

1. 先説結論:這次上線更像“工程能力”的分水嶺
如果你把大模型當作“更強的搜索框”,那評測重點往往是知識點覆蓋與文風;但當你開始把它接進研發與業務流程,評測重點會立刻變成:
- 需求拆解是否靠譜,能不能形成可執行的交付路徑
- 多輪迭代是否穩定,是否會在長鏈路裏逐步跑偏
- 成本與吞吐是否可控,是否適合持續運行的 Agent 工作流
GLM-4.7 與 MiniMax M2.1 的組合,剛好覆蓋這三類訴求:一個更偏“複雜任務一次性交付”,一個更偏“長時運行效率與吞吐”。 而 AI Ping 的價值在於:你可以在同一平台裏用真實指標對比不同供應商,並用同一套接口把模型接入到工程裏,減少試錯與維護成本。
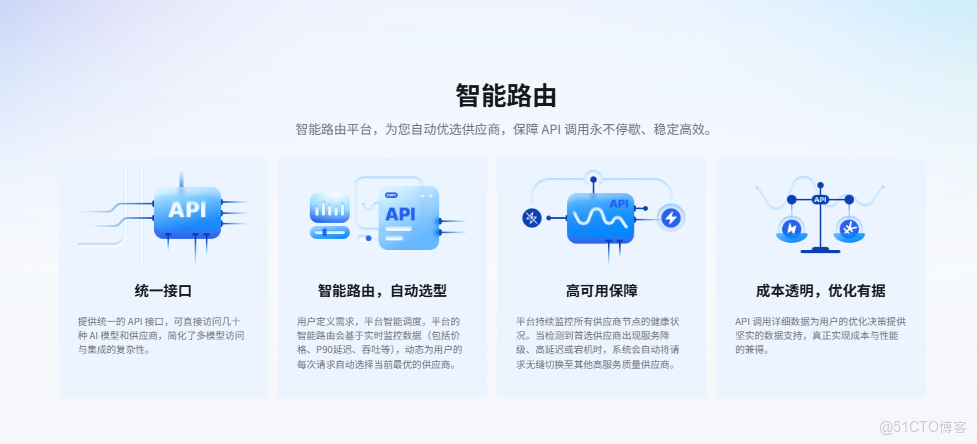
2. AI Ping 解決的不是“能不能用”,而是“怎麼穩定用”
很多團隊第一次接入大模型時,會踩到三個常見坑:
- 供應商切換成本高:每家接口、參數、限流策略都不一樣,換一家等於重寫一遍。
- 線上體驗不穩定:同一模型在不同時段延遲波動大,Agent 一超時就全鏈路斷。
- 選型缺少依據:只靠主觀體驗對比,難以解釋“為什麼選它”。
AI Ping 把這些問題收斂成平台能力:
- 多供應商統一接入:業務只對接一次,後續切換供應商更多是“配置問題”
- 指標看板:把吞吐、延遲、上下文等關鍵數據擺到枱面上
- 智能路由:高峯期自動挑更優供應商,降低抖動對業務的衝擊

這會帶來一個很現實的變化:模型接入不再是“集成一次就別動”,而是變成可持續優化的運行時能力。
3. 用數據看差異:同一模型在不同供應商上會有明顯不同
AI Ping 公佈了平台實測數據。把關鍵指標整理如下(輸入/輸出價格在表中為免費,可靠性為 100%):
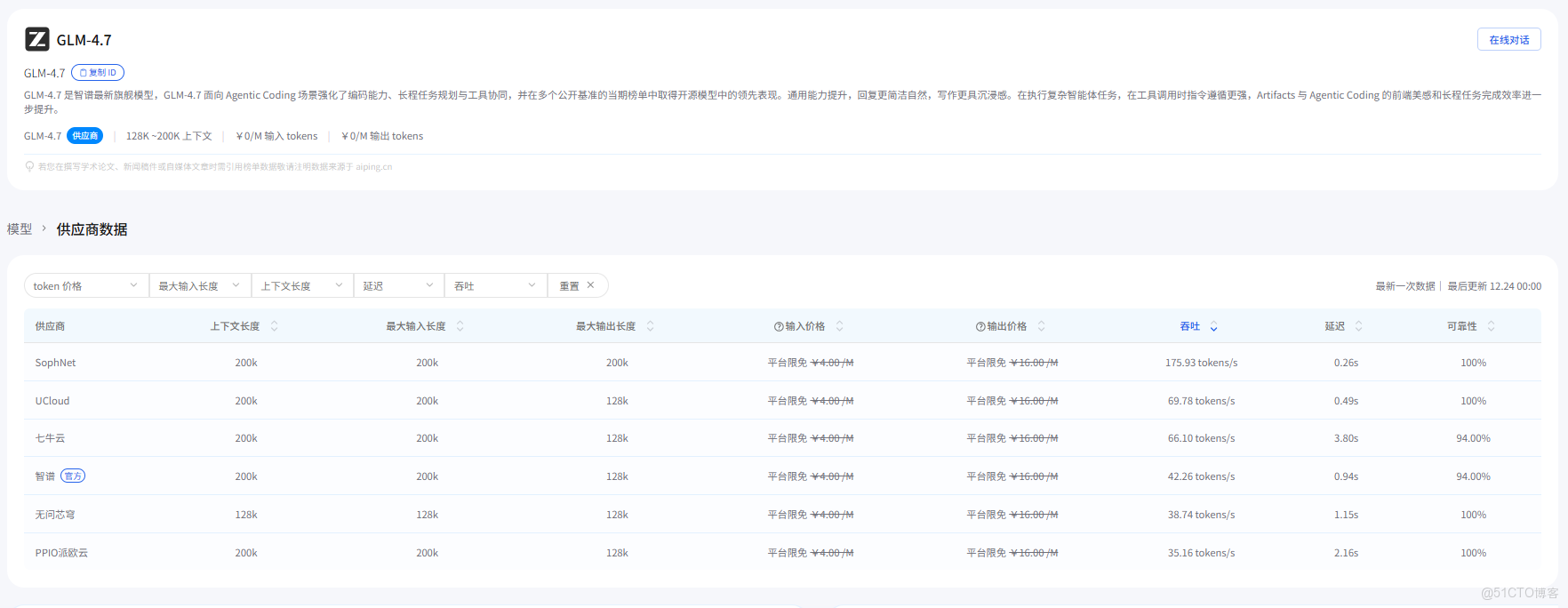
3.1 GLM-4.7(不同供應商)
| 供應商 | 吞吐量 (tokens/s) | 延遲 P90 (s) | 上下文長度 |
|---|---|---|---|
| PPIO 派歐雲 | 50.47 | 3.64 | 200k |
| 智譜(官方) | 50.30 | 10.61 | 200k |
| 七牛雲 | 37.64 | 2.52 | 200k |
| 無問芯穹 | 22.94 | 3.93 | 128k |
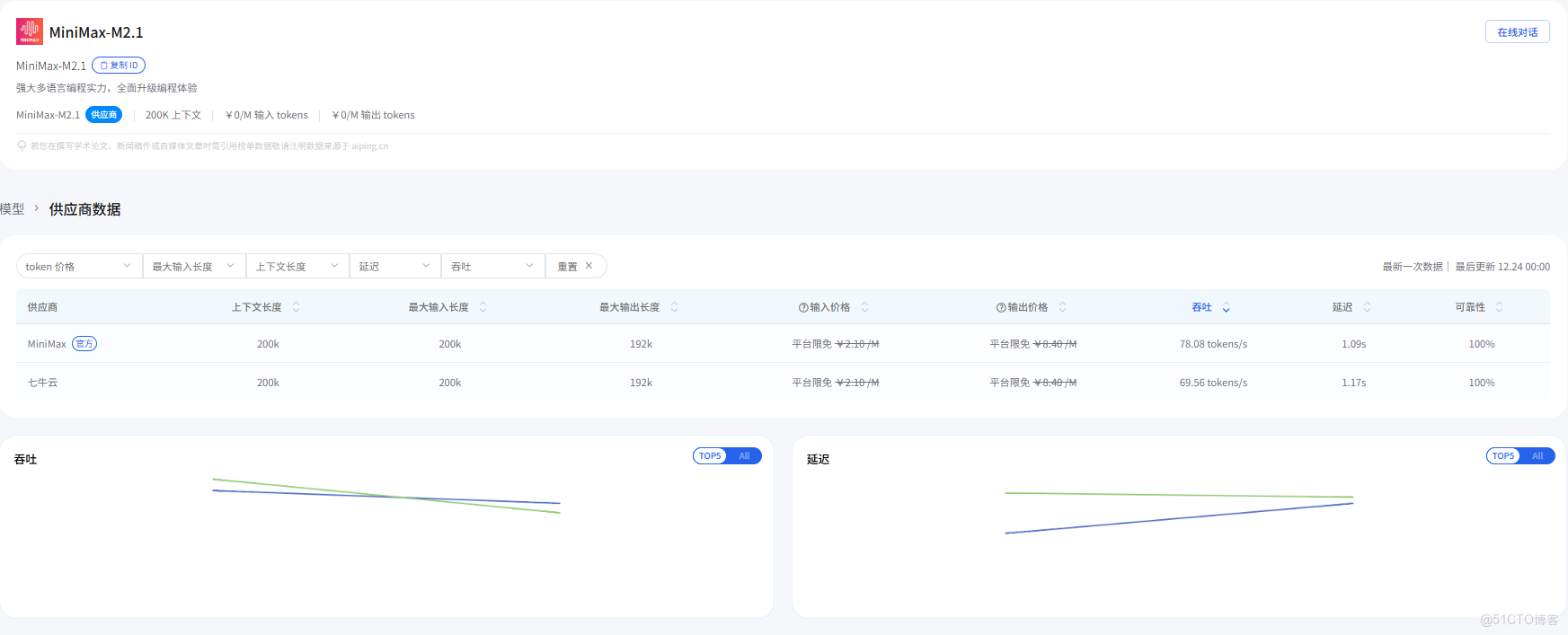
3.2 MiniMax M2.1(不同供應商)
| 供應商 | 吞吐量 (tokens/s) | 延遲 P90 (s) | 上下文長度 |
|---|---|---|---|
| 七牛雲 | 99.75 | 0.54 | 200k |
| MiniMax(官方) | 89.56 | 0.72 | 200k |
這組數據對工程決策的意義可以用一句話概括:
- 想要交互更絲滑,盯
延遲 P90 - 想要長輸出/長鏈路更快,盯
吞吐量 - 想要一次塞進更多需求+代碼+日誌,盯
上下文長度
如果你做的是“持續運行的 Agent”,通常會同時看 P90 和可靠性,再決定是固定供應商還是交給路由。
4. GLM-4.7 與 MiniMax M2.1:更實用的任務分工方式
