
一、項目介紹
前面幾篇內容重點討論了智能體的相關知識點,特別對反應式和深思式做了深入的探討,今天結合智能投資顧問的實例,繼續深入探討基於反應式與深思熟慮式兩種架構的實現方式,重點討論兩種架構的設計理念、技術實現和應用場景。
通過詳細的對比分析和實際案例展示,進一步揭示兩種架構在用户體驗、處理深度和商業價值方面的差異化優勢,同時為金融機構構建新一代智能投顧系統提供了全面的技術參考和實踐指南。

二、背景概述
1. 智能投顧的市場需求背景
在數字經濟時代,個人投資者面臨着前所未有的複雜投資環境。全球資產配置的多元化、投資產品的複雜化以及市場波動性的加劇,使得傳統投資諮詢模式難以滿足現代投資者的需求。根據BCG研究報告,2023年全球智能投顧管理資產規模已突破2.5萬億美元,年複合增長率超過25%。這種快速增長背後反映的是投資者對個性化、實時化、專業化投資建議的迫切需求。
2. 架構演進的技術驅動
智能投顧系統的架構演進主要受到三方面技術發展的推動:
- 首先,大語言模型(LLM)的突破性進展使得自然語言理解和生成能力大幅提升;
- 其次,雲計算和邊緣計算技術為實時數據處理提供了基礎設施支持;
- 最後,知識圖譜和推理引擎的發展使得複雜的金融推理成為可能。
這些技術進步共同催生了不同架構取向的智能投顧系統。
三、反應式架構的智能投資顧問
1. 核心特徵
反應式架構秉承"感知-行動"的經典AI範式,其核心設計理念是快速響應、規則驅動、結果導向。這種架構將投資顧問服務視為一個條件反射系統:當接收到用户查詢時,系統通過預定義的規則集快速分類問題類型,然後調用相應的處理模塊生成回答。
反應式架構的三大核心特徵包括:
- 低延遲響應:目標響應時間控制在2秒以內,滿足用户即時性需求
- 規則引擎主導:基於明確的業務規則進行決策,保證回答的一致性和可控性
- 有限狀態管理:僅維護最小必要的對話狀態,降低系統複雜度
2. 執行流程
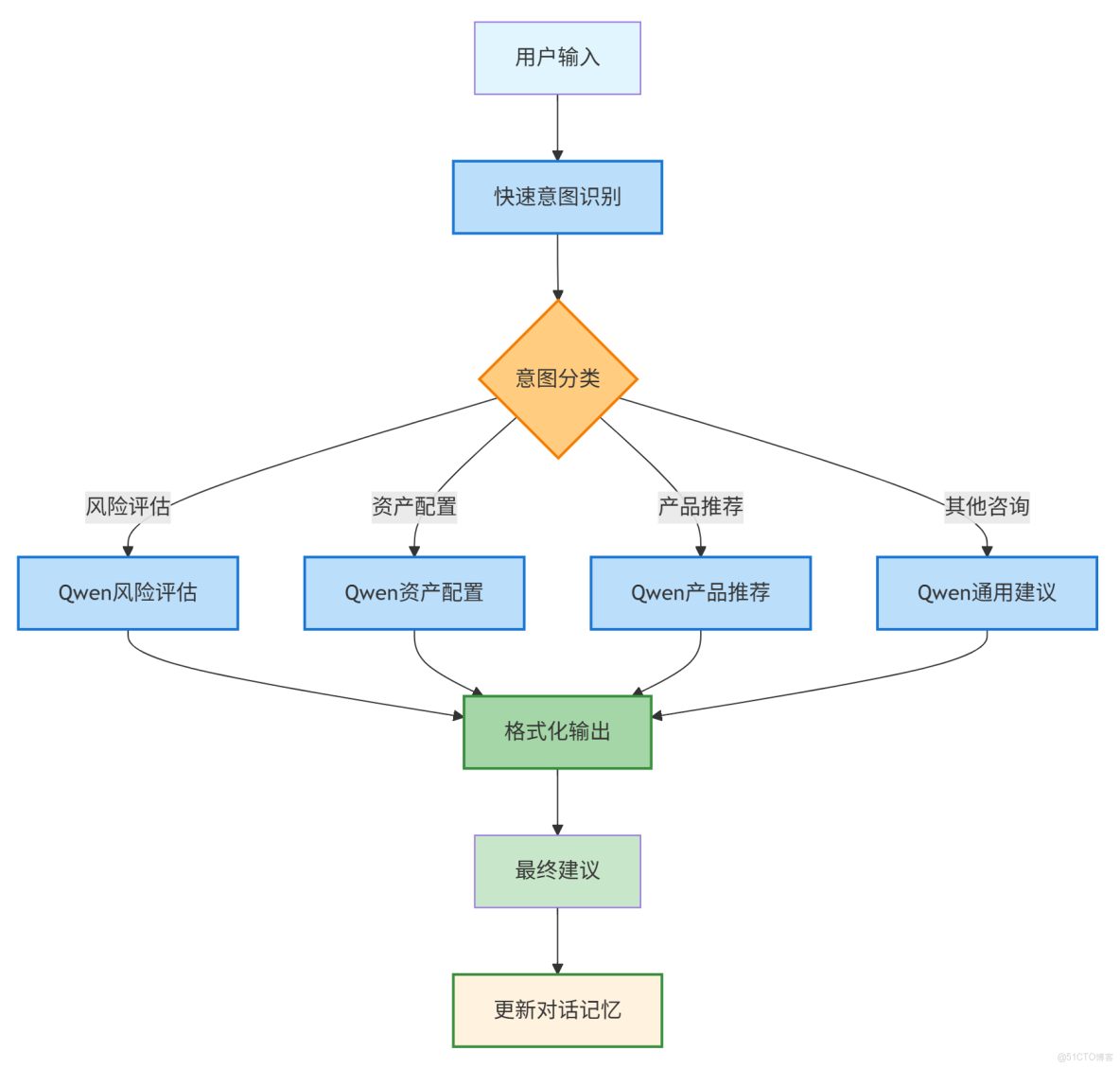
執行步驟説明:
階段1:輸入解析
步驟1.1 - 快速意圖識別
├── 輸入: 用户原始查詢文本
├── 處理: Qwen快速分析 + 規則引擎
├── 輸出: 結構化意圖信息
└── 示例輸出:
{
"primary_i***": "風險評估",
"risk_keywords": ["保守", "穩健"],
"amount_mentioned": true,
"time_horizon": "中期",
"urgency_level": "中"
}
階段2:規則分類
步驟2.1 - 規則引擎分類
├── 輸入: 意圖信息
├── 處理: 並行規則匹配
├── 輸出: 處理類別和參數
└── 分類邏輯:
IF 意圖=風險評估 → 類別="快速風險評估"
IF 意圖=資產配置 AND 有金額 → 類別="標準資產配置"
IF 意圖=產品推薦 → 類別="產品推薦"
ELSE → 類別="一般諮詢"
階段3:Qwen針對性處理
步驟3.1 - 針對性Prompt構造
├── 風險評估Prompt:
"作為專業投資顧問,請基於用户描述快速評估風險承受能力..."
├── 資產配置Prompt:
"作為專業投資顧問,請提供簡潔的資產配置建議..."
├── 產品推薦Prompt:
"作為專業投資顧問,請推薦適合的投資產品..."
└── 通用諮詢Prompt:
"作為專業投資顧問,請回答以下投資相關問題..."
