
一、前言
隨着模型在自然語言理解、文本生成等基礎任務上的性能持續突破,其在複雜問題解決場景中的推理能力不足逐漸成為技術落地的關鍵瓶頸。儘管主流模型在單一任務中展現出接近甚至超越人類的表現,但在需要多步驟邏輯推演、數學運算或因果關係分析的複雜任務中,往往因缺乏明確的推理路徑而產生錯誤結論或表面化回答。這種推理能力的侷限性,本質上反映了大模型在處理非線性、多約束問題時對中間推理過程建模的不足,也凸顯了傳統提示方法在引導模型進行深度思考方面的侷限性。
在此背景下,思維鏈提示作為一種新興的提示工程技術應運而生,其核心價值在於通過顯式引導模型生成逐步推理過程,將複雜問題分解為可執行的中間步驟,從而顯著提升大模型在推理任務中的準確性與可靠性。作為連接基礎模型能力與複雜任務需求的關鍵橋樑,思維鏈提示不僅拓展了大模型的應用邊界,更為提示工程領域提供了全新的方法論指導。

二、什麼是思維鏈提示
1. 基礎概念
思維鏈提示是一種引導大模型進行逐步推理的提示工程技術,其核心在於通過結構化提示引導模型生成逐步推理過程,而非直接輸出答案。這一技術通過模擬人類解決複雜問題時的邏輯分析路徑,使大模型能夠顯式化中間推理步驟,從而提升推理準確性與結果可解釋性。
2. 關鍵特徵
- 步驟可解釋性:思維鏈提示要求模型將推理過程分解為若干可解釋的中間步驟,每個步驟均包含明確的邏輯判斷或計算過程。這種顯式化的推理路徑不僅使最終答案可追溯,還為模型決策提供了可解釋的依據,有效緩解了傳統大模型"黑箱"推理的侷限性。
- 邏輯鏈條完整性:思維鏈提示通過構建連貫的邏輯鏈條,確保推理過程中各步驟之間存在嚴格的因果關聯或遞進關係。這種完整性體現在:從問題定義到子問題分解,再到每個子問題的求解,最終彙總為結論,形成閉環的推理體系。實驗表明,完整的邏輯鏈條能夠顯著降低模型推理過程中的"跳躍性錯誤",尤其在數學推理、邏輯演繹等複雜任務中表現突出。
- 問題分解能力:思維鏈提示具備將複雜問題自動分解為多級子問題的能力,通過遞歸式推理逐步簡化問題難度。例如,在解決多步驟數學問題時,模型會先將問題拆解為"已知條件提取→公式選擇→分步計算→結果驗證"等子任務,再依次求解。這種分解能力使模型能夠處理超出其直接計算能力的複雜任務。
3. 工作原理
思維鏈提示的工作原理植根於對人類認知過程的模擬與計算機制的結合,其核心在於通過結構化推理步驟實現複雜問題的求解。從認知科學視角看,這一機制與人類解決問題時採用的"手段-目的分析"高度相似——即通過將目標問題分解為一系列子目標,逐步縮小當前狀態與目標狀態的差距,最終達成問題解決。這種分步推理模式不僅符合人類認知資源有限性的基本特徵,也為大模型處理複雜任務提供了可解釋的路徑。
4. 與傳統提示對比
傳統提示方式通常直接詢問最終答案,如"15+28等於多少?"。而思維鏈提示則會設計為:"請逐步計算15+28:首先10+20=30,然後5+8=13,最後30+13=43。所以答案是43。"這種差異使得模型必須展示推理路徑而非直接跳轉到結果。
三、思維鏈提示的流程
1. 流程圖
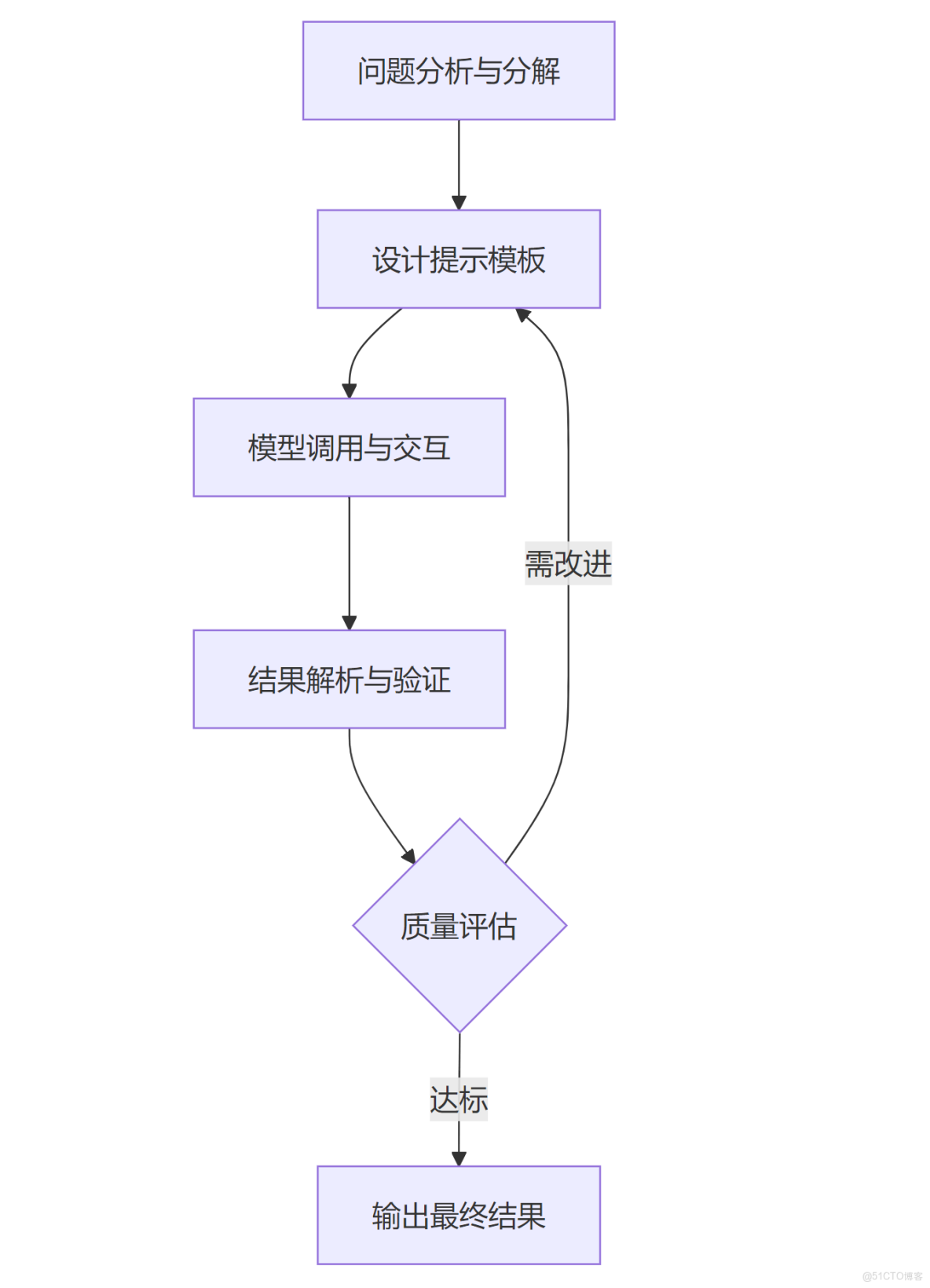
2. 步驟説明
- 問題分析與分解:深入理解任務本質,識別關鍵推理節點和依賴關係,明確問題類型及所需推理深度,判斷是否涉及多步驟邏輯(如數學運算、因果推斷、決策分析等),確定思維鏈的必要長度與複雜度。
- 提示模板設計:創建結構化的提示框架,明確步驟引導語言,構建包含問題描述、推理示例與引導語的結構化提示。示例需展示完整推理過程而非僅結論,引導語明確要求模型“逐步思考並解釋推理過程”。
- 模型交互優化:通過多次迭代調整提示策略,優化推理路徑,輸入設計好的提示至大模型,觸發其生成中間推理步驟。需確保模型輸出包含明確的邏輯銜接詞(如“首先”“其次”“因此”)與分步解釋。
- 結果驗證機制:建立檢查標準,確保推理邏輯的合理性和一致性,通過對比推理鏈與正確邏輯路徑,檢查中間步驟的連貫性、合理性及與最終結論的一致性,識別邏輯斷層或錯誤假設。
- 迭代優化:基於驗證結果調整提示結構,如增加示例多樣性、細化引導語或修正推理步驟模板,直至模型穩定生成高質量思維鏈。
四、思維鏈提示案例
1. 數學思維推理
調用Qwen大模型並要求大模型用思維鏈方式解決數學問題:“一個水池有進水管和出水管,進水管單獨注滿需要6小時,出水管單獨排空需要8小時。如果同時打開進水管和出水管,需要多少小時才能注滿水池?”,並展示完整的推理過程;
提示詞設計:
"""請用思維鏈方式解決以下數學問題,展示完整的推理過程:
問題:{problem}
