
視頻説明:
MNNVL 超節點集合通信初識、NCCL、SuperPod、SuperNode,scale-up,Multi-Node NvLink、啥是超節點_嗶哩嗶哩_bilibili
前言
NCCL、ACCL等集合通信庫發展的早期,並沒有超節點(SuperNode/SuperPod)的概念,這些集合通信庫是如何支撐超節點集合通信的?
AllReduce、AlltoAll等集合通信,是現在大模型訓練/推理必不可少的底層支撐。並且隨着大模型參數量不斷上升,對集合通信性能的要求越來越高,超節點(SuperNode/SuperPod)應運而生。
哈哈哈,本文分享:
1、什麼是超節點
2、非超節點的傳統集合通信
3、超節點集合通信
一、什麼是超節點
隨着 AIGC 等大模型參數規模的不斷增長,對 GPU 集羣的規模需求也在不斷擴大,從千卡級到萬卡級甚至更高。傳統的單台服務器受限於空間、功耗和散熱等因素,能塞入的 GPU 數量有限,且基於 PCIe 協議的數據傳輸速率慢、時延高,無法滿足需求。為了解決這些問題,超節點(SuperNode/SuperPod)被提出。超節點是通過超大帶寬低延遲互聯的多 GPU系統,由多台服務器和網絡設備共同組成,這些設備處於同一個超帶寬域。