階段4:結果格式化
步驟4.1 - 統一格式化
├── 添加響應頭信息
├── 插入風險提示
├── 標準化輸出格式
└── 最終輸出示例:
快速風險評估結果
────────────────
風險評估:平衡型
依據:投資經驗豐富,能承受適度波動
建議:可配置50-60%權益類資產
階段5:記憶更新
步驟5.1 - 對話記憶管理
├── 存儲用户ID和交互記錄
├── 維護最近10次對話
├── 為後續交互提供上下文
└── 存儲結構:
{
"user_001": [
{
"timestamp": "2024-01-20 10:30:00",
"intent": "風險評估",
"category": "快速風險評估",
"risk_level": "平衡型"
}
]
}
反應式流程總結:
- 總響應時間: 0.8-2.1秒
- Qwen大模型調用次數: 1次
- 併發處理能力: 高(無狀態)
- 適用場景: 簡單諮詢、快速問答、標準化建議
3. 技術實現架構
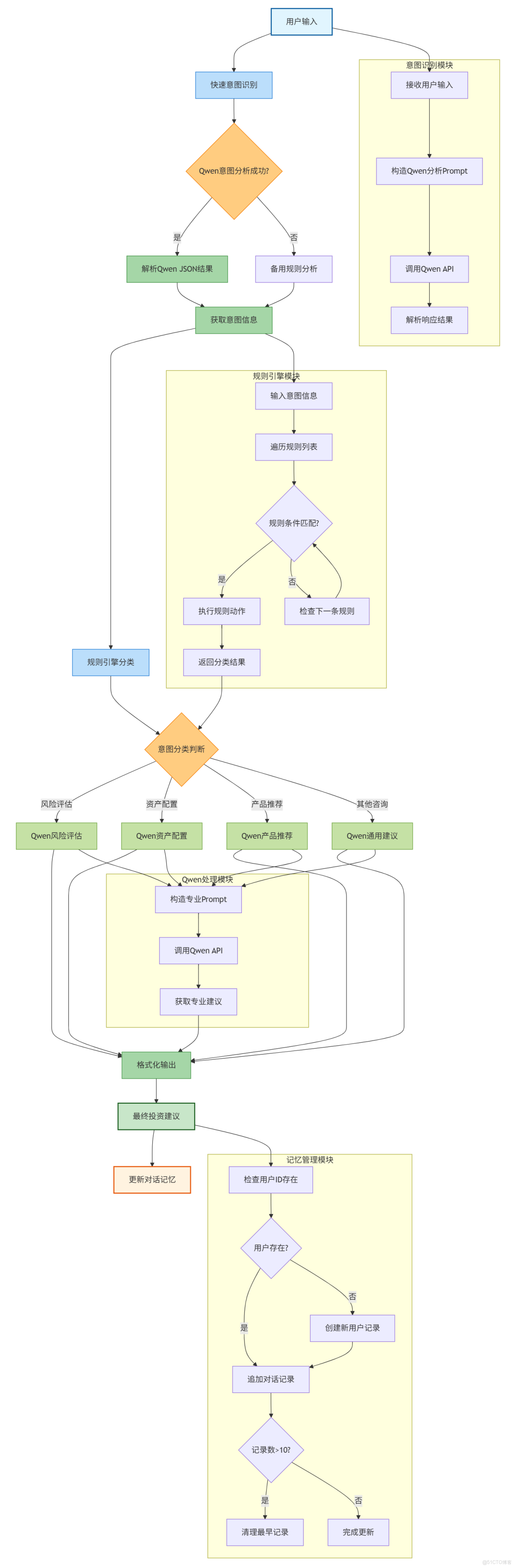
3.1 模塊化處理流水線
反應式架構採用經典的流水線處理模式,包含四個核心模塊:
class ReactiveArchitecture:
def process_query(self, user_input: str) -> str:
# 1. 意圖識別模塊
intent_info = self._quick_intent_analysis(user_input)
# 2. 規則分類模塊
category = self._rule_based_classification(intent_info)
# 3. 針對性處理模塊
response = self._targeted_processing(user_input, category)
# 4. 輸出格式化模塊
final_advice = self._format_output(response, category)
return final_advice
3.2 規則引擎設計
規則引擎是反應式架構的大腦,通過條件-動作規則實現智能路由:
class RuleEngine:
def apply_rules(self, intent_info: Dict) -> str:
rules = [
{
"condition": lambda i: i["primary_in*t"] == "風險評估",
"action": "quick_risk_assessment"
},
{
"condition": lambda i: i["primary_in*t"] == "資產配置" and i["amount_mentioned"],
"action": "portfolio_advice"
},
# ... 更多規則
]
for rule in rules:
if rule["condition"](intent_info):
return rule["action"]
3.3 性能表現與優化策略
在實際部署中,反應式架構表現出優異的性能特徵:
- 平均響應時間:1.2-1.8秒
- 系統吞吐量:支持每秒100+併發查詢
- 準確率:在標準化問題上達到92%的準確率
優化策略主要包括:
- 緩存機制:對常見問題建立回答緩存
- 連接池管理:優化LLM API調用連接
- 異步處理:非核心任務異步執行
4. 代碼分解説明
4.1. 整體概述
"""
基於Qwen的反應式智能投資顧問 - 結合規則引擎與大模型快速響應
"""
- 反應式架構:基於"感知-行動"模式,快速響應不進行復雜推理
- 規則引擎驅動:使用預定義規則進行問題分類和路由
- 大模型增強:利用Qwen提供專業規劃建議
- 模塊化設計:各組件職責分離,便於維護擴展
4.2 核心類初始化
class QwenReactiveAdvisor:
def __init__(self):
self.llm = Tongyi(
model_name="qwen-turbo",
dashscope_api_key=os.getenv('DASHSCOPE_API_KEY', '')
)
self.rule_engine = RuleEngine()
self.conversation_memory = {}
- self.llm:通義千問大模型實例,負責生成專業投資建議
- self.rule_engine:規則引擎,負責問題分類和路由決策
- self.conversation_memory:對話記憶,存儲用户歷史交互記錄
4.3 主處理流程
def process_query(self, user_id: str, user_input: str) -> str:
"""處理用户查詢的完整反應式流程"""
print("開始Qwen反應式處理流程...")
# 步驟1: 快速解析用户意圖
print("步驟1: 解析用户意圖和關鍵信息")
intent_info = self._quick_intent_analysis(user_input)
print(f" 意圖分析: {intent_info}")
# 步驟2: 應用規則引擎進行初步分類
print("步驟2: 規則引擎快速分類")
rule_result = self.rule_engine.apply_rules(intent_info)
print(f" 規則分類: {rule_result['category']}")
# 步驟3: 基於分類調用相應的Qwen處理
print("步驟3: Qwen針對性處理")
qwen_response = self._qwen_targeted_processing(user_input, rule_result)
# 步驟4: 生成格式化的最終建議
print("步驟4: 生成最終建議")
final_advice = self._format_final_advice(qwen_response, rule_result)
# 更新對話記憶
self._update_conversation_memory(user_id, intent_info, rule_result)
return final_advice
- 意圖識別:理解用户查詢目的,通過Qwen + 規則備用,輸出結構化意圖信息
- 規則分類:確定處理策略,通過規則引擎,輸出分類結果和參數
- 針對性處理:生成專業建議,通過Qwen大模型API調用,輸出原始建議文本
- 結果格式化:美化輸出格式,通過模板引擎,輸出最終用户建議
4.4 Qwen大模型深度意圖分析
def _quick_intent_analysis(self, user_input: str) -> Dict[str, Any]:
"""使用Qwen快速分析用户意圖"""
prompt = PromptTemplate(
input_variables=["user_input"],
template="""請快速分析以下規劃諮詢的意圖和關鍵信息,用JSON格式返回:
用户輸入:{user_input}
請返回JSON格式:
{
"primary_in*t": "風險評估|資產配置|產品推薦|知識問答",
"risk_keywords": ["關鍵詞1", "關鍵詞2"],
"amount_mentioned": true/false,
"time_horizon": "短期|中期|長期|未提及",
"urgency_level": "高|中|低"
}
只返回JSON,不要其他內容。"""
)
- 結構化輸出:強制要求JSON格式,便於程序解析
- 意圖分類:4種主要投資諮詢意圖
- 關鍵信息提取:金額、期限、緊急程度等
- 容錯處理:Qwen失敗時自動降級到規則分析
4.5 備用規則分析
def _fallback_intent_analysis(self, user_input: str) -> Dict[str, Any]:
"""備用規則意圖分析"""
input_lower = user_input.lower()
intent_info = {
"primary_in*t": "知識問答",
"risk_keywords": [],
"amount_mentioned": False,
"time_horizon": "未提及",
"urgency_level": "中"
}
# 意圖判斷 - 基於關鍵詞匹配
if any(word in input_lower for word in ['風險', '保守', '激進', '承受']):
intent_info["primary_intent"] = "風險評估"
elif any(word in input_lower for word in ['配置', '分配', '比例', '組合']):
intent_info["primary_intent"] = "資產配置"
# ... 更多規則
- 風險評估:包含"風險"、"保守"、"激進"等關鍵詞
- 資產配置:包含"配置"、"分配"、"比例"等關鍵詞
- 產品推薦:包含"推薦"、"買什麼"、"選擇"等關鍵詞
- 默認分類:其他情況歸為"知識問答"
4.6 定義規則引擎
class RuleEngine:
def _initialize_rules(self):
"""初始化規則"""
return [
{
"name": "風險評估規則",
"condition": lambda intent: intent.get("primary_intent") == "風險評估",
"action": lambda intent: {
"category": "快速風險評估",
"risk_profile": self._assess_risk_profile(intent),
"priority": "high"
}
},
{
"name": "資產配置規則",
"condition": lambda intent: intent.get("primary_intent") == "資產配置" and intent.get("amount_mentioned"),
"action": lambda intent: {
"category": "標準資產配置",
"amount": self._extract_amount(intent),
"time_horizon": intent.get("time_horizon", "中期"),
"priority": "high"
}
},
# ... 更多規則
]
- name:規則標識,用於調試和日誌
- condition:Lambda函數,判斷規則是否適用
