

在機器學習中,模型性能的評估不僅依賴於訓練數據上的表現,更取決於其在未見數據上的穩定性。訓練精度的提升固然令人欣喜,但若這種提升無法轉化為對新樣本的可靠預測,則表明模型可能已經偏離了學習的核心目標——從有限數據中提取普遍規律。過擬合正是這一偏離的體現,它揭示了模型複雜性、數據量、訓練策略與泛化能力之間的微妙平衡。
過擬合是統計學習理論中模型選擇與假設空間設計中不可避免的挑戰。當模型過度關注訓練樣本的特定特徵時,它會將噪聲或偶然性作為規律吸收,從而在新樣本上表現不穩定。這一現象不僅限制了模型在實際應用中的可靠性,也直接影響了人工智能系統的知識抽象能力與決策穩健性。
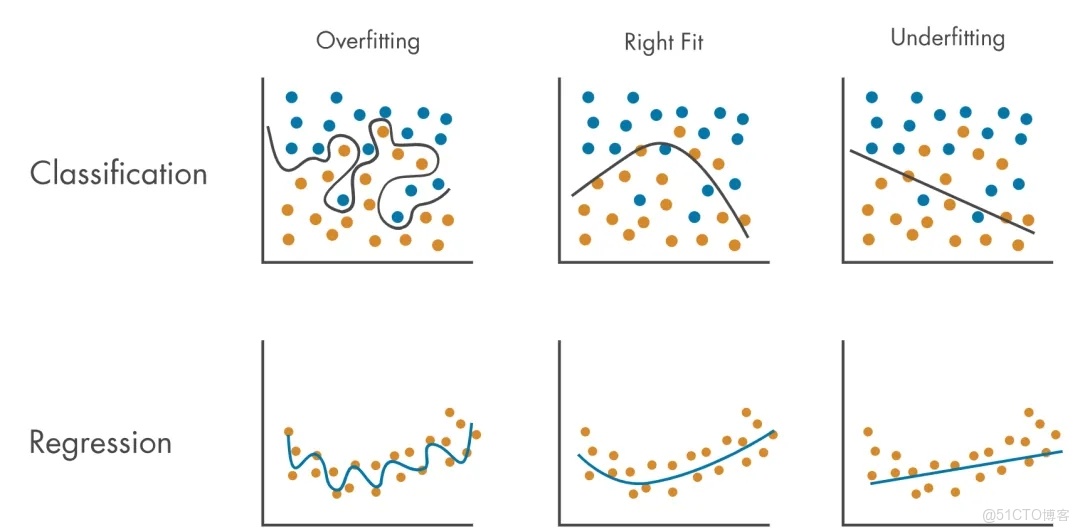
理解過擬合,需要深入分析訓練數據的分佈特性、模型結構的複雜性以及優化過程的動態特徵。通過這一分析,我們不僅可以界定何為合理的學習,還能探索提升模型泛化能力的數學原理和工程策略。在數據驅動智能系統日益普及的背景下,過擬合問題的研究不僅具有理論價值,也關係到算法設計、系統部署以及人工智能在複雜環境下的長期性能。
1. 過擬合的定義與本質
在統計學習理論中,機器學習的核心目標是從有限訓練數據中構建能夠對新樣本做出準確預測的模型。設訓練數據集為

模型的目標是學習一個映射函數 


在此框架下,過擬合(Overfitting)可形式化定義為:當模型在訓練數據上的誤差遠低於在獨立測試數據上的誤差時,即

模型被認為發生了過擬合。其本質在於模型在訓練階段捕獲了訓練數據中的偶然特徵或噪聲,而非反映數據生成機制的穩健規律。
從統計學習理論角度,過擬合是經驗風險最小化(Empirical Risk Minimization, ERM)與期望風險最小化之間的偏差。當模型複雜度增加時,訓練誤差(經驗風險)

通常單調下降,但模型對未知樣本的期望誤差

可能反而上升。複雜模型的高自由度使其能夠逼近任意訓練數據點,從而降低訓練誤差,但增加泛化風險。這種現象可以通過偏差-方差分解進一步理解:

其中 


在理論上,模型複雜度與泛化能力之間有一個最優平衡點。若模型複雜度超出該平衡點,即便訓練集表現完美,模型也無法保證對未知數據的可靠預測。過擬合體現了模型結構、訓練策略與數據規模之間的關係,是理解學習能力和泛化極限的核心問題。
2. 過擬合的直觀表現與診斷方法
過擬合的判定不僅依賴理論定義,更可以通過實驗與指標進行直觀分析。常見的判斷方法包括以下幾種:
2.1 訓練集與驗證集性能差異
最直接的過擬合判斷依據是訓練誤差與驗證誤差之間的差距。設訓練集誤差為 


即説明模型在訓練數據上表現良好,但在獨立數據上的泛化能力不足。例如,在分類任務中,訓練準確率接近100%,而驗證集準確率明顯下降,即為典型過擬合。
2.2 損失曲線分析
繪製訓練損失與驗證損失隨訓練迭代次數 



在深度神經網絡訓練中,這種現象被稱為驗證損失反彈(Validation Loss Bounce),反映模型對訓練數據細節的過度適應。
2.3 泛化誤差度量
泛化誤差 