請按以下格式回答:
1. 理解問題:[簡要説明問題要求]
2. 分解步驟:[將問題分解為多個求解步驟]
3. 逐步計算:[展示每一步的具體計算]
4. 最終答案:[給出最終結果]
推理過程:"""
import requests
import json
from typing import List, Dict
import os
class QwenChainOfThought:
def __init__(self, api_key: str, base_url: str = "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation"):
self.api_key = api_key
self.base_url = base_url
self.headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
def generate_response(self, prompt: str, max_tokens: int = 1000) -> str:
"""調用Qwen API生成響應"""
data = {
"model": "qwen-max",
"input": {
"messages": [
{
"role": "user",
"content": prompt
}
]
},
"parameters": {
"max_tokens": max_tokens,
"temperature": 0.1 # 低温度值保證推理穩定性
}
}
try:
response = requests.post(self.base_url, headers=self.headers, json=data)
result = response.json()
# print(result)
# return result['output']['choices'][0]['message']['content']
return result['output']['text']
except Exception as e:
return f"API調用錯誤: {str(e)}"
def math_problem_solver(self, problem: str) -> Dict:
"""數學問題思維鏈求解"""
prompt = f"""請用思維鏈方式解決以下數學問題,展示完整的推理過程:
問題:{problem}
請按以下格式回答:
1. 理解問題:[簡要説明問題要求]
2. 分解步驟:[將問題分解為多個求解步驟]
3. 逐步計算:[展示每一步的具體計算]
4. 最終答案:[給出最終結果]
推理過程:"""
reasoning_process = self.generate_response(prompt)
return {
"problem": problem,
"reasoning_process": reasoning_process,
"prompt_used": prompt
}
# 使用示例
def main():
# 初始化Qwen客户端
qwen_client = QwenChainOfThought(api_key=os.environ.get("DASHSCOPE_API_KEY"))
# 數學問題示例
math_result = qwen_client.math_problem_solver(
"一個水池有進水管和出水管,進水管單獨注滿需要6小時,出水管單獨排空需要8小時。如果同時打開進水管和出水管,需要多少小時才能注滿水池?"
)
print("數學問題求解結果:")
print(json.dumps(math_result, ensure_ascii=False, indent=2))
if __name__ == "__main__":
main()
模型返回的結果:

模型推理步驟:
問題:"一個水池有進水管和出水管,進水管單獨注滿需要6小時,出水管單獨排空需要8小時。如果同時打開進水管和出水管,需要多少小時才能注滿水池?
推理過程:
1. 理解問題:這個問題要求我們計算當一個水池的進水管和出水管同時開啓時,注滿整個水池所需的時間。已知條件是進水管單獨工作可以在6小時內將水池注滿,而出水管單獨工作則能在8小時內將滿池水排空。
2. 分解步驟:
- 第一步:確定進水管每小時可以填充水池的比例
- 第二步:確定出水管每小時可以排出水池的比例。
- 第三步:計算兩者同時作用下每小時實際增加的水量比例。