與其抽象地説“哪個更強”,不如按任務拆分:
4.1 適合優先用 GLM-4.7 的任務
- 需求複雜、驗收嚴格:必須輸出可執行步驟、可驗證結果、風險點與回滾方案
- 需要頻繁工具協同:讀文件、查依賴、對齊接口、生成補丁並回歸驗證
- 關鍵節點交付:例如發佈前最後一輪“全量修復建議 + 變更清單 + 風險評估”
4.2 適合優先用 MiniMax M2.1 的任務
- 連續編碼與重構:多輪往返,吞吐與延遲直接影響整體效率
- 長鏈路 Agent:需求更新、日誌追加、再修復、再驗證,循環次數多
- 多語言工程:尤其是 Rust / Go / Java / C++ 等偏“工程肌肉”的代碼任務
實際落地時,很推薦做成“按場景路由”:把模型當作一組可切換的能力,而不是一個固定依賴。
5. 從 0 到 1:在 AI Ping 上完成一次可復現的接入
下面用“最小可行路徑”把接入講清楚:拿 Key → 發請求 → 驗證流式輸出 → 加上路由篩選。
5.1 獲取 API Key(只做一次)
- 登錄 AI Ping官網
- 進入控制枱的
API Key頁面創建 Key - 把 Key 放進環境變量(避免寫入倉庫)
PowerShell 示例:
$env:AIPING_API_KEY="YOUR_API_KEY"
5.2 最小請求:Chat Completions(非流式)
curl "https://aiping.cn/api/v1/chat/completions" ^
-H "Authorization: Bearer %AIPING_API_KEY%" ^
-H "Content-Type: application/json" ^
-d "{\"model\":\"GLM-4.7\",\"messages\":[{\"role\":\"user\",\"content\":\"用三句話解釋吞吐量和延遲的差別。\"}],\"temperature\":0.2}"
如果你在 Windows 上更習慣用 WSL 或 Git Bash,把換行符改成反斜槓即可。核心不變:Authorization: Bearer ... + model + messages。
5.3 流式請求:適合 UI 與 Agent 逐步產出
Python(Requests)示例:
import os
import requests
api_key = os.environ["AIPING_API_KEY"]
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
payload = {
"model": "MiniMax-M2.1",
"messages": [
{
"role": "user",
"content": "Hello"
}
],
"stream": True,
"extra_body": {
"provider": {
"only": [],
"order": [],
"sort": None,
"input_price_range": [],
"output_price_range": [],
"input_length_range": [],
"throughput_range": [],
