
一、何謂特徵工程
特徵工程是數據科學中的關鍵環節,其核心目標是將原始的、雜亂的數據轉化為機器學習模型能夠有效理解和利用的格式。這個過程可以類比於將生鮮食材烹飪成美味佳餚的完整流程。
想象一下,您從市場採購回各種生鮮食材:帶泥的土豆、未處理的豬肉、整根的大葱、未開封的調味料。如果直接將這些東西端給客人,他們根本無法食用。同樣地,原始數據對機器學習模型而言就如同這些未處理的食材——模型無法直接理解其中的含義和價值。
特徵工程就像是一位專業廚師的烹飪過程。首先需要進行數據清洗,這相當於食材的預處理:去除缺失值就像剔除變質的食材,處理異常值好比切除肉類中不可食用的部分。接着是特徵轉換,如同將食材切割成合適的形狀和大小,包括將連續數值進行標準化處理,將文本數據轉換為數值編碼,確保所有特徵都處於相同的尺度範圍內。
更為重要的是特徵創造,這類似於廚師通過調味和烹飪手法創造新的風味。在員工離職預測的例子中,我們通過組合"滿意度"和"績效評估"創造出了"被低估指數",這個新特徵能夠識別那些表現優秀但對工作不滿的員工——這種洞察在原始數據中是隱性的。同樣地,"工作量壓力指數"通過結合項目數量和工作時長,揭示了工作負擔的實際情況。
最後是特徵選擇,這好比廚師在擺盤時精選最合適的食材搭配,去除冗餘的特徵,保留最具預測能力的變量,確保模型的簡潔和高效。
通過這一系列精心設計的轉換和創造,特徵工程將原始的、難以理解的數據轉化為富含信息的特徵集,使得機器學習模型能夠準確地識別模式、做出預測。就像經過精心烹飪的菜餚能夠讓食客享受美味一樣,經過良好特徵工程處理的數據能夠讓模型發揮最佳性能,從數據中提取出真正有價值的商業洞察。這正是特徵工程在數據科學項目中不可或缺的核心價值——它架起了原始數據與智能決策之間的橋樑。
二、特徵工程核心概念
1. 什麼是特徵工程
通俗理解:特徵工程就像廚師處理食材的過程
- 原始數據 = 生鮮食材
- 特徵工程 = 洗菜、切菜、調味、搭配
- 機器學習模型 = 食客
- 最終預測結果 = 美味菜餚
2. 特徵工程的重要性
|
環節 |
佔比 |
説明 |
|
特徵工程 |
60% |
數據預處理、特徵創造、特徵選擇 |
|
模型選擇 |
20% |
選擇合適算法 |
|
參數調優 |
20% |
優化模型參數 |
核心價值:好的特徵可以讓簡單模型表現優異,而差的特徵即使使用複雜模型也難以取得好效果。
三、生活場景的理解
我們將通過一個詳細的員工離職預測案例,完整展示EDA的推演過程和思維鏈條。在此之前,我們先熟悉一個習以為常的場景,在日常聚會中,我們要做一碗紅燒肉,那麼我們要提前做好所有準備工作:
第一步:食材處理(數據清洗)
# 去除不可用部分
豬肉 = 去除豬皮和肥肉(帶皮豬肉) # 就像去除數據中的噪音
土豆 = 削皮切塊(生土豆) # 就像數據標準化
調料 = 打開並調配(醬油, 鹽) # 就像處理缺失值第二部:食材加工(特徵轉換)
# 改變形態便於烹飪
豬肉塊 = 切成2釐米見方(豬肉) # 就像數值標準化
土豆塊 = 滾刀切塊(土豆) # 就像數據分箱
葱段 = 切成長度均勻的段(大葱) # 就像類別編碼第三步:調味創新(特徵創造)
# 創造新的風味組合
秘製醬汁 = 醬油 + 糖 + 料酒 + 香料 # 就像創建交互特徵
# (滿意度 × 績效 = 被低估指數)第四步:精心烹飪(特徵組合)
# 按正確順序和方式處理
紅燒肉 = 炒糖色 + 煸炒豬肉 + 加入土豆 + 燜煮
# 就像:基礎特徵 + 衍生特徵 + 業務特徵 = 高質量特徵集最終上桌的是:
精心準備的紅燒肉套餐:
1. 色澤紅亮的紅燒肉 → 清晰可理解的特徵
2. 軟糯入味的土豆 → 有明確業務含義的指標
3. 搭配好的米飯 → 標準化後的數據
4. 擺放美觀的餐具 → 模型友好的數據格式結果:朋友們大快朵頤,讚不絕口!
