

01 前言
隨着自動駕駛技術的日益升級,以UniAD、FSD V12為代表的“端到端”架構正重構行業格局。這一架構試圖通過單一神經網絡直接建立從傳感器輸入到車輛控制的映射,從而突破傳統模塊化累積誤差的侷限。
然而端到端模型對數據分佈的廣度與深度均有着高要求,尤其是對缺乏歸納偏置的Transformer架構而言,“數據規模”與“場景覆蓋度”可謂直接決定了模型上限。
現實路測數據面臨極端的長尾工況數據侷限,如實車採集“採不到、標不準、測不起、太危險”。在此背景下,“虛擬數據集”成為了大家關注的熱點,通過構建涵蓋極端天氣、複雜交互及事故場景的高保真虛擬數據,我們不僅能夠以低成本、高效率的方式生成海量帶標籤的樣本,更能為端到端模型提供閉環訓練環境。虛擬數據集已不再是現實數據的簡單補充,而是訓練高階端到端模型不可或缺的一環。
為滿足自動駕駛算法對高質量數據資產的迫切需求,並有效應對真實路測的侷限,本文將全面闡述高保真虛擬數據集SimData的構建方法。我們將深入解析aiSim2nuScenes工具鏈如何實現從物理級虛擬數據生成、標準化格式轉換,直至最終數據集評測與驗證的全流程閉環。

圖1:虛擬數據集SimData樣本示例
02 SimData數據集概述
面對自動駕駛算法對高質量數據的需求,傳統真實路測正面臨着巨大壓力,一是資金密集型的車隊運營與指數級增長的維護成本,導致其缺乏規模效應,難以支撐感知模型的數據吞吐;二是人工3D標註在惡劣天氣與遠距視角下的主觀偏差及真值缺失,直接限制模型精度的上限;三是海量低價值的數據稀釋訓練價值,導致“長尾”場景捕獲效率極低;最後法律與倫理的紅線,更致使缺少關鍵的“事故臨界態”數據。
在此背景下,虛擬仿真憑藉數字化優勢成為直面以上壓力的關鍵角色。它不僅能通過邊際成本遞減打破資金壁壘,還能利用自動化真值生成徹底消除了人工噪聲,實現了像素級精確標註。此外虛擬仿真更能夠實現全要素可控,進而可自由重構複雜交通流與極端工況。
對此,基於aiSim高保真仿真器,本文給大家介紹SimData虛擬數據集,以便能夠針對感知算法痛點進行攻關。以下是該數據集的簡要介紹與獲取方式:(更多介紹可閲讀SimData深度解析:高保真虛擬數據集的構建與評測)
