vLLM-ascend 下的 PD 分離實戰:從DeepSeek-V3-w8a8模型到壓測,一次把坑踩完
Prefill 計算密集、Decode 訪存密集——這對天然割裂的階段,決定了大模型推理並非一鍋燉。
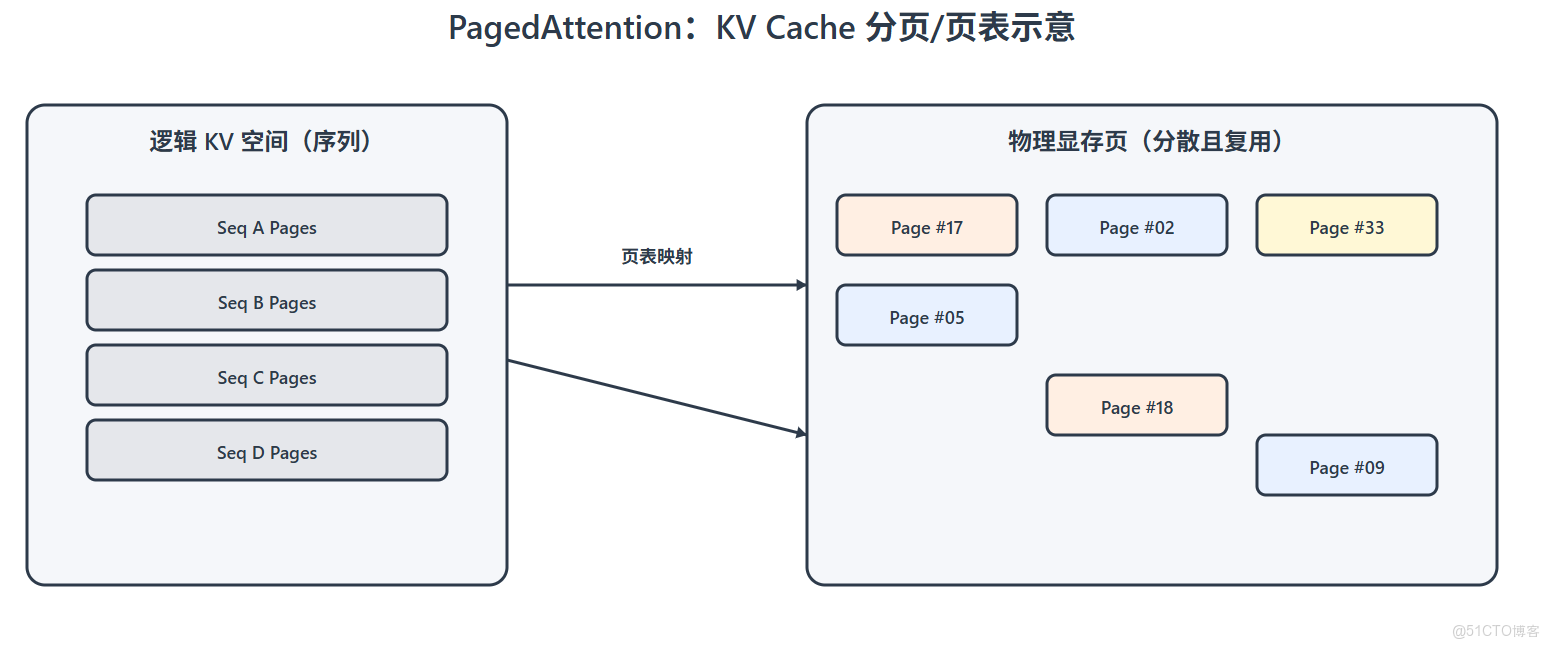
把兩者解耦(PD 分離)+ 用 vLLM 的 PagedAttention 精準管控 KV Cache,是目前在昇騰場景下把吞吐與成本同時打上去的可靠路徑。
我們就用 DeepSeek-V3-w8a8 為例,完整記錄在 vLLM-ascend 上落地 PD 分離 的過程與最佳實踐,並附常見報錯與處理清單,幫助你少走彎路。
<font style="color:#3370FF;">1. </font>背景與意義
Prefill:把完整輸入編碼為隱藏狀態並生成初始 KV Cache,計算密集、顯存瞬時佔用高。
Decode:一次生成一個 token,強依賴 KV Cache 讀寫,訪存/帶寬密集、鏈路易 HostBound。
PD 分離(Prefill/Decode 解耦)將兩類負載放到更合適的資源上,避免強強碰撞。
配合 vLLM 的 PagedAttention(分塊管理 KV 內存),可以有效降低 Cache 碎片化與浪費,讓 高併發 + 長上下文 的場景更穩、更省、更快。
<font style="color:#3370FF;">2. </font>環境版本與依賴
2.1 基礎環境

點擊圖片可查看完整電子表格
2.2 軟件依賴
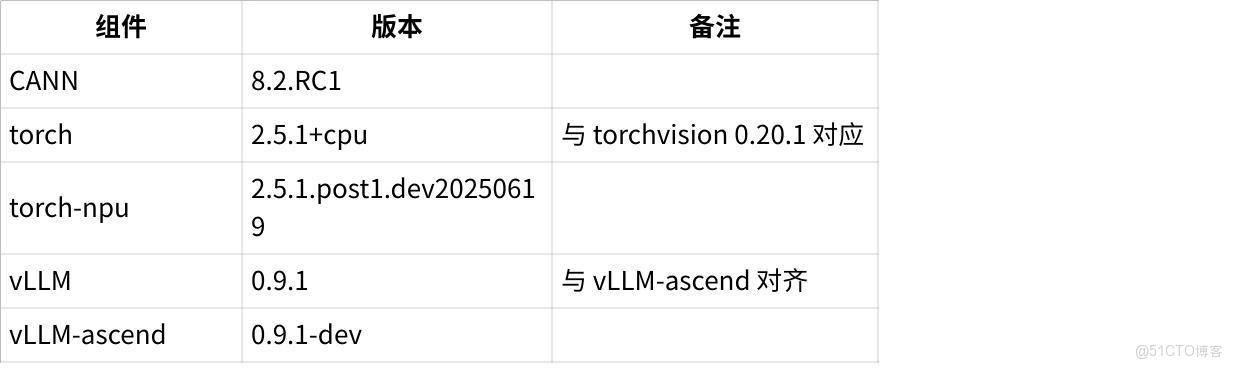
點擊圖片可查看完整電子表格
| <font style="color:rgb(100, 106, 115);">建議把 </font><font style="color:rgb(100, 106, 115);">vLLM</font><font style="color:rgb(100, 106, 115);"> 與 </font><font style="color:rgb(100, 106, 115);">vLLM-ascend</font><font style="color:rgb(100, 106, 115);"> 的 commit/tag 鎖定到同一大版本,避免 API 漂移帶來的兼容性問題。</font> |
|---|
<font style="color:#3370FF;">3. </font>環境搭建(要點版)
3.1 連通性與健康檢查
| <font style="color:rgb(100, 106, 115);">Bash</font># 設備與狀態 npu-smi info # HCCL 鏈路(逐卡) for i in {0..15}; do hccn_tool -i $i -lldp -g | grep Ifname; done for i in {0..15}; do hccn_tool -i $i -link -g; done for i in {0..15}; do