在集合通信超節點編程中,一個超節點就被叫做一個NvLink域或AccLink域。也就是大家所熟知的MNNVL(Multi-Node NvLink)多節點NvLink或MNACL(Multi-Node AccLink)多節點AccLink。
來個形象點的解釋就是:能夠通過Nvlink/AccLink進行跨服務器(跨節點)超高帶寬超低延遲通信的眾多GPU,就構成了一個超節點。
哈哈哈,再來兩個圖直觀的感受下。
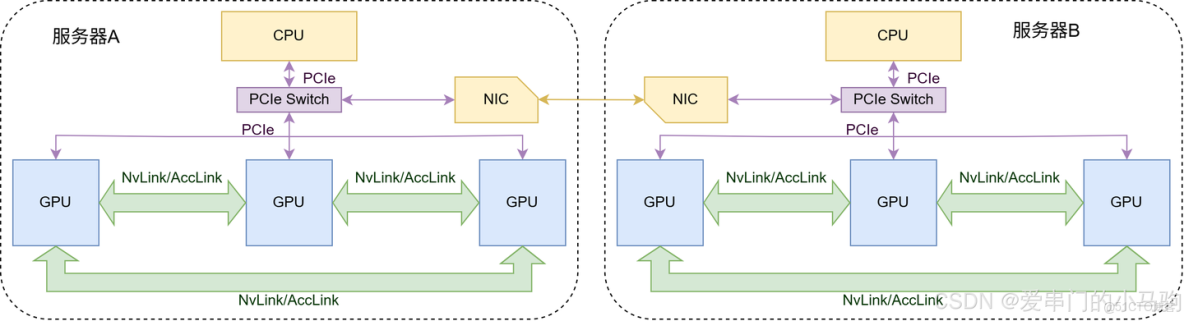
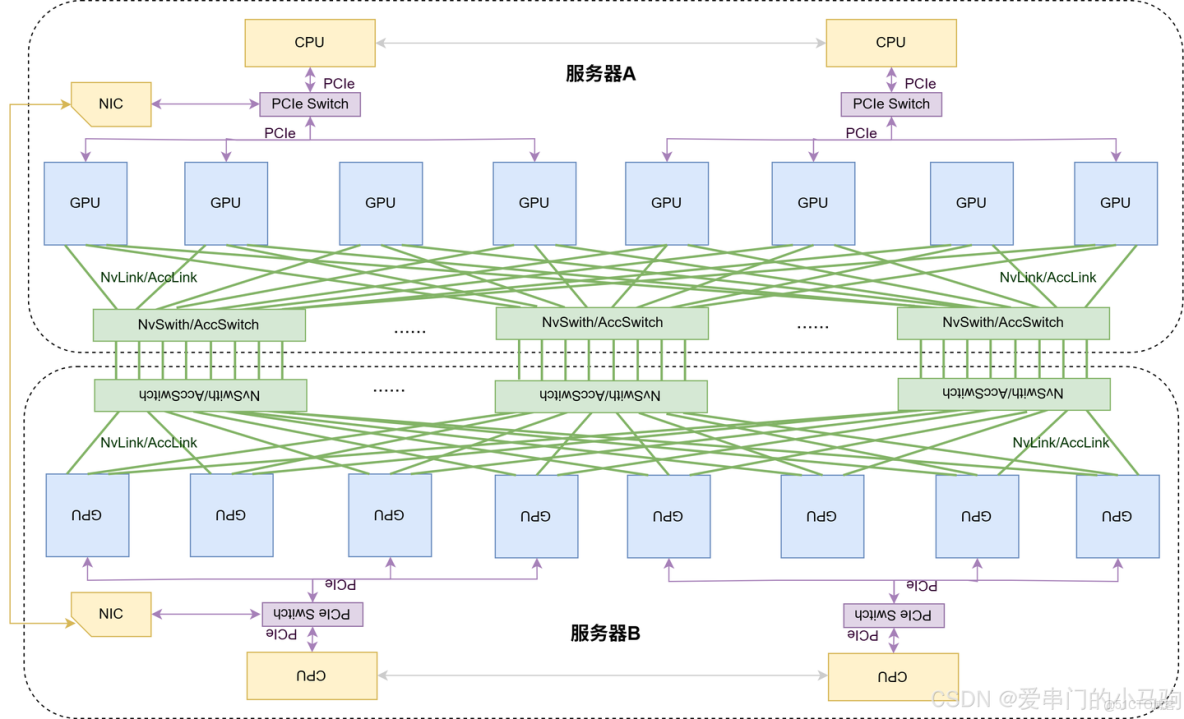
圖1是一個超節點麼?顯然不是!服務器A是節點,服務器B是節點,但是服務器A和B之間是通過延遲較高網卡相連,不是通過高帶寬低延遲的NvLink/AccLink相連,不構成一個超節點。
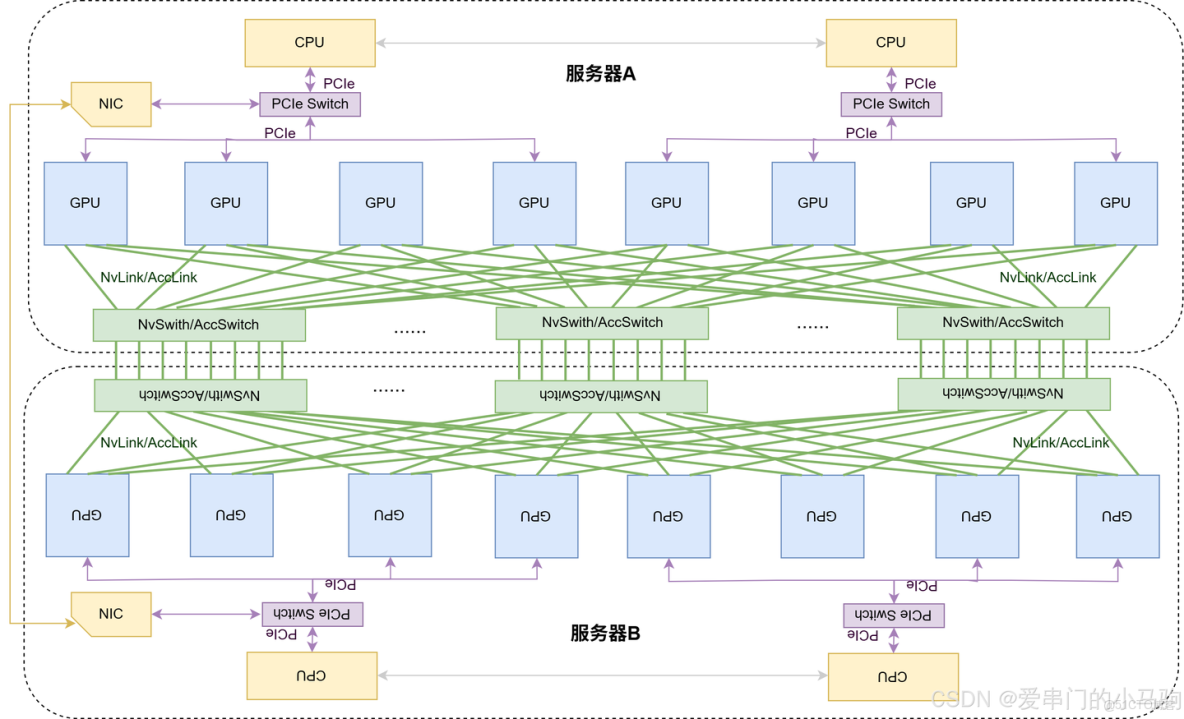
下面的圖2是一個超節點麼?哈哈哈,是的!服務器節點A和服務器節點B的眾多GPU通過NvLink/AccLink相連,構成了NvLink/AccLink域,是多節點的NvLink/AccLink。