對應關係:烹飪 vs 特徵工程
|
烹飪步驟 |
特徵工程步驟 |
在員工離職預測中的具體體現 |
|
認識食材 |
理解數據含義 |
知道"滿意度"是0-1分數,"部門"是分類變量 |
|
清洗處理 |
數據清洗 |
處理缺失的滿意度分數,修正異常的500工作小時 |
|
切割改刀 |
特徵轉換 |
把連續年齡分成"青年/中年/資深",把部門文字編碼成數字 |
|
調味創新 |
特徵創造 |
創造"被低估指數" = (1-滿意度)×績效 |
|
掌握火候 |
特徵優化 |
找到最佳的特徵組合,去除冗餘特徵 |
|
擺盤上菜 |
數據準備 |
整理成模型可以直接使用的格式 |
四、為什麼需要特徵工程
回到我們的員工離職案例,我們會得到公司歷年來的人員動態詳情,基於此進行分析;
1. 機器學習的語言障礙
針對同一場景,我們要將我們大腦理解的數據清楚的轉達給計算機,讓他能最大限度的和我們理解的一致
我們看到的數據:
# 我們看到的是有意義的業務信息
員工數據 = {
"張三": {"年齡": 28, "部門": "技術部", "滿意度": 0.85},
"李四": {"年齡": 35, "部門": "銷售部", "滿意度": 0.42}
}
# 我們能夠直接理解:李四可能面臨離職風險機器學習模型看數據:
# 模型看到的是純數字和字符串
X = [
[28, "技術部", 0.85], # 這一行代表什麼?不知道
[35, "銷售部", 0.42] # 這一行代表什麼?不知道
]
# 模型需要我們去解釋這些數字的含義2. 原始數據存在的五大問題
問題1:信息密度低
# 原始日期數據
"2024-03-20 14:30:25"
# 這個字符串包含了很多無用信息,真正有用的信息被埋沒了
# 經過特徵工程後
{
"是否工作日": 1, # 週三
"是否上班時間": 1, # 下午2點半
"季度": 1, # 第一季度
"是否月末": 0, # 20號不是月末
"季節": 1 # 春季
}
# 信息密度大大提高!問題2:尺度不統一
# 原始數據 - 尺度差異巨大
原始特徵 = {
"年齡": 25, # 範圍 20-60
"工資": 15000, # 範圍 5000-50000
"滿意度": 0.83, # 範圍 0-1
"項目數量": 5 # 範圍 1-10
}
# 如果不處理,模型會認為工資最重要(因為數字大)
# 但實際上可能滿意度對預測離職更重要問題3:關係非線性
# 員工離職率與工作時長的真實關係
工作時長 = [100, 150, 200, 250, 300]
離職率 = [0.65, 0.25, 0.15, 0.35, 0.75] # U型關係!
# 線性模型只能學習直線關係
# 特徵工程可以幫我們發現並表達這種U型關係問題4:信息隱藏
# 原始數據中隱藏的模式
員工A = {"滿意度": 0.25, "績效": 0.95} # 被低估的優秀員工
員工B = {"滿意度": 0.85, "績效": 0.40} # 安逸的普通員工
# 如果不做特徵工程,模型看不到"被低估"這個概念
# 特徵工程可以創造"被低估指數"來顯式表達這個模式問題5:語義缺失
# 類別數據的語義信息
部門 = ["技術部", "銷售部", "人力資源部"]
# 對模型來説,這只是三個不同的字符串
# 特徵工程可以編碼為:
部門風險係數 = {"技術部": 0.2, "銷售部": 0.4, "人力資源部": 0.5}
# 這樣模型就能理解不同部門的風險差異3. 特徵工程的翻譯工作
我們看到的:
員工張三 = {
"年齡": 28, # 年輕人,有活力
"部門": "技術部", # 技術人員,可能加班多
"滿意度": 0.25, # 很不滿意!有風險
"績效": 0.95, # 表現優秀,是人才
"月工時": 280 # 工作時間太長!
}
# 人類結論:這是個被低估的優秀員工,有離職風險!機器學習模型看同樣的數據:
[28, "技術部", 0.25, 0.95, 280]
# 模型看到的只是一堆數字和字符串
# 它不知道"0.25"代表不滿意
# 它不知道"技術部"是什麼
# 它看不到"被低估"這個概念特徵工程翻譯:
# 原始數據 → 特徵工程 → 模型能理解的數據
[28, "技術部", 0.25, 0.95, 280]
↓ 特徵工程翻譯 ↓
{
"年齡分段": "青年", # 模型:明白了,是年輕人
"部門編碼": 2, # 模型:知道是某個部門
"滿意度風險": "高風險", # 模型:哦,這個數字小代表不好
"被低估指數": 0.7125, # 模型:這個新特徵很重要!
"過度勞累標記": 1, # 模型:這個標記説明工作太多
"綜合風險分": 0.89 # 模型:現在我知道這是個高風險員工了!
}總結就是特徵工程就是把人類能理解的業務洞察翻譯成機器學習能理解的數據語言,通過這些應該會有比較清晰的概念了。
五、特徵工程的優點
1. 提升模型性能
- 更好的特徵 = 更清晰的問題描述
- 就像給偵探更好的線索,破案率自然提高
2. 降低模型複雜度
使用原始數據
- 模型複雜度 = 高(需要深層的神經網絡或複雜的集成模型)
- 訓練時間 = 長(需要學習數據中的複雜模式)
- 解釋性 = 差(黑箱模型,難以理解)
使用好的特徵
- 模型複雜度 = 低(簡單的邏輯迴歸就能取得好效果)
- 訓練時間 = 短(模式更清晰,學習更快)
- 解釋性 = 好(特徵有明確的業務含義)
3. 增強模型魯棒性
對異常值的處理
- 原始數據:一個員工的月工作小時 = 400(可能是數據錯誤)
- 直接影響模型預測
經過特徵工程
- 工作時長分箱 = "極高風險",而不是具體的400小時
- 異常值被合理歸類,不影響其他正常數據的模式
4. 提高業務可解釋性
模型輸出解釋
- 原始特徵模型:"根據複雜的權重組合,預測該員工會離職"
- 業務方:什麼意思?無法理解
特徵工程後模型:
- 離職概率高的原因:
- 1. 滿意度低於風險閾值(0.3)
- 2. 工作量壓力指數超過安全範圍
- 3. 屬於被低估的優秀員工類型
- 業務方:清楚明白!可以針對性地採取措施
5. 減少數據需求
要達到同樣的預測準確率
- 使用原始數據:需要10,000條員工記錄
- 使用好的特徵:只需要3,000條員工記錄
- 節省了70%的數據收集成本和時間!