通過分析泛化誤差隨模型複雜度 




2.4 交叉驗證與留一驗證
- K折交叉驗證(K-Fold CV):將數據集劃分為
個子集,循環使用其中
個子集訓練,剩餘一個子集驗證。若模型在不同折間表現波動大,説明其對特定訓練樣本依賴過強,即可能過擬合。
- 留一驗證(Leave-One-Out CV):每次僅留一個樣本作為驗證,其餘訓練。對小樣本問題尤其敏感,若模型在刪除單個樣本時性能顯著變化,則顯示出訓練階段對具體樣本的過度依賴。
2.5 學習曲線與訓練數據量關係
通過繪製學習曲線,分析訓練誤差與驗證誤差隨訓練樣本數量變化的趨勢,可以發現過擬合潛在風險。當增加數據量後,訓練誤差略有上升,但驗證誤差顯著下降,表明原模型在小樣本階段發生過擬合。
3. 過擬合的常見成因
3.1 模型複雜度過高
最直接的原因是模型參數數量遠超數據所能支撐的範圍。例如,一個擁有上億參數的神經網絡若僅在幾千樣本上訓練,幾乎必然出現過擬合。 數學上,模型的自由度過高意味着它能逼近任意函數形式,這在理論上雖具普適逼近能力,但在有限數據下將引入極高的方差。
3.2 訓練數據不足或樣本代表性差
當樣本數量有限,模型往往只能「記住」數據,而無法提取其中穩定結構。數據代表性差,如訓練集與真實分佈不一致,也會導致模型學習方向偏離。
3.3 噪聲與標籤錯誤
數據噪聲的干擾是另一根源。當訓練集中包含錯誤標籤或無關特徵時,高複雜度模型會試圖「解釋」這些隨機性,從而在訓練階段獲得更低誤差,卻失去預測可靠性。
3.4 過長訓練時間
訓練過程未及時中止,也會引發過擬合。若模型不斷優化訓練損失,它最後可能將數據細節全部信息存儲下來。此時驗證集性能下降,表明模型超越了合理學習階段。
3.5 正則化不足
缺乏正則化機制的模型容易自由調整權重以追尋訓練精度,從而導致參數不受約束。常見正則項如


其中
3.6 特徵冗餘或維度過高
高維特徵空間中,樣本點彼此之間的距離趨於均勻,導致模型難以分辨結構規律。此時若不進行特徵降維或主成分分析,模型會誤以為所有特徵都同等重要。
4. 理論解釋:偏差-方差分解與模型複雜性
偏差-方差分解提供了過擬合的理論基礎。預測誤差可拆分為三部分:

其中:
- Bias(偏差)反映模型假設與真實關係的系統偏離;
- Variance(方差)反映模型對訓練數據波動的敏感度;
為不可避免的噪聲項。
簡單模型通常偏差較高但方差較低,而複雜模型偏差較低但方差極高。過擬合正對應於方差主導階段:模型在訓練樣本間大幅振盪,對新樣本預測不穩定。
若以複雜度

找到曲線最低點對應的複雜度,是控制過擬合的關鍵。
5. 過擬合的典型案例分析
5.1 多項式迴歸
假設我們擬合一組數據點

當
5.2 神經網絡訓練
在深度學習中,模型層數和參數量龐大,極易陷入過擬合。例如,在圖像分類任務中若數據增強不足,網絡可能僅記住訓練集中每張圖片的細節,而無法識別新的圖像。 此時常用技術包括:
- Dropout(隨機失活)
- Batch Normalization
- Early Stopping
- 數據增強(Data Augmentation)
這些策略的共同點是降低模型對特定樣本的依賴,提升泛化能力。
6. 過擬合的防範與控制策略
6.1 正則化
如前述,

6.2 數據增強
通過旋轉、平移、翻轉、加噪等方式擴展樣本,有助於模型學習數據的不變性,從而減少對訓練樣本的過度信息存儲。
6.3 Dropout機制
隨機地將神經元輸出置零,促使網絡在多種子網絡結構間學習共享權重。數學上,Dropout等價於模型集合平均(Model Averaging),可顯著抑制過擬合。
6.4 提前中斷(Early Stopping)
在訓練過程中監測驗證集損失,一旦其開始上升,則中斷訓練。這樣可有效防止模型過度擬合訓練樣本的細節。
6.5 交叉驗證與模型集成
使用K折交叉驗證提高估計穩定性。採用集成學習(如Bagging、Boosting、Stacking)可在多個模型平均結果下減少方差。
6.6 降維與特徵選擇
通過主成分分析(PCA)、線性判別分析(LDA)等方法減少特徵冗餘,使模型僅保留主要信息結構,防止高維空間的誤差放大。
7. 結語
過擬合是機器學習中不可迴避的基本問題。它揭示了模型複雜度、數據特性、算法設計與泛化性能之間的微妙平衡。從數學的角度看,過擬合是風險最小化過程中的結構性偏差;從工程的角度看,它是模型在有限樣本上的性能陷阱;從認知角度看,它反映了學習系統面對不確定性時的適應極限。 理解過擬合,不僅是掌握技術的基礎,更是理解「學習」本質的途徑。