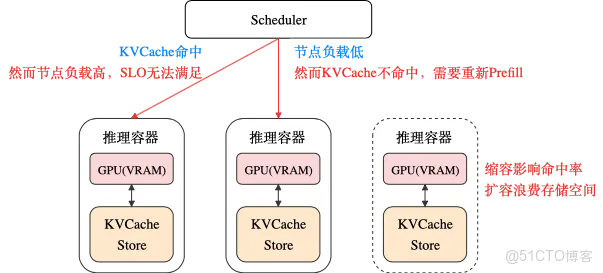
值得慶幸的是,隨着高性能網絡技術不斷演進,智算環境內網絡帶寬快速增長(單端口從25Gbps快速躍升至200+Gbps),互聯規模不斷擴大(千卡、萬卡甚至跨可用區),互聯機型更加多樣(eRDMA等已覆蓋主流存儲機型),讓我們擁有了解耦算力資源和KVCache存儲的可能性。
以阿里云為例,智算場景下KVCache跨機傳輸的典型帶寬約為20GB/s:EGS 8卡機型對應20GB/s通用網絡帶寬,靈駿8卡機型對應25GB/s存儲帶寬(另有200~400GB/s ScaleOut網絡帶寬)。我們以Deepseek和Qwen3-Coder的典型Prefill吞吐為例進行分析,20G/s帶寬均可以滿足KVCache跨機傳輸需求。隨着高性能網絡的繼續演進,我們相信KVCache傳輸帶寬還會進一步擴展,不斷降低跨機傳輸代價。
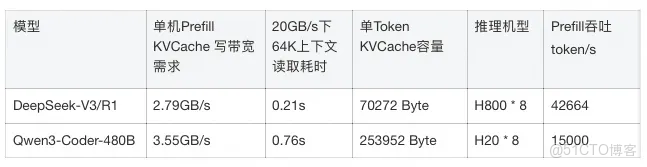
(DeepSeek Prefill吞吐來自於RTP-LLM復現報告[3],DeepSeek官方披露中為32.2K。Qwen3-Coder Prefill吞吐為優化後的部署模式下的粗略估計值,單機部署時實測值約為10000 token/s。)
1.1.1 由此外部KVCache存儲開始從推理綁定走向全局池化:
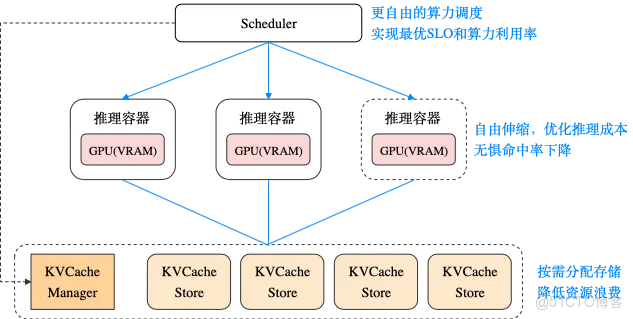
結合高性能網絡和HiCache等推理引擎內的優化,全局池化讓KVCache無法在推理本地VRAM命中的代價大大降低(從遠端拉取代價遠低於重新Prefill),放寬了親和性約束。使調度器更輕鬆地實現高KVCache命中率,進而可以專注於算力調度,實現更高的算力利用率和SLO。
同時基於全局池化的外部KVCache存儲,我們可以進一步將外部KVCache存儲從推理容器中剝離出來,這將帶來以下好處:
1. 讓推理容器的擴縮容不再影響KVCache容量和命中率,更自由地彈性伸縮以優化推理成本。
2. 可以為不同Agent場景靈活設置更優的KVCache存儲容量,一方面避免存儲容量被推理規模限制,另一方面降低存儲資源的浪費。
3. 將存儲和推理服務從部署層面解耦,有利於簡化運維管理,避免互相影響穩定性。
4. 引入3FS等外部存儲系統,進一步擴大存儲容量,降低存儲成本。
當然這種分離並不代表放棄推理主機節點上的存儲資源,事實上將這些存儲資源統一池化能更充分地利用這些資源,同時還有利於提高存儲系統的整體穩定性。
1.2 LLM場景對現有存儲系統提出新需求
在KVCache全局池化後,大量現有存儲系統被用於外部KVCache的存儲,常見的有:文件存儲、KV存儲、內存池、對象存儲等等,均有各自的接口。基於現有接口快速實現全局KVCache池化存儲的同時也遇到了一些問題。
LLM KVCache相較傳統KV存儲有其特殊的業務特徵和存儲模式:
1. 數據間有前綴依賴性。(A,C和B,C中的C代表不同數據);
2. 查詢模式常為前綴匹配+反向滑動窗口(SWA/Linear);
3. 單block內KVCache切分模式多樣:多樣的並行模式和混合注意力方案;
4. 多個推理進程同時讀寫單個block;
TP/PP並行下多推理進程會同時讀/寫同一Block對應的KVCache的不同部分(比如不同的head);
不同部分生命週期綁定,使用時缺一不可。