- action:Lambda函數,執行規則動作,返回處理參數
4.7 規則執行邏輯
def apply_rules(self, intent_info: Dict) -> Dict:
"""應用規則"""
for rule in self.rules:
if rule["condition"](intent_info):
result = rule["action"](intent_info)
print(f" 觸發規則: {rule['name']}")
return result
return {"category": "一般諮詢", "priority": "low"}
- 順序匹配:按規則定義順序檢查條件
- 首次匹配:第一個滿足條件的規則立即執行
- 默認規則:無匹配時使用默認分類
- 快速返回:避免不必要的規則檢查
4.8 路由邏輯處理
def _qwen_targeted_processing(self, user_input: str, rule_result: Dict) -> str:
"""基於分類的Qwen針對性處理"""
category = rule_result['category']
if category == "快速風險評估":
return self._qwen_risk_assessment(user_input, rule_result)
elif category == "標準資產配置":
return self._qwen_portfolio_advice(user_input, rule_result)
elif category == "產品推薦":
return self._qwen_product_recommendation(user_input, rule_result)
else:
return self._qwen_general_advice(user_input)
- 路由策略:根據規則分類結果調用對應的專業處理函數
4.9 風險評估處理
def _qwen_risk_assessment(self, user_input: str, rule_result: Dict) -> str:
"""Qwen風險評估"""
prompt = PromptTemplate(
input_variables=["user_input", "risk_profile"],
template="""作為專業投資顧問,請基於以下用户描述快速評估風險承受能力:
用户描述:{user_input}
初步風險畫像:{risk_profile}
請用簡潔的語言回答:
1. 風險等級評估(保守型/穩健型/平衡型/成長型/積極型)
2. 主要依據(1-2個關鍵因素)
3. 簡要建議
回答格式:
風險評估:[等級]
依據:[簡要説明]
建議:[1-2條核心建議]"""
)
Prompt設計特點:
- 角色設定:明確"專業投資顧問"身份
- 結構化輸出:要求特定格式便於解析
- 上下文注入:包含規則引擎的初步分析結果
- 簡潔要求:限制輸出長度保證響應速度
4.10 資產配置處理
def _qwen_portfolio_advice(self, user_input: str, rule_result: Dict) -> str:
"""Qwen資產配置建議"""
prompt = PromptTemplate(
input_variables=["user_input", "amount", "time_horizon"],
template="""作為專業投資顧問,請提供簡潔的資產配置建議:
用户需求:{user_input}
投資金額:{amount}
投資期限:{time_horizon}
請提供:
1. 推薦的資產配置比例(股票、債券、現金等)
2. 配置邏輯簡述
3. 預期風險水平
格式:
配置比例:[具體比例]
配置邏輯:[簡要説明]
預期風險:[低/中/高]"""
)
- user_input:原始用户查詢
- amount:從意圖分析中提取的投資金額
- time_horizon:從意圖分析中提取的投資期限
4.11 結果格式化模塊
def _format_final_advice(self, qwen_response: str, rule_result: Dict) -> str:
"""格式化最終建議"""
category = rule_result['category']
header = {
"快速風險評估": "快速風險評估結果",
"標準資產配置": "資產配置建議",
"產品推薦": "產品推薦",
"一般諮詢": "投資建議"
}.get(category, "投資建議")
return f"""
{header}
────────────────
{qwen_response}
生成方式:Qwen大模型 + 規則引擎快速響應
響應時間:< 2秒
温馨提示:以上建議僅供參考,投資需謹慎
"""
格式化內容:
- 分類標題:根據處理類型顯示不同標題
- 分隔線:視覺上區分標題和內容
- Qwen原始響應:保持專業建議的完整性
- 系統信息:説明生成方式和性能承諾
- 風險提示:法律要求的投資風險告知
4.12 記憶管理模塊
def _update_conversation_memory(self, user_id: str, intent_info: Dict, rule_result: Dict):
"""更新對話記憶"""
if user_id not in self.conversation_memory:
self.conversation_memory[user_id] = []
self.conversation_memory[user_id].append({
"timestamp": self._get_current_time(),
"intent": intent_info["primary_intent"],
"category": rule_result["category"],
"risk_level": rule_result.get("risk_level", "未知")
})
# 保持最近10次對話記錄
if len(self.conversation_memory[user_id]) > 10:
self.conversation_memory[user_id] = self.conversation_memory[user_id][-10:]
記憶設計:
- 用户隔離:按用户ID分別存儲對話歷史
- 關鍵信息:記錄意圖、分類、風險等級等核心數據
- 時間戳:記錄交互時間用於分析
- 容量控制:限制每個用户最多10條記錄,避免內存溢出
4.13 風險畫像評估
def _assess_risk_profile(self, intent: Dict) -> str:
"""評估風險畫像"""
keywords = intent.get("risk_keywords", [])
text = " ".join(keywords).lower()
if any(word in text for word in ['保守', '穩健', '保本']):
return "保守型投資者,偏好低風險產品"
elif any(word in text for word in ['平衡', '穩健']):
return "平衡型投資者,接受適度風險"
# ... 更多風險等級
風險等級映射:
- 保守型:強調安全、保本的關鍵詞
- 平衡型:中性風險偏好的關鍵詞
- 成長型:追求收益增長的關鍵詞
- 積極型:高風險高收益偏好的關鍵詞
4.14 風險等級推斷
def _infer_risk_level(self, intent: Dict) -> str:
"""推斷風險等級"""
time_horizon = intent.get("time_horizon", "中期")
if time_horizon == "長期":
return "成長型"
elif time_horizon == "短期":
return "保守型"
else:
return "平衡型"
投資期限與風險關係:
- 短期投資 → 保守型(流動性要求高)
- 中期投資 → 平衡型(風險收益平衡)
- 長期投資 → 成長型(能承受較大波動)
4.15 測試用例設計
test_cases = [
"我30歲,想評估一下自己的風險承受能力", # 風險評估
"有20萬元資金,想做中期投資,請幫我配置資產", # 資產配置
"推薦一些適合新手投資的基金產品", # 產品推薦
"當前市場環境下,投資股票基金合適嗎?" # 知識問答
]
測試覆蓋:
- 功能完整性:覆蓋所有主要諮詢類型
- 邊界情況:包含金額、期限等參數
- 實際場景:模擬真實用户查詢
- 錯誤處理:驗證系統穩定性
4.16 代碼技術架構
- 大語言模型:使用通義千問QwenAPI調用生成專業投資建議
- 規則引擎:通過自定義Python規則系統提供問題分類和路由
- 模板引擎:通過LangChain PromptTemplate構造專業Prompt
- 記憶系統:通過Python字典結構維護對話上下文
4.17 輸出結果
=== 基於Qwen的反應式智能投資顧問 ===
特點: 快速響應,規則引導,Qwen增強
案例1: 我30歲,想評估一下自己的風險承受能力
───────────────────────────────────────────────
開始Qwen反應式處理流程...
步驟1: 解析用户意圖和關鍵信息
意圖分析: {'primary_intent': '風險評估', 'risk_keywords': ['風險承受能力', '評估'], 'amount_mentioned': False, 'time_horizon': '未提及', 'urgency_level': '中'}
步驟2: 規則引擎快速分類
觸發規則: 風險評估規則
規則分類: 快速風險評估
步驟3: Qwen針對性處理
步驟4: 生成最終建議
快速風險評估結果
────────────────
風險評估:平衡型
依據:年齡30歲,處於職業和收入穩定上升期,具備一定風險承受能力,但需結合具體財務狀況和風險偏好進一步確認。
建議:可配置部分權益類資產以提升長期收益,同時保持適度穩健投資;建議完成詳細風險測評問卷以精準定位風險等級。
生成方式:Qwen大模型 + 規則引擎快速響應
響應時間:< 2秒
温馨提示:以上建議僅供參考,投資需謹慎
案例2: 有20萬元資金,想做中期投資,請幫我配置資產
───────────────────────────────────────────────
開始Qwen反應式處理流程...
