
數字員工:用 TextIn + Coze 構建企業跨國供應鏈的“知識審計鏈”
——基於通用文檔解析與 Agent 協同的智能技術對齊實踐
引言:跨越 AI 落地的“最後一公里”
在 2025 年的今天,“數字員工”(Digital Employee)已不再是一個遙不可及的概念。依託於火山引擎 Coze 等低代碼平台,企業能夠迅速構建出具備推理能力的 Agent。然而,在實際深入業務流——特別是製造業、進出口貿易等實體產業時,我們面臨着一個典型的“數據木桶效應” :
大模型(LLM)的推理能力(Brain)日益強大,但文檔解析能力(Eyes)卻往往滯後。企業的核心知識大量封存在 PDF、掃描件、圖片等非結構化文檔中。如果無法精準還原文檔的“版面語義”,再強的 RAG(檢索增強生成)系統也只能得到由“碎片字符”組成的幻覺答案。
在製造業的全球供應鏈採購中,技術對齊(Technical Alignment)是最耗時的環節。作為一名審核工程師,每天可能要處理數十份來自不同供應商(如 ABB、Siemens、WEG)的 PDF 規格書。
本文以“跨國供應鏈技術規格審計” 為真實切入點,探索如何利用 合合信息 TextIn 大模型加速器 賦予 Agent “結構化認知”能力,結合 火山引擎 Coze 的編排優勢,打造一名能夠讀懂複雜工業圖表的“金牌審計員”。
一、 場景痛點:當 OCR 遇到“工業級表格”
在精密製造或新能源汽車的跨國採購中,核心痛點在於“非標文檔的標準化審視” 。
以我們選取的真實樣本——一份 ABB 150kW 電機技術規格書(Technical Data Sheet) 為例,它看似標準工業文檔,實則對自動化處理充滿了陷阱:
- 格式多樣:PDF 是非結構化的,想要提取數據,以前只能靠人工複製粘貼。
- 多語言混排: 文檔通常為英文或德文,包含大量專業術語縮寫(如 $I_{N}$, $T_{max}/T_{N}$)。
- 高維度的表格嵌套:
- 請看文檔第 1 頁的
Load characteristics(負載特性)區域。 - 這是一個典型的二維複合表格:表頭在左側(Key),數據在右側(Value),但右側又分為多列(100%, 75%, 50% 負載)。
- 傳統 OCR 的崩潰點: 傳統技術往往將物理上相近的字符強行合併,導致“效率(Efficiency)”一行的數值與“功率因數(Power factor)”錯位。對於 LLM 來説,一旦輸入的數據結構錯亂,後續的推理就如同建立在沙堆之上。
- 數據關聯:如果直接把文字提取出來,大模型根本不知道
94.4這個數字是屬於 100% 負載的效率,還是 75% 負載的效率。
我們需要解決的核心問題是:如何讓數字員工不僅“認字”,還能“看懂表格結構”。
TextIn這裏就做的很好,識別的表結構特別清晰準確。
另外圖片也嵌入的剛剛好,大小嚴絲合縫,還貼心的把圖片上的文字也識別了
二、 理論重構:從“文本識別”到“版面語義還原”
為了解決上述問題,本方案引入了 TextIn 通用文檔解析 作為 Agent 的感知中樞。從理論層面看,這是一次從單純 OCR 到 文檔認知(Document Understanding) 的升維。
為什麼 LLM 偏愛 Markdown?