當前存儲系統接口面向通用場景設計,直接套用抹去了LLM的業務語義和特徵,使得底層存儲系統難以針對KVCache特徵進行更深入的優化。典型問題如:為了方便多進程同時寫入,將單Block拆分為多個Key,但多Key逐出時間並不一致,導致部分Key被逐出後剩餘Key雖然佔用存儲容量但無法提供命中,浪費存儲資源。
部分存儲系統的元數據性能不足,難以在短時間內完成大量元數據查詢:
以block_size=64為例,64K上下文就需要查詢1K個block的元數據,判斷存在性並讀取相關信息。而且64K token對應的KVCache傳輸僅需要不到1秒,查詢元數據的耗時影響就更加明顯。同時單個block的KVCache大小在個位數MB級別,百TB的存儲就需要支撐億級block的管理。大部分針對HPC場景設計的存儲系統主要側重於優化讀寫帶寬,對如此海量block下的大規模元數據查詢支持有限。
改造現有存儲系統或重新做一套存儲系統工程量都較大:
高性能分佈式存儲系統本身具有較高的複雜性。同時由於存量業務場景的接口通用性訴求,和存儲系統固有的高穩定性和可靠性要求,不論是為現有存儲系統增加LLM相關的能力,還是重新針對LLM場景研發一套存儲系統,都需要很多的研發資源和時間,而且如果使用多套存儲系統,則每套系統都要進行相關開發。
因此需要儘可能複用現有工程資源,以儘快滿足迫切的KVCache的存儲需求。同時也為針對LLM場景的專用存儲系統先行明確實際需求和負載模式,使其可以有更完備的信息和充裕的時間來完成設計和開發,協助其更好的滿足KVCache需求。
結合以上問題,構建一個專注於LLM語義適配和存儲管理的元數據管理層成為了一條務實可行的路徑:
該層不替代底層存儲,而是作為元數據管理器,向上對推理引擎暴露符合 LLM 語義的原生接口,向下將操作映射為對底層存儲的高效調用,同時將提煉並轉譯後的存儲特徵提供給底層存儲。這種添加抽象層的方式可以兼顧落地速度與長期演進——短期可快速利用現有存儲系統支持大容量KVCache池化存儲,中長期則為專用存儲系統明確優化目標與接口邊界,實現平滑演進。
1.3 規模部署要求管理系統提供新能力
隨着推理引擎的支持和KVCache存儲系統的完善,池化KVCache開始從小範圍試驗走向規模部署。當數PB的後端存儲開始支撐多種Agent模型的KVCache存儲,各類企業級管理能力的需求隨之出現。
在推理服務啓用外部KVCache存儲前,需要評估KVCache容量需求、外部KVCache存儲的收益和ROI,從大量存量推理服務中找出收益最明顯的一部分。
在運行中,需要可觀測能力,及時感知系統水位變化,結合線上實際需求持續調優存儲容量配置。同時需要高可用和高可靠解決方案,避免元數據服務或存儲系統故障導致推理服務異常。
針對部分重要模型服務,嚴格保障充足的KVCache資源。而且針對長尾模型服務,儘可能共享存儲資源,減少容量配置工作量。
當切換模型版本時,保障新舊模型KVCache隔離,同時跟隨新舊版本的推理流量變化柔性調整KVCache容量比例。
隨着部署規模的擴大,諸如此類的需求不斷出現,對KVCache管理系統的企業級能力提出了更高的要求。

2. Tair KVCache Manager 應運而生
在這樣的背景下,阿里雲 Tair 與阿里巴巴智能引擎、基礎設施與穩定性工程團隊聯合共建了面向大模型KVCache的企業級管理服務產品Tair KVCache Manager(以下簡稱Tair KVCM)。系統通過以下設計解決上述問題:
1. 中心化管理KVCache元數據信息,實現跨推理實例的全局KVCache池化共享。顯著提升Agent等長上下文場景下的推理性能。
2. 對LLM KVCache語義進行合理抽象,解耦推理引擎和存儲系統。簡化接入難度的同時為存儲系統保留充足的優化空間。
3. 設計之初便考慮到大規模部署的需求,提供覆蓋KVCache全生命週期的企業級管理能力,如:模型上線前的ROI評估和高收益場景篩選,模型在線服務過程中的可觀測和高可用等等。
最終實現在保持低成本的同時,顯著減少GPU計算資源消耗,提升推理在線服務質量。
文章後續部分將對系統中的基本概念和架構設計做詳細介紹。
2.1 系統基本概念
2.1.1 管控面概念
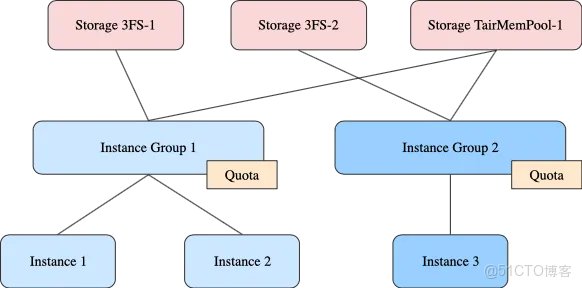
1. Storage:一套存儲系統
- 有獨立的存儲配置(連接地址等等)
- 支持多種不同存儲類型,如NFS、3FS、TairMemPool、Mooncake等
- 允許不同的Instance Group和Instance共享同一Storage
2. Instance Group
- 同Group內所有Instance共享一套配額
- 每個Group可以單獨配置可用的Storage列表
- 常見用途:
- 對應一個業務團隊,團隊內的多個模型共享存儲配額
- 對應一個模型,模型的多個版本共享存儲配額
- 為重要模型單獨配置Instance Group,保證獨佔存儲資源
- 多個長尾模型共用一個Instance Group,共享存儲資源的同時滿足個別模型的突發容量需求
3. Instance:一個KVCache實例
- 僅單個Instance內部會複用KVCache(需要互相複用KVCache的推理實例應當配置為使用同一個Instance)。跨Instance不復用KVCache。
- 對應的模型和KVCache配置(比如fp8/bf16,block_size等)唯一且不變
- 屬於且僅屬於一個Instance Group。
- 無需單獨配置容量配額,使用所屬的Instance Group的配額。
通過以上抽象,將存儲、配額和實例解耦,允許靈活控制KVCache存儲方式和容量,便於統一管理大量KVCache實例。在Instance Group上配置容量配額,避免了為Instance單獨配置存儲容量,簡化了業務側的接入流程,也便於模型版本切換時的容量轉移。
2.1.2 數據面概念

1. Block:一段定長的連續Token組成1個Block。
- 單個block的對應token ids數量在Instance初始化時指定。用户傳入的token id序列會被切分為多個block。
- 有前綴依賴關係。自身Token序列相同但前綴不一致的兩個block是不同的。
- 每個block可以有多個CacheLocation:對應多個存儲位置/層級。
2. CacheLocation:單個block的一個存儲位置。
- 單個CacheLocation內的所有數據必須全部位於同一種存儲類型(type)。
- 狀態:writing-》serving-》deleting
- writing:KVCache正在寫入,不可服務。暫時無需再次寫入。
- serving:已寫入完成,可正常讀取。
- deleting:正在刪除中,不可讀取。
3. LocationSpec:單個CacheLocation的一部分數據
- 組織存儲位置格式統一為URI,但允許不同表達方式:
- 對於內存池可能是地址。對於文件系統可能是文件路徑。對於KV存儲可能是Key。
- 統一了格式,同時避免了強制映射到地址偏移或KV等導致的底層位置語義錯位。
- 在uri中記錄size以簡化容量統計。
- 通過blkid+size支持單個存儲位置(如單個3fs文件)內的分塊存儲。
- spec name允許用户配置:靈活支持不同的TP、PP、混合注意力。
- 允許Location內僅有部分Spec:混合注意力場景下很多block不需要存儲線性注意力
基於以上抽象,既滿足了推理引擎的KVCache查詢需求(混合注意力的複合匹配等等),也在Tair KVCM內保留了LLM的相關業務特徵和語義:多Block間的前綴關係,同Location多Spec的關聯關係等等。由於感知並保留了LLM相關特徵,Tair KVCM還可以針對KVCache存儲場景實現更多優化,如:通過前綴對請求進行更細緻的分類,針對性調整逐出策略。利用前綴依賴的數據關係,避免後綴的無效存儲。為線性注意力選擇最需要保留的Block,在不犧牲命中率的情況下優化存儲容量等等。
從底層存儲視角看,降低了接入的複雜度(不需要了解任何推理概念,完全透明),同時還可以獲取到提煉並翻譯後的存儲特徵(存儲對象間的生命週期關聯等等),為後續更進一步的優化和專用存儲系統的開發留出了充足空間。
2.2 部署模式和服務接口
Tair KVCM以中心化模式部署。由於僅負責KVCache的元數據管理,結合C++作為開發語言,依靠scale up就可以滿足單一推理集羣的需求。同時instance group的抽象使得使用同一存儲的不同的group也可以很輕鬆地進行拆分,橫向scale out以服務不同推理集羣。中心化模式使得運維部署大幅簡化,同時也避免了將KVCM邏輯注入推理容器,規避了可能導致的元數據存儲後端(如Valkey)連接數爆炸等問題。
同時結合3FS Master等工作,Tair KVCM可以僅使用TCP和推理引擎及後端存儲進行交互,並不依賴強依賴RDMA環境。對於RDMA環境內僅有GPU機型的場景,可以將KVCM部署在RDMA環境外的其他機型上,規避GPU機型故障率過高的問題。
在通過Tair KVCM獲取到KVCache的存儲位置後,推理引擎內的Connector將直接讀寫後端存儲,KVCache數據流完全繞過Tair KVCM,降低了KVCache讀寫延遲和對Tair KVCM的帶寬需求。
為方便隔離,Tair KVCM對元數據面和管控面做了分離,這裏列舉其中一部分關鍵接口。
- 管理接口:
- Storage、Instance Group、Instance等對象的CRUD接口;
- Account相關API用於權限管理控制;
- Metrics相關API用於系統可觀測性功能;
- 元數據接口:
- RegisterInstance:用於從元數據面創建Instance,簡化推理接入流程;
- 元數據相關主要API:
- GetCacheLocation:獲取KVCache是否命中及存儲位置;
- startWriteCache:請求需要寫入的KVCache及目標寫入位置並通知KVCM開始寫入;
- finishWriteCache:上報寫入完成;
- removeCache&trimCache:KVCache數據修剪和刪除;
- API參數設計:
- 支持block_keys和token_ids兩種模式,兼容多種推理引擎的同時方便周邊系統查詢;
- 主要接口均攜帶完整的前綴信息以便維護前綴元數據;
