
一:客户信息
海南某三甲醫院
二:案例背景
什麼是分佈式文件系統
分佈式文件系統(DistributedFile System,DFS)是一種能夠在多台計算機之間共享文件存儲資源的系統。它將文件存儲在多個節點上,這些節點通常是位於不同地理位置的服務器或計算機集羣。分佈式文件系統的核心目標是提高文件存儲的可靠性、可擴展性和性能,同時為用户提供透明的文件訪問體驗,彷彿文件是存儲在單一的本地文件系統中一樣。
Ceph的三種存儲結構
對象存儲:Ceph 提供 S3 和 Swift 兼容的RESTful API,用於存儲和檢索對象數據。
塊存儲:Ceph 提供塊設備接口,支持虛擬機的塊存儲,如 KVM、OpenStack 等虛擬化平台。
文件系統:Ceph 提供一個 POSIX 兼容的文件系統(CephFS),支持傳統的文件存儲需求。
三:案例描述
近期我司遇到一個華三的分佈式雲平台,有三台物理機,每台物理機使用24塊12TB的物理盤+3塊1TB的閃存+2塊480G的SSD系統盤,總容量為七百多TB,客户誤操作刪除了100TB的數據文件,雲平台才用的是文件存儲模式,通過NFS協議掛載傳入數據。。
四:解決方案
**1.**應急響應
客户聯繫我們以後,我方技術團隊面對這一緊急情況,立即讓客户的運維團隊啓動應急預案,採取了以下措施:
1.緊急停機:首先,為避免進一步的數據損壞,立即停止了所有可能影響到Ceph集羣的操作,包括數據寫入和讀取。
2.環境評估:對當前的Ceph分佈式集羣狀態進行全面評估,確認受影響的範圍及程度,包括哪些配置文件丟失,是否已造成數據損壞等。
**2.**恢復挑戰
在服務器沒有備份容災的情況下進行數據恢復是**挑戰性的,主要挑戰包括:
無備份可用:傳統的恢復方式依賴於已有的備份,而在沒有備份的情況下,需要通過日誌文件、元數據和其他剩餘數據來重建丟失的配置。
系統複雜性:雲平台與Ceph分佈式存儲的配置複雜,恢復過程中稍有不慎就可能造成數據的**性丟失。
時間緊迫:在實際業務環境中,服務的中斷會帶來巨大的損失,因此需要快速而準確地進行恢復。
**3.**案例評估
客户已經找過多家數據恢復公司進行恢復操作,雖未能成功恢復數據文件,但已經把三台物理機的87塊硬盤全部鏡像為虛擬磁盤的鏡像文件。因為華三大多數都是使用的ceph來管理,我司對各個版本的ceph都有過底層解析,經過溝通客户選擇相信我們,跳過現勘階段,直接將裝有鏡像文件的硬盤送至我司進行數據提取。
**4.**恢復方案
1、初步解析
在工作站上使用winhex查看物理盤和閃存盤,發現底層為ceph分佈式存儲,其下層是基於bluestore的分佈式結構,“上層”使用leveldb算法,“中間層”使用rocksdb運作。全局採用持久化的模式,算是一種標準化的新版ceph分佈式存儲系統。
Bluestore:
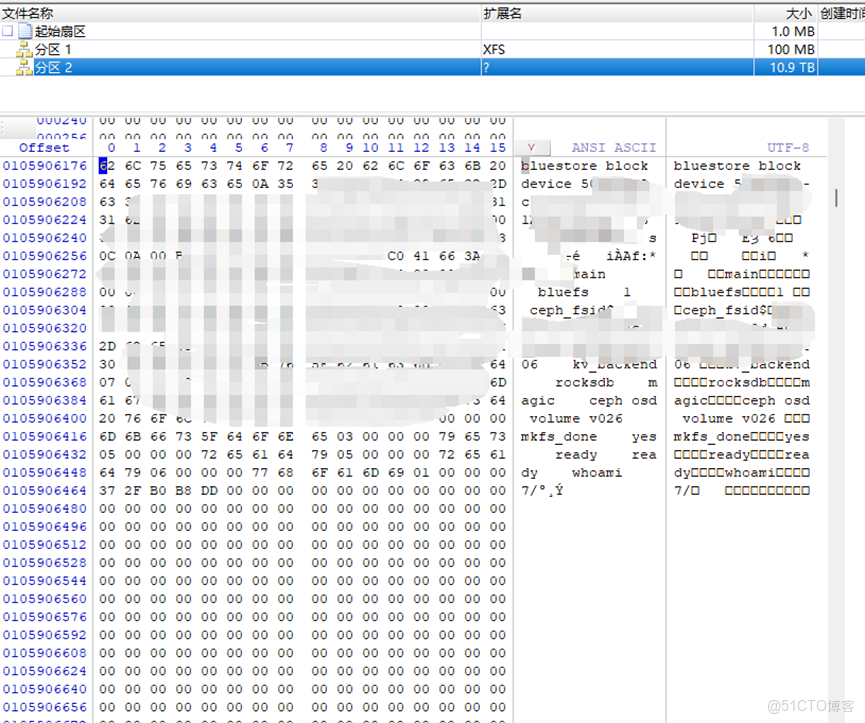
Leveldb:
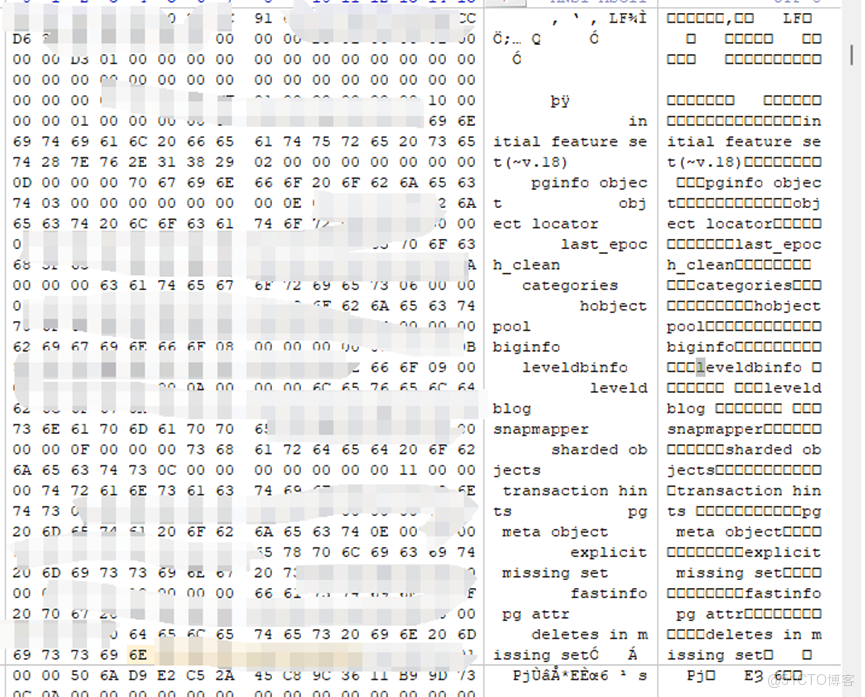
告知客户2天內可讓客户看見我司隨機提取的數據文件。
2.恢復前的準備工作
1、從閃存盤獲取leveldb數據庫文件。
Leveldb-sst:
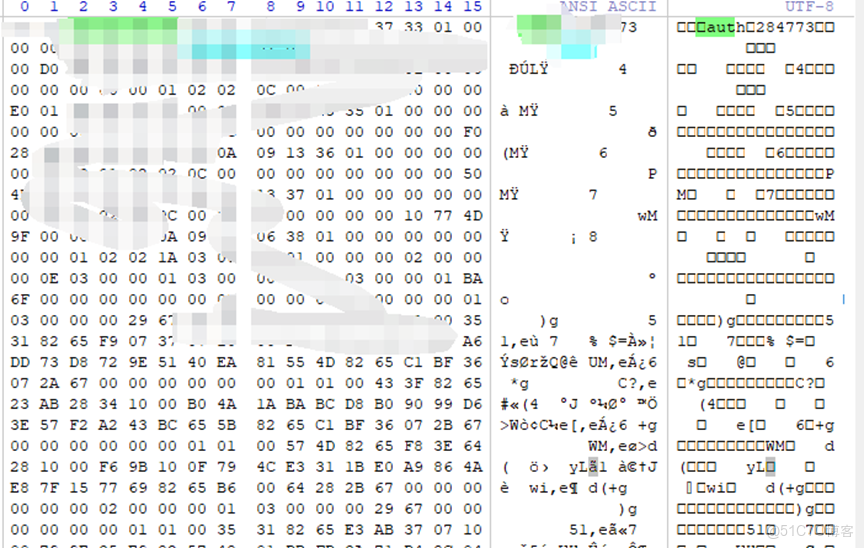
2、解析rocksdb的運作模式,可以理解為“16進制結構的表信息”。