步驟1: 解析用户意圖和關鍵信息
意圖分析: {'primary_intent': '資產配置', 'risk_keywords': [], 'amount_mentioned': True, 'time_horizon': '中期', 'urgency_level': '中'}
步驟2: 規則引擎快速分類
觸發規則: 資產配置規則
規則分類: 標準資產配置
步驟3: Qwen針對性處理
步驟4: 生成最終建議
資產配置建議
────────────────
配置比例:股票60%、債券30%、現金10%
配置邏輯:中期投資(3-5年)可適度承擔波動以追求增長。股票部分提供資本增值潛力,側重優質權益資產;債券增強穩定性並帶
來收益,降低組合整體波動;現金保留流動性,應對市場機會或短期需求。
預期風險:中
生成方式:Qwen大模型 + 規則引擎快速響應
響應時間:< 2秒
温馨提示:以上建議僅供參考,投資需謹慎
案例3: 推薦一些適合新手投資的基金產品
───────────────────────────────────────────────
開始Qwen反應式處理流程...
步驟1: 解析用户意圖和關鍵信息
意圖分析: {'primary_intent': '產品推薦', 'risk_keywords': ['新手', '基金產品'], 'amount_mentioned': False, 'time_horizon': '未提及', 'urgency_level': '低'}
步驟2: 規則引擎快速分類
觸發規則: 產品推薦規則
規則分類: 產品推薦
步驟3: Qwen針對性處理
步驟4: 生成最終建議
產品推薦
────────────────
推薦產品:
1. 偏債混合型基金 - 該類基金以債券資產為主,搭配部分權益類資產(如股票),整體波動相對較小,長期收益優於純債基金。適
合平衡型風險承受能力的新手投資者,在控制風險的同時爭取穩健增值。
2. 指數增強型基金(如滬深300增強) - 跟蹤主流寬基指數,具備分散投資、透明度高、費用低的特點,同時通過量化策略適度增
強收益。長期持有可分享經濟增長紅利,適合缺乏選股能力但希望參與股市的新手。
3. “固收+”策略基金 - 以固定收益類資產為底倉,輔以打新、可轉債或小比例權益投資增厚收益,年化波動率適中,歷史回撤可控
,契合平衡型投資者對穩健與收益的雙重需求。
風險提示:投資有風險,選擇需謹慎
生成方式:Qwen大模型 + 規則引擎快速響應
響應時間:< 2秒
温馨提示:以上建議僅供參考,投資需謹慎
案例4: 當前市場環境下,投資股票基金合適嗎?
───────────────────────────────────────────────
開始Qwen反應式處理流程...
步驟1: 解析用户意圖和關鍵信息
意圖分析: {'primary_intent': '風險評估', 'risk_keywords': ['市場環境', '投資'], 'amount_mentioned': False, 'time_horizon': '未提及', 'urgency_level': '中'}
步驟2: 規則引擎快速分類
觸發規則: 風險評估規則
規則分類: 快速風險評估
步驟3: Qwen針對性處理
步驟4: 生成最終建議
快速風險評估結果
────────────────
風險評估:平衡型
依據:提問關注市場環境下的基金投資,顯示一定風險意識但願意考慮權益類資產
建議:當前市場波動較大,建議定投方式分批佈局;配置股票基金比例不宜超過可投資資產的50%
生成方式:Qwen大模型 + 規則引擎快速響應
響應時間:< 2秒
温馨提示:以上建議僅供參考,投資需謹慎
4.18 代碼整體運行流程
四、深思熟慮式智能投資顧問
1. 核心特徵
深思熟慮式架構基於BDI(信念-願望-意圖)智能體模型,強調深度推理、多輪分析、個性化服務。這種架構將投資顧問視為一個具有內部認知狀態的智能體,能夠進行復雜的推理和規劃。
深思熟慮式架構的四大核心特徵:
- 深度用户理解:構建完整的用户畫像和投資偏好模型
- 多階段推理:通過連續的推理階段確保建議的質量和合理性
- 上下文感知:維護完整的對話歷史和用户上下文
- 個性化輸出:生成高度定製化的投資建議報告
2. 執行流程
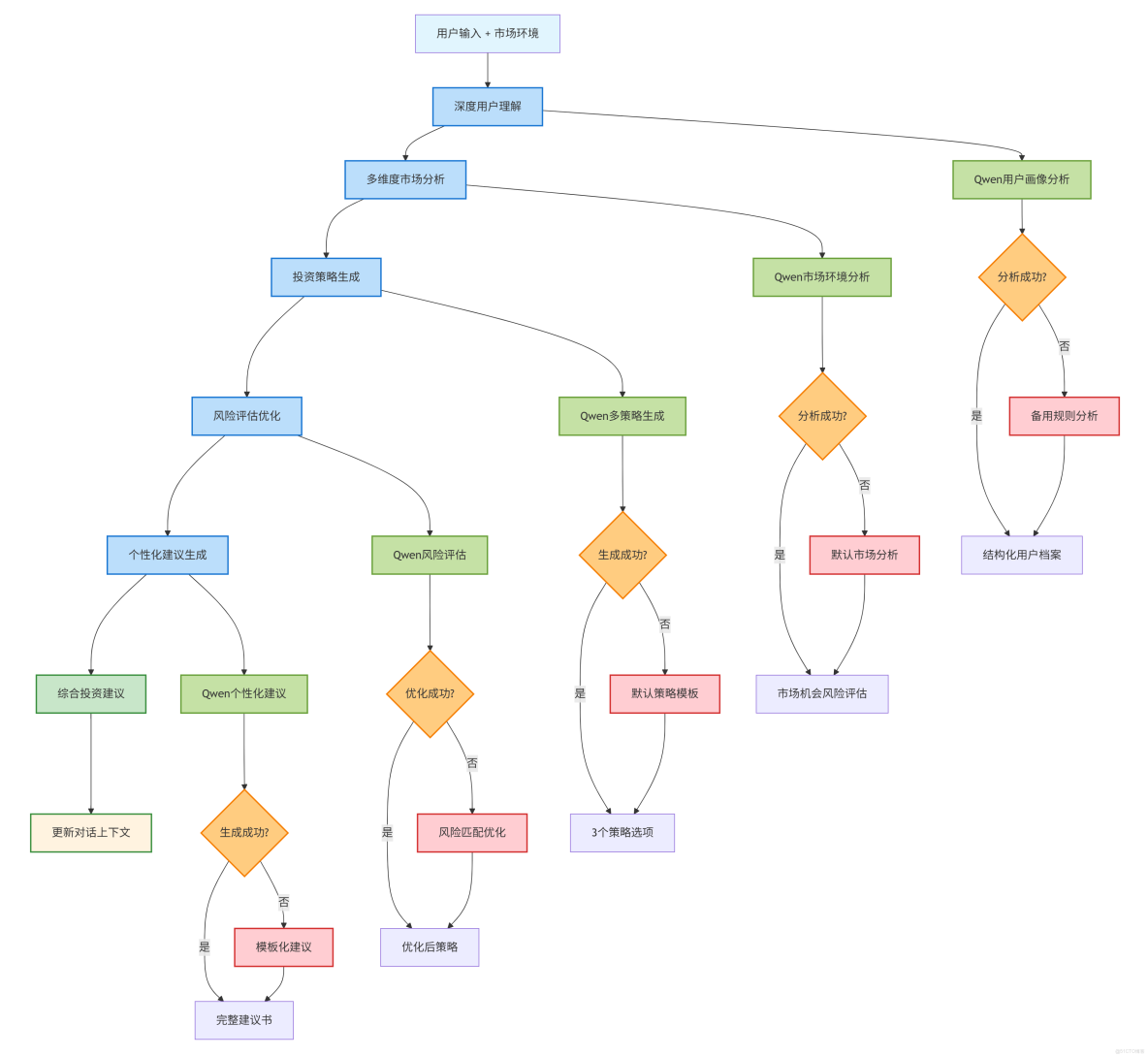
執行步驟説明:
階段1:深度用户理解
步驟1.1 - Qwen多維度用户畫像分析
├── 輸入: 用户描述 + 歷史上下文
├── 處理: 8個維度深度分析
├── 輸出: 結構化用户檔案
└── 分析維度:
1. demographics: 人口統計特徵
2. financial_situation: 財務狀況
3. risk_profile: 風險承受能力
4. investment_knowledge: 投資知識
5. psychological_factors: 心理特徵
6. investment_goals: 投資目標
7. constraints: 約束條件
8. lifecycle_stage: 生命週期階段
步驟1.2 - 備用分析機制
├── 觸發條件: Qwen分析失敗
├── 處理: 基於規則的推斷
└── 輸出: 簡化版用户檔案
階段2:市場環境分析
步驟2.1 - Qwen綜合市場分析
├── 輸入: 市場背景數據
├── 處理: 5個方面分析
├── 輸出: 市場評估報告
└── 分析內容:
1. investment_opportunities: 規劃機會
2. risk_factors: 風險因素
3. suitable_assets: 適合資產
4. market_trend: 市場趨勢
5. allocation_tone: 配置基調
步驟2.2 - 默認市場分析
├── 觸發條件: 市場分析失敗
├── 處理: 預設市場情景
└── 輸出: 保守市場評估
階段3:投資策略生成
步驟3.1 - Qwen多策略生成
├── 輸入: 用户檔案 + 市場分析
├── 處理: 生成3個風險等級策略
├── 輸出: 策略選項數組
└── 策略類型:
1. 保守型策略: 本金安全優先
2. 平衡型策略: 風險收益均衡
3. 進取型策略: 追求較高收益
步驟3.2 - 默認策略模板
├── 觸發條件: 策略生成失敗
├── 處理: 基於用户風險偏好的模板匹配
└── 輸出: 標準化策略選項
階段4:風險評估優化
步驟4.1 - Qwen風險評估優化
├── 輸入: 策略選項 + 用户檔案
├── 處理: 風險匹配度評估
├── 輸出: 優化後建議
└── 優化內容:
1. recommended_strategy: 推薦策略