"latency_range": []
}
}
}
response = requests.post(
"https://aiping.cn/api/v1/chat/completions",
headers=headers,
json=payload,
stream=True,
timeout=(10, None)
)
response.encoding = "utf-8"
response.raise_for_status()
try:
for line in response.iter_lines(decode_unicode=True):
if line:
print(line)
except KeyboardInterrupt:
print("流被手動中斷。")
如果你直接用瀏覽器訪問 https://aiping.cn/api/v1/chat/completions,會看到 Method Not Allowed,這是因為該接口需要用 POST 調用(瀏覽器地址欄默認是 GET)。
同一段代碼想切到 GLM-4.7,只需要把 payload["model"] 改成 "GLM-4.7"。
5.4 用 extra_body.provider 做“可解釋的路由篩選”
當你希望把“選擇哪家供應商”這件事從拍腦袋變成可解釋策略時,可以使用 extra_body.provider(字段以頁面示例為準):
only:只允許命中某些供應商(白名單)order:優先級順序(當存在多個候選時)sort:按某個指標排序(例如優先低延遲)input_length_range:對上下文長度有要求時使用throughput_range/latency_range:按吞吐或延遲做篩選
示例(以 GLM-4.7 為例,結構與頁面示例一致,值按你的策略填寫):
{
"model": "GLM-4.7",
"stream": true,
"messages": [{"role": "user", "content": "請給出一份可落地的接口改造方案。"}],
"extra_body": {
"provider": {
"only": [],
"order": [],
"sort": null,
"input_price_range": [],
"output_price_range": [],
"input_length_range": [],
"throughput_range": [],
"latency_range": []
}
}
}
在工程實踐中,更推薦兩種模式:
- 日常業務:交給平台自動路由,省運維、抗波動
- 發佈前/關鍵鏈路:固定或強約束供應商,保證可復現與可排障
6. 兩個“拿來就用”的實戰模板:把模型能力落到交付件上
為了避免模型輸出“看起來很對但落不了地”,建議每次都讓它產出可驗證的交付物。
一個“實際調用 + 返回展示”的最小示例如下:
import os
import json
import requests
api_key = os.environ["AIPING_API_KEY"]
url = "https://aiping.cn/api/v1/chat/completions"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
