
MoE(Mixture of Experts,專家混合模型))是當前大模型(尤其是 GPT-4、Gemini、Mixtral、DeepSeek 等)架構中非常核心的一個概念。
MoE 的思想非常直白:不同的 專家/Expert 只負責處理自己擅長的那一類輸入,而不是讓整個模型的所有參數都去處理所有任務。
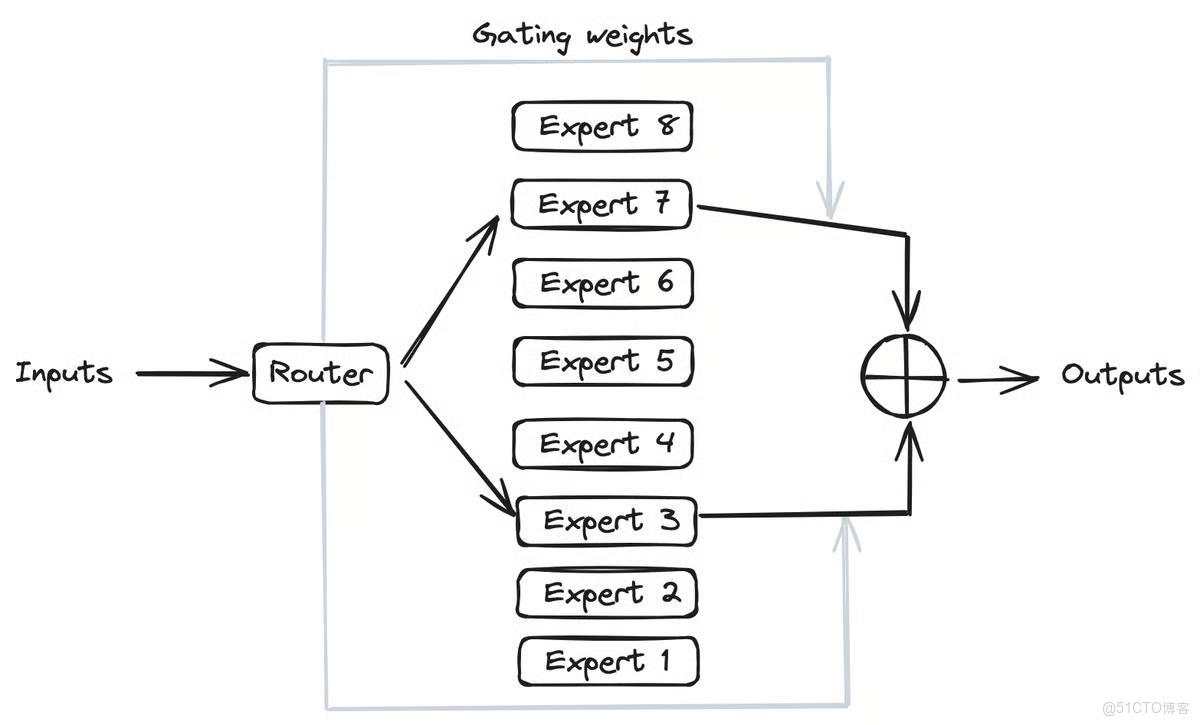
也就是説:
- 一個 MoE 模型內部其實包含了很多個“子網絡”(這些子網絡叫做
專家/Expert); - 每次輸入一句話或一段文本時,模型不會激活所有
專家/Expert,而是通過一個路由/Router來挑選 最合適的幾個專家; - 只有被選中的那幾個
專家/Expert會參與這次計算,從而節省大量算力。
為什麼要用MoE
1. 計算成本更低,模型容量更大
傳統 Transformer:
- 每一層都要激活所有參數;
想增加模型容量(參數量),計算成本會線性上升。
MoE:
- 只有少數專家被激活(稀疏激活);
例如:一個 1 萬億參數的 MoE 模型,每次推理只用 10% 參數;因此,在計算成本不變的情況下,模型容量可以放大 10 倍甚至 100 倍。
例如:
Google 的 Switch Transformer(1.6T 參數)推理成本 ≈ GPT-3(175B 參數),但性能更強。
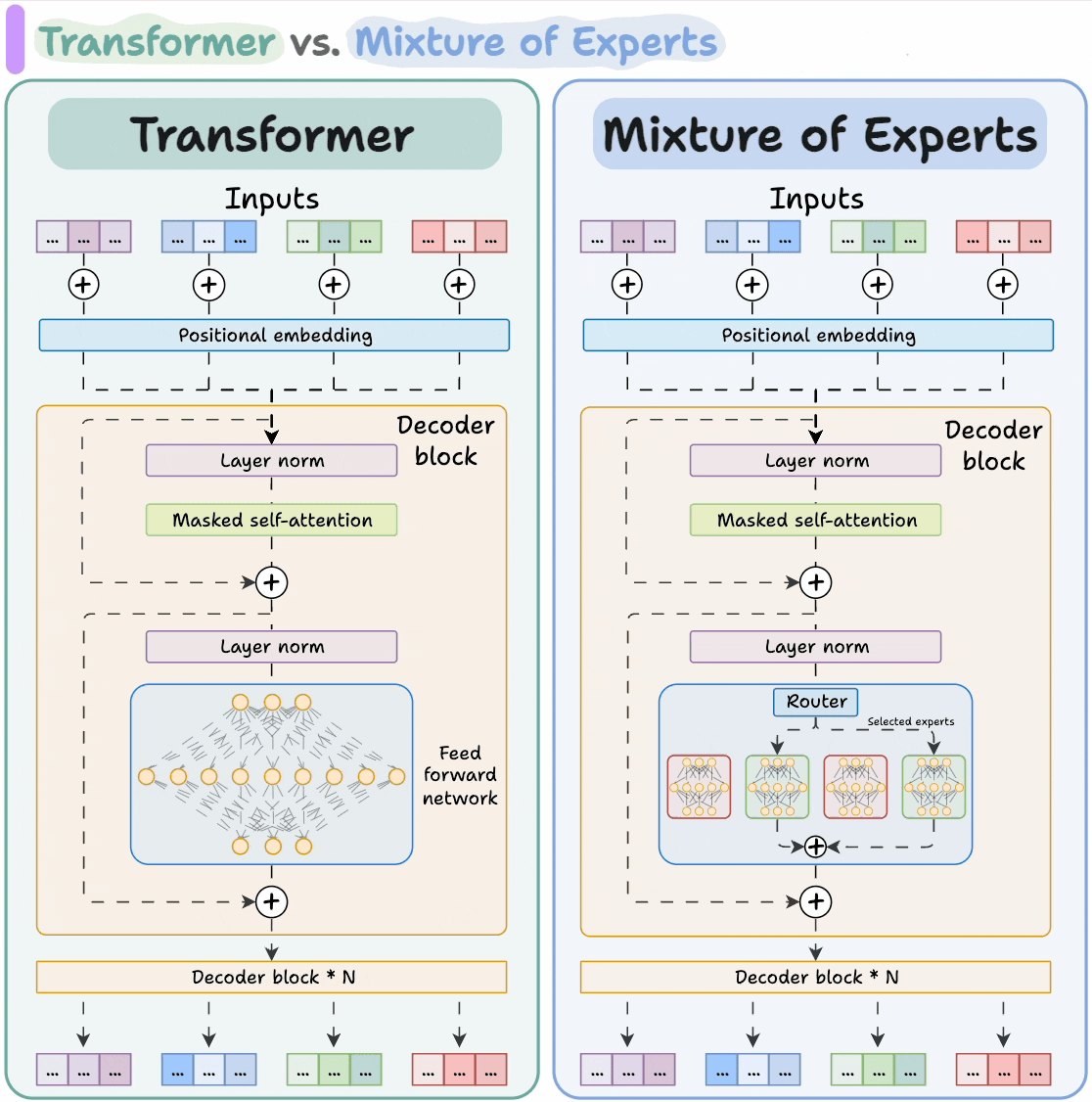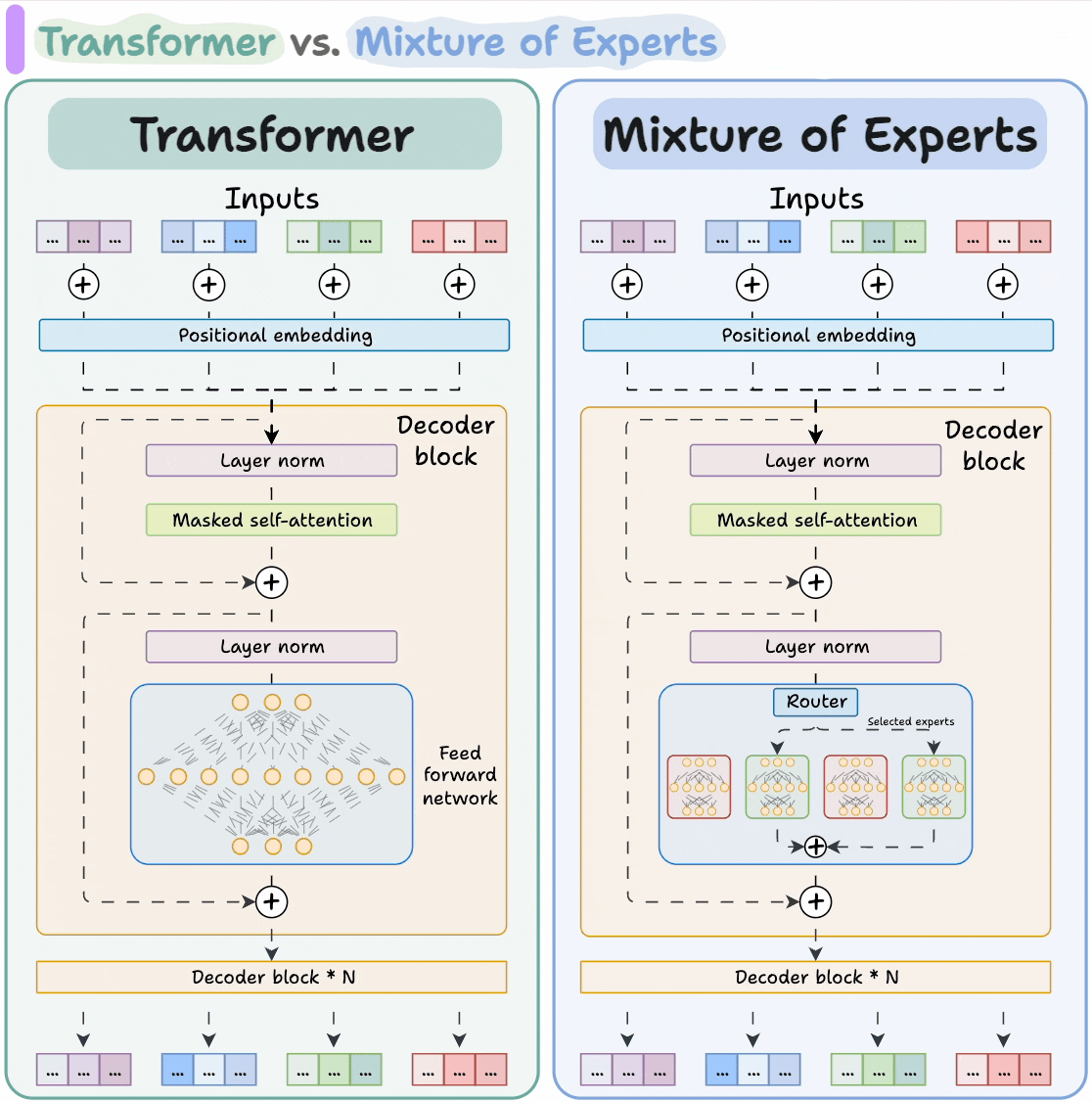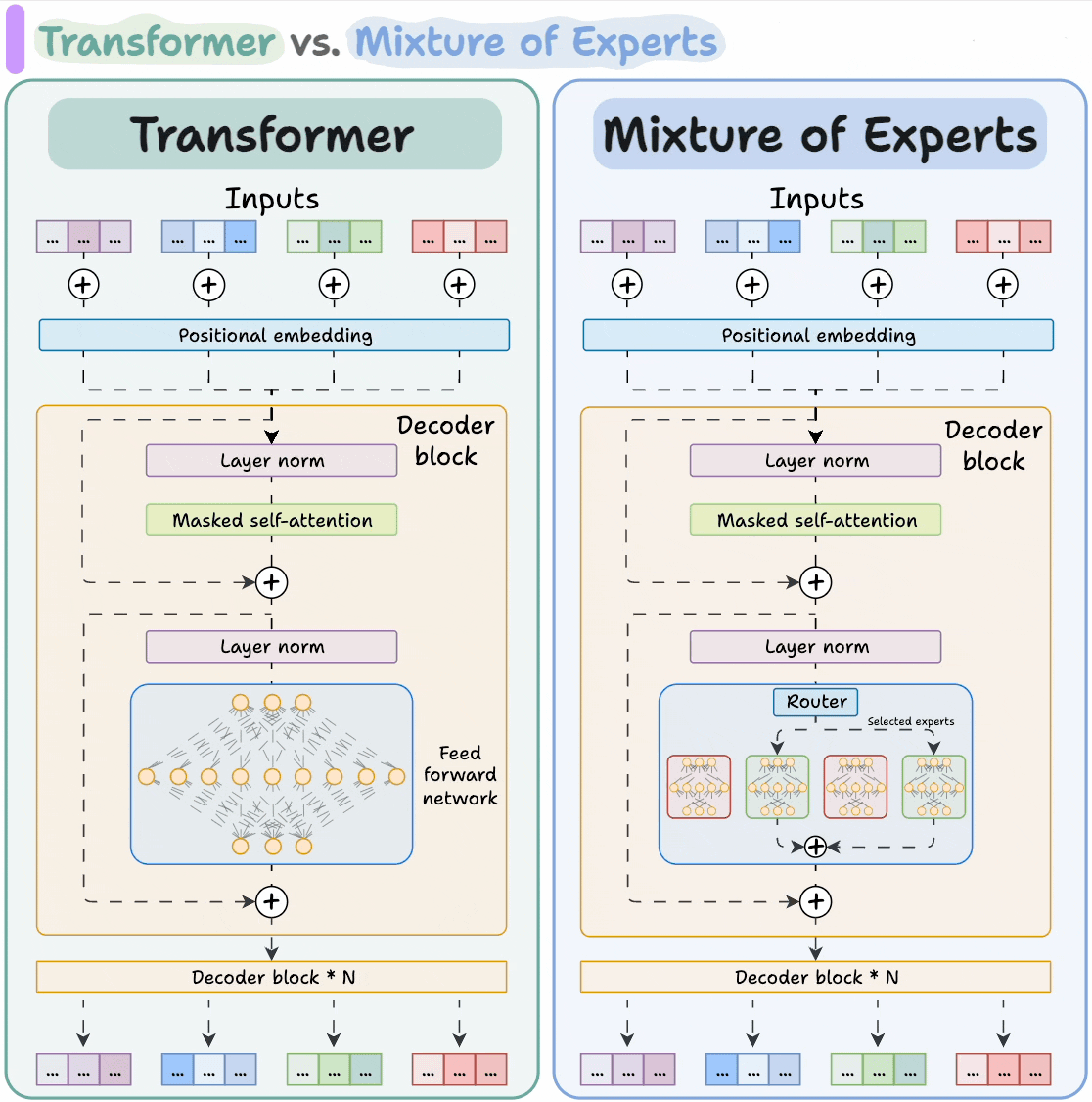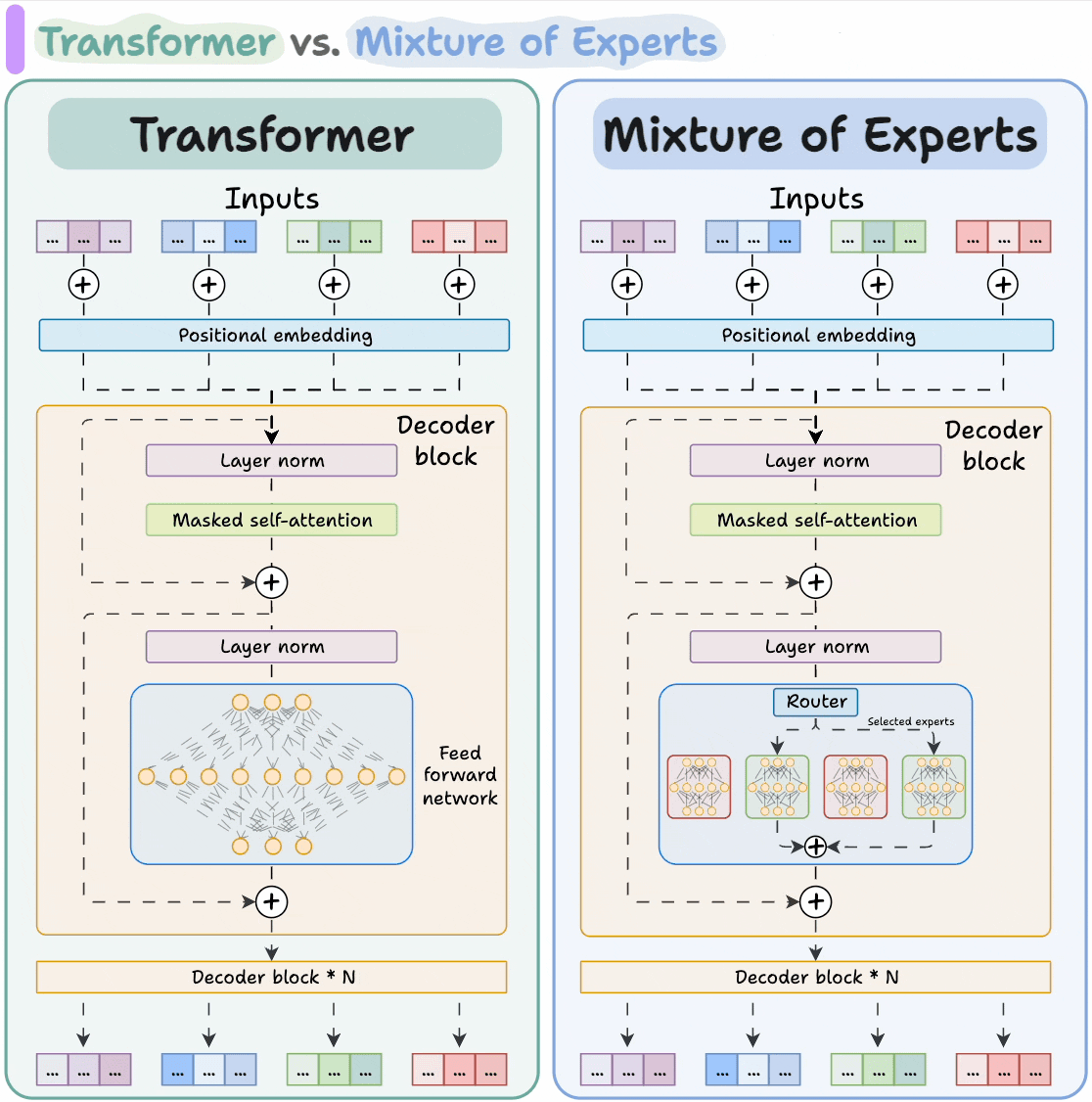
2. 模型可以專長分工