- 第四步:根據第三步的結果,計算完全注滿水池所需的總時間。
3. 逐步計算:
- 第一步:既然進水管可以在6小時內注滿水池,則它每小時可以填充(1/6)的水池容量。
- 第二步:同樣地,出水管在8小時內可以排空水池,意味着它每小時排出(1/8)的水池容量。
- 第三步:當兩管同時工作時,每小時淨增加的水量為進水管填充量減去出水管排空量,即((1/6) - (1/8))。將這兩個分數轉換成相同分母進行相減得到(frac{4-3}{24} = frac{1}{24}),這意味着每小時實際上只增加了水池容量的(1/24)。
- 第四步:既然每小時能增加(1/24)的水池容量,那麼要完全填滿這個水池就需要(24)個小時。
4. 最終答案:如果同時打開進水管和出水管,需要24小時才能注滿水池。
2. 邏輯推理求解
調用Qwen大模型並基於前提條件"所有哺乳動物都有脊椎,鯨魚是哺乳動物,魚類不是哺乳動物"進行邏輯推理"鯨魚有脊椎嗎",展示完整的思維鏈。
提示詞設計:
"""請基於以下前提進行邏輯推理,展示完整的思維鏈:
前提:{premise}
問題:{question}
推理步驟:
1. 分析前提條件:[提取關鍵信息]
2. 建立邏輯關係:[分析元素間的邏輯聯繫]
3. 逐步推導:[展示推理鏈條]
4. 得出結論:[回答原始問題]
請開始推理:"""
import requests
import json
from typing import List, Dict
import os
class QwenChainOfThought:
def __init__(self, api_key: str, base_url: str = "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation"):
self.api_key = api_key
self.base_url = base_url
self.headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
def generate_response(self, prompt: str, max_tokens: int = 1000) -> str:
"""調用Qwen API生成響應"""
data = {
"model": "qwen-max",
"input": {
"messages": [
{
"role": "user",
"content": prompt
}
]
},
"parameters": {
"max_tokens": max_tokens,
"temperature": 0.1 # 低温度值保證推理穩定性
}
}
try:
response = requests.post(self.base_url, headers=self.headers, json=data)
result = response.json()
# print(result)
# return result['output']['choices'][0]['message']['content']
return result['output']['text']
except Exception as e:
return f"API調用錯誤: {str(e)}"
def logical_reasoning(self, premise: str, question: str) -> Dict:
"""邏輯推理問題思維鏈求解"""
prompt = f"""請基於以下前提進行邏輯推理,展示完整的思維鏈:
前提:{premise}
問題:{question}
推理步驟:
1. 分析前提條件:[提取關鍵信息]
2. 建立邏輯關係:[分析元素間的邏輯聯繫]
3. 逐步推導:[展示推理鏈條]
4. 得出結論:[回答原始問題]
請開始推理:"""
reasoning = self.generate_response(prompt)
return {
"premise": premise,
"question": question,
"logical_reasoning": reasoning
}
# 使用示例
def main():
# 初始化Qwen客户端
qwen_client = QwenChainOfThought(api_key=os.environ.get("DASHSCOPE_API_KEY"))