payload = {
"model": "GLM-4.7",
"messages": [
{
"role": "user",
"content": "你是資深工程師。請按以下順序輸出:1) 根因假設列表(按概率排序)2) 最小驗證步驟(每步説明預期現象)3) 最小修複方案(用補丁/偽代碼表達)4) 迴歸清單(必須覆蓋的邊界條件)",
}
],
"temperature": 0.2,
"stream": False,
"extra_body": {
"provider": {
"only": [],
"order": [],
"sort": None,
"input_price_range": [],
"output_price_range": [],
"input_length_range": [],
"throughput_range": [],
"latency_range": [],
}
},
}
resp = requests.post(url, headers=headers, json=payload, timeout=(10, 120))
resp.raise_for_status()
print(resp.status_code)
print(json.dumps(resp.json(), ensure_ascii=False, indent=2))
返回示例:
6.1 模板 A:讓模型輸出“可迴歸的修復補丁方案”
適用:線上報錯、CI 失敗、依賴升級導致的不兼容。
輸入建議包含:
- 目標:修復什麼、驗收標準是什麼
- 約束:不能改哪些模塊、不能引入哪些依賴
- 證據:錯誤日誌、關鍵代碼片段、運行環境
提示詞骨架:
你是資深工程師。請按以下順序輸出:
1) 根因假設列表(按概率排序)
2) 最小驗證步驟(每步説明預期現象)
3) 最小修複方案(用補丁/偽代碼表達)
4) 迴歸清單(必須覆蓋的邊界條件)
GLM-4.7 通常更適合在“根因假設+驗證步驟”階段承擔主力;MiniMax M2.1 更適合在“反覆改補丁+再驗證”的循環階段保持效率。
6.2 模板 B:讓模型輸出“可交付的技術方案文檔”
適用:需求評審、架構設計、接口改造、性能優化方案。
要求它輸出:
- 關鍵決策與取捨(為什麼這麼選)
- 里程碑拆分(每個階段的驗收標準)
- 風險與回滾(出現問題怎麼退回去)
提示詞骨架:
請用面向團隊評審的方式寫方案:
- 背景與目標
- 方案對比(至少 2 個備選)
- 詳細設計(數據結構/接口/流程)
- 實施計劃(按周拆解)
- 風險與回滾
7. 小結:把“會寫”升級為“能交付、可持續”
GLM-4.7 與 MiniMax M2.1 的這次上線,最值得關注的不是某一條基準測試分數,而是它們對工程鏈路的覆蓋:前者更利於複雜任務的穩定完成,後者更利於長鏈路與持續迭代的效率。而 AI Ping 讓這件事更容易落地:你能看到不同供應商的真實表現,用統一接口完成接入,並通過路由策略把穩定性與效率做成可配置的工程能力。
當你把模型放進真實業務之後,“選擇模型”就不該是一錘子買賣,而應當像選擇數據庫與緩存一樣:持續觀測、按場景切換、用數據説話。