二、非超節點的傳統集合通信
哈哈哈,淺淺回顧一下非超節點的集合通信。集合通信早期沒有超節點,集合通信也相對簡單點。
2.1 拓撲識別
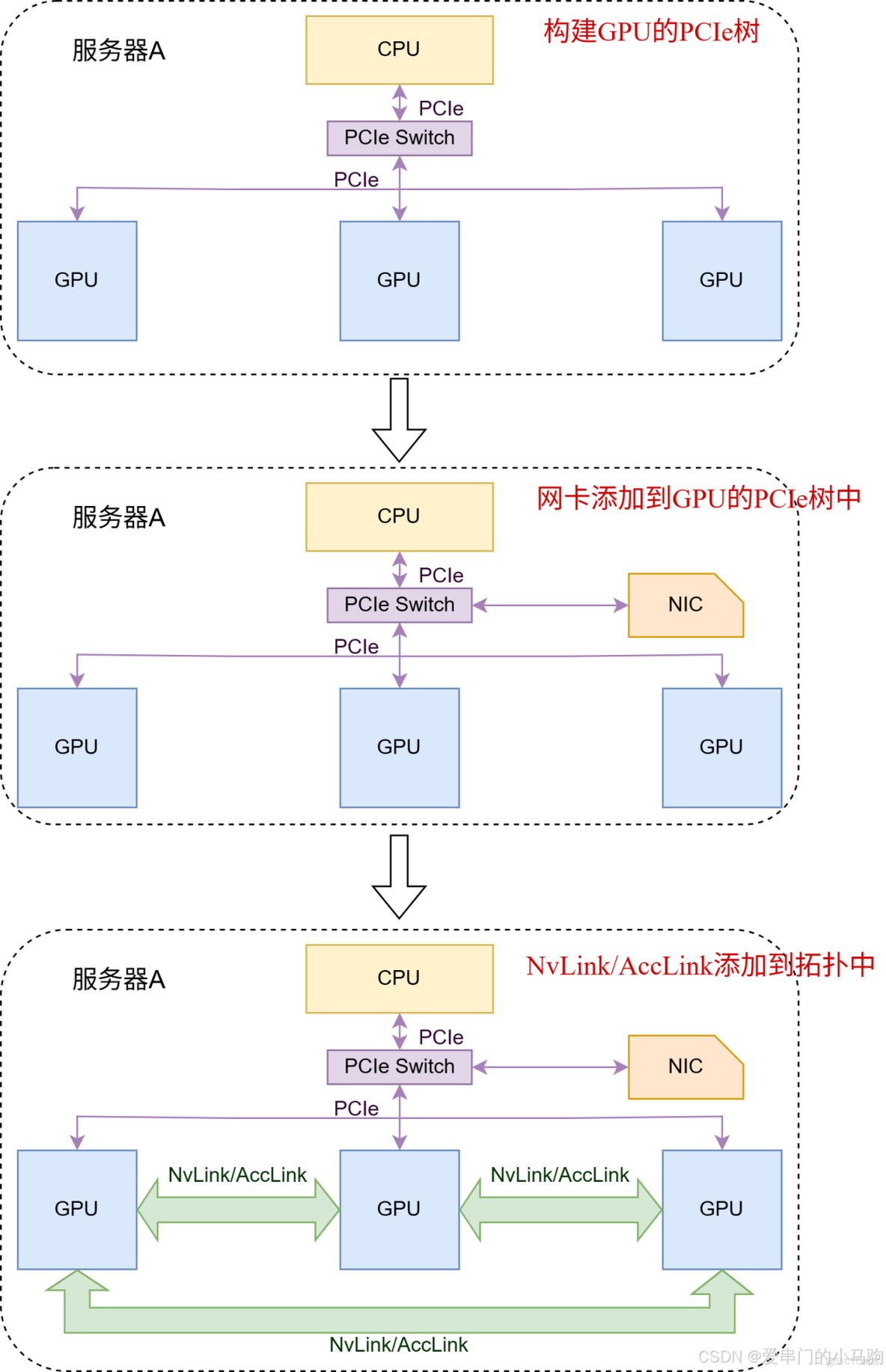
非超節點的傳統集合通信拓撲識別核心流程如圖3所示。
1.構建GPU的PCIe樹
2.將網卡添加到GPU的PCIe樹中
3.如果有NvLink/AccLink連接,將NvLink/AccLink添加到拓撲中。
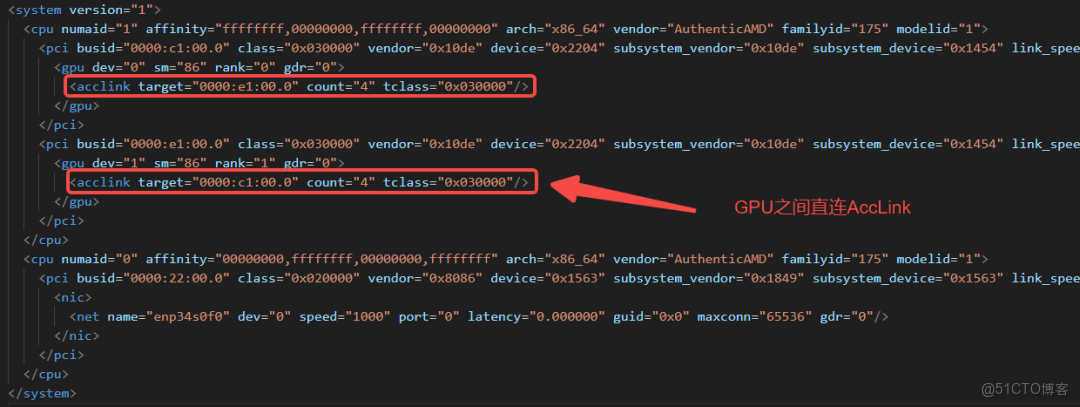
沒有超節點時,每個服務器節點只需完成自生的拓撲識別,如圖4所示,給出了ACCL識別出來的一台服務器拓撲文件,可以看到CPU、GPU、NIC、直連AccLink、PCIe等信息。
可以看出,沒有超節點時,每個服務器只完成服務器內拓撲識別,難以滿足超節點集合通信需求。那超節點的拓撲識別是如何做的,見下一章?
2.2 集合通信算法
傳統非超節點集合通信,由於節點內NvLink/AccLink的通信延遲帶寬性能遠高於跨服務器的網卡通信,因此集合通信算法嚴格區分節點內和節點間通信。