# 邏輯推理示例
logic_result = qwen_client.logical_reasoning(
premise="所有哺乳動物都有脊椎,鯨魚是哺乳動物,魚類不是哺乳動物",
question="鯨魚有脊椎嗎?"
)
print("\n邏輯推理結果:")
print(json.dumps(logic_result, ensure_ascii=False, indent=2))
if __name__ == "__main__":
main()
模型返回的結果:

模型推理步驟:
前提條件:所有哺乳動物都有脊椎,鯨魚是哺乳動物,魚類不是哺乳動物
問題:鯨魚有脊椎嗎?
邏輯推理過程:
1. 分析前提條件:
- 前提一:所有哺乳動物都有脊椎。
- 前提二:鯨魚是哺乳動物。
- 前提三:魚類不是哺乳動物。(這個信息對於解答當前問題不是直接相關,但有助於理解背景)
2. 建立邏輯關係:
- 根據前提一和前提二,我們可以建立一個直接的邏輯聯繫。既然所有哺乳動物都具有某一特徵(即有脊椎),而鯨魚屬於哺乳動物這一類別,那麼鯨魚也應該具備該類別成員共有的特徵。
3. 逐步推導:
- 步驟A: 確認鯨魚的身份 - 鯨魚被定義為哺乳動物(前提二)。
- 步驟B: 應用普遍規則到特定案例 - 所有哺乳動物都有脊椎(前提一)。因為鯨魚是哺乳動物之一,所以這條規則也適用於鯨魚。
- 結合步驟A與B, 我們可以得出結論説鯨魚應該擁有脊椎。
4. 得出結論:
- 綜上所述,根據給定的前提條件以及通過邏輯推理過程,我們可以確定鯨魚確實有脊椎。
3. 多輪推理複雜問題
調用Qwen大模型並基於前提條件"某公司有A、B、C三個部門,A部門人數是B部門的2倍,C部門人數比A部門少20人。如果三個部門總人數是280人,且B部門女性佔40%,A部門女性佔60%,C部門男女各半"進行邏輯推理"全公司女性總人數是多少",展示完整的思維鏈。
提示詞設計:
第一輪:問題分析與規劃
"""請分析以下複雜問題並制定解決計劃:
問題:{complex_problem}
請輸出:
1. 問題類型識別:[判斷問題屬於哪類推理任務]
2. 關鍵信息提取:[列出問題中的關鍵數據和條件]
3. 解決策略:[規劃大致的解決步驟]
4. 潛在難點:[預測可能遇到的困難]
分析結果:"""
第二輪:詳細推理
"""基於以下分析,請進行詳細推理:
問題:{complex_problem}
初步分析:{analysis}現在請執行詳細的逐步推理:"""
import requests
import json
from typing import List, Dict
import os
class QwenChainOfThought:
def __init__(self, api_key: str, base_url: str = "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation"):
self.api_key = api_key
self.base_url = base_url
self.headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
def generate_response(self, prompt: str, max_tokens: int = 1000) -> str:
"""調用Qwen API生成響應"""
data = {
"model": "qwen-max",
"input": {
"messages": [
{
"role": "user",
"content": prompt
}
]
},
"parameters": {
"max_tokens": max_tokens,
"temperature": 0.1 # 低温度值保證推理穩定性
}
}
try:
response = requests.post(self.base_url, headers=self.headers, json=data)
result = response.json()
# print(result)
# return result['output']['choices'][0]['message']['content']
return result['output']['text']
except Exception as e:
return f"API調用錯誤: {str(e)}"
def math_problem_solver(self, problem: str) -> Dict:
"""數學問題思維鏈求解"""
prompt = f"""請用思維鏈方式解決以下數學問題,展示完整的推理過程:
問題:{problem}
請按以下格式回答:
1. 理解問題:[簡要説明問題要求]
2. 分解步驟:[將問題分解為多個求解步驟]
3. 逐步計算:[展示每一步的具體計算]
4. 最終答案:[給出最終結果]
推理過程:"""
reasoning_process = self.generate_response(prompt)
return {
"problem": problem,
"reasoning_process": reasoning_process,
"prompt_used": prompt
}
def logical_reasoning(self, premise: str, question: str) -> Dict:
"""邏輯推理問題思維鏈求解"""
prompt = f"""請基於以下前提進行邏輯推理,展示完整的思維鏈:
前提:{premise}
問題:{question}
推理步驟:
1. 分析前提條件:[提取關鍵信息]
2. 建立邏輯關係:[分析元素間的邏輯聯繫]
3. 逐步推導:[展示推理鏈條]
4. 得出結論:[回答原始問題]
請開始推理:"""
reasoning = self.generate_response(prompt)
return {
"premise": premise,
"question": question,
"logical_reasoning": reasoning
}
class AdvancedChainOfThought(QwenChainOfThought):
def multi_step_reasoning(self, complex_problem: str) -> Dict:
"""處理需要多輪推理的複雜問題"""
# 第一輪:問題分析與規劃
analysis_prompt = f"""請分析以下複雜問題並制定解決計劃:
問題:{complex_problem}
請輸出:
1. 問題類型識別:[判斷問題屬於哪類推理任務]
2. 關鍵信息提取:[列出問題中的關鍵數據和條件]
3. 解決策略:[規劃大致的解決步驟]
4. 潛在難點:[預測可能遇到的困難]
分析結果:"""
analysis = self.generate_response(analysis_prompt)
# 第二輪:詳細推理
reasoning_prompt = f"""基於以下分析,請進行詳細推理:
問題:{complex_problem}
初步分析:{analysis}
現在請執行詳細的逐步推理:"""
detailed_reasoning = self.generate_response(reasoning_prompt)
return {
"complex_problem": complex_problem,
"problem_analysis": analysis,
"detailed_reasoning": detailed_reasoning
}
# 使用示例
def main():
# 初始化Qwen客户端
qwen_client = QwenChainOfThought(api_key=os.environ.get("DASHSCOPE_API_KEY"))
# 複雜問題示例
advanced_client = AdvancedChainOfThought(api_key=os.environ.get("DASHSCOPE_API_KEY"))
complex_result = advanced_client.multi_step_reasoning(
"某公司有A、B、C三個部門,A部門人數是B部門的2倍,C部門人數比A部門少20人。"
"如果三個部門總人數是280人,且B部門女性佔40%,A部門女性佔60%,C部門男女各半,"
"請問全公司女性總人數是多少?"
)
print("複雜問題求解結果:")
print(json.dumps(complex_result, ensure_ascii=False, indent=2))
if __name__ == "__main__":
main()
模型返回的結果:

模型推理步驟:
問題:某公司有A、B、C三個部門,A部門人數是B部門的2倍,C部門人數比A部門少20人。如果三個部門總人數是280人,且B部門
女性佔40%,A部門女性佔60%,C部門男女各半,請問全公司女性總人數是多少?