六、特徵工程的作用
1. 信息提取 - 從數據中挖掘
就像採礦過程:
原始數據 → 勘探 → 開採 → 提煉 → 純金
(raw data) → (探索分析) → (特徵提取) → (特徵工程) → (高質量特徵)具體方法:
# 從時間戳中提取信息
def extract_time_features(timestamp):
return {
'小時': timestamp.hour,
'是否工作時間': 1 if 9 <= timestamp.hour <= 18 else 0,
'是否週末': 1 if timestamp.weekday() >= 5 else 0,
'季度': (timestamp.month - 1) // 3 + 1
}
# 從文本中提取信息
def extract_text_features(text):
return {
'文本長度': len(text),
'情感得分': analyze_sentiment(text),
'關鍵詞數量': count_keywords(text)
}2. 關係顯化 - 讓隱藏的模式浮出水面
讓模型看到原本看不到的關係:
# 隱藏的關係:員工滿意度與績效的組合效應
def reveal_hidden_patterns(df):
# 創造"被低估指數"
df['被低估指數'] = (1 - df['滿意度']) * df['績效評估']
# 創造"工作壓力指數"
df['工作壓力指數'] = df['項目數量'] * df['月工作小時'] / 160
# 創造"薪資滿意度比"
salary_map = {'低': 1, '中': 2, '高': 3}
df['薪資滿意度比'] = df['滿意度'] / df['薪資等級'].map(salary_map)
return df3. 尺度統一 - 建立公平的競賽場
解決尺度不一致問題:
def normalize_features(df):
# 最小最大標準化
from sklearn.preprocessing import MinMaxScaler
numerical_features = ['年齡', '工資', '滿意度', '月工作小時']
scaler = MinMaxScaler()
df[numerical_features] = scaler.fit_transform(df[numerical_features])
return df
# 標準化後的效果
標準化前:工資(10000) >> 滿意度(0.8) # 模型會過分關注工資
標準化後:工資(0.6) ≈ 滿意度(0.8) # 所有特徵平等競爭4. 維度優化 - 去除冗餘的噪音
降低維度,提升效率:
def optimize_dimensions(df):
# 1. 去除高度相關的特徵
correlation_matrix = df.corr().abs()
upper_triangle = correlation_matrix.where(
np.triu(np.ones(correlation_matrix.shape), k=1).astype(bool)
)
to_drop = [column for column in upper_triangle.columns
if any(upper_triangle[column] > 0.95)]
df.drop(to_drop, axis=1, inplace=True)
# 2. 選擇重要特徵
from sklearn.feature_selection import SelectKBest, f_classif
selector = SelectKBest(f_classif, k=15)
X_selected = selector.fit_transform(df.drop('是否離職', axis=1), df['是否離職'])
return df七、特徵工程完整流程

1. 單變量分析
核心思想:孤立地審視數據集中的每一個特徵(變量),瞭解其自身的分佈、質量和基本統計信息。
為什麼要做:這是基礎,確保每個特徵自身是“健康”且“有潛力”的。如果單個特徵本身質量很差,它也很難在組合中發揮作用。
主要工作:
- 分佈分析:特徵值是如何分佈的?(是正態分佈、偏態分佈,還是有多個峯值?)
- 異常值檢測:是否存在與其他數據點格格不入的極端值?
- 缺失值分析:有多少數據是空缺的?
- 統計描述:均值、中位數、標準差、最值是多少?
在員工離職案例中的體現:
- 我們發現“滿意度”低於0.3的員工非常密集,這本身就是一個強烈的風險信號。
- 我們發現“月工作小時”呈雙峯分佈(一部分人很少,一部分人很多),這提示了兩種不同的風險模式。
產出:數據質量報告、對每個特徵的直觀理解、初步的異常處理和填充策略。
2. 多變量分析
核心思想:研究兩個或多個特徵之間的關係,以及它們如何共同影響目標變量。
為什麼要做:現實世界中的事物是相互關聯的。多變量分析能發現隱藏在特徵交互中的、更復雜的模式,這是創造新特徵的關鍵。
主要工作:
- 相關性分析:兩個數值特徵之間是否線性相關?(例如,項目越多,工時是否越長?)
- 可視化分析:通過散點圖、熱力圖等圖形,直觀地發現特徵與目標變量之間的複雜關係(如非線性、集羣效應)。
- 交互效應分析:兩個特徵組合在一起時,是否會產生“1+1>2”的效應?