最常見的集合通信算法就是服務器內構建ring環,服務器間構建tree樹。
如下圖所示,rank就代表GPU,服務器內構建ring環。

node就代表服務器節點,服務器間構建tree樹。
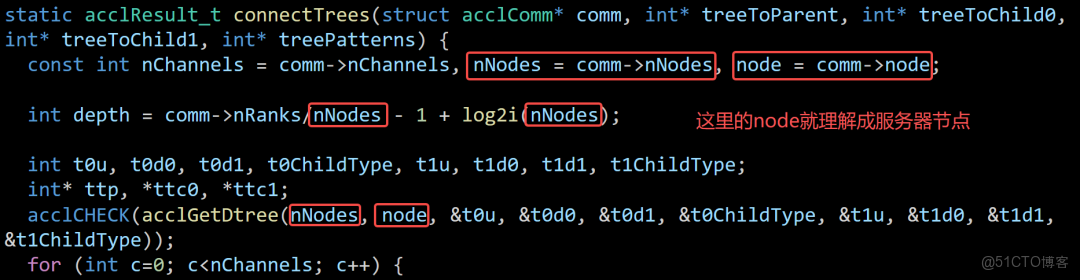
由於超節點NvLink/AccLink是跨服務器的,還這麼搞肯定有問題。
三、超節點集合通信
超節點出現後,集合通信的整個框架都做了相應修改和調整。今天呢,我們初步瞭解一下其中一部分內容。
3.1 拓撲識別
3.1.1 NvSwitch/AccSwitch交換芯識別
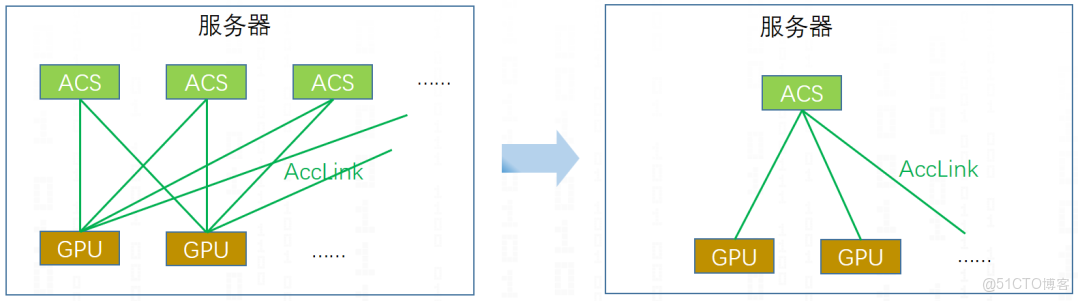
早期集合通信中,由於GPU數量有限,直接GPU間直連即可,沒有NvSwitch/AccSwitch(NVS/ACS),不需要識別交換芯片。因此在超節點拓撲識別中所要做的第一步就是將NvSwitch/AccSwitch交換芯識別出來。

如上圖代碼所示,ACS就代表AccSwitch交換芯,將AccSwitch交換芯識別出來,並增加到集合通信的拓撲圖中。