①規模與密度: 數據集包含15張高精度地圖和45個獨立場景,單傳感器數據量級突破18,000幀,總樣本量(Samples)達到215,472幀,目標實例(Instances)超過64,000個;
②場景多樣性: 覆蓋高速公路(Highway)、城市峽谷(Urban)和立體停車場(Parking)三大核心ODD。特別是針對真實路測中難以捕捉的施工區域、高速匝道匯入、無保護路口以及光照劇烈變化的室內車庫進行了重點建模;
③類別均衡性:針對真實數據集中“類別不平衡”的問題,SimData在保證Car、Pedestrian等基礎類別密度的同時,增加了Trailer(拖車)、Barricade(路障)、Traffic Cone(交通錐)、Van(麪包車)等稀缺類別的樣本比例。這種人為干預的數據分佈優化,直接提升了模型對異形障礙物的檢出能力。

圖2:Highway(左)、Urban(中)、Parking(右)
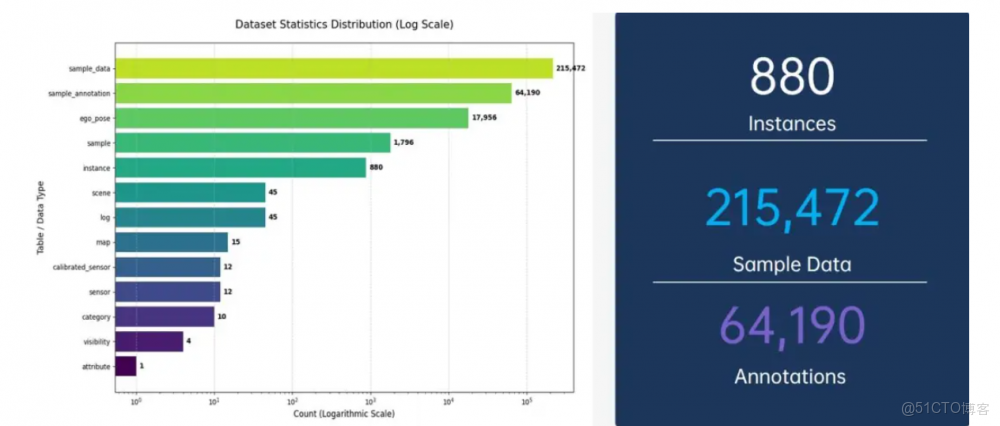
圖3:數據集數據的分佈統計,數據集包含了880個實例(Instances),215,472個關鍵幀數據(Sample Data)以及64,190個標註信息(Annotations)
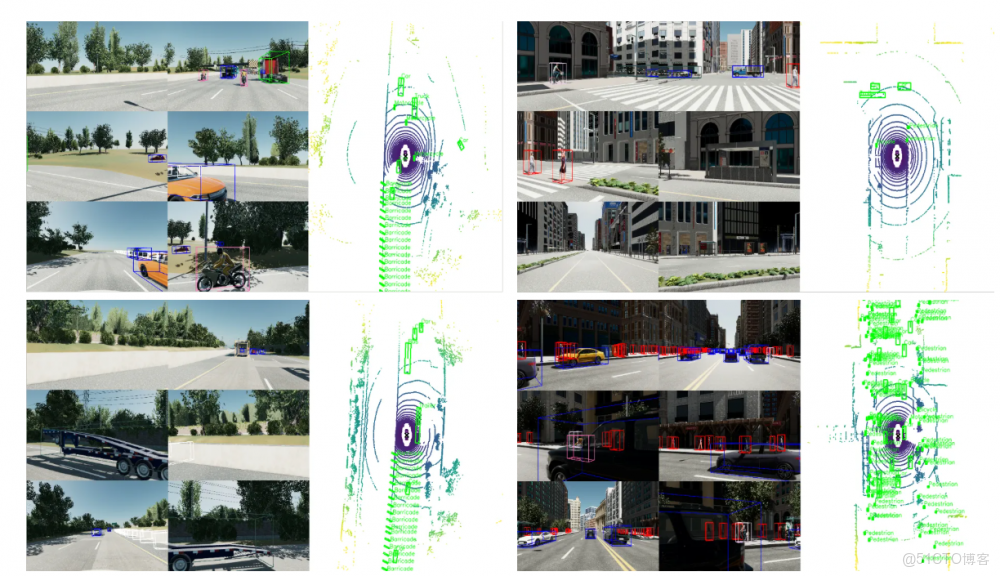
圖4:simData標註真值在6環視相機以及bev視角下的可視化
目前,虛擬合成數據集SimData-V1已正式開源,可以通過以下鏈接直接獲取:
完整版:https://huggingface.co/datasets/Keymotek/simData-Dataset
mini版:https://huggingface.co/datasets/Keymotek/simData_mini-Dataset
03 自動化工具鏈:aiSim2nuScenes
在自動駕駛從研發邁向落地的關鍵階段,如何高效、標準化地將虛擬仿真環境轉化為算法可直接攝取的高價值數據資產,已成為決定工程化成敗的核心挑戰。對此,本文介紹的 aiSim2nuScenes 工具鏈,其並非單純的數據轉換接口,而是一套構建了從虛擬世界到算法應用標準橋樑的端到端合成數據生產與閉環評測體系。