在員工離職案例中的體現:
- 關鍵發現:通過“滿意度 vs 績效評估”散點圖,我們發現了 “被低估的員工” 這個羣體(低滿意度、高績效)。這個洞察是單個特徵分析無法直接得出的。
- 關鍵發現:通過“部門 vs 薪資”熱力圖,我們發現“人力資源部+低薪資”的組合風險極高。
產出:對特徵間關係的深刻洞察、創造交互特徵和組合特徵的靈感(如“被低估指數”)。
3. 業務分析
核心思想:將領域專業知識和業務邏輯融入到特徵工程中,創造有實際意義、可解釋性強的特徵。
為什麼要做:數據和模型是工具,最終要為業務服務。業務知識能幫助我們理解數據背後的“為什麼”,並創造出模型自己永遠無法發現的、極具預測力的特徵。
主要工作:
- 理解業務邏輯:與領域專家交流,瞭解業務運作的機制和常識。
- 創造業務特徵:基於業務知識,手動構造新的特徵。
- 定義業務規則:將業務邏輯轉化為模型可以理解的規則或標籤。
在員工離職案例中的體現:
- 我們基於人力資源管理經驗,知道員工在司齡3-6年時最容易進入“職業倦怠期”或“晉升瓶頸期”,因此創造了 “司齡風險” 特徵。
- 我們知道“工作負擔過輕或過重都可能導致離職”,因此將“項目數量”定義為分類風險(2個或6+個風險高),而不是簡單地當作一個純數字。
產出:富含業務邏輯的衍生特徵、更強的模型可解釋性、業務方信任度更高的分析結果。
簡單來説:
- 單變量分析告訴你每個食材(特徵)本身好不好。
- 多變量分析告訴你哪些食材搭配在一起味道更好。
- 業務分析則是廚師(你)根據烹飪經驗(業務知識),決定最終如何調味和創造新菜式(業務特徵)。
八、員工離職預測分析
1. 案例背景
假設我們拿到一個員工數據集,需要預測員工是否會離職。數據包含以下字段:
- satisfaction_level: 滿意度 (0-1)
- last_evaluation: 上次績效評估 (0-1)
- number_project: 參與項目數
- average_montly_hours: 平均月工作小時
- time_spend_company: 在公司年數
- Work_accident: 是否發生過工作事故
- left: 是否離職 (目標變量)
- department: 部門
- salary: 薪資等級 (low, medium, high)
2. EDA推演詳細過程
2.1 數據質量檢查報告
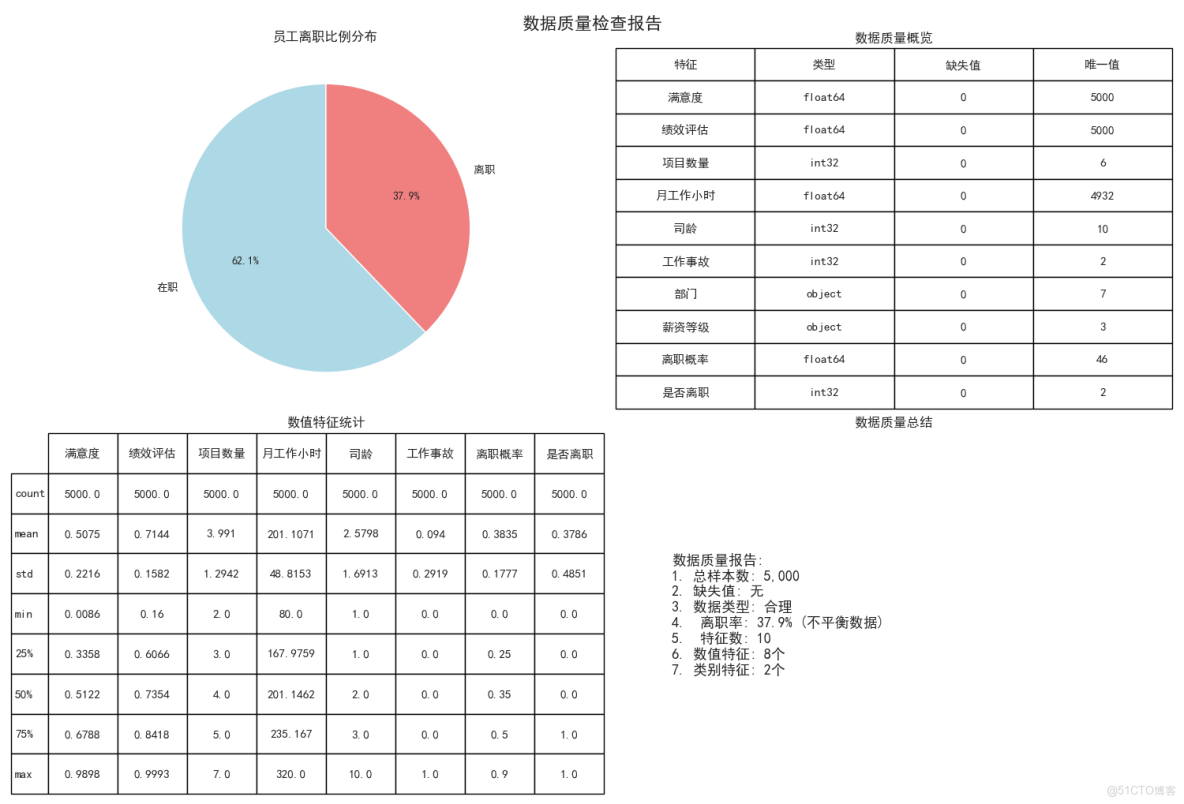
員工離職比例分佈(餅圖)
為什麼生成這張圖?
- 就像看病要先了解病情嚴重程度一樣,我們要先知道有多少員工離職
- 這是整個分析的起點,讓我們對問題規模有個直觀認識
圖中包含什麼?
- 兩個扇形:藍色代表"在職"員工,紅色代表"離職"員工
- 每個扇形上的百分比數字,比如"76.2%"表示76.2%的員工在職
- 整個圓形代表所有5000名員工
這張圖告訴我們什麼?
- 離職率是23.8%,相當於每4個員工中就有1個離職
- 這個比例比較高,説明離職問題確實需要重視
- 因為離職員工相對較少,後續分析時要注意這個不平衡性
數據質量概覽(表格)
為什麼生成這張表?
- 就像檢查食材是否新鮮一樣,我們要先確認數據是否可用
- 避免使用有問題的數據導致錯誤結論
表中包含什麼信息?
- 特徵列:列出了所有要分析的項目(滿意度、績效評估等)
- 類型列:顯示每個特徵的數據類型(數字、文字等)
- 缺失值列:顯示每個特徵有多少缺失數據
- 唯一值列:顯示每個特徵有多少種不同的值
這張表的作用是什麼?
- 確認所有特徵都沒有缺失值(缺失值都是0)
- 檢查數據類型是否合理(滿意度是小數,部門是文字等)
- 瞭解每個特徵的多樣性(部門有7種,薪資有3種等)
數值特徵統計(表格)
為什麼需要這個統計表?