並且只要在system->nodes[ACS].count == 0時才會創建ACS節點,本質如圖5所示,不管實際有多少個AccSwitch交換芯拓撲上將其合併為一個,標識當前服務器裏面有AccSwitch。當然探微芯聯ACCL集合通信庫也支持不合並AccSwitch交換芯的拓撲架構,來進行通信優化,這又是另外一套了,挖個坑,有時間再介紹,哈哈哈,此次我們還是偏NCCL。
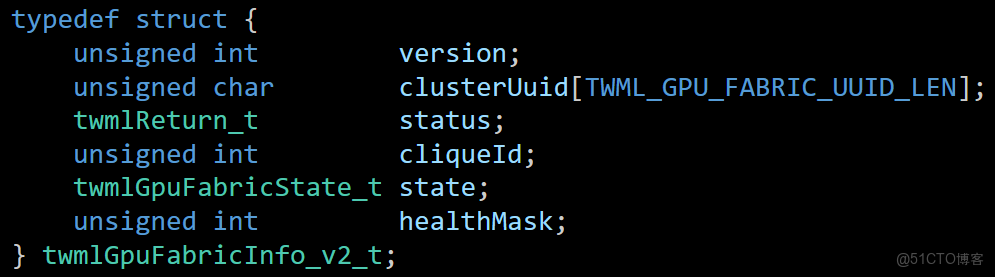
3.1.2 跨服務器拓撲識別
超節點,當然不能只在服務器節點內搞一搞,必須得跨服務器。如下面的圖所示,建立集羣和AccLink域的超節點標識clusterUuid、CliqueId。

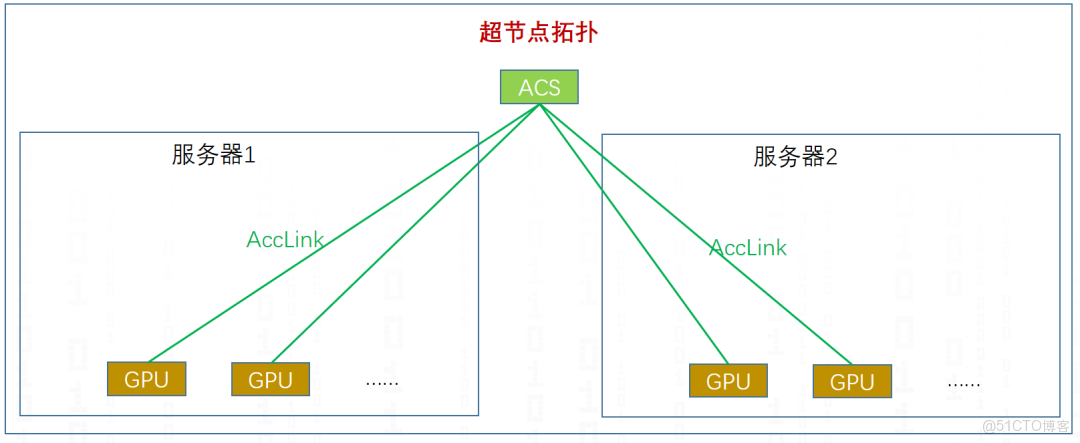
標識通信域之後,進行跨服務器拓撲融合,得到如圖6的AccLink域的超節點拓撲。自此,ACCL構建了自己的超節點拓撲,一個AccLink通信域
3.2 集合通信算法
針對超節點的集合通信,有一個兩個需要注意的點。
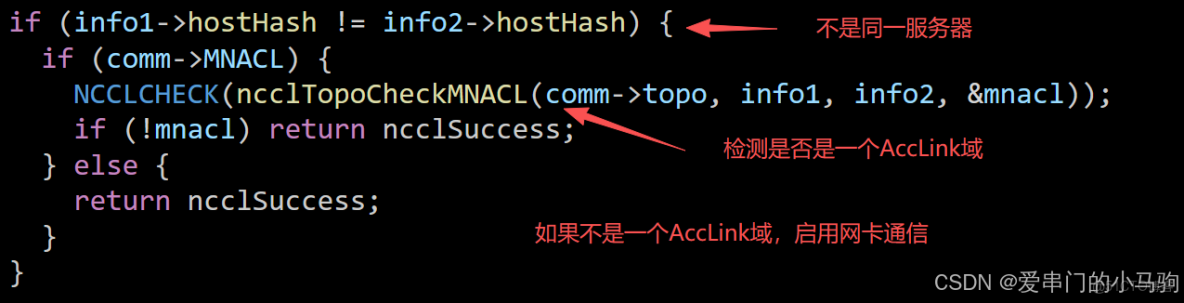
1.有跨服務器的AccLink,當然不用網卡進行通信。
