

在人工智能研究的發展歷程中,卷積神經網絡(CNN)因其在模式識別與特徵提取中的卓越表現,成為深度學習的重要基礎工具。CNN最初主要面向二維圖像數據,通過卷積核在局部區域提取空間模式,使得網絡能夠自動構建從低級到高級的特徵表示。然而,隨着自然語言處理技術的不斷進步,研究者發現CNN在文本序列建模中同樣具有顯著作用,能夠識別局部詞組模式、捕捉短語語義信息,並在文本分類、情感分析等任務中取得優異性能。這種跨領域應用顯示了CNN結構的普適性,同時也暴露出在不同數據形式與任務目標下的適應性差異。
計算機視覺與自然語言處理在數據特性和任務需求上有根本差異。圖像數據呈現為二維甚至三維矩陣,空間結構直接影響特徵提取策略;而文本數據是離散符號序列,通常需要通過向量化映射將其轉換為連續表示,以便神經網絡處理。面對這些差異,CNN在不同領域的實現方式有所調整,但其核心設計理念——局部模式感知、權值共享、特徵層次化與匯聚——仍然保持一致。深入分析CNN在視覺與文本任務中的聯繫與區別,有助於理解深度學習模型的跨領域能力,同時為模型優化、任務適應以及多模態系統設計提供理論依據。
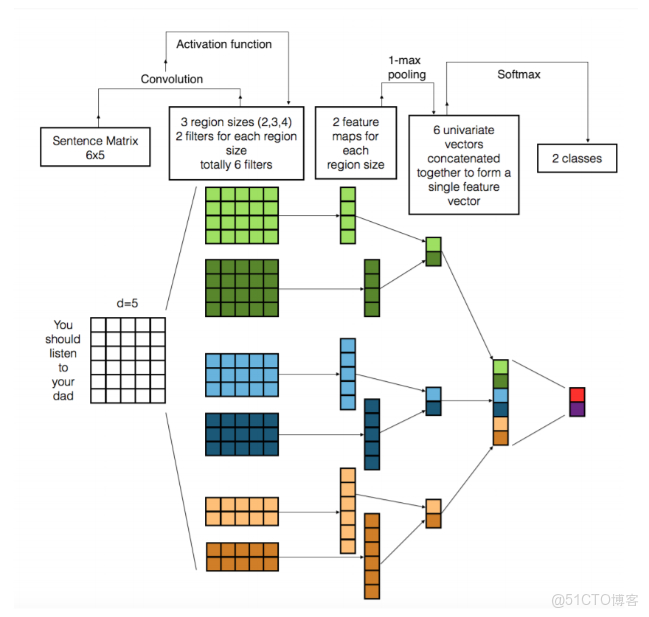
此外,CNN在CV與NLP中展現的不同特性,也引發了對網絡架構設計、卷積核選擇、池化策略以及訓練優化方法的深度研究。在圖像處理中,CNN更注重空間特徵的連續性和局部模式的組合;在文本處理中,CNN需要關注詞序列的局部組合及其語義表達,同時面對長序列依賴和上下文關係的挑戰。理解這些差異不僅有助於模型性能提升,也為探索卷積與其他網絡結構(如RNN或Transformer)的融合策略提供參考。
1 CNN基本原理回顧
卷積神經網絡(CNN)是一類專門處理具有網格結構數據的深度學習模型,其核心思想是通過卷積操作提取局部特徵,並通過多層堆疊構建高層次表示。在分析CNN在計算機視覺與自然語言處理中的聯繫與區別前,有必要回顧其基本原理和結構設計。
1.1 卷積操作
卷積層是CNN的核心,其通過卷積核在輸入數據上滑動,計算局部區域與卷積核權重的加權和,從而提取局部模式。在二維圖像中,卷積操作可表示為:

其中,





在一維序列數據(如文本嵌入向量序列)中,卷積操作簡化為:

這種一維卷積可用於捕捉局部n-gram特徵,體現CNN在不同數據維度下的適應性。
1.2 非線性激活函數
卷積操作後通常使用非線性激活函數引入非線性表達能力,常見選擇包括ReLU、Leaky ReLU和GELU:

非線性激活保證了CNN能夠表示複雜模式,而非僅限於線性組合特徵。
1.3 池化層
池化層用於對局部特徵進行匯聚,降低特徵圖維度,同時增強對局部變形和噪聲的魯棒性。最常用的池化操作為最大池化(Max Pooling):

其中
1.4 層次特徵構建
多層卷積和池化的堆疊,使CNN能夠從低級到高級逐步構建特徵層次。在圖像中,低層卷積核檢測邊緣和紋理,高層卷積核組合複雜形狀和對象部件。在文本中,低層卷積核捕捉短語模式,高層卷積核聚合語義片段。
層疊結構也可表示為遞歸函數形式:

其中



1.5 參數優化與反向傳播
CNN訓練通過梯度下降優化卷積核權重和偏置。損失函數

通過反向傳播和梯度更新,CNN能夠自適應調整卷積核以捕捉最具判別力的局部模式。
2 CNN在計算機視覺中的應用
在計算機視覺領域,CNN以其卓越的空間特徵提取能力成為核心模型。其主要應用包括圖像分類、目標檢測、語義分割以及特徵可視化等。
2.1 圖像分類
圖像分類任務旨在將輸入圖像映射到預定義類別集合。CNN通過卷積層提取局部邊緣、紋理和形狀特徵,再通過全連接層或全局池化層進行分類。對於輸入圖像

其中


其中


著名網絡架構包括LeNet、AlexNet、VGG和ResNet。其中,ResNet引入殘差連接:

有效緩解了深層網絡的梯度消失問題,使網絡能夠訓練數百層深度,同時保持穩定的性能。
2.2 目標檢測
目標檢測不僅需要識別圖像內容,還需定位目標。CNN通常用於生成特徵圖,再結合候選區域方法(R-CNN系列)或迴歸方法(YOLO系列)實現檢測。特徵映射


其中

2.3 圖像分割
在語義分割任務中,CNN通過編碼器-解碼器結構實現像素級分類。編碼器提取多層次特徵,解碼器通過上採樣重建空間分辨率:

U-Net等網絡利用跳躍連接(Skip Connection)保留編碼器的細粒度信息,提高分割精度。
2.4 特徵可視化與解釋
CNN卷積核可視作特徵檢測器,低層卷積核響應邊緣和紋理,高層卷積核響應對象部分或整體。通過Grad-CAM等方法,卷積特徵映射可與輸入圖像對齊,揭示網絡關注的區域:

其中


3 CNN在自然語言處理中的應用
在NLP中,CNN的應用初期主要集中在文本分類、情感分析、實體識別等任務中。與圖像不同,文本數據是離散序列,因此CNN在NLP中的輸入通常經過詞嵌入或字符嵌入映射到連續向量空間:
- 文本分類:通過一維卷積核滑動在嵌入向量序列上提取n-gram特徵,池化操作匯聚重要特徵,再通過全連接層輸出類別。例如,Kim(2014)提出的CNN文本分類模型通過多尺寸卷積核捕捉不同長度的局部詞序列特徵。
- 情感分析與意圖識別:CNN能夠檢測局部詞組組合的情感或語義模式,並對全局語義進行匯聚,從而判斷文本的情感傾向或意圖。
- 序列標註任務:在命名實體識別(NER)中,CNN可作為局部特徵提取器,與循環神經網絡(RNN)或條件隨機場(CRF)結合,實現對序列標籤的預測。
- 文本特徵可視化:卷積核在不同位置響應不同詞序列,能夠揭示模型對關鍵短語的敏感度。不同卷積核長度對短語模式的捕捉能力有差異,這種設計使CNN能夠靈活應對不同文本結構。
在NLP中,卷積核長度和數量如何影響模型對語義和語法的捕捉能力?CNN在捕捉長距離依賴上是否受限,是否需要結合其他序列模型增強表現?
4 CNN在CV與NLP的聯繫
儘管CV和NLP的數據形式和任務目標差異明顯,CNN在兩個領域的共通點在於其核心思想的統一:
- 局部模式提取:無論是圖像中的局部像素模式,還是文本中的局部詞序列,CNN都能夠通過卷積核識別這些模式。
- 權值共享機制:權值共享減少了參數量,使模型能夠在不同位置檢測相同模式,在CV中對應空間模式,在NLP中對應語義或短語模式。
- 特徵層次化:多層卷積層構建特徵層次,從低級到高級。在CV中是從邊緣到對象部分,在NLP中是從局部詞組到語義片段。
- 池化匯聚機制:池化操作在兩個領域都能降低維度,提高模型對局部變化的魯棒性。在文本中,這相當於從詞序列中提取最具代表性的n-gram特徵。
CNN的局部感受野和權值共享機制是否可以進一步優化,使其在CV和NLP兩類任務中同時適應局部與全局特徵提取?
5 CNN在CV與NLP的區別
- 數據結構差異:圖像是二維甚至三維數據,通道(如RGB)信息明確,而文本是離散序列,需要映射到連續向量空間才能使用卷積操作。
- 卷積維度不同:CV多使用二維卷積(2D Conv)操作,而NLP主要使用一維卷積(1D Conv)在序列上滑動卷積核。
- 特徵語義差異:圖像特徵的空間局部性較強,像素之間的空間關係直接對應對象形態;文本特徵的語義局部性較弱,詞序列的局部模式可能不總是直接對應語義,需要通過嵌入向量捕捉潛在語義。
- 全局依賴捕捉:在圖像中,深層CNN可以通過逐步擴大感受野捕捉全局特徵;在文本中,長序列依賴較難通過卷積捕捉,通常需要結合RNN或Transformer結構。
- 數據增強與正則化方法:CV中常用旋轉、翻轉、縮放等數據增強方法;NLP中數據增強相對複雜,需要同義詞替換、隨機插入或語義保持的擾動技術。
CNN在處理長序列文本時,其局部感受野和池化操作是否會導致重要語義信息的丟失?是否需要設計新的卷積架構或結合注意力機制改善長距離依賴建模?
6 CNN優化方法在不同領域的異同
- 激活函數選擇:CV中常用ReLU及其變種,提高訓練速度並緩解梯度消失;NLP中也使用ReLU或GELU,但需要注意嵌入向量的分佈特點。
- 正則化策略:CV中使用Dropout、Batch Normalization等防止過擬合;NLP中結合Layer Normalization或Embedding Dropout優化序列特徵學習。
- 卷積核設計:在CV中,卷積核大小一般為3x3或5x5,以平衡特徵捕捉和計算量;在NLP中,卷積核長度決定了n-gram模式捕捉範圍,多尺寸卷積核能夠同時提取不同長度局部特徵。
- 多模態融合:在CV與NLP結合任務(如圖文檢索、視覺問答)中,CNN特徵可以與Transformer特徵融合,通過卷積處理圖像局部模式,再與文本卷積或嵌入向量結合,實現跨模態建模。
在跨領域任務中,如何協調卷積核設計、特徵匯聚和序列全局信息捕捉,以提升整體模型性能?
7 CNN與其他網絡結構的結合趨勢
在NLP領域,純CNN模型由於長距離依賴建模不足,常與RNN或Transformer結合:
- CNN+RNN:CNN提取局部特徵,RNN捕捉序列全局依賴。此方法在情感分析、文本分類等任務中效果顯著。
- CNN+Transformer:CNN用於局部模式提取,Transformer用於全局依賴建模。例如,在視覺問答任務中,圖像通過CNN提取特徵,再與文本Transformer進行多模態融合。
- 圖像文本聯合表示:CNN在CV中提取空間特徵,NLP中的卷積或嵌入用於提取文本局部模式,再通過注意力機制或對比學習實現統一表示。這種結合凸顯了CNN在不同領域特徵抽取的一致性及其侷限性。
在未來模型設計中,CNN是否仍然是局部特徵提取的核心方法?是否會被純注意力機制取代,或與其形成互補?
8 實踐中的設計策略與挑戰
在CV與NLP實踐中,設計CNN模型時需考慮以下要點:
- 卷積層深度:在CV中,深層網絡能夠捕捉更高層次的語義信息,但訓練難度增加;在NLP中,過深的卷積可能導致局部模式過度聚合,信息丟失。
- 卷積核尺寸與數量:卷積核尺寸直接影響局部特徵捕捉範圍,多尺寸卷積可同時提取不同長度特徵;卷積核數量影響特徵表示能力與計算複雜度。
- 池化策略:CV中常用最大池化降低空間維度並增強魯棒性;NLP中池化需考慮序列長度與重要詞彙信息的保留。
- 訓練數據量與正則化:CV中大規模圖像數據集(如ImageNet)支撐深層CNN訓練;NLP中語料庫多樣性決定了卷積模式學習的廣度,需要嵌入正則化、數據增強等策略。
如何在模型設計中權衡卷積層深度、卷積核尺寸和池化策略,從而同時兼顧特徵表達能力和計算效率,是研究者在CV與NLP中必須面對的問題。
9 總結與思考
CNN作為深度學習中最具影響力的模型之一,其在CV和NLP中的應用展示了跨領域適用性與差異性。核心聯繫在於局部模式提取、權值共享、特徵層次化和池化匯聚,而差異主要體現為數據結構、卷積維度、特徵語義及全局依賴捕捉能力。理解這些聯繫與區別,不僅有助於優化CNN架構,也為跨模態任務提供理論基礎。同時,CNN與其他模型結合、卷積核自適應設計以及跨模態特徵學習,是未來研究的重要方向。研究者需要在模型表達能力、訓練效率和任務適應性之間尋求平衡,推動CNN在不同領域的持續發展。