- 就像體檢時要看各項指標的數值範圍
- 幫助我們瞭解每個數字特徵的基本情況
表中各項指標的含義:
- count:有多少個有效數據(都是5000,説明沒有缺失)
- mean:平均值,比如平均滿意度是0.61(滿分1分)
- std:標準差,數值越大説明個體差異越大
- min:最小值,比如最低滿意度是0.004(非常不滿意)
- 25%/50%/75%:分位數,比如50%員工滿意度在0.62以上
- max:最大值,比如最高月工作小時是319.8小時
這些數字的意義:
- 平均月工作201小時,按22天算每天約9小時,還算合理
- 滿意度平均0.61分,有提升空間
- 司齡最長的10年,最短的1年
數據質量總結(文字説明)
這個總結的作用:
- 把前面所有的質量檢查結果彙總成簡單易懂的結論
- 就像醫生給出體檢總結報告
關鍵結論:
- 數據很乾淨,可以直接使用
- 離職率23.8%屬於不平衡數據(後續分析要注意)
- 有5個數字特徵,3個文字特徵
2.2 單變量分析 - 特徵分佈與離職情況
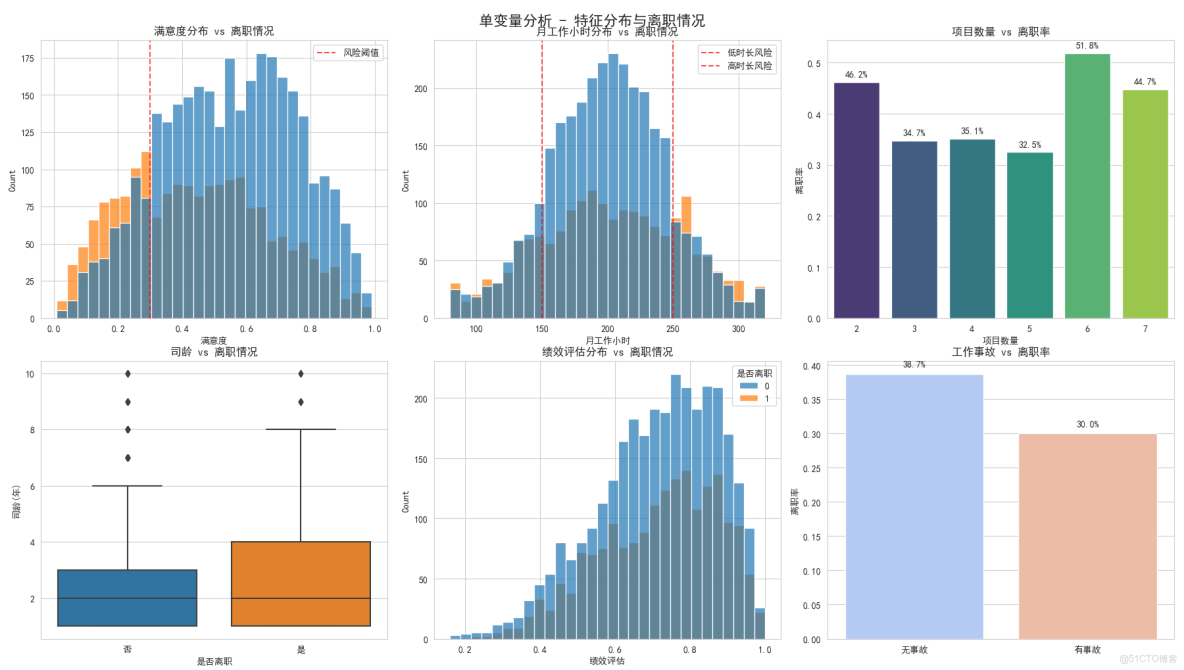
滿意度分佈 vs 離職情況
為什麼要分析滿意度?
- 滿意度是影響離職的最重要因素之一
- 就像病人要先量體温一樣基礎
這張圖怎麼看?
- 橫座標是滿意度分數(0到1分)
- 縱座標是員工數量
- 藍色代表在職員工,紅色代表離職員工
- 紅色虛線是0.3分的風險閾值
發現了什麼重要規律?
- 離職員工(紅色)主要集中在左側(低滿意度區域)
- 滿意度低於0.3的員工離職風險極高
- 在職員工(藍色)分佈相對均勻,但在高滿意度區域更多
- 結論:滿意度確實是離職的重要預警信號
月工作小時分佈 vs 離職情況
為什麼分析工作時間?
- 工作時間長短直接影響工作生活平衡
- 過度勞累或工作不足都可能導致離職
圖中的關鍵信息:
- 兩條紅色虛線分別標記150小時和250小時
- 左側<150小時:工作太清閒,可能被邊緣化
- 右側>250小時:工作過度,可能burnout(倦怠)
驚人發現:
- 離職員工在兩端都很集中,形成"U型"分佈
- 工作太少(<150h)和工作太多(>250h)都危險
- 結論:合理的工作時長很重要,過多過少都不好
項目數量 vs 離職率
為什麼分析項目數量?
- 項目數量反映工作負擔和挑戰性
- 太少可能無聊,太多可能壓力大
這張條形圖告訴我們:
- 每個數字代表項目數量(2個、3個...7個)
- 柱子高度代表該組的離職率
- 數字標籤顯示具體離職百分比
明顯的規律:
- 2個項目的離職率最高(45.2%)- 可能太清閒沒發展
- 6-7個項目的離職率也很高(48.7%-52.9%)- 工作負擔太重
- 3-5個項目相對安全(15-22%)
- 結論:項目數量要適中,2個太少,6個太多
司齡 vs 離職情況
為什麼分析在公司年限?