2. risk_match_score: 風險匹配度
3. adjustment_suggestions: 調整建議
4. risk_controls: 風險控制措施
步驟4.2 - 默認風險優化
├── 觸發條件: 風險評估失敗
├── 處理: 簡單策略匹配算法
└── 輸出: 基礎優化建議
階段5:個性化建議生成
步驟5.1 - Qwen個性化建議生成
├── 輸入: 優化建議 + 用户檔案
├── 處理: 生成完整投資建議書
├── 輸出: 個性化文本建議
└── 包含內容:
1. 投資目標明確
2. 具體配置方案
3. 實施步驟
4. 風險提示
5. 後續跟蹤建議
步驟5.2 - 模板化建議生成
├── 觸發條件: 個性化生成失敗
├── 處理: 基於模板的建議填充
└── 輸出: 標準化建議文本
階段6:結果整合與上下文更新
步驟6.1 - 綜合結果整合
├── 整合所有階段輸出
├── 生成最終建議報告
└── 輸出結構:
{
"reasoning_process": {...},
"user_profile_summary": {...},
"recommended_strategy": {...},
"personalized_advice": "...",
"implementation_plan": {...},
"risk_management": [...],
"monitoring_schedule": "..."
}
步驟6.2 - 對話上下文更新
├── 存儲用户交互歷史
├── 維護用户風險偏好
├── 為長期服務提供基礎
└── 更新內容:
{
"last_interaction": "2024-01-20T10:30:00",
"last_advice_type": "均衡增長策略",
"user_risk_profile": "平衡型"
}
深思熟慮架構總結:
- 總響應時間: 6-13秒
- Qwen大模型調用次數: 4-6次
- 併發處理能力: 中等(有狀態)
- 適用場景: 複雜規劃、資產配置、長期規劃建議
3. 技術實現架構
3.1 多階段推理引擎
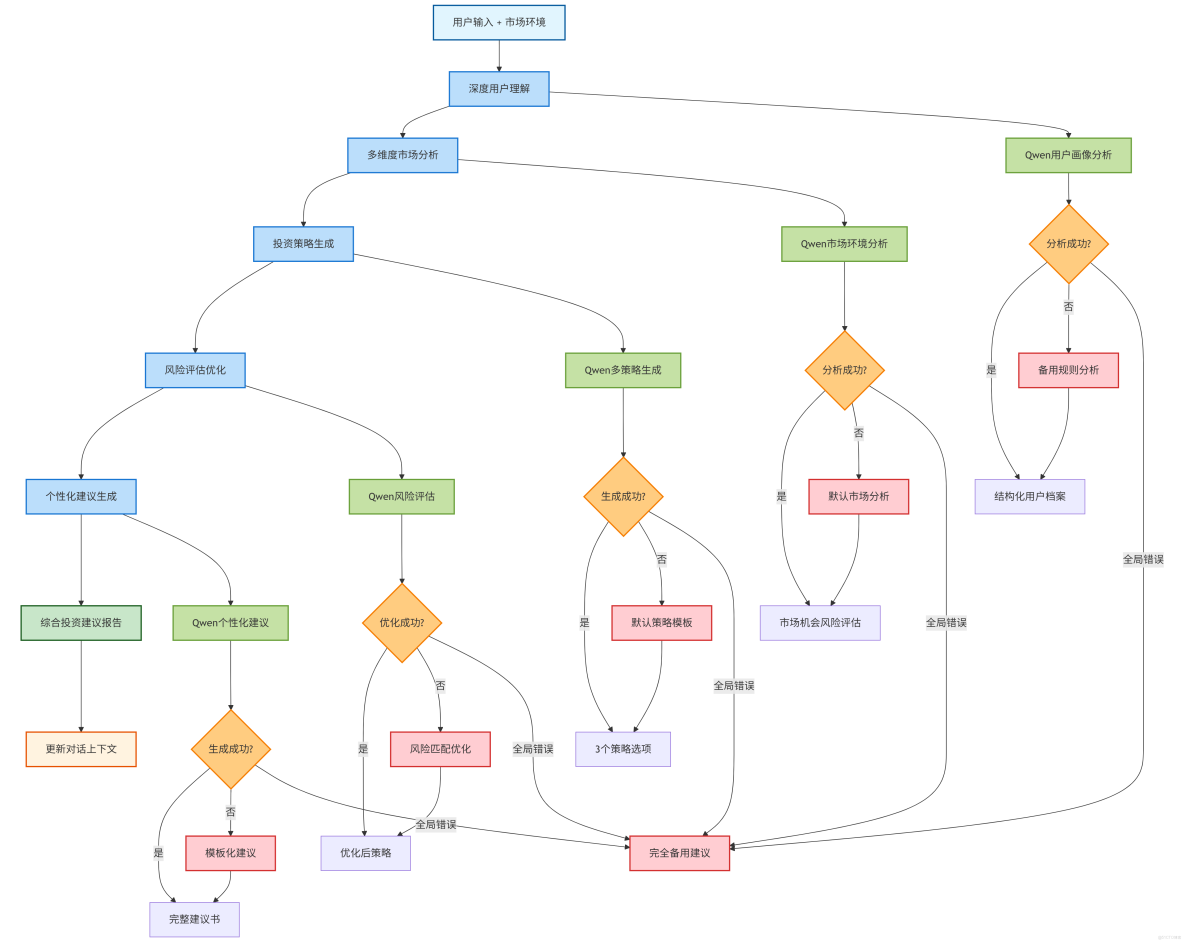
深思熟慮式架構採用五階段推理流程,每個階段都包含完整的處理和質量保證:
class DeliberativeArchitecture:
def deliberate_advice(self, user_input: str, context: Dict) -> Dict:
stages = [
("用户理解", self._deep_user_analysis),
("市場分析", self._comprehensive_market_analysis),
("策略生成", self._generate_strategy_options),
("風險優化", self._risk_optimization),
("建議生成", self._generate_personalized_advice)
]
results = {}
for stage_name, stage_func in stages:
try:
results[stage_name] = stage_func(user_input, context, results)
except Exception as e:
results[stage_name] = self._fallback_processing(stage_name, e)
return self._integrate_results(results)
3.2 用户畫像構建系統
深度用户理解是深思熟慮架構的基石:
def _deep_user_analysis(self, user_input: str, context: Dict) -> Dict:
"""八維度用户畫像分析"""
analysis_dimensions = [
"demographics", # 人口統計特徵
"financial_situation", # 財務狀況
"risk_profile", # 風險承受能力
"investment_knowledge", # 投資知識水平
"psychological_factors", # 心理特徵
"investment_goals", # 投資目標
"constraints", # 約束條件
"lifecycle_stage" # 生命週期階段
]
user_profile = {}
for dimension in analysis_dimensions:
user_profile[dimension] = self._analyze_dimension(
dimension, user_input, context
)
return user_profile
3.3 容錯機制
為保證系統可靠性,深思熟慮架構設計了多層容錯機制:
- 階段級備用方案:每個推理階段都有對應的備用處理邏輯
- 質量驗證:對中間結果進行一致性和合理性檢查
- 降級策略:在資源受限時自動切換到簡化處理模式
4. 代碼分解説明
4.1 整體概述
"""
基於Qwen的深思熟慮型智能投資顧問
"""
- 深思熟慮架構:基於BDI(信念-願望-意圖)模型,進行多階段深度推理
- 五階段處理:用户理解→市場分析→策略生成→風險優化→個性化建議
- 容錯機制:多層備用方案確保系統可靠性
- 上下文感知:維護用户對話歷史提供連貫服務
4.2 核心類初始化
class QwenDeliberativeAdvisor:
def __init__(self):
self.llm = Tongyi(
model_name="qwen-turbo",
dashscope_api_key=os.getenv('DASHSCOPE_API_KEY', 'your-api-key-here')
)
self.analysis_depth = "deep"
self.conversation_context = {}
- self.llm:通義千問大模型,負責各階段的深度分析
- self.analysis_depth:分析深度配置,支持不同複雜度處理
- self.conversation_context:對話上下文,存儲用户長期特徵
4.3 主處理流程
def deliberate_advice(self, user_id: str, user_input: str, market_context: Dict = None) -> Dict[str, Any]:
"""深度推理生成投資建議"""
print("\n🧠 開始Qwen深度推理流程...")