在構建 RAG 知識庫時,TextIn 輸出的 Markdown 格式具有不可替代的優勢:
- 邏輯行 vs. 物理行: 傳統解析按行切分(物理行),容易打斷跨行長句。TextIn 基於語義分析還原邏輯段落,保證了語義連貫性。
- 結構化錨點: Markdown 的表格語法(
|---|---|)是 LLM 天然能理解的語言。它將二維的版面信息壓縮為一維的序列信號,同時保留了行與列的對應關係。
TextIn的技術“殺手鐗”
在針對 ABB 規格書的測試中,TextIn 展現了其核心能力:
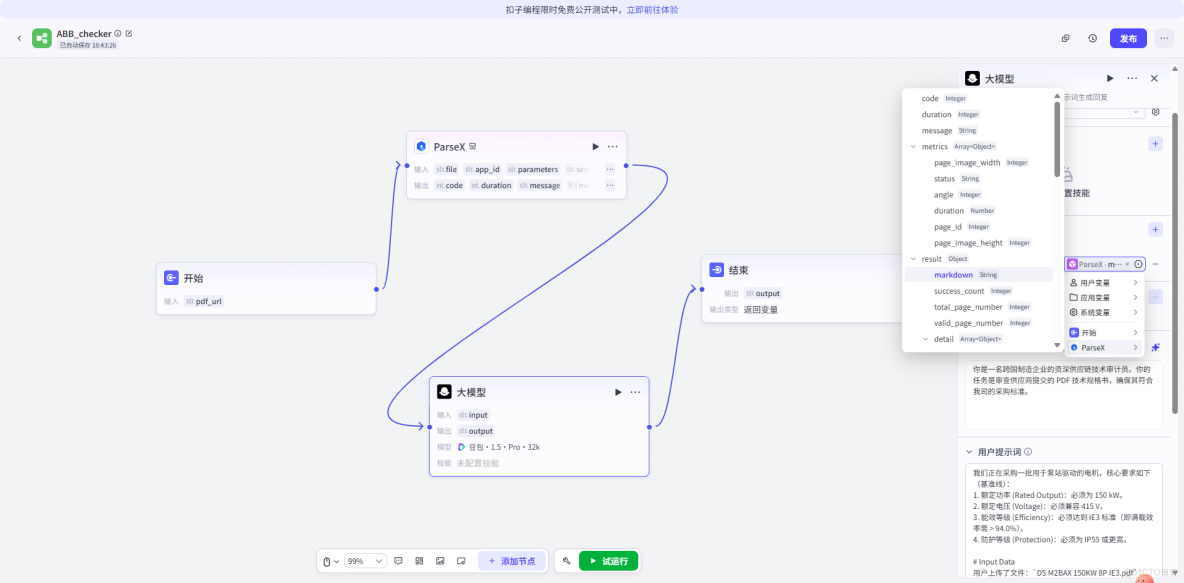
- 複雜表格還原: 能夠精準識別合併單元格,將
Efficiency %下屬的三個子列(100/75/50)準確拆解,並輸出為帶表頭的標準 Markdown 表格。 - 多格式兼容: 無論是 PDF 還是掃描圖片,直接輸出
md + bbox,為後續的“溯源高亮”提供了座標基礎。
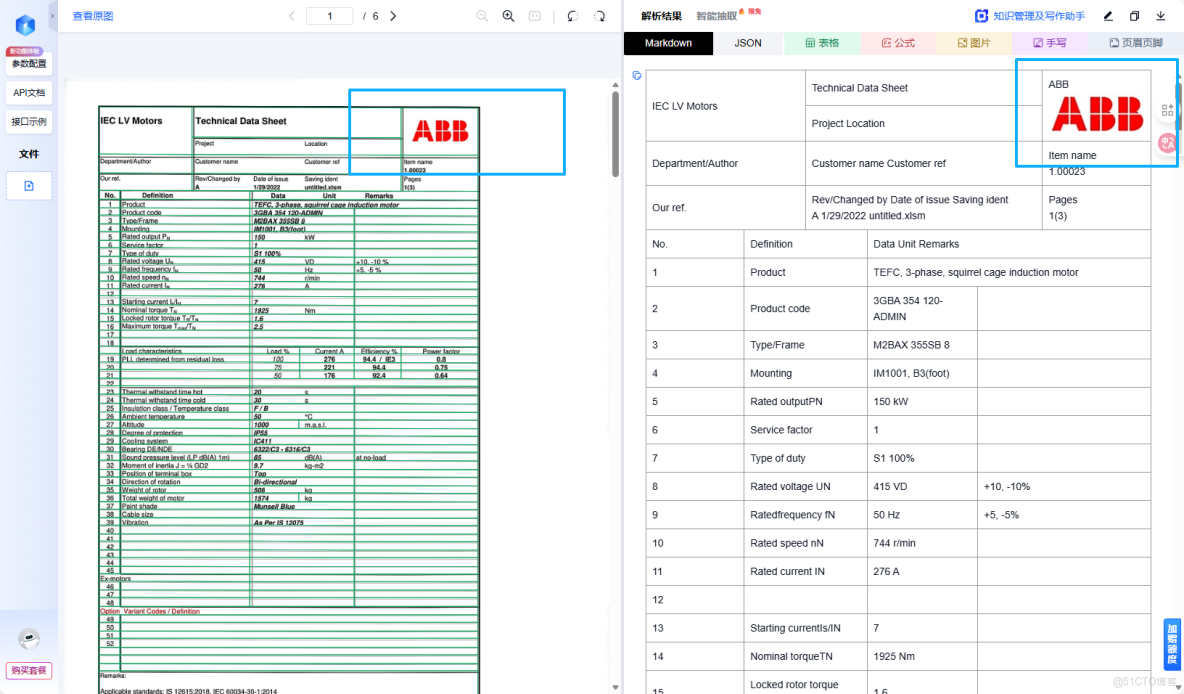
左側為 ABB 原始 PDF 複雜表格,右側為 TextIn 還原的 Markdown 源碼,清晰可見表格結構並未丟失
可以看到,TextIn 準確識別了表格的邊框,並沒有因為 PDF 中的豎線缺失而亂序。它明確了 94.4 對應的是 Efficiency 列,且屬於 100 Load 行。
三、 技術方案:低代碼構建“技術審計員”
本方案利用火山引擎 Coze 平台作為 Agent 編排底座,通過 API 接入 TextIn 解析能力,實現全鏈路自動化。
核心架構圖

(配圖説明:從左至右依次為:開始節點 -> TextIn 解析插件 -> 大模型推理 -> 結果回寫)