hccn_tool -i $i -net_health -g; done for i in {0..15}; do hccn_tool -i $i -netdetect -g; done for i in {0..15}; do hccn_tool -i $i -gateway -g; done # TLS 行為一致(PD 分離場景建議顯式設置) for i in {0..15}; do hccn_tool -i $i -tls -g; done | grep switch for i in {0..15}; do hccn_tool -i $i -tls -s enable 0; done # 跨節點互通(從本節點 ping 對端 NPU IP) for i in {0..15}; do hccn_tool -i $i -ip -g; done for i in {0..15}; do hccn_tool -i $i -ping -g address <PEER-NPU-IP>; done | | :--- |
3.2 容器建議(示例)
使用 --privileged + --net=host,並掛載 Ascend 驅動/日誌路徑。
進入容器後,每次記得 source set_env.sh(toolkit 與 atb)。
3.3 安裝 CANN / torch / torch-npu
CANN:安裝 toolkit + kernels + nnal,磁盤預留 > 10GB;完成後:
| <font style="color:rgb(100, 106, 115);">Bash</font>source /path/to/cann/ascend-toolkit/set_env.sh source /path/to/cann/nnal/atb/set_env.sh |
|---|
PyTorch & torch-npu:固定源,避免“依賴衝突找不到包”的老問題:
| <font style="color:rgb(100, 106, 115);">Bash</font>pip config set global.extra-index-url "https://download.pytorch.org/whl/cpu/ https://mirrors.huaweicloud.com/ascend/repos/pypi" pip install torchvision==0.20.1 # 將自動裝 torch==2.5.1+cpu pip install torch-npu==2.5.1.post1.dev20250619 |
|---|
3.4 安裝 vLLM 與 vLLM-ascend