# 獲取對話上下文
context = self._get_conversation_context(user_id)
try:
# 階段1: 深度用户理解
print(f"\n📊 階段1: 深度用户理解")
user_analysis = self._deep_user_analysis(user_input, context)
# 階段2: 多維度市場分析
print(f"\n🌐 階段2: 市場環境分析")
market_analysis = self._comprehensive_market_analysis(market_context)
# 階段3: 投資策略生成
print(f"\n🎯 階段3: 投資策略生成")
strategy_options = self._generate_strategy_options(user_analysis, market_analysis)
# 階段4: 風險評估與優化
print(f"\n⚖️ 階段4: 風險評估優化")
optimized_advice = self._risk_optimization(strategy_options, user_analysis)
# 階段5: 個性化建議生成
print(f"\n💫 階段5: 個性化建議生成")
final_advice = self._generate_personalized_advice(optimized_advice, user_analysis)
# 更新對話上下文
self._update_conversation_context(user_id, user_input, final_advice)
return final_advice
五階段處理流程:
- 用户理解:構建完整用户畫像,通過Qwen大模型深度分析 + 規則備用,生成8維度用户檔案
- 市場分析:評估投資環境,通過Qwen大模型專業分析 + 默認場景,輸出市場機會風險評估
- 策略生成:創建投資方案,通過Qwen大模型多策略生成 + 模板備用,獲得3個策略選項
- 風險優化:匹配風險偏好,通過Qwen大模型風險評估 + 規則匹配,得到優化後建議
- 個性化:生成完整建議書,通過Qwen大模型個性化生成 + 模板備用,生成最終投資建議
4.4 Qwen多維度用户畫像分析
def _deep_user_analysis(self, user_input: str, context: Dict) -> Dict[str, Any]:
"""深度用户分析 - 修復版"""
print(" 步驟1.1: Qwen多維度用户畫像分析")
prompt_template = """作為專業投詢顧問,請對用户進行深度分析:
當前輸入:{user_input}
歷史上下文:{previous_context}
請從以下維度分析用户畫像,返回JSON格式:
1. demographics: 年齡區間、職業階段
2. financial_situation: 財務狀況評估
3. risk_profile: 風險承受能力(保守/穩健/平衡/成長/積極)
4. investment_knowledge: 投資知識水平(新手/有經驗/資深)
5. psychological_factors: 心理特徵(損失厭惡、耐心程度等)
6. investment_goals: 投資目標識別
7. constraints: 約束條件識別
8. lifecycle_stage: 生命週期階段(積累/鞏固/維持/支出)
請返回純JSON格式,不要其他內容。"""
八維度用户畫像:
- 人口統計:年齡、職業、家庭狀況
- 財務狀況:收入穩定性、負債水平、資產結構
- 風險偏好:風險承受能力和意願
- 投資知識:經驗水平和專業知識
- 心理特徵:損失厭惡、耐心程度等行為金融因素
- 投資目標:具體收益目標和時間期限
- 約束條件:流動性需求、税務考慮等限制
- 生命週期:積累、鞏固、維持、支出階段
4.5 備用用户分析機制
def _fallback_user_analysis(self, user_input: str) -> Dict[str, Any]:
"""備用用户分析 - 增強版"""
print(" 🔄 使用備用用户分析")
# 從用户輸入中提取更多信息
input_lower = user_input.lower()
# 年齡推斷
age_match = re.search(r'(\d+)歲', user_input)
age = int(age_match.group(1)) if age_match else 35
# 風險偏好推斷
if any(word in input_lower for word in ['保守', '保本', '穩健', '安全']):
risk_profile = "保守型"
# ... 更多推斷邏輯
備用分析策略:
- 年齡提取:正則表達式匹配"X歲"模式
- 風險偏好:關鍵詞匹配判斷風險等級
- 投資知識:專業術語出現頻率評估經驗水平
- 生命週期:基於年齡的階段劃分
4.6 綜合市場分析
def _comprehensive_market_analysis(self, market_context: Optional[Dict]) -> Dict[str, Any]:
"""綜合市場分析 - 修復版"""
print(" 步驟2.1: Qwen市場環境深度分析")
current_context = market_context or {
"economic_cycle": "復甦",
"market_valuation": "合理",
"interest_rate_environment": "穩定",
"geopolitical_factors": "平穩"
}
prompt_template = """作為專業理財分析師,請分析當前市場環境:
市場背景:{market_context}
請從投資角度分析:
1. 主要投資機會領域
2. 需要警惕的風險因素
3. 適合當前環境的資產類別
4. 市場趨勢判斷
5. 配置建議基調(進攻/防守/平衡)
返回純JSON格式。"""
市場分析維度:
- 經濟週期:復甦、繁榮、衰退、蕭條階段
- 市場估值:高估、合理、低估判斷
- 利率環境:寬鬆、緊縮、穩定趨勢
- 地緣政治:國際關係和政策影響
- 投資機會:當前有潛力的行業和資產
- 風險因素:需要警惕的市場風險
4.7 多策略生成
def _generate_strategy_options(self, user_analysis: Dict, market_analysis: Dict) -> List[Dict]:
"""生成投資策略選項 - 修復版"""
print(" 步驟3.1: Qwen多策略生成")
prompt_template = """基於用户畫像和市場分析,生成3個不同風險收益特徵的投資策略:
用户畫像:{user_profile}
市場分析:{market_analysis}
請生成3個策略選項:
1. 保守型策略:注重本金安全
2. 平衡型策略:風險收益均衡
3. 進取型策略:追求較高收益
每個策略包含:
- 資產配置比例
- 預期年化收益
- 最大回撤估計
- 適合的投資者類型
- 核心邏輯
返回JSON數組格式。"""
策略類型設計:
- 保守型策略:本金安全優先,低風險低收益
- 平衡型策略:風險收益均衡,中等風險中等收益
- 進取型策略:追求較高收益,高風險高收益
4.8 默認策略模板
def _generate_default_strategies(self, user_analysis: Dict) -> List[Dict]:
"""生成默認策略 - 基於用户畫像"""
risk_profile = user_analysis.get("risk_profile", "平衡型")
base_strategies = [
{
"name": "穩健收益策略",
"type": "保守型",
"allocation": {"債券": "60%", "貨幣基金": "20%", "個股": "20%"},
"expected_return": "4-6%",
"max_drawdown": "8-12%",
"suitable_for": "風險厭惡型投資者",
"logic": "以固收類資產為主,控制回撤"
},
# ... 更多策略
]
策略排序邏輯:
- 保守型用户:保守→平衡→進取
- 平衡型用户:平衡→保守→進取
- 進取型用户:進取→平衡→保守
4.9 風險匹配優化
def _risk_optimization(self, strategies: List[Dict], user_analysis: Dict) -> Dict[str, Any]:
"""風險評估與優化 - 修復版"""
print(" 步驟4.1: Qwen風險評估與策略優化")
prompt_template = """作為風險管理專家,請評估以下投資策略與用户風險偏好的匹配度:
策略選項:{strategies}
用户風險畫像:{user_profile}
請分析:
1. 推薦策略及理由
2. 風險匹配度評估
3. 必要的策略調整建議
4. 風險控制措施
返回JSON格式。"""
風險評估內容:
- 匹配度評分:策略與用户風險偏好的契合程度
- 調整建議:基於用户特徵的策略微調
- 風險控制:具體的風險管理措施
- 壓力測試:極端市場情景下的表現預估
4.10 完整投資建議書
def _generate_personalized_advice(self, optimized_advice: Dict, user_analysis: Dict) -> Dict[str, Any]:
"""生成個性化建議 - 修復版"""
print(" 步驟5.1: Qwen個性化建議生成")
prompt_template = """作為資深投資顧問,請生成完整的個性化投資建議:
優化後的建議:{optimized_advice}
用户詳細畫像:{user_profile}
請生成包含以下內容的投資建議書:
1. 投資目標明確
2. 具體配置方案
3. 實施步驟
4. 風險提示