2.3 系統架構
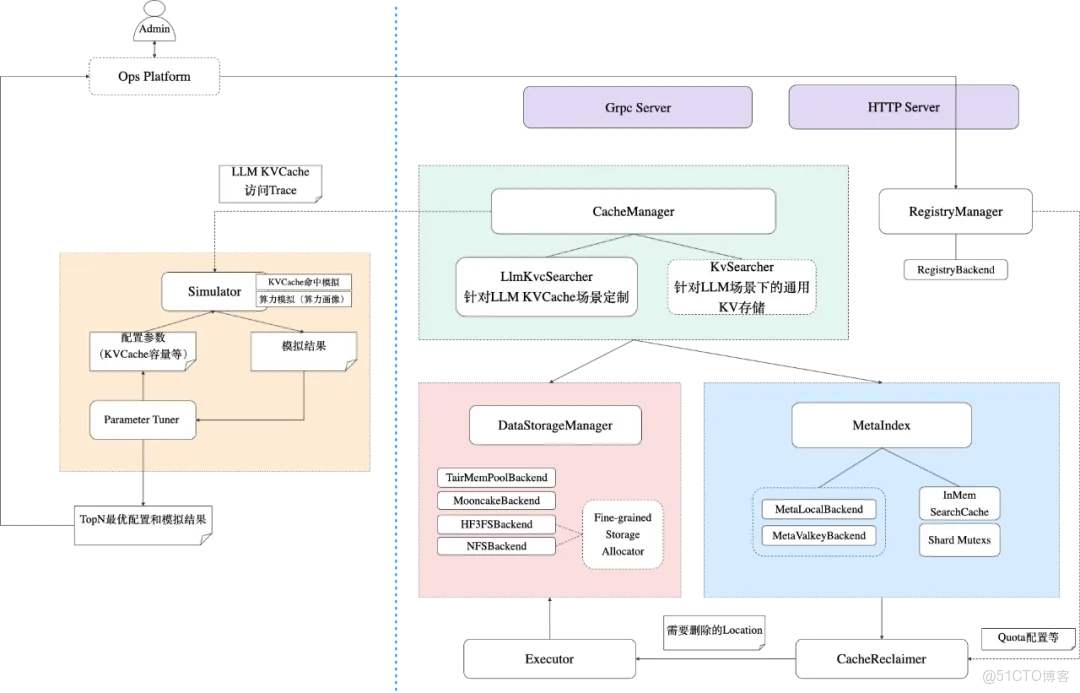
2.3.1 Manager
接入層(Server)
1. 同時提供http和grpc接口,方便不同推理引擎接入。
2. 依託C++下的RDMA生態,如果有極低延遲需求,也可實現RDMA甚至GPU Direct接入。
讀寫模塊(CacheManager)
1. 多種匹配模式支持。推理引擎讀取KVCache元數據時,支持多種匹配模式:
- KV式匹配:給定若干key,直接返回對應元數據;
- 前綴式匹配:給定若干key,僅返回符合前綴順序的元數據。這種匹配模式是推理引擎讀取時的主要模式,vLLM/SGLang均支持按前綴複用KV Cache;
- 滑動窗口式匹配:給定若干key和窗口長度,僅返回最近窗口長度內的元數據。對於使用滑動窗口機制的KVCache模式,這種匹配方式有更高的性能;
2. 兩階段寫入機制。推理引擎寫入KVCache時,基於如下的兩階段寫入機制:
- 寫入前調用 StartWriteCache 接口從Tair KVCM獲取元信息,本地調用不同存儲後端的sdk進行寫入。正在寫入的cache key會被標記為 writing 狀態,在指定超時時間內等待推理引起寫入完成,保證相同key無法同時寫入;
- 寫入後調用 FinishWriteCache 接口通知Tair KVCM寫入完成,服務端將對應寫入成功的key標記為serving狀態,同時刪除寫入失敗的key。
3. 高可用讀寫支持:
- Tair KVCM支持多種存儲後端(詳見下面「存儲管理」部分),支持動態切換不同存儲後端進行讀寫,提高可用性;
- 由於KVCM能同時對接多種存儲後端,對於推理引擎來説可以方便地按需求將數據存儲至不同的後端。例如將熱數據存儲到TairMemPool,將冷數據存儲到3FS。同時也能保證某個後端掛掉時,cache服務依然處於可用狀態。
存儲管理(DataStorage)
1. 兼容多種存儲系統
- 不同的存儲系統有獨立的存儲配置。
- 支持3FS、TairMemPool、Mooncake、NFS等多種存儲系統,同一個Storage可以被不同的InstanceGroup和Instance共享。
- 存儲位置格式統一為Uri,並支持不同表達方式:內存池是地址、文件系統是路徑等。
- 所有存儲系統均通過統一的 DataStorageBackend 抽象接口接入,確保上層邏輯無需感知底層差異。 解耦性與擴展性較強,上層只需傳遞Uri,新增存儲類型只需實現接口,無需修改核心邏輯。
2. DataStorageManager進行多種存儲系統的統一管理
- GetAvailableStorage進行探活檢查,健康檢查在後台週期性進行以提升性能,並返回所有可用存儲實例,提高可用性。
- 支持不同後端存儲的動態生命週期管理,RegisterStorage、UnRegisterStorage對存儲實例註冊與註銷。
- EnableStorage、DisableStoarge動態開啓或關閉某個存儲實例的可用狀態。
- Create、Delete、Exist用於存儲實例空間的開闢、釋放及有效性的判斷。
3. 其他特性
- 針對無元數據管理能力或元數據性能有限的存儲系統NFS和3FS,提供block分配能力(分配少量大文件,切成小塊使用)。