Rocksdb:
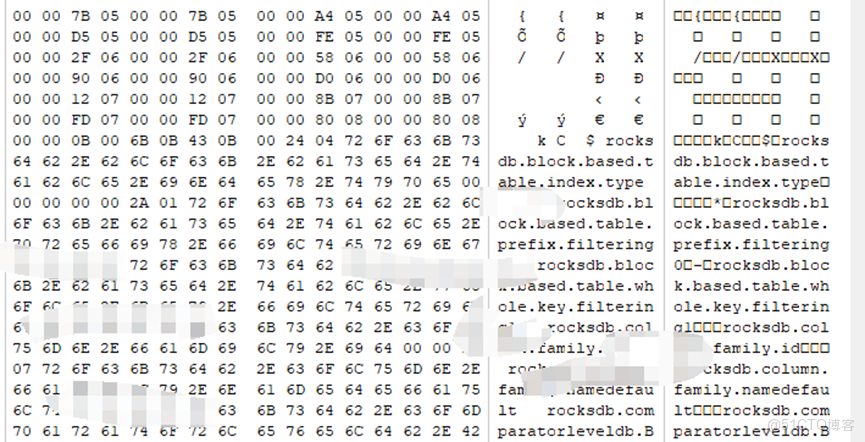
3、獲取所有物理盤的osd位圖信息。
Osdmap:
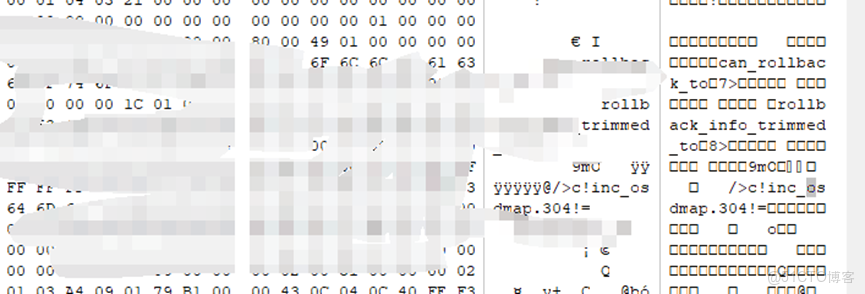
3、獲取必要信息
1、解析leveldb的表結構,依照特定的算法全盤獲取持久化之前的meta_data(元數據)。
2、解析當前rocksdb的運作模式,通過meta_data中記錄的信息與之關聯。
3、將所有物理盤上的osd信息按照特定的結構全部獲取,獲取每段osd信息上的“ID”信息。
4、獲取閃存盤上記錄的文件head信息。
5、獲取bluestore給每個對象分配的ID信息(包含文件名信息)。
4、分佈式空間碎片組合
將獲取的各種元數據信息導入到SQL數據庫內
1、將rocksdb與meta_data進行關聯,獲取每塊的空間信息
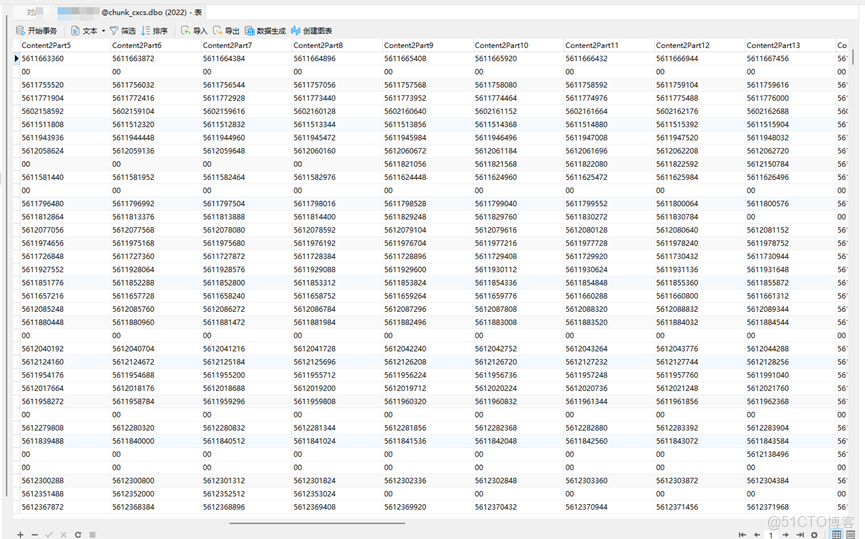
2、將head信息與空間信息進行關聯,使得可以通過head去訪問文件的在空間內的存儲地址。
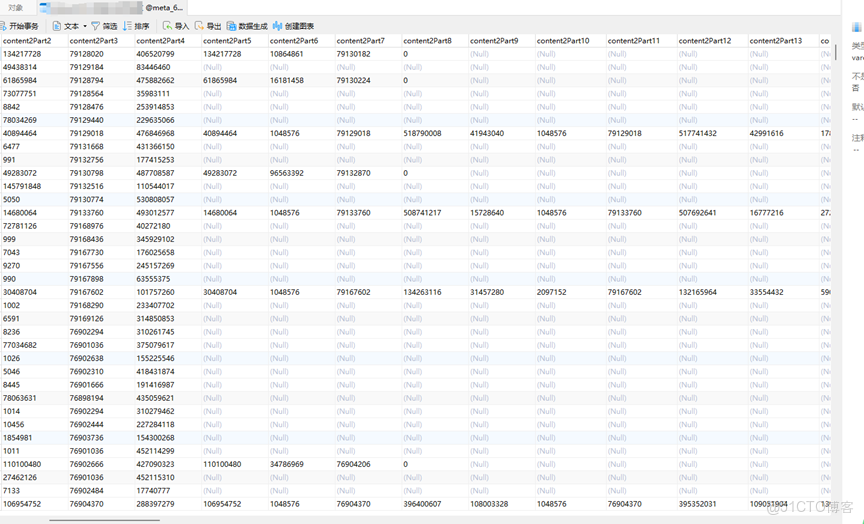
3、將從bluestore獲取的對象ID信息與head關聯。
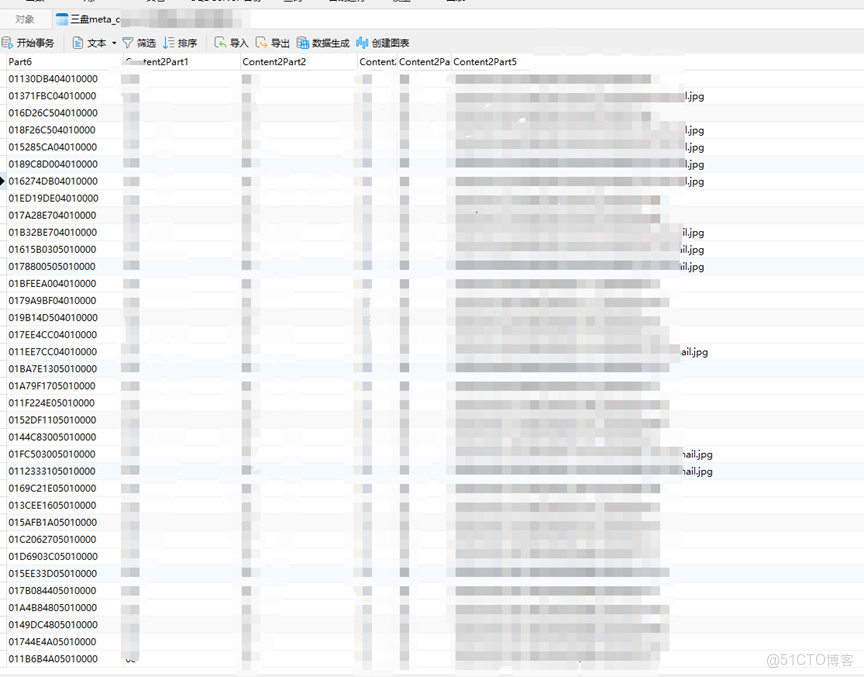
4、將自建的SQL數據庫與每塊硬盤(osd)關聯
5、通過ID→head→空間信息→獲取分配的地址信息
5、開始數據文件的恢復提取
五:案例總結
經過緊張而有序的工作,我方技術團隊終於成功恢復了Ceph分佈式存儲服務器集羣的配置文件,並確保了整個系統環境的穩定運行。此次事件雖然驚心動魄,但也帶來了寶貴的經驗教訓:
1. 加強備份管理:務必建立健全的備份機制,定期備份Ceph集羣關鍵配置文件和數據,確保備份的完整性和可用性,以防不測。
2. 提高安全意識:合理設置管理員權限,加強運維人員的安全教育和培訓,提升自身的運維能力和數據保護水平,降低人為錯誤的發生概率。
3. 完善應急預案:制定規範的操作流程,不斷完善和優化應急預案,確保在緊急情況下能夠迅速、有效地響應。
4. 加強監控與日誌分析:開啓日誌審計功能,記錄管理員的所有操作,便於追溯和排查問題,充分利用監控系統和日誌分析工具,及時發現並處理潛在問題。
Ceph是當前非常流行的開源分佈式存儲系統,具有高擴展性、高性能、高可靠性等優點,同時提供塊存儲服務(rbd)、對象存儲服務(rgw)以及文件系統存儲服務(cephfs)。目前也是OpenStack的主流後端存儲,和OpenStack親如兄弟,為OpenStack提供統一共享存儲服務。使用Ceph作為OpenStack後端存儲,具有如下優點:
所有的計算節點共享存儲,遷移時不需要拷貝根磁盤,即使計算節點掛了,也能立即在另一個計算節點啓動虛擬機(evacuate)。
利用COW(Copy On Write)特性,創建虛擬機時,只需要基於鏡像clone即可,不需要下載整個鏡像,而clone操作基本是0開銷,從而實現了秒級創建虛擬機。
Ceph RBD支持thin provisioning,即按需分配空間,有點類似Linux文件系統的sparse稀疏文件。創建一個20GB的虛擬硬盤時,最開始並不佔用物理存儲空間,只有當寫入數據時,才按需分配存儲空間。