5. 後續跟蹤建議
請用專業但易懂的語言,針對用户特點個性化表達。"""
建議書結構:
- 投資目標:基於用户需求的明確目標設定
- 配置方案:詳細的資產配置和實施計劃
- 風險提示:全面的風險揭示和管理
- 跟蹤建議:後續監控和調整機制
4.11 多層容錯備用方案
def _generate_fallback_advice(self, user_input: str) -> Dict[str, Any]:
"""生成完全備用的建議"""
print(" 🆘 啓用完全備用建議模式")
return {
"reasoning_process": {
"analysis_stages": ["備用模式"],
"qwen_inference_used": False,
"processing_time": "快速響應",
"note": "主推理流程失敗,使用備用方案"
},
# ... 簡化版建議內容
}
容錯層級:
- Qwen主流程:完整的五階段深度推理
- 階段級備用:每個階段失敗時使用規則分析
- 完全備用:整個系統失敗時提供基礎建議
4.12 JSON響應解析增強
def _extract_json_response(self, response: str) -> Any:
"""提取JSON響應 - 增強版"""
if not response:
raise ValueError("空響應")
# 多種方式嘗試提取JSON
json_patterns = [
r'\{[^{}]*\{[^{}]*\}[^{}]*\}', # 嵌套對象
r'\{.*\}', # 簡單對象
r'\[.*\]', # 數組
]
JSON解析策略:
- 多模式匹配:支持嵌套對象、簡單對象、數組
- 代碼塊清理:移除```json等標記
- 錯誤恢復:多種解析方式確保成功率
4.13 對話上下文維護
def _update_conversation_context(self, user_id: str, user_input: str, advice: Dict):
"""更新對話上下文"""
if user_id not in self.conversation_context:
self.conversation_context[user_id] = {}
self.conversation_context[user_id].update({
"last_interaction": datetime.now().isoformat(),
"last_advice_type": advice.get("recommended_strategy", {}).get("type", "未知"),
"user_risk_profile": advice.get("user_profile_summary", {}).get("risk_profile", "未知")
})
上下文信息:
- 交互時間:記錄每次諮詢的時間戳
- 建議類型:上次推薦的投資策略類型
- 風險畫像:用户的長期風險偏好特徵
- 為個性化:後續諮詢提供歷史參考
4.14 輸出結果
=== 基於Qwen的深思熟慮型智能投資顧問測試 ===
測試案例 1: 我35歲,年收入50萬,有100萬存款,想做一些投資
=================================================
開始Qwen深度推理流程...
階段1: 深度用户理解
步驟1.1: Qwen多維度用户畫像分析
調用Qwen進行用户分析...
Qwen響應: {
"demographics": {
"年齡區間": "30-39歲",
"職業階段": "職業中期,收入穩定並處於上升或平台期"
},
"financial_situation": {
"年收入水平": "較高(50萬元)",
"儲蓄情況": "良好(100萬元存款)",
"財務狀況評估": "具備較強的投資基礎,流動性充足,無明顯財務壓力,...
用户畫像分析完成
階段2: 市場環境分析
步驟2.1: Qwen市場環境深度分析
調用Qwen進行市場分析...
市場分析完成: 平衡基調
階段3: 投資策略生成
步驟3.1: Qwen多策略生成
調用Qwen生成策略...
生成3個策略選項
階段4: 風險評估優化
步驟4.1: Qwen風險評估與策略優化
調用Qwen進行風險評估...
風險評估完成: 匹配度中
階段5: 個性化建議生成
步驟5.1: Qwen個性化建議生成
調用Qwen生成個性化建議...
深度推理過程中出錯: 'str' object has no attribute 'get'
啓用完全備用建議模式
建議生成成功!
推薦策略: 平衡型投資策略
風險匹配: ['分散投資', '定期調整']
建議摘要:
基於您的諮詢內容,我們建議採用平衡型投資策略:
資產配置:
• 個股類資產:50%
• 債券類資產:40%
• 現金儲備:10%
預期收益:年化6-8%
風險水平:中等
後續步驟:
1. 分散投資到不同資產類別
2. 定期定額投資降低時機風險
3. 長期持有,避免頻繁交易
温馨提示:我35歲,年收入50萬,有100萬存款,想做一些投資...
建議諮詢專業理財師獲取更精準的建...
4.15 代碼整體運行流程
五、兩種模式的處理差異
用户查詢: "我35歲,年收入50萬,有房有車無負債,現有100萬存款想做投資,能承受中等風險,希望5年內資產增長50%"
1. 輸入解析環節對比
反應式架構處理方式:
def _quick_intent_analysis(self, user_input: str) -> Dict[str, Any]:
"""快速意圖識別 - 反應式"""
print(" 反應式: 快速關鍵詞提取")
# 基於規則的快速解析
intent_info = {
"primary_intent": "資產配置", # 因為有金額和投資意向
"risk_keywords": ["中等風險"],
"amount_mentioned": True, # 檢測到"100萬"
"time_horizon": "中期", # 檢測到"5年內"
"urgency_level": "中"
}
# 簡單金額提取
amount_match = re.search(r'(\d+)萬', user_input)
if amount_match:
intent_info["amount"] = f"{amount_match.group(1)}萬元"
return intent_info
# 處理時間: 0.1秒
# 輸出: {"primary_intent": "資產配置", "amount": "100萬元", ...}
深思熟慮架構處理方式:
def _deep_user_analysis(self, user_input: str, context: Dict) -> Dict[str, Any]:
"""深度用户理解 - 深思熟慮式"""
print(" 深思熟慮: Qwen多維度分析")
prompt = """
作為專業投資顧問,深度分析用户畫像:
用户描述:{user_input}
請從8個維度返回JSON格式分析:
1. demographics: 年齡、職業階段、家庭狀況
2. financial_situation: 收入穩定性、負債水平、資產結構
3. risk_profile: 風險承受能力等級和依據
4. investment_knowledge: 投資經驗水平評估
5. psychological_factors: 損失厭惡、投資耐心等心理特徵
6. investment_goals: 具體投資目標和可行性
7. constraints: 投資約束條件
8. lifecycle_stage: 生命週期階段判斷
"""
# Qwen深度分析調用
response = self.llm.invoke(prompt.format(user_input=user_input))
# 輸出示例
return {
"demographics": {
"age": 35,
"career_stage": "職業發展期",
"family_status": "穩定,有房有車",
"lifecycle_stage": "積累階段"
},
"financial_situation": {
"income_stability": "高",
"debt_level": "無負債",
"asset_structure": "存款為主",
"emergency_fund": "充足"
},
"risk_profile": {
"level": "平衡型",
"basis": "明確表達中等風險承受意願",
"max_drawdown_tolerance": "15-20%"
},
"investment_goals": {
"primary": "5年內資產增長50%",
"feasibility": "年化約8.4%,有一定挑戰性",
"time_horizon": "中期(5年)"
}
# ... 其他維度
}
# 處理時間: 2-3秒
# 輸出: 完整的8維度用户畫像
環節對比總結:
|
方面 |
反應式 |
深思熟慮式 |
|
分析方法 |
關鍵詞匹配 + 簡單規則 |
Qwen大模型深度語義分析 |
|
輸出維度 |
5個基礎意圖維度 |
8個詳細用户畫像維度 |
|
處理深度 |
表層信息提取 |
深層特徵推斷 |
|
時間消耗 |
0.1秒 |
2-3秒 |
|
準確性 |
依賴關鍵詞質量 |
理解上下文語義 |
2. 風險評估環節對比
反應式架構處理方式:
def _qwen_risk_assessment(self, user_input: str, rule_result: Dict) -> str:
"""快速風險評估 - 反應式"""
print(" 反應式: 針對性風險評估")
prompt = """
基於用户描述快速評估風險承受能力:
用户描述:{user_input}
請用簡潔語言回答:
1. 風險等級(保守/穩健/平衡/成長/積極)
2. 主要依據
3. 簡要建議
"""
response = self.llm.invoke(prompt)