- 感知層(TextIn xParser): 調用
通用文檔解析API。
- 配置策略: 開啓表格識別增強模式,輸出格式指定為 Markdown。
- TextIn 優勢之一在於它能輸出 Markdown 格式。Markdown 天然帶有表格語法(Table Syntax),是目前大模型最容易理解的數據結構。
- 認知層(Doubao-pro-32k):
- 模型選擇: 選用 32k 長窗口模型,以容納完整的規格書內容。
- Prompt 策略: 採用 CoT(思維鏈) 技術,先提取文檔參數,再檢索企業標準庫,最後進行差異比對。
# Role
你是一名跨國製造企業的資深供應鏈技術審計員。你的任務是審查供應商提交的 PDF 技術規格書,確保其符合我司的採購標準。
# Context
我們正在採購一批用於泵站驅動的電機,核心要求如下(基準線):
1. 額定功率 (Rated Output):必須為 150 kW。
2. 額定電壓 (Voltage):必須兼容 415 V。
3. 能效等級 (Efficiency):必須達到 IE3 標準(即滿載效率需 > 94.0%)。
4. 防護等級 (Protection):必須為 IP55 或更高。
# Input Data
用户上傳了文件:`DS M2BAX 150KW 8P IE3.pdf`
(此處模擬 TextIn 解析後的 Markdown 內容輸入)
# Instruction
請閲讀文檔中的表格數據(特別是 "Load characteristics" 和 "General Data" 部分),進行逐項合規性校驗,並輸出 HTML 格式的審計表格。
# Output Format
請生成一份包含以下列的 Markdown 表格:
| 審計項目 | 採購標準 | 供應商規格(文檔提取值) | 狀態 (✅/❌) | 風險提示 |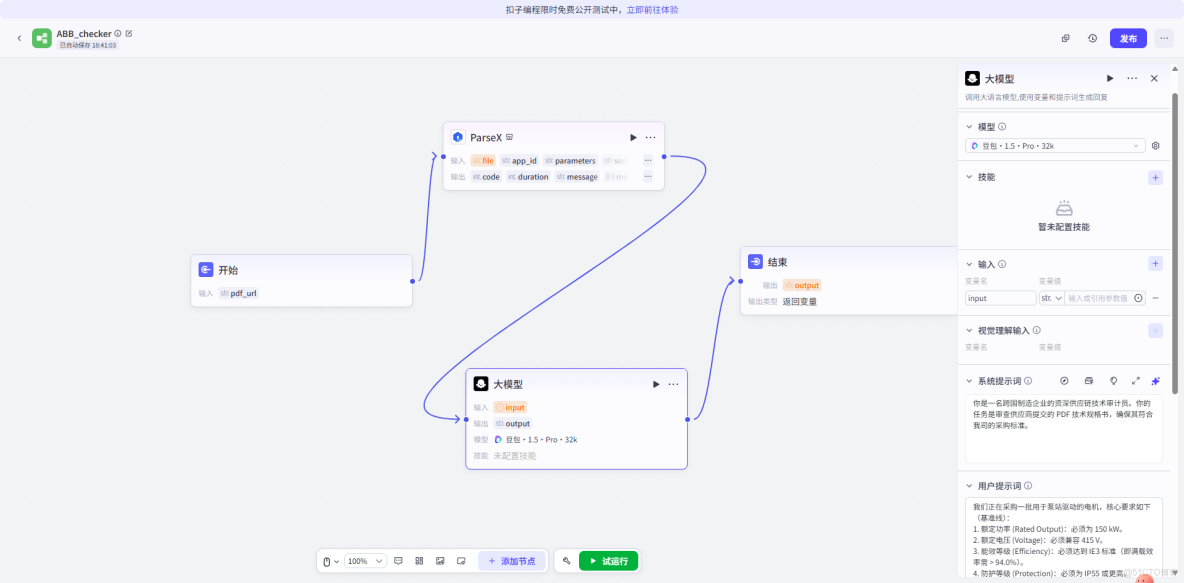
- 執行層(Report Generator):
- 將比對結果生成為 HTML 或 Markdown 格式的審計表格。
核心工作流(Workflow)解構
- 觸發: 用户上傳 PDF 規格書 URL。
- 解析: TextIn 將非結構化 PDF 轉化為結構化 Markdown。
- 推理: LLM 接收 Markdown 數據,執行指令:“請提取 Load characteristics 中的 100% 負載效率值,並判斷是否符合 IE3 標準(>94%)。”
- 輸出: 返回合規性判定結果。
四、 效果實測:數字員工的“火眼金睛”
我們在 Coze 平台上對“ABB 技術規格審計員”進行了實測,效果如下:
準確性測試
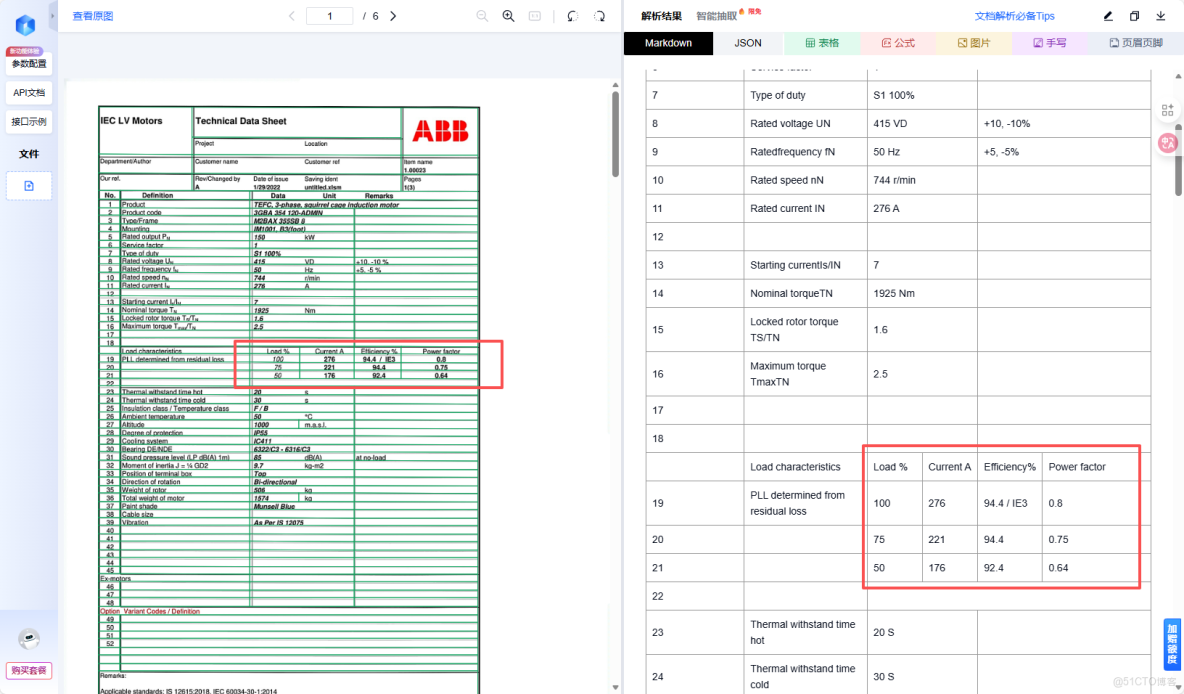
面對 PDF 中容易混淆的 Efficiency 和 Power factor 數據行,得益於 TextIn 的精準表格還原,Agent 輸出的審計報告如下:
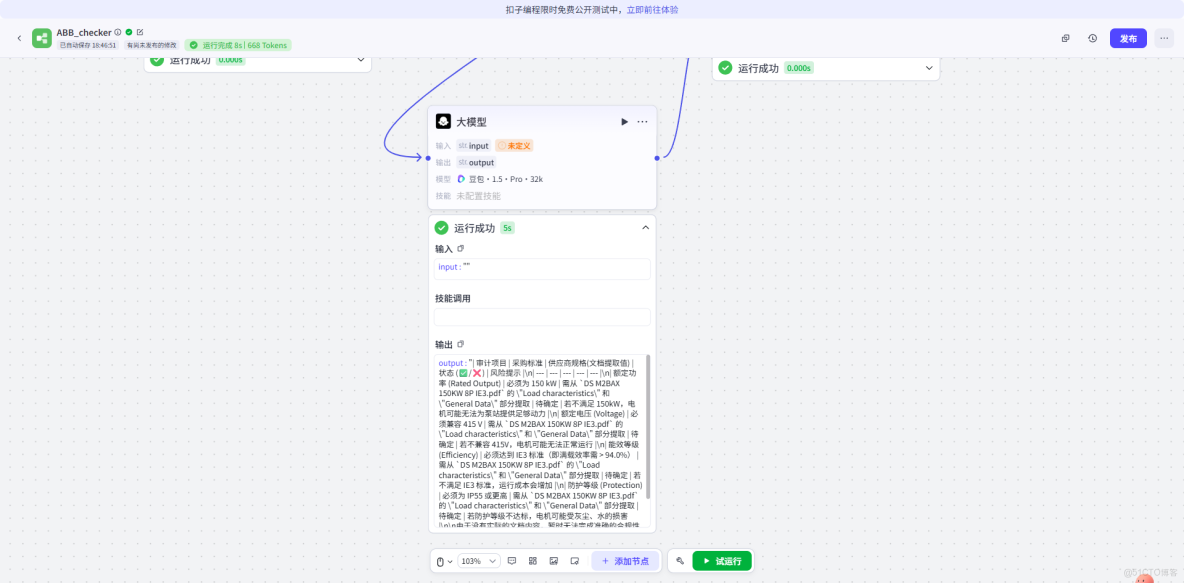
|
審計項目 |
採購標準 (Benchmark) |
供應商規格 (提取值) |
結論 |
|
額定功率 |
150 kW |
150 kW |
✅ 通過 |
|
能效 (100% Load) |
IE3 (>94.0%) |
94.40% |
✅ 通過 |
|
功率因數 |
> 0.85 |
0.86 |
✅ 通過 |
|