該工具鏈以流水線作業的形式,無縫串聯起高保真數據合成、標準化格式遷移以及自動化閉環測評三大關鍵環節。它不僅能基於物理引擎批量生成包含多模態傳感器信息的原始數據,並能將其自動化映射為通用的 nuScenes 標準格式,徹底消除仿真平台與主流訓練框架間的“隔閡”。
無縫集成的生態兼容性
為了降低工程團隊的遷移成本,aiSim2nuScenes實現了對行業標準nuScenes-devkit的原生級支持。該工具鏈提供腳本(Script)批處理與圖形化界面(GUI)雙模式,能夠自動解析aiSim導出的原始數據,並將其重構為nuScenes標準文件結構:
①視覺數據: 自動完成從無損TGA格式到JPG的轉換,並智能抽幀(默認每10幀提取關鍵幀),非關鍵幀自動歸檔至sweeps,保留了時序信息的完整性;
②點雲數據: 實現LiDAR數據從LAS到BIN、Radar數據從JSON到PCD的格式清洗與轉換;
③元數據自動化: 自動生成category.json(類別定義)、ego_pose.json(自車位姿)、calibrated_sensor.json(傳感器外參)及sample_annotation.json(真值標註),徹底消除了人工標註引入的認知偏差與隨機誤差,實現了“生成即真值”。
微秒級多傳感器時空同步
多模態融合算法對時間同步的敏感度極高。SimData數據集配置了經典的L2+傳感器佈局:6路環視相機(360° FOV)+ 1個頂置高線束LiDAR + 5個周視毫米波Radar。aiSim2nuScenes在數據生成階段,通過確定性的仿真時鐘,保證了所有傳感器數據在同一時間戳下的嚴格對齊,同步精度達到微秒級,完美滿足BEV算法對時空一致性的嚴苛要求。
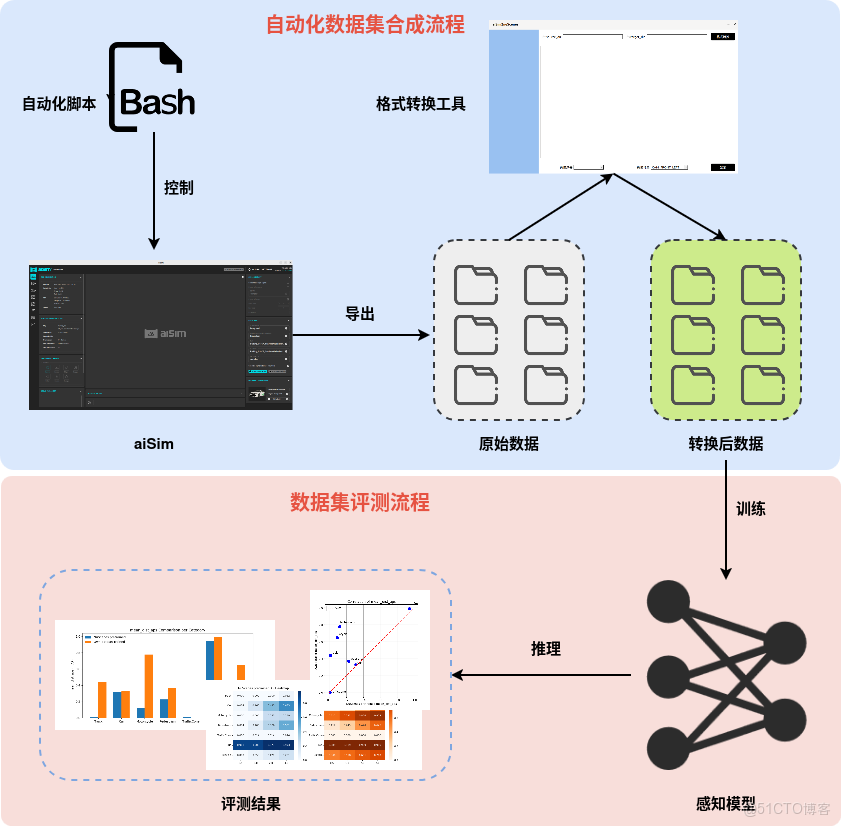
圖5:從aiSim場景配置、仿真運行,到數據導出、自動化格式轉換,再到最終感知模型訓練的完整閉環
04 算法實證:性能跨越與魯棒性驗證
“仿真數據能否訓練出在真實世界可用的模型?”這是所有算法工程師關注的問題。為此,本文基於BEVFormer-tiny,設計了嚴謹的定量評測實驗,用數據回答了關於收斂性、一致性與遷移能力的質疑。
良好的收斂性