MoE 的“專家”結構天然支持 不同子模型擅長不同任務,這讓模型更像一個“專家團隊”,比“通才模型”更智能、更高效。
想象你在一個醫院看病:
- 傳統模型:不管你是牙疼還是腳疼,所有科室醫生都要參與討論 → 效率極低。
- MoE 模型:門診處(Router)判斷你該看牙科,於是只調動牙科和內科醫生(Expert 3、Expert 7) → 快而準。
3. 可擴展性強
MoE 架構是可增量擴展的:
- 你可以隨時添加新的 Experts,而不用重新訓練整個模型;
- 很適合 多任務學習、多語言擴展 等場景;
例如 DeepSeek 的 MoE 架構,可以動態激活與任務匹配的專家模塊。
4. 訓練/推理並行性好
不同 Expert 可以放在不同 GPU 上並行計算。
在大規模集羣中,MoE 的通信方式非常適合分佈式訓練。
MoE 的主要缺點
MoE不是萬能的,它也有自己的缺點。
| 問題 | 説明 |
|---|---|
| 訓練複雜,容易失衡 | Router 可能會偏好某幾個 Expert,導致部分專家“閒置”,部分“過載” |
| 負載均衡困難 | 必須加入額外的“Load Balancing Loss”來強制均勻使用 Experts |
| 通信開銷大 | 分佈式訓練時,輸入 token 要分發到不同 GPU(專家所在節點),需要 All-to-All 通信 |
| 優化難度高 | Routing、稀疏路由、專家並行都需要複雜的工程實現 |
| 推理延遲波動 | 因為不同輸入觸發的專家不同,推理時延不穩定 |
| 調參複雜 | 例如:專家數量、激活比例(Top-1 or Top-2)、平衡損失、Drop Tokens 等都很敏感 |
業界典型 MoE 應用
| 模型 | MoE 應用特點 |
|---|---|