| <font style="color:rgb(100, 106, 115);">Bash</font># vLLM git clone https://github.com/vllm-project/vllm.git cd vllm && git checkout releases/v0.9.1 VLLM_TARGET_DEVICE=empty pip install -v -e . # vLLM-ascend cd .. git clone https://github.com/vllm-project/vllm-ascend cd vllm-ascend && git checkout v0.9.1-dev pip install -v -e . |
|---|
| <font style="color:rgb(100, 106, 115);">克隆倉庫如遇到 SSL 校驗報錯,可臨時:</font><br/> |
|---|
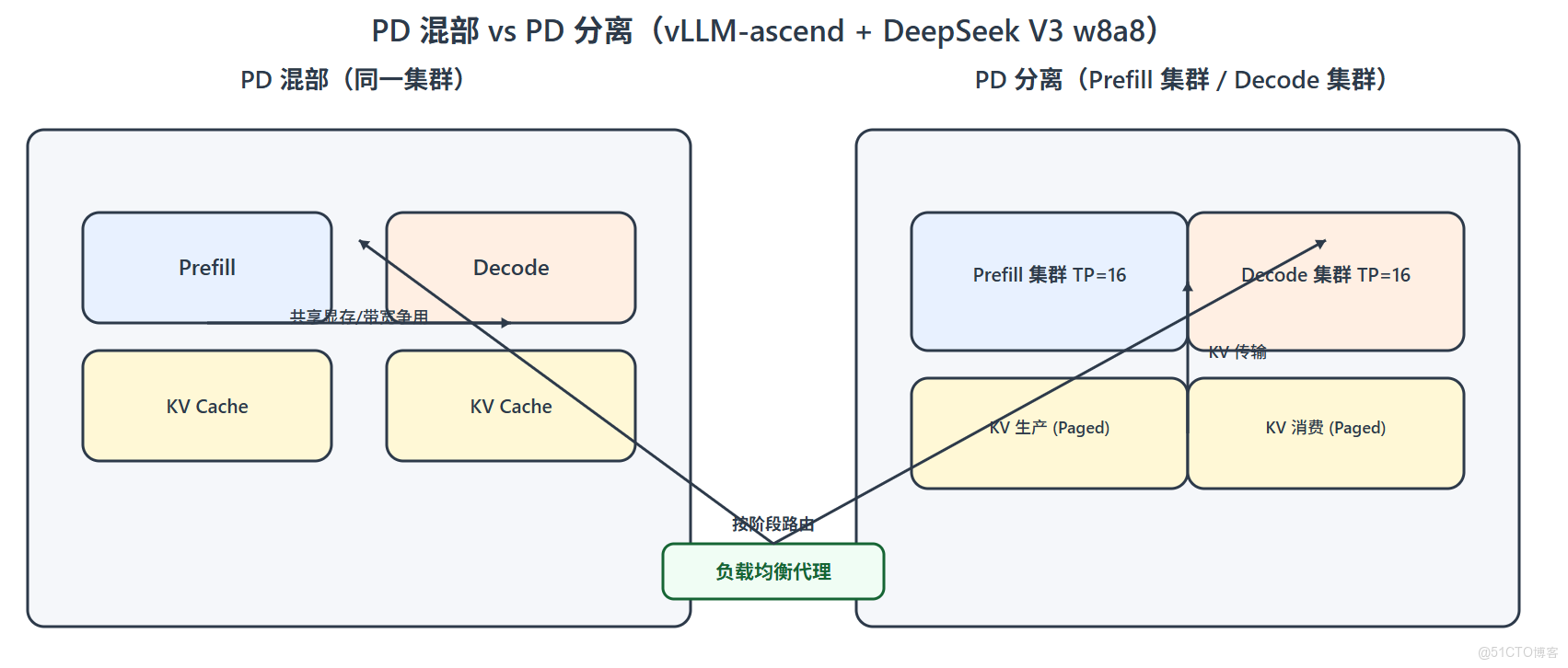
<font style="color:#3370FF;">4. </font>PD 分離部署流程
4.1 生成 ranktable.json
在 兩台參與 PD 的機器上執行(IP 順序:Prefill 在前,Decode 在後):
| <font style="color:rgb(100, 106, 115);">Bash</font>cd /home/<name>/vllm-ascend/examples/disaggregate_prefill_v1/ bash gen_ranktable.sh --ips 141.61.41.163 141.61.41.164 \ --npus-per-node 16 \ --network-card-name ens3f0 \ --prefill-device-cnt 16 \ --decode-device-cnt 16 |
|---|
關鍵參數説明:
--ips:PD 兩端的宿主機 IP(Prefill 優先、Decode 其次)
--network-card-name:承載通信的網卡名(ifconfig 查同 IP)
--prefill/--decode-device-cnt:分配的 NPU 數量
4.2 Prefill 節點腳本(P)
| <font style="color:rgb(100, 106, 115);">Bash</font># 環境與端口 export HCCL_IF_IP=141.61.41.163 export GLOO_SOCKET_IFNAME="ens3f0" export TP_SOCKET_IFNAME="ens3f0" export HCCL_SOCKET_IFNAME="ens3f0" export DISAGGREGATED_PREFILL_RANK_TABLE_PATH=/home/<name>/vllm-ascend/examples/disaggregate_prefill_v1/ranktable.json export OMP_PROC_BIND=false export OMP_NUM_THREADS=32 export VLLM_USE_V1=1 export VLLM_LLMDD_RPC_PORT=5559 # 拉起服務(Prefill 端) vllm serve /home/weight/deepseek/DeepSeek-V3.1-w8a8-rot-mtp \ --host 0.0.0.0 \ --port 20002 \ --data-parallel-size 1 \ --data-parallel-size-local 1 \ --api-server-count 1 \ --data-parallel-address 141.61.41.163 \ --data-parallel-rpc-port 13356 \ --tensor-parallel-size 16 \ --enable-expert-parallel \ --quantization ascend \ --seed 1024 \ --served-model-name deepseek \ --max-model-len 32768 \ --max-num-batched-tokens 32768 \ --max-num-seqs 64 \ --trust-remote-code \ --enforce-eager \ --gpu-memory-utilization 0.9 \ --kv-transfer-config \ '{"kv_connector":"LLMDataDistCMgrConnector","kv_buffer_device":"npu","kv_role":"kv_producer","kv_parallel_size":1,"kv_port":"20001","engine_id":"0","kv_connector_module_path":"vllm_ascend.distributed.llmdatadist_c_mgr_connector"}' |
|---|
| <font style="color:rgb(100, 106, 115);">關鍵項:--quantization ascend(w8a8 量化,避免 OOM)、--kv-transfer-config(PD 分離 KV 傳輸)。</font> |
|---|
4.3 Decode 節點腳本(D)
| <font style="color:rgb(100, 106, 115);">Bash</font># 環境與端口 export HCCL_IF_IP=141.61.41.164 export GLOO_SOCKET_IFNAME="ens3f0" export TP_SOCKET_IFNAME="ens3f0" export HCCL_SOCKET_IFNAME="ens3f0" export DISAGGREGATED_PREFILL_RANK_TABLE_PATH=/home/<name>/vllm-ascend/examples/disaggregate_prefill_v1/ranktable.json export OMP_PROC_BIND=false export OMP_NUM_THREADS=32 export VLLM_USE_V1=1 export VLLM_LLMDD_RPC_PORT=5659 # 拉起服務(Decode 端;注意更小的 max-model-len / batch) vllm serve /home/weight/deepseek/DeepSeek-V3.1-w8a8-rot-mtp \ --host 0.0.0.0 \ --port 20002 \ --data-parallel-size 1 \ --data-parallel-size-local 1 \ --api-server-count 1 \ --data-parallel-address 141.61.41.164 \ --data-parallel-rpc-port 13356 \ --tensor-parallel-size 16 \ --enable-expert-parallel \ --quantization ascend \ --seed 1024 \ --served-model-name deepseek \ --max-model-len 8192 \ --max-num-batched-tokens 256 \ --max-num-seqs 64 \ --trust-remote-code \ --gpu-memory-utilization 0.9 \ --kv-transfer-config \ '{"kv_connector":"LLMDataDistCMgrConnector","kv_buffer_device":"npu","kv_role":"kv_consumer","kv_parallel_size":1,"kv_port":"20001","engine_id":"0","kv_connector_module_path":"vllm_ascend.distributed.llmdatadist_c_mgr_connector"}' \ --additional-config \ '{"torchair_graph_config":{"enabled":true}}' |
|---|
| <font style="color:rgb(100, 106, 115);">Decode 端更關注 </font><font style="color:rgb(100, 106, 115);">RPS 與時延</font><font style="color:rgb(100, 106, 115);">,因此 max-model-len / max-num-batched-tokens 可按場景調小。</font> |
|---|
4.4 分別拉起 P 與 D
| <font style="color:rgb(100, 106, 115);">Bash</font># Prefill 節點 cd vllm-ascend/examples/disaggregate_prefill_v1/ bash npu16_vllm_ds_prefill.sh # Decode 節點 cd vllm-ascend/examples/disaggregate_prefill_v1/ bash npu16_vllm_ds_decode.sh |