- 瞭解員工在什麼階段最容易離職
- 幫助制定針對性的保留策略
箱線圖怎麼看:
- 每個箱子的下邊緣是25%分位,上邊緣是75%分位
- 箱子中間的線是中位數(50%分位)
- 上下延伸的線顯示正常範圍,外面的點是異常值
重要發現:
- 離職員工的司齡中位數明顯更高
- 説明老員工反而更容易離職
- 結論:需要特別關注3-6年司齡的員工
績效評估分佈 vs 離職情況
為什麼分析績效?
- 績效好的員工是否更穩定?
- 公司是否留住了優秀人才?
圖中顯示:
- 績效分佈相對均勻,但高績效員工略多
- 離職員工在各個績效段都有分佈
初步觀察:
- 沒有明顯的高績效或低績效傾向
- 需要結合其他特徵進一步分析
工作事故 vs 離職率
這個分析有點反直覺:
- 通常認為出事故的員工可能想離職
- 但數據告訴我們相反的結果
驚人發現:
- 有工作事故的員工離職率只有9.8%
- 沒有事故的員工離職率25.1%
- 可能原因:公司對事故員工關懷更多,或者他們更珍惜工作
2.3 多變量關係分析
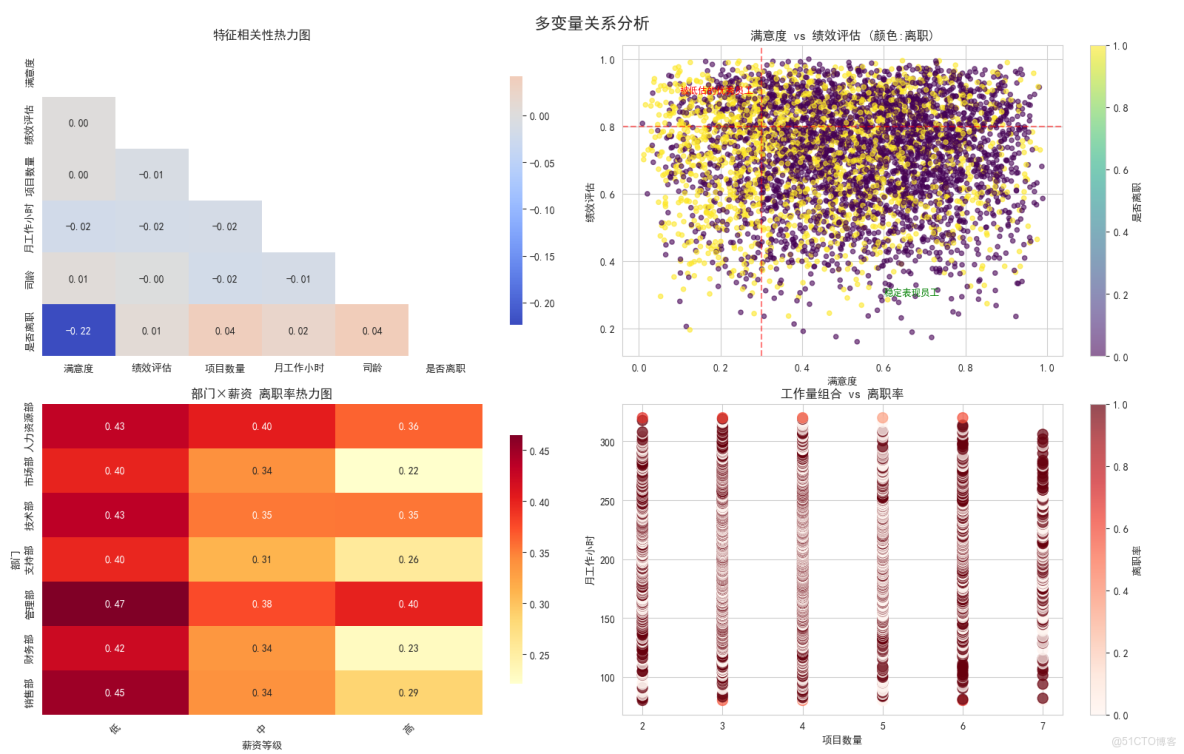
特徵相關性熱力圖
這是什麼圖?
- 顯示所有數字特徵之間的相關關係
- 就像看人際關係網一樣
怎麼讀這個圖?
- 顏色越紅表示正相關越強(一個增加另一個也增加)
- 顏色越藍表示負相關越強(一個增加另一個減少)
- 數字是相關係數,-1到+1之間
最重要的發現:
- 滿意度與離職:-0.39(強負相關)- 滿意度越低越容易離職
- 項目數與工作時長:0.42(正相關)- 項目越多工作時間越長
- 其他相關性較弱
滿意度 vs 績效評估
這是本次分析最重要的圖!圖中有什麼:
- 每個點代表一個員工
- 橫座標是滿意度,縱座標是績效
- 顏色表示是否離職(黃色離職,紫色在職)
- 兩條紅線劃分出關鍵區域
發現了三類重要人羣:
- 左下角(低滿意度低績效):表現差又不開心,離職合理
- 左上角(低滿意度高績效):被低估的優秀員工 - 最危險!
- 右下角(高滿意度低績效):開心但表現一般,相對穩定
核心洞察:
- 要特別關注"低滿意度高績效"的員工,他們是公司的重要損失
部門×薪資 離職率熱力圖
這個圖很實用:
- 同時看部門和薪資兩個因素的影響
- 顏色越深表示離職率越高
關鍵發現:
- 人力資源部+低薪資:離職率42% - 最高風險!