問題分析:
1. 問題類型識別
這個問題屬於代數推理任務,需要通過給定的條件建立方程組來求解未知數,並基於這些數值進
一步計算特定羣體(本例中為女性員工)的數量。
2. 關鍵信息提取
- A部門人數是B部門的2倍。
- C部門人數比A部門少20人。
- 三個部門總人數為280人。
- B部門女性佔比40%。
- A部門女性佔比60%。
- C部門男女比例相等。
3. 解決策略
步驟一:設B部門人數為x,則A部門人數為2x,C部門人數為2x-20。
步驟二:根據題目給出的總人數建立等式:[x + 2x + (2x - 20) = 280],解此方程找到x值。
步驟三:利用x值確定每個部門的具體人數。
步驟四:根據各部性別比例計算出各部門女性人數。
- B部門女性人數 = (x * 40%)
- A部門女性人數 = (2x * 60%)
- C部門女性人數 = ((2x - 20) / 2) (因為男女比例相同)
步驟五:將上述結果相加得到全公司女性總數。
4. 潛在難點
- 確保正確理解題意並準確設置變量與方程。
- 在處理百分比時注意單位一致性(例如,確保使用小數或分數形式進行計算)。
- 計算過程中避免簡單的數學錯誤,如乘法、除法運算失誤等。
分析結果\n按照上述策略執行:
- 第一步設定方程:[5x - 20 = 280] => [5x = 300] => [x = 60]
- 因此,B部門有60人,A部門有(2*60=120)人,C部門有(120-20=100)人。
- 接下來計算女性人數:
- B部門女性人數 = (60 * 0.4 = 24)
- A部門女性人數 = (120 * 0.6 = 72)
- C部門女性人數 = (100 / 2 = 50)
- 全公司女性總人數 = (24 + 72 + 50 = 146)
綜上所述,該公司的女性總人數為146人。
詳細推理:
根據題目描述和初步分析,我們可以按照以下步驟進行詳細推理:
步驟一:設定變量
- 設B部門人數為(x)。
- 根據題意,A部門人數是B部門的2倍,即A部門人數為(2x)。
- C部門人數比A部門少20人,因此C部門人數為(2x - 20)。
步驟二:建立等式並求解\n根據題目給出的信息,三個部門總人數為280人。可以建立如下等式:[x + 2x + (2x - 20) = 280]
簡化上述等式得:[5x - 20 = 280]
進一步簡化得到:[5x = 300]
從而得出:[x = 60]這意味着B部門有60人。
步驟三:確定每個部門的具體人數
- B部門人數(x = 60)人。
- A部門人數(2x = 120)人。
- C部門人數(2x - 20 = 100)人。
步驟四:計算各部門女性人數
- **B部門**:女性佔比40%,所以女性人數為(60 * 0.4 = 24)人。
- **A部門**:女性佔比60%,因此女性人數為(120 * 0.6 = 72)人。
- **C部門**:男女比例相等,故女性人數為(100 / 2 = 50)人。
步驟五:彙總全公司女性總數\n將上述結果相加得到全公司女性總數:[24 + 72 + 50 = 146]人
結論
綜上所述,該公司的女性總人數為146人。
這與初步分析的結果一致,驗證了我們的解題過程正確無誤。
四、思維鏈提示的應用場景
- 教育領域應用:在智能教育助手場景中,思維鏈提示可用於解題輔導。當學生詢問數學問題時,系統不僅給出答案,還展示完整的解題思路,幫助學生理解方法而非僅僅記憶結果。
- 商業決策支持:企業使用思維鏈提示進行風險評估和數據分析。例如在投資決策中,模型會逐步分析市場數據、競爭態勢和財務指標,提供透明化的決策依據。
- 科學研究輔助:研究人員利用該技術進行文獻分析和假設生成。模型能夠展示從已有數據到新發現的推理路徑,增強科研工作的可重複性和可信度。
五、總結
思維鏈提示作為大模型能力增強的關鍵技術,其核心價值體現在對人工智能推理機制的根本性優化。首先,該技術突破了傳統大模型的黑箱推理瓶頸,通過將複雜問題拆解為顯式化的中間推理步驟,使模型從直接輸出結論轉變為可追蹤的邏輯推演過程,有效解決了複雜任務中推理路徑模糊的問題。
其次,思維鏈提示顯著提升了AI系統的決策透明度,顯式呈現的推理鏈條為人類理解AI決策依據提供了可解釋框架,這一特性在高風險領域決策中尤為重要,能夠增強用户對AI系統的信任度並降低應用風險。