| Google Switch Transformer | 每層只有 1 個 Expert 被激活(Top-1),參數達 1.6T,訓練成本與 GPT-3 相近 |
| Google GLaM | 稀疏激活的 MoE 模型,每個 token 激活 2 個 Expert,參數達 1.2T |
| Mixtral (by Mistral) | 採用 8×7B Experts,每次激活 2 個 Expert,相當於性能≈13B 模型,但推理只需 ≈2 Experts 的計算量 |
| DeepSeek-V2/V3 (中國團隊) | 採用混合稀疏 MoE,具備極高推理效率和動態專家調度能力 |
| GPT-4 (推測) | 多路專家架構,每個請求只調用部分模型參數(官方未公開細節) |
適用場景與不適用場景
MoE只在特定場合才適用。
| 場景 | 是否推薦使用 MoE |
|---|---|
| 多語言大模型 | ✅ 非常適合,不同語言走不同專家 |
| 通用大模型(GPT類) | ✅ 可以顯著提升容量與效率 |
| 專用小模型(單任務) | ❌ 不推薦,MoE 帶來的複雜度得不償失 |
| 邊緣/輕量模型 | ❌ 不適合,通信開銷過大 |
簡單總結
與 傳統 Transformer相比,MoE 有如下特點:
| 項目 | MoE 模型 | 傳統 Transformer |
|---|---|---|
| 參數量 | 極大(可達萬億) | 較小(幾百億) |
| 激活參數 | 稀疏(部分專家) | 全部激活 |
| 計算成本 | 較低 | 高 |
| 專業性 | 專家分工明確 | 全局模型 |
| 擴展性 | 強,可增量 | 弱 |
| 工程複雜度 | 高 | 低 |
| 推理延遲 | 不穩定 | 穩定 |
實際上,MoE 的設計思想不僅僅適用於傳統的大語言模型,它是一個很好的架構,也可以應用在人工智能以及其它各個領域。
🪐感謝觀看,祝好運🪐