# 輸出示例: "風險評估:平衡型\n依據:能承受中等風險...\n建議:..."
return response
# 處理時間: 1秒
# 輸出: 簡潔的三段式風險評估
深思熟慮架構處理方式:
def _comprehensive_risk_assessment(self, user_profile: Dict) -> Dict[str, Any]:
"""綜合風險評估 - 深思熟慮式"""
print(" 深思熟慮: 多維度風險評估")
prompt = """
基於完整用户畫像進行綜合風險評估:
用户檔案:{user_profile}
請從以下維度評估並返回JSON:
1. risk_capacity: 風險承擔能力(財務角度)
2. risk_willingness: 風險承擔意願(心理角度)
3. composite_risk_score: 綜合風險分數(0-100)
4. suitable_risk_level: 適合的風險等級
5. risk_misalignment: 風險偏好與實際能力匹配度
6. recommendation: 個性化風險建議
"""
response = self.llm.invoke(prompt)
return {
"risk_capacity": {
"score": 75,
"factors": ["收入穩定", "無負債", "充足應急資金"],
"assessment": "財務風險承擔能力強"
},
"risk_willingness": {
"score": 65,
"factors": ["明確中等風險偏好", "合理收益目標"],
"assessment": "風險意願與能力匹配"
},
"composite_risk_score": 70,
"suitable_risk_level": "成長型",
"risk_misalignment": "低",
"recommendation": "可適當提高風險暴露至成長型水平"
}
# 處理時間: 2秒
# 輸出: 結構化的多維度風險評估
環節對比總結:
|
方面 |
反應式 |
深思熟慮式 |
|
評估維度 |
單一風險等級 |
能力+意願雙維度 |
|
分析依據 |
用户描述文本 |
完整用户畫像 |
|
輸出形式 |
簡潔文本 |
結構化評分和建議 |
|
處理深度 |
表面風險偏好 |
風險匹配度分析 |
|
時間消耗 |
1秒 |
2秒 |
3. 策略生成環節對比
反應式架構處理方式:
def _qwen_portfolio_advice(self, user_input: str, rule_result: Dict) -> str:
"""快速資產配置 - 反應式"""
print(" 反應式: 標準配置建議")
prompt = """
提供簡潔的資產配置建議:
用户需求:{user_input}
金額:{amount}
請提供:
1. 資產配置比例
2. 配置邏輯簡述
3. 預期風險水平
"""
response = self.llm.invoke(prompt)
# 輸出示例: "配置比例:個股60%、債券30%、現金10%..."
return response
# 處理時間: 1.5秒
# 輸出: 文本格式的配置建議
深思熟慮架構處理方式:
def _generate_strategy_options(self, user_analysis: Dict, market_analysis: Dict) -> List[Dict]:
"""多策略生成 - 深思熟慮式"""
print(" 深思熟慮: 生成3個策略選項")
prompt = """
基於用户畫像和市場分析生成3個投資策略:
用户畫像:{user_profile}
市場分析:{market_analysis}
要求每個策略包含:
- 策略名稱和類型
- 詳細資產配置比例
- 預期收益區間
- 最大回撤估計
- 適合投資者畫像
- 核心投資邏輯
- 風險收益特徵
"""
response = self.llm.invoke(prompt)
return [
{
"name": "穩健平衡策略",
"type": "平衡型",
"allocation": {
"A股藍籌": "30%",
"港股科技": "15%",
"利率債": "25%",
"信用債": "20%",
"貨幣基金": "10%"
},
"expected_return": "6-8%",
"max_drawdown": "12-15%",
"suitable_for": "風險偏好平衡的投資者",
"logic": "股債均衡,側重優質藍籌和利率債",
"risk_return": "中等風險中等收益"
},
{
"name": "成長增值策略",
"type": "成長型",
"allocation": {
"科技成長股": "40%",
"消費龍頭": "20%",
"可轉債": "15%",
"高收益債": "15%",
"黃金": "5%",
"現金": "5%"
},
"expected_return": "8-10%",
"max_drawdown": "18-22%",
"suitable_for": "能承受較高波動的成長型投資者",
"logic": "側重成長板塊,搭配可轉債增強收益",
"risk_return": "中高風險中高收益"
},
# ... 第三個策略
]
# 處理時間: 3-4秒
# 輸出: 3個完整的策略選項
環節對比總結:
|
方面 |
反應式 |
深思熟慮式 |
|
策略數量 |
1個標準建議 |
3個對比選項 |
|
配置細節 |
大類資產比例 |
細分資產類別 |
|
考慮因素 |
用户風險偏好 |
用户畫像+市場環境 |
|
輸出形式 |
文本建議 |
結構化策略對象 |
|
決策支持 |
直接採納 |
多方案比較選擇 |
4. 風險優化環節對比
反應式架構處理方式:
# 反應式架構無獨立風險優化環節
# 風險考慮直接融入策略生成過程
def _format_final_advice(self, qwen_response: str, rule_result: Dict) -> str:
"""格式化輸出 - 包含基礎風險提示"""
advice = f"""
{qwen_response}
風險提示:投資有風險,入市需謹慎
"""
return advice
# 處理時間: 0.1秒
# 輸出: 添加標準風險提示
深思熟慮架構處理方式:
def _risk_optimization(self, strategies: List[Dict], user_analysis: Dict) -> Dict[str, Any]:
"""風險評估優化 - 深思熟慮式"""
print(" 深思熟慮: 策略風險評估優化")
prompt = """
作為風險管理專家,評估策略與用户匹配度:
策略選項:{strategies}
用户風險畫像:{user_profile}
請分析:
1. 推薦策略及匹配理由
2. 風險收益匹配度評分
3. 具體調整建議
4. 風險控制措施
5. 壓力測試情景
"""
response = self.llm.invoke(prompt)
return {
"recommended_strategy": "成長增值策略",
"risk_match_score": "85/100",
"matching_reason": "用户風險承受能力與成長型策略匹配度高",
"adjustment_suggestions": [
"建議將科技股比例從40%降至35%",
"增加5%的防禦性消費板塊",
"設置15%的整體止損線"
],
"risk_controls": [
"單一個股不超過組合5%",
"行業集中度不超過25%",
"保留5-10%現金應對波動"
],
"stress_test": {
"market_crash": "最大回撤預計22%",
"rate_hike": "債券部分可能下跌3-5%",
"recession": "整體收益可能降至2-4%"
}
}
# 處理時間: 2秒
# 輸出: 詳細的風險優化建議
環節對比總結:
|
方面 |
反應式 |
深思熟慮式 |
|
風險處理 |
標準風險提示 |
個性化風險評估 |
|
優化程度 |
無實質性優化 |
具體調整建議 |
|
風險測量 |
定性描述 |
定量壓力測試 |
|
控制措施 |
通用提示 |
具體風控規則 |
|
處理深度 |
表面風險告知 |
深度風險管理 |
5. 輸出生成環節對比
反應式架構處理方式:
def _format_final_advice(self, qwen_response: str, rule_result: Dict) -> str:
"""快速格式化輸出 - 反應式"""
print(" 反應式: 標準化輸出格式化")
return f"""
資產配置建議
────────────────
{qwen_response}
生成方式:Qwen快速響應
響應時間:< 2秒
温馨提示:投資有風險,決策需謹慎
"""
# 最終輸出示例:
"""
資產配置建議
────────