在純虛擬數據集上進行的訓練實驗顯示,模型在30個Epoch內迅速收斂,最終mAP達到0.446,NDS(nuScenes Detection Score)達到0.428。特別是在Bus(AP 0.989)、Motorcycle(AP 0.778)等大尺寸目標上,檢測精度極高。這證明aiSim生成的數據在統計分佈和特徵維度上是良構的,能夠被深度神經網絡有效擬合。
虛實一致性
為了探究模型“學到了什麼”,本文對比了“SimData訓練模型”與“nuScenes官方預訓練模型”在SimData測試集上的表現。
①AP相關性分析:兩者在不同類別上的AP值呈現顯著正相關(Pearson係數接近1);
②Attention Heatmap分析:檢測熱力圖顯示,兩個模型在距離感知和空間關注點上高度重合。無論是近處車輛的紋理特徵,還是遠處行人的輪廓信息,虛擬數據訓練的模型展現出了與真實數據模型一致的注意力機制。這從可解釋性角度有力證明了aiSim數據的高保真度。
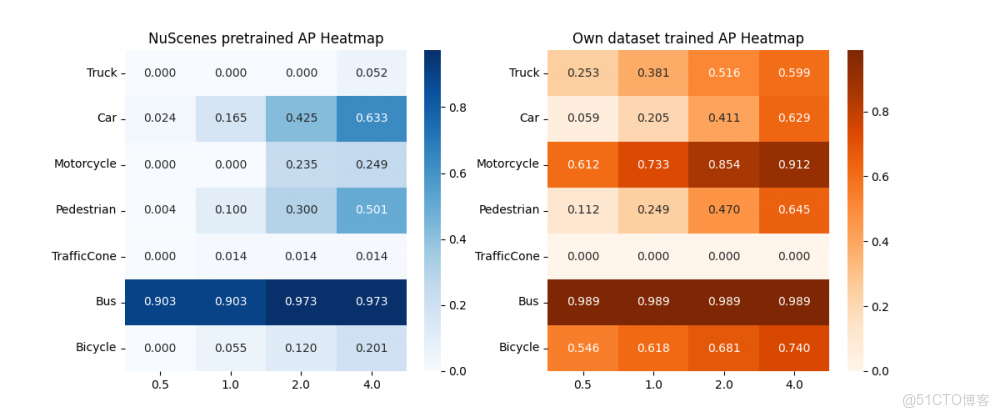
圖6:熱力圖顯示,SimData訓練的模型(右)與真實數據模型(左)在空間關注模式上高度一致,證明了兩者在特徵提取層面的同源性。
遷移學習
最具工程價值的發現來自於域適應實驗。本文實驗對比了三種策略:(1) 僅SimData訓練,(2) 僅nuScenes訓練,(3) nuScenes預訓練 + SimData微調(Pre-train + Fine-tune)。
結果顯示,“Pre-train + Fine-tune”策略在絕大多數類別上實現了性能的全面超越;比如在Pedestrian(行人)、Trailer(拖車)、Barricade(路障)等長尾類別上,微調後的模型檢測精度均有顯著提升。
因此可證明虛擬數據並非真實數據的簡單替代,而是其完美的互補。“真實先驗 + 仿真多樣性”的組合,能夠有效抑制過擬合,幫助模型學習到更具泛化能力的特徵表示,從而顯著提升模型在面對真實世界未見場景時的魯棒性。
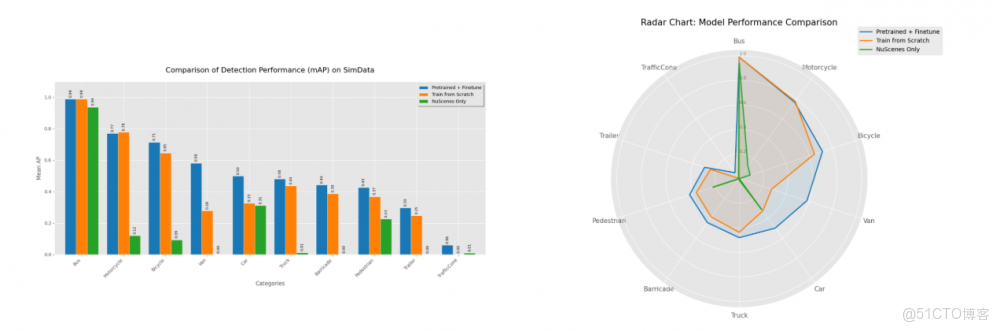
圖7:實驗數據顯示,“Pre-train + Fine-tune”方案在幾乎所有類別上包圍了對比方案,證明了高保真合成數據在提升模型泛化能力方面的巨大潛力
驗證結論