|---|
看到 Application startup complete. 即表示就緒。
4.5 代理層(可選但推薦)
Prefill 機再開一個容器窗口,啓動 負載均衡代理:
| <font style="color:rgb(100, 106, 115);">Bash</font>source /home/<name>/cmc/cann_8.2.rc1/ascend-toolkit/set_env.sh source /home/<name>/cmc/cann_8.2.rc1/nnal/atb/set_env.sh cd /home/<name>/vllm-ascend/examples/disaggregate_prefill_v1/ python load_balance_proxy_server_example.py \ --host 141.61.41.163 \ --port 1025 \ --prefiller-hosts 141.61.41.163 \ --prefiller-ports 20002 \ --decoder-hosts 141.61.41.164 \ --decoder-ports 20002 |
|---|
代理層負責把請求按階段路由到 P / D,輸出裏會顯示初始化成功的客户端數與服務地址。
<font style="color:#3370FF;">5. </font>功能驗證與壓測
5.1 API 驗證
| <font style="color:rgb(100, 106, 115);">Bash</font>curl http://141.61.41.163:1025/v1/completions \ -H "Content-Type: application/json" \ -d '{ "model":"deepseek", "prompt":"how is it today", "max_tokens":50, "temperature":0 }' |
|---|
添加 -v 可查看更細日誌;響應中 choices[0].text 為模型輸出。
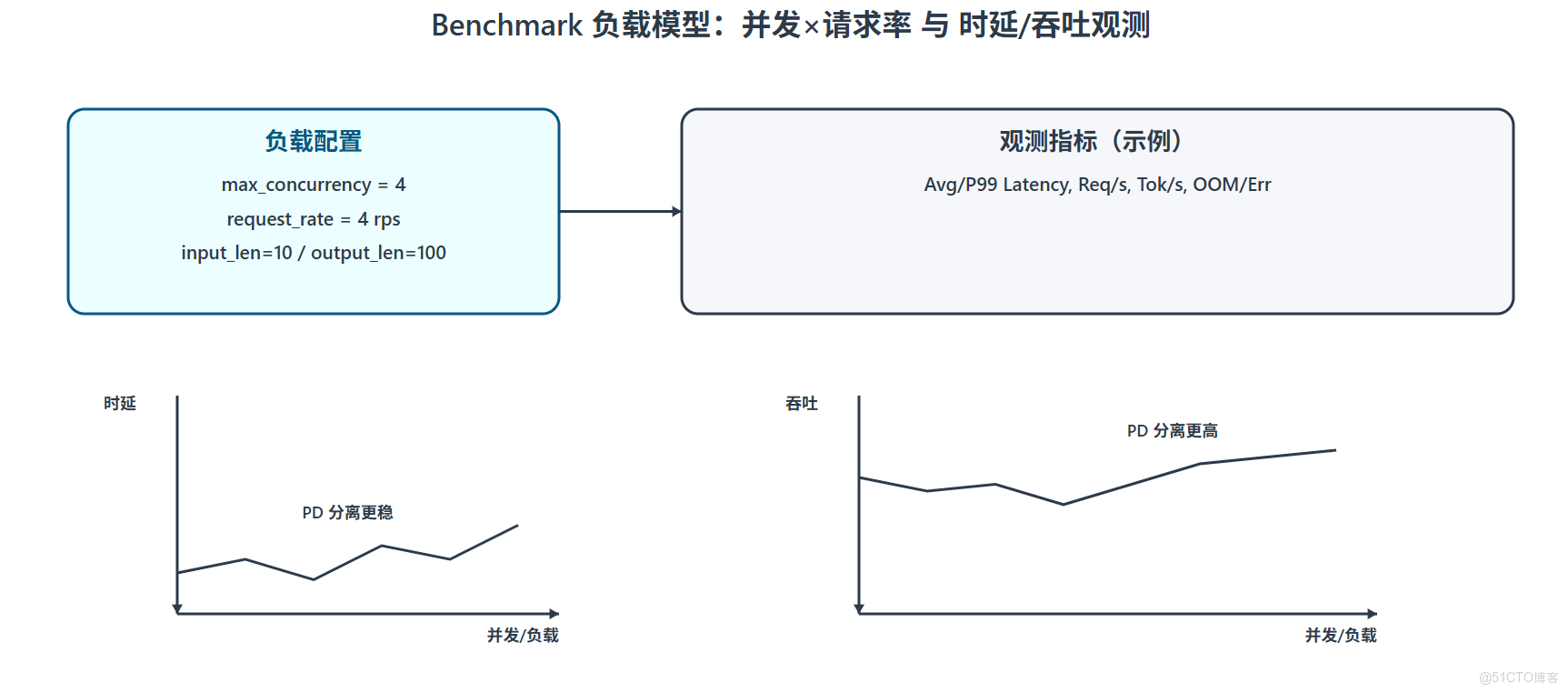
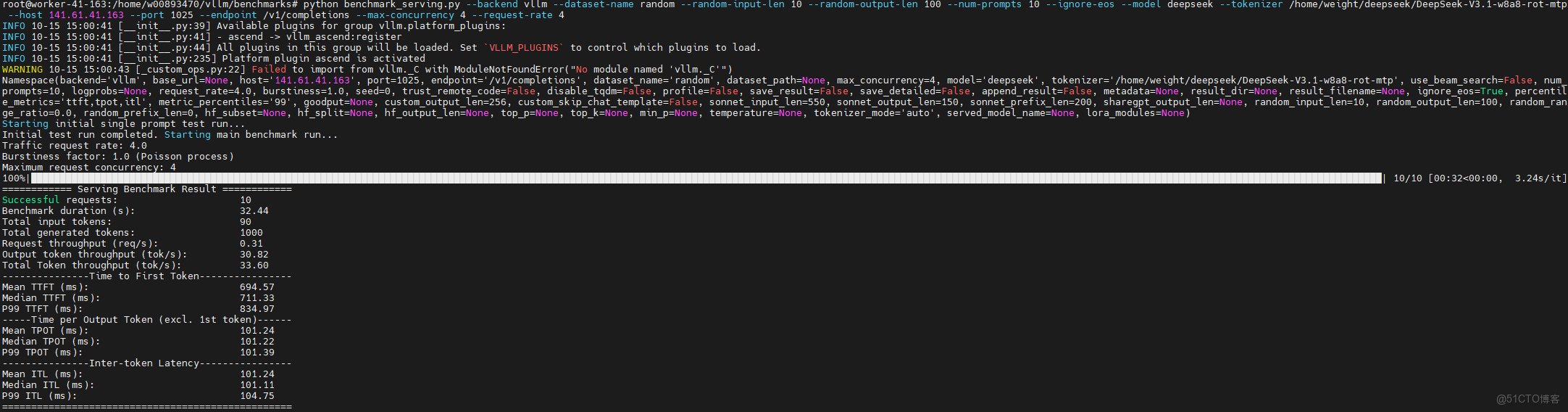
5.2 benchmark(vLLM 官方腳本)
| <font style="color:rgb(100, 106, 115);">Bash</font>source /home/<name>/cmc/cann_8.2.rc1/ascend-toolkit/set_env.sh source /home/<name>/cmc/cann_8.2.rc1/nnal/atb/set_env.sh cd /home/<name>/vllm/benchmarks/ python benchmark_serving.py \ --backend vllm \ --dataset-name random \ --random-input-len 10 \ --random-output-len 100 \ --num-prompts 10 \ --ignore-eos \ --model deepseek \ --tokenizer /home/weight/deepseek/DeepSeek-V3.1-w8a8-rot-mtp \ --host 141.61.41.163 \ --port 1025 \ --endpoint /v1/completions \ --max-concurrency 4 \ --request-rate 4 |
|---|
| <font style="color:rgb(100, 106, 115);">關注指標:平均時延、P99、吞吐(req/s 或 tok/s)。對比 </font><font style="color:rgb(100, 106, 115);">PD 混部 vs PD 分離</font><font style="color:rgb(100, 106, 115);">,一般在中高併發下分離更穩。</font> |
|---|
<font style="color:#3370FF;">6. </font>易錯點與快速修復
(1)torch-npu 找不到可用版本
現象:No matching distribution found for torch-npu
原因:源不對/被牆。
解法:
| <font style="color:rgb(100, 106, 115);">Bash</font>pip uninstall torch -y pip config set global.trusted-host "download.pytorch.org mirrors.huaweicloud.com mirrors.aliyun.com" pip config set global.extra-index-url "https://download.pytorch.org/whl/cpu/ https://mirrors.huaweicloud.com/ascend/repos/pypi" pip install torchvision==0.20.1 pip install torch-npu==2.5.1.post1.dev20250619 |
|---|
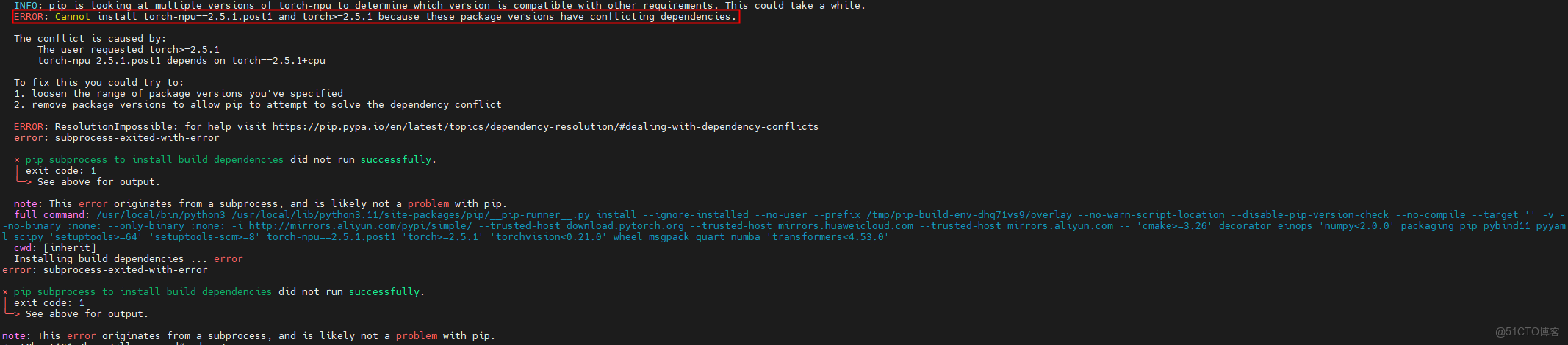
(2)依賴衝突:torch-npu 與 torch 版本不兼容
現象:Cannot install torch-npu==2.5.1.post1 and torch>=2.5.1 ...
解法:
| <font style="color:rgb(100, 106, 115);">Bash</font>pip uninstall torch==2.5.1 torch-npu==2.5.1.post1.dev20250619 -y pip cache purge pip config unset global.extra-index-url pip config set global.extra-index-url "https://download.pytorch.org/whl/cpu/ https://mirrors.huaweicloud.com/ascend/repos/pypi" pip install torch==2.5.1 pip install torch-npu==2.5.1.post1.dev20250619 pip show torch torch-npu | grep Version | | :--- |
(3)NPU OOM
現象:RuntimeError: NPU out of memory ...
根因:量化未生效或 batch 過大。
解法:啓動參數加 --quantization ascend;調小 --max-model-len / --max-num-batched-tokens / --max-num-seqs。
(4)aclnnQuantMatmulV4 類型不支持
現象:Tensor scale not implemented for DT_FLOAT16 ...
根因:模型 torch_dtype 與內核期望不符。
解法:改模型 config.json:"torch_dtype":"bfloat16"。
(5)HCCL 初始化失敗
現象:HCCL function error ... error code is 6
根因:HCCL_IF_IP 與本機 IP 不一致 / ranktable 不匹配。
解法:修正 HCCL_IF_IP,複查 ranktable.json 與實際卡數/網卡。
<font style="color:#3370FF;">7. </font>優化建議(進階)
KV 策略:長文本場景適當提高 --max-model-len,但要與 Decode 側併發上限平衡;觀察 PagedAttention 的 page 命中情況,避免頻繁遷移。
並行度:--tensor-parallel-size 與模型結構相關;EP(專家並行)建議先按官方實踐設置,壓測後再做微調。
IRQ/綁核:Decode 端對延遲敏感,建議業務線程與高頻 IRQ 分核(同 NUMA)。
代理層:把路由邏輯從業務進程剝離,便於後續橫向擴縮(多 P / 多 D)。
故障演練:壓測時主動製造 Decode 端抖動,觀察代理的重試/熔斷策略是否生效。
<font style="color:#3370FF;">8. </font>小結
PD 分離 讓 Prefill 的計算與 Decode 的訪存/帶寬壓力“各歸其位”,避免互相爭搶。
vLLM 的 PagedAttention 把 KV Cache 的佔用與碎片化壓得更穩,適合長上下文與高併發。
在 vLLM-ascend 上部署 DeepSeek-V3-w8a8 的關鍵,是 版本對齊、量化生效、HCCL 正確 與 KV 傳輸配置。
按文中流程走一遍,基本能做到“可復現、可壓測、可擴展”。剩下的,就是基於你的業務畫像做參數的工程化微調了。