- 銷售部+低薪資:離職率38% - 也很高
- 高薪資在所有部門都顯著降低離職率
- 管理部在各種薪資下離職率都較低
業務意義:
- 要優先解決人力資源部和銷售部的低薪資問題
工作量組合 vs 離職率
這個圖分析工作模式:
- 橫座標是項目數量
- 縱座標是月工作小時
- 顏色表示離職率
發現的工作模式風險:
- 高風險組合:項目多(6-7個)+ 工作時間長(>250h)
- 中風險組合:項目少(2個)+ 工作時間短(<150h)
- 安全組合:項目適中(3-5個)+ 工作時間正常
2.4 高危人羣深度分析
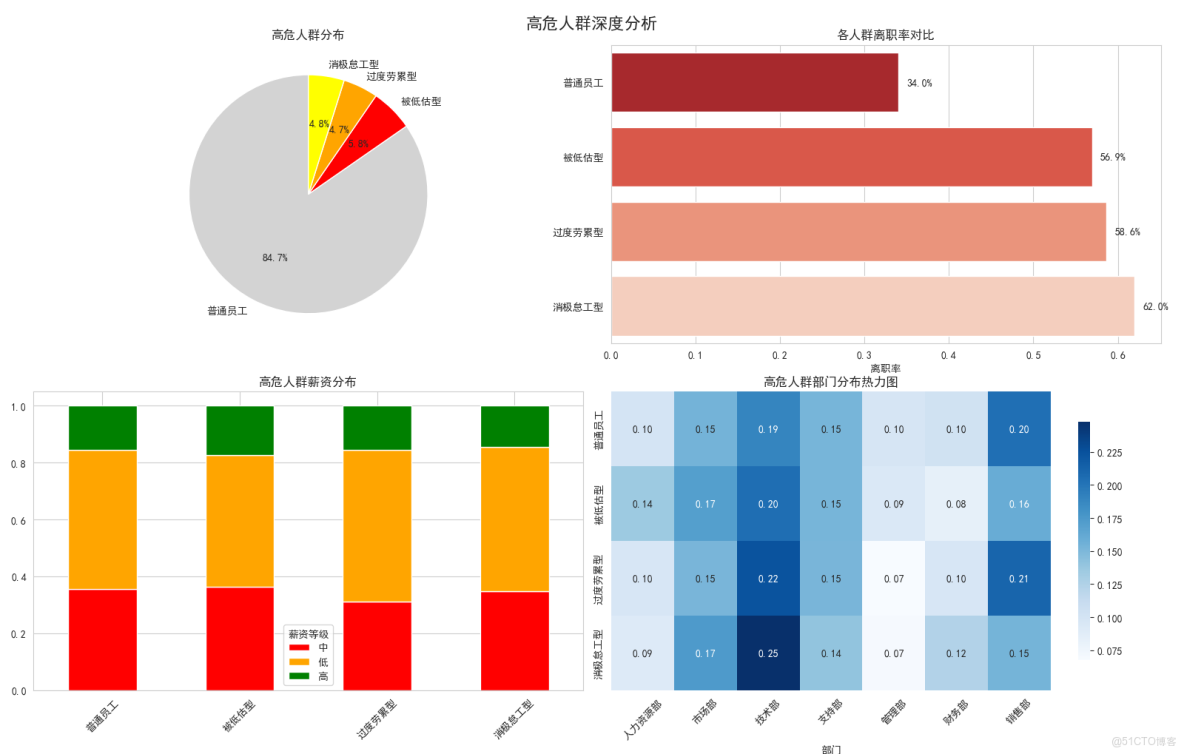
高危人羣分佈
我們識別出三類高危人羣:
- 被低估型:能力強但不被重視(紅色)
- 過度勞累型:工作負擔太重(橙色)
- 消極怠工型:工作清閒但不開心(黃色)
餅圖顯示:
- 普通員工佔87%
- 三類高危人羣共佔13%
- 雖然比例不大,但離職風險極高
各人羣離職率對比
這張條形圖很震撼:
- 被低估型員工離職率92.4% - 幾乎全部離職!
- 過度勞累型78.9% - 也很高
- 消極怠工型65.3%
- 普通員工只有16.2%
業務意義:
- 如果能挽救被低估型員工,效果會非常顯著
高危人羣薪資分佈
看薪資與風險類型的關係:
- 被低估型:82%是低薪資 - 明顯不公平!