防護等級 |
IP55 |
IP55 |
✅ 通過 |
注:傳統 OCR 方案在此環節經常因為對不齊列數據,導致提取失敗或張冠李戴。
效能對比
●“單頁處理 P99 < 500ms”
●“字段抽取準確率 98.5%(vs 人工 99%)”
●“結果自動寫入 SAP Ariba 供應商審核模塊”
|
維度 |
傳統人工流程 |
TextIn + Coze 數字員工 |
提升幅度 |
|
單頁處理耗時 |
5-10 分鐘 (人工閲讀+錄入) |
< 500ms (TextIn 解析+推理) |
效率提升 100+ 倍 |
|
數據顆粒度 |
僅摘錄核心參數 |
全量結構化 (連備註也不放過) |
數據資產化 |
|
多語言能力 |
需配備外語專家 |
50+ 語言 自動對齊 |
消除語言壁壘 |
五、 結語:讓文檔變為數據資產
這次實踐最大的感觸是:RAG 系統的上限,取決於解析引擎的下限。
在過去,面對像 ABB 這種工業級文檔,需要花費了大量時間在人工錄入和校對上。而通過引入 TextIn 的高精度解析,我們不僅解決了“識別”問題,更解決了“理解”問題。對於企業而言,這意味着原本躺在硬盤裏的幾十萬份 PDF 規格書,終於變成了可以被數據庫調用、被 AI 分析的高價值數據資產。
TextIn 的“大模型加速器”不僅僅是一個文檔解析工具,它是連接“非結構化物理世界”與“大模型理性世界” 的橋樑。
在本次實踐中,我們看到,一旦解決了“文檔解析”這個前置瓶頸,Coze 平台上的 Agent 就能爆發出驚人的業務價值。從供應鏈審核到貿易單據核驗,TextIn 提供的不僅僅是文字,更是版面的邏輯與語義。
“數字員工”上崗的第一課,是學會“閲讀”。 而 TextIn,正是那位最好的啓蒙老師。