4. TairMemPool介紹:TairMemPool是阿里雲Tair團隊與服務器研發定製計算與芯片系統團隊聯合打造的高性能KVCache內存池方案。該方案通過軟硬件協同優化,實現多節點內存統一尋址與全局訪問能力,支持多介質/協議接入及KVCache專用傳輸優化,在多網卡環境下網絡帶寬利用率超90%,兼具企業級高可用特性,為TairKVCache系統提供高可靠存儲支撐。
索引管理(MetaIndex)
1. 使用KV系統存儲元數據
- KV系統易於獲取且生態成熟,開源社區和雲服務市場提供了大量高可用、高性能的KV存儲解決方案,可拓展性和可用性高。如Valkey、Redis等以內存為主、支持持久化的高性能KV引擎,如基於LSM-Tree結構的Rocksdb,適合寫密集型負載。
- 在項目早期階段,團隊資源有限,直接使用外部高可用與持久化的能力,能夠有效降低初期系統複雜度和開發成本。
- 元數據同樣適用KV存儲,與上層Cache的KV語義統一,方便對外接口的設計和實現
2. 接口設計
- 支持針對KV Cache元數據的Put、Delete、Update、Get接口,對外提供增刪改查能力。
- 支持ReadModifyWrite接口,提供可自定義Modifier的線程安全更新。
- 在高併發場景下,如多個推理請求同時更新同一模型的KV Cache元數據信息,簡單的讀改寫容易產生狀態不一致的問題,故MetaIndex提供了原生支持的讀改寫原子操作接口。
- ReadModifyWrite(keys, ModifierFunc),外部可以通過自定義ModifierFunc函數處理增改刪三種操作,提供了靈活且線程安全的讀改寫能力。
- 該接口內將對指定keys加分片鎖,查詢keys,用户通過自定義ModifierFunc函數,基於查詢結果指定刪除、修改和寫入操作,最後由MetaIndex驗證並執行相應操作。
- 支持Scan、RandomSample接口,支持獲取存儲和緩存容量等接口
- 隨着緩存規模增長,系統必須具備對Instance粒度的元數據存儲實施有效的容量管理(如 LRU逐出),為這些容量管理的逐出策略提供相關數據信息並指定已逐出的key。
3. 其他特性
- 使用LRU Cache作為元數據存儲的search cache,減少查詢I/O,降低高命中場景下的延遲。
- SearchCache位於數據訪問邏輯之上,查詢Value時都會優先嚐試本地的LRU Cache,如果存在Cache,將不會參與後續包含I/O開銷的查詢
- 新的KV查詢,將查詢結果插入到SearchCache中;所有寫操作(如Put、Delete、Update)在成功提交到底層存儲後,會同步失效對應緩存項
- 可以配置LRU Cache參數,調節Search Cache能力,如Cache大小、Cache Shard數量
- 支持配置分片鎖和分批操作,提供高性能和高併發的服務能力
- 在多線程環境下,元數據操作必須保證強線程安全。然而,全局鎖會成為性能瓶頸,而完全無鎖又難以實現複雜Read-Modify-Write語義。為此,系統採用分片鎖(Sharded Locking)+批處理對齊的混合策略。
- 分片鎖:將key空間按哈希劃分為N個分片(N需配置為2的冪次方的倍數),每個分片維護獨立的鎖,操作某key時僅需要鎖定其所屬分片即可。注意,為了提高查詢性能,查詢操作不加鎖也不會被鎖阻塞。