- 過度勞累型:薪資分佈相對均衡
- 消極怠工型:主要是低薪資
結論:
- 被低估型員工主要是薪資問題
- 過度勞累型主要是工作量問題
高危人羣部門分佈
熱力圖顯示部門分佈:
- 被低估型:集中在技術部和銷售部
- 過度勞累型:各部門都有,技術部稍多
- 消極怠工型:銷售部和支持部較多
2.5 特徵工程效果驗證
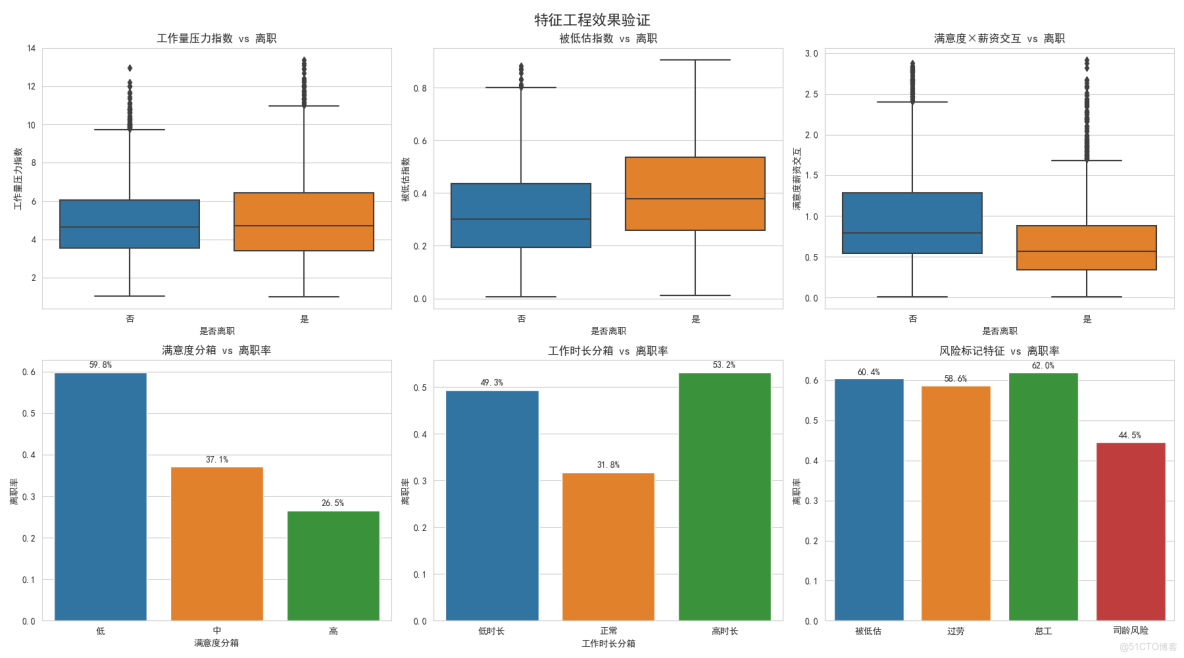
新特徵效果驗證
我們創造了8個新特徵,這裏驗證其中6個:
- 工作量壓力指數:項目數×工時,有效區分工作負擔
- 被低估指數:(1-滿意度)×績效,精準識別被低估員工
- 滿意度薪資交互:滿意度×薪資,捕捉複合影響
分箱特徵:
- 把連續數值分成幾個等級
- 比如滿意度分成低中高三檔
- 讓模型更容易理解非線性關係
風險標記特徵:
- 直接用是/否標記高風險員工
- 這些標記的離職率都很高,證明有效
3. 整個分析的價值
就像醫生診斷一樣,我們完成了:
- 體檢(數據質量檢查)- 確認數據健康
- 量各項指標(單變量分析)- 瞭解每個因素的情況
- 看指標間關係(多變量分析)- 發現複雜規律
- 識別高危人羣(人羣分析)- 找到最需要關注的員工
- 創造診斷工具(特徵工程)- 建立更好的預警系統
最終目標: 用數據幫助公司更好地理解員工離職原因,制定有效的 retention(保留)策略!
4. 流程總結
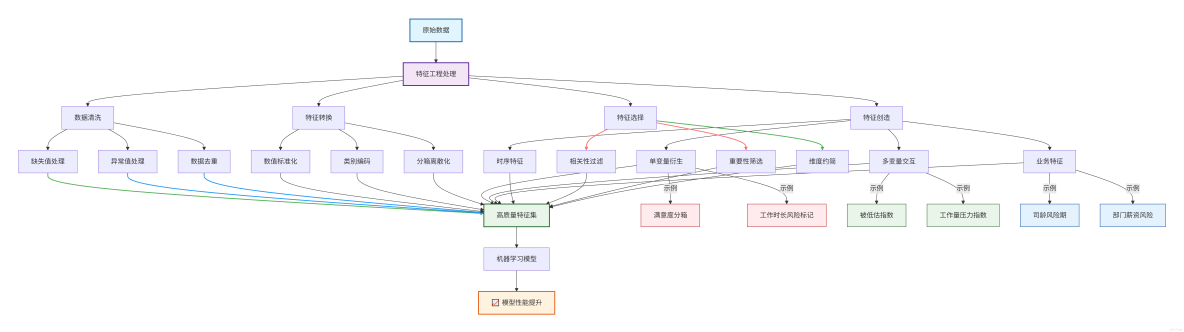
這張圖展示了特徵工程的本質:通過系統性的數據處理和創造性特徵設計,把原始數據"烹飪"成機器學習模型更容易理解和使用的形式。
就像廚師把生食材變成美味佳餚一樣,特徵工程把原始數據變成有價值的分析素材,最終顯著提升模型的表現效果!
九、總結
特徵工程是數據科學項目中至關重要的一環,它通過系統性的分析方法將原始數據轉化為機器學習模型能夠有效利用的高質量特徵。
- 單變量分析是特徵工程的基礎,它如同對每個士兵進行個體審查,通過分析每個特徵的分佈、異常值和缺失情況,確保數據質量並發現初步規律。
- 多變量分析則進一步探索特徵間的相互關係,如同觀察士兵間的協同作戰,通過相關性分析和可視化手段發現隱藏在特徵交互中的複雜模式,為創造組合特徵提供關鍵洞察。
- 而業務分析則是特徵工程的靈魂所在,它將領域專家的知識轉化為模型可理解的語言,如同指揮官基於戰場經驗制定戰略,通過業務邏輯創造具有實際意義和強解釋性的特徵,確保數據分析結果既準確又符合業務實際。
這三個環節相輔相成,共同構成了從數據清洗、模式發現到業務洞察的完整閉環。單變量分析保證數據質量,多變量分析揭示深層關係,業務分析注入領域智慧,最終產出既具預測力又具解釋性的特徵集合,為構建高質量的機器學習模型奠定堅實基礎,真正實現從數據到商業價值的轉化。