2.多級AccSwitch的影響。
針對第一條,如下圖所示,集合通信時,檢測兩個服務器間能否進行AccLink通信,如果能進行AccLink通信,用AccLink通信,否則才使用網卡進行通信。
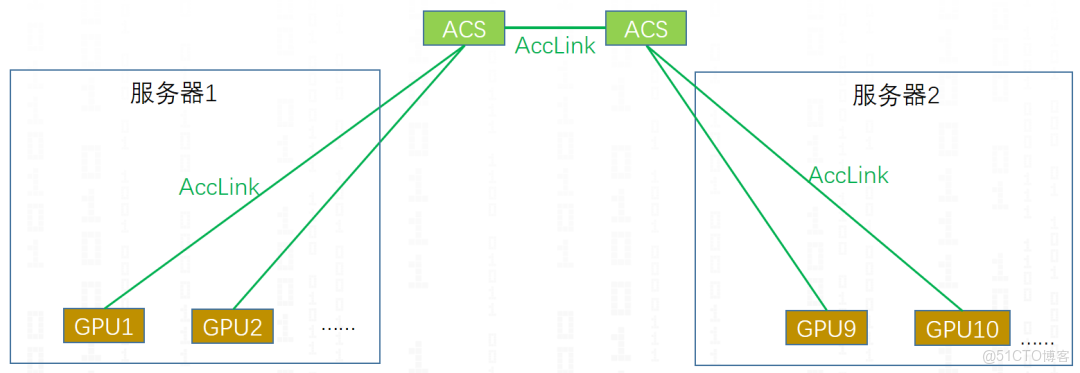
針對第二條,多級AccSwitch的影響,我們將下面的圖7抽象一下。
抽象一下,得到下面的圖8,可以明顯看出GPU1和GPU2只通過一級ACS(AccSwitch)就能進行通信,而GPU1和和GPU9需要進行兩級ACS(AccSwitch)進行通信,在集合通信中,對能夠一級ACS(AccSwitch)進行通信的GPU進行標記,優先一級ACS,優化通信過程。
當然ACCL/NCCL超節點還有在網計算、Symmetric Memory對稱內存、單端put/fetch操作,AccSwitch/NvSwitch特性等等。記得點個關注、我們下次有時間繼續分享。就道是紙短情長啊,哈哈哈紙也不短,畢竟電子紙,就是得早點睡覺明天繼續奮鬥。
文章出處:https://mp.weixin.qq.com/s/OUmLAvBpK_U_QBtO36IOmw