- 分批操作與鎖粒度對齊:MetaIndex的對外接口均接受批處理操作,為了避免死鎖,加鎖需要按鎖分片粒度升序排序依次加鎖。同時,為了避免大批次的操作長期阻塞其他小批次操作,我們需要進行分批,將大批次keys分為若干小批次操作,小批次之間的鎖分片互不相交,執行完一小批則釋放其分片鎖,其批次大小受batch_size和鎖shard_count兩個配置共同影響。這種按鎖粒度自適應對齊批次大小進行增刪改的能力,使得MetaIndex能夠針對不同業務特點通過配置參數實現高併發能力和單批操作吞吐之間的trade-off調控。
- 底層存儲支持靈活擴展,目前已支持本地存儲和遠端Valkey/Redis存儲
容量管理(Reclaimer & Executor)
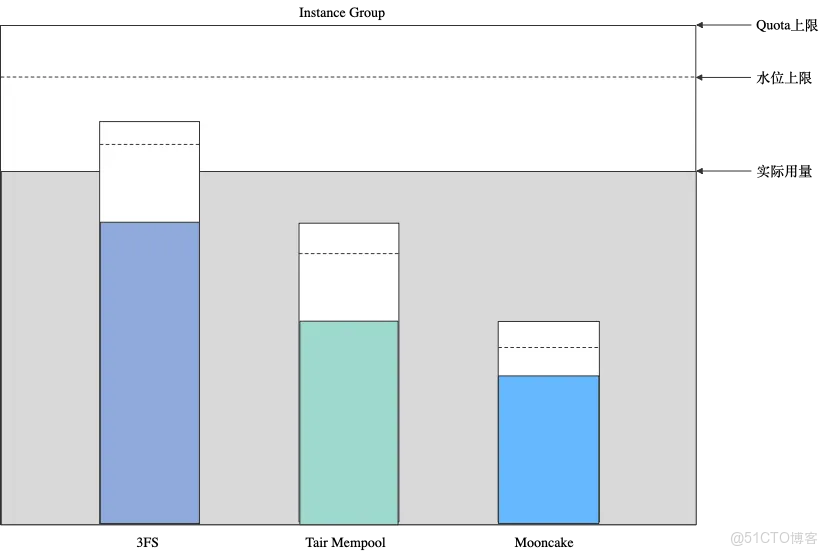
KVCM中的容量管理分兩個維度實現:
- Instance Group維度:
- Quota配置:
- Instance Group可配置一個總Quota,以及針對每種存儲類型配置一個Quota。例如:總Quota = 100T,TairMemPool Quota = 1T,3FS Quota = 99T。
- Quota配置用於Instance Group的存儲容量的硬上限控制:若某個Instance Group的總用量超出配置的總Quota上限,則KVCM將停止為該Instance Group分配寫入地址;若Instance Group下的某種存儲類型的用量超過對應的Quota上限,則KVCM將停止為該Instance Group往該種類型的存儲後端分配寫入地址,轉而嘗試其他類型的可用存儲後端。
- 通過控制總用量和分存儲類型用量上限,可更明確管理Instance Group下的KVCache數據的存儲使用意圖。
- 水位配置:
- Instance Group的配置中還包含了逐出策略,其中一個重要控制項是用量水位配置,以浮點數百分比表示。當某個Instance Group的用量達到指定水位,則KVCM將開始觸發逐出動作,嘗試將用量控制在該水位以下。
- 逐出水位配置相當於存儲容量的軟上限控制:若Instance Group針對某一種Storage Type的用量超過配置的水位,KVCM將開始觸發針對該 Instance Group的限於特定Storage Type的逐出;若Instance Group的整體水位超出,則可能觸發該Instance Group的所有Storage Type的逐出。
- 用量水位以及逐出策略控制是存儲後端整體用量管理和提前規劃的重要手段,使KVCache數據存儲池化大規模部署的整個服務生命週期可持續。
- 存儲後端容量維度:
- 後續還將支持為每個具體的存儲後端實例單獨配置容量管理策略,當某個存儲後端的總用量達到上限時停止寫入,達到逐出水位時按一定的算法逐出數據,可與Instance Group的容量管理結合,更進一步確保存儲後端的水位安全。
具體工程實現上,KVCM通過將刪除任務放入後台線程池等工程手段實現刪除的異步執行,使得刪除性能可擴展以支持較大的部署規模;同時支持TTL、LRU、LFU等多種常見逐出模式,可以靈活適配不同的容量管理需求;支持水位與Quota在Runtime的實時更新;支持結合Optimizer模塊實現Instance級別的逐出參數動態調優;未來還將支持基於前綴的更精準的逐出能力,例如:後綴block先於父親block逐出、混合注意力下Linear和Full的前後綴關聯性逐出。
2.3.2 Optimizer