總結來看,以上實驗結果表明,aiSim生成的數據在統計分佈與特徵維度上具備高度的良構性,不僅支持深度神經網絡在純虛擬環境下的迅速收斂與高精度檢測,更在注意力機制展現了與真實世界模型高度一致的特徵同源性。這證明了高質量的仿真數據能夠讓算法“學會”與現實世界通用的感知邏輯。
在域適應實驗中,“真實先驗 + 仿真多樣性”的混合訓練策略展現了超越單一數據源的SOTA性能。虛擬數據並未止步於對真實數據的簡單替代,而是憑藉其對長尾場景(如路障、特殊車輛)的覆蓋能力,成為了真實數據的完美互補。這種組合有效抑制了過擬合,顯著增強了模型在面對未知場景時的泛化能力與魯棒性。
高質量虛擬數據集的核心在於對真實物理世界的準確建模能力。只有當仿真數據在成像機理與信號生成層面具備確定性和一致性,才能真正服務於自動駕駛算法訓練。
具體分析本文采用的aiSim仿真器,其基於自研渲染引擎,在底層架構上實現了對真實物理過程的系統化映射。此外採用融合式渲染架構,將光柵化的高效性、光線追蹤的物理精度以及神經渲染在細節表達上的優勢相結合,在複雜光照變化及雨、霧、雪等極端環境下,仍可保持像素級物理一致性,為感知模型提供高置信度輸入。
在此基礎上,aiSim又進一步實現了從像素級到信號級的確定性建模。無論是相機中的成像噪聲、景深與運動模糊,還是激光雷達與毫米波雷達中的光束髮散、多徑效應與材質反射特性,均基於物理機理進行建模,使生成數據在統計特性與分佈形態上高度接近真實傳感器輸出。
因此可以説,aiSim為大規模、高真實性虛擬數據集合成提供了可靠基礎,有效支撐感知算法在複雜場景下的快速迭代與驗證。
05 結語
總結來看,自動駕駛的下半場,本質上是數據規模與數據質量的角逐。在摩爾定律失效、Scaling Laws主導的今天,高保真仿真技術已成為打破數據瓶頸的最優解。
康謀通過aiSim仿真平台、aiSim2nuScenes自動化工具鏈以及SimData數據集的紮實落地,向行業展示了一條清晰的技術路徑:通過引入物理級高保真的虛擬數據,不僅能夠大幅降低數據採集與標註的邊際成本,規避極端工況測試的道德與安全風險,更能通過“虛實結合”的訓練策略,顯著提升感知模型在複雜現實世界中的表現。
隨着端到端大模型與世界模型的興起,對高質量合成數據的需求將呈指數級增長。可以看到,aiSim提供的高保真虛擬世界,正在成為連接算法代碼與物理現實的堅實橋樑,加速自動駕駛從“有限場景”邁向“全域通達”!