Optimizer 模塊是一個專為 LLM 推理系統設計的緩存策略優化分析工具,通過高效模擬重放真實 Trace 數據來深度分析 KVCache 命中率和存儲容量消耗模式,並通過分析結果來優化指導 Manager 的容量管理。
該模塊構建了基於 Radix Tree 的前綴匹配索引,支持包括 Tair KVCM event 在內的多種格式的真實訪問 Trace 數據解析與轉換,能夠精確模擬 LRU、Random-LRU 等不同驅逐策略下的讀寫訪問模式,不僅計算分析不同容量配置對緩存命中率的影響,還能夠深入分析每個 block 的訪問時間局部性、訪問頻率分佈等關鍵指標。模塊支持通過參數遍歷與重放循環,自動尋找最優存儲參數配置,實現存儲成本與性能的最佳權衡。同時,模塊內置了靈活的緩存層級配置和統一的驅逐策略接口,既支持單一緩存層的精細化分析,也為多層級緩存架構的協同優化預留了擴展接口。
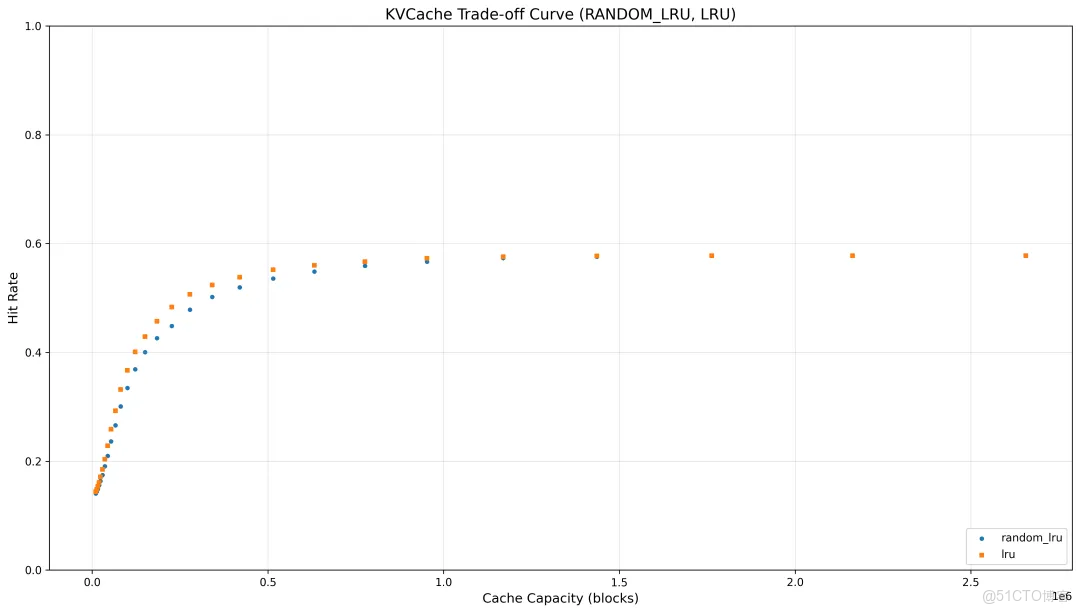
通過統一的 Trace 數據結構和高效的 Trace 處理機制,Optimizer 模塊能夠準確還原真實業務場景下的緩存行為,提供穩定且快速的性能分析。效果如圖所示,圖1的動態分析能夠實時追蹤緩存容量使用與命中率的協同變化;而圖2清晰描繪了不同驅逐策略在不同緩存容量配置下的 KVCache 命中率收益,從而測試不同驅逐策略的性能變化以及指導最優容量配置。
(示例trace來源)
更進一步,Optimizer 模塊通過靈活的架構設計,支持與 GPU 推理性能模型(算力畫像)進行深度集成,能夠基於緩存命中率對prefill階段計算量的減少效果進行量化建模,將 KVCache 帶來的延遲改善(如TTFT優化)和吞吐量提升直接映射到 GPU 資源利用效率的提升上,進而量化為 GPU 節點數量縮減和運營成本節約的具體優化建議,為智能推理系統資源調度和成本優化提供數據驅動的決策依據。具體細節將在後續文章中詳細介紹。
3. 未來工作
3.1 支持更全面的LLM緩存場景
隨着多模態模型能力的提升,多輪會話需求也在增多,需要進一步完善LLM KVCache接口多模態支持。
針對encoder cache和類似VLCache的上下文無關KVCache場景,添加傳統KV語義接口。
面對更多樣的部署環境,也有很多工作:
- 線下私有環境:線下環境自持主機使得KVCM在命中率以外出現了更多的優化目標。需要為該類場景設計更多針對性的逐出算法來進行優化。
- 超節點:該類系統中GPU通過ScaleUp網絡訪問內存池的帶寬已經大於通過PCIE訪問CPU內存的帶寬,對用於存儲KVCache的內存進行統一池化管理順理成章。我們將協助實現超節點內KVCache的存儲管理,充分發揮超節點的性能優勢。
3.2 完善主流推理引擎和後端存儲的支持
通過和推理引擎社區的合作,使更多推理引擎能夠獲得原生的支持能力。同時進一步優化傳輸性能。
適配更多後端存儲系統,滿足更多不同場景下的KVCache存儲需求。
3.3 進一步加強仿真和緩存分析能力,優化存儲算法
增強推理聯合仿真能力。優化逐出算法,提高命中率,降低推理成本。
此外現有分層算法大多基於冷熱等傳統數據特徵,並不完全適合LLM KVCache場景下的數據分層需求。需要結合LLM的訪問特徵,探索更符合該場景需求的數據分層算法。
3.4 不斷增強企業級能力
對大規模部署下暴露出的痛點,持續增強相關企業級能力,提供更全面的管理能力。
4. 瞭解更多
歡迎搜索釘釘羣號:109765011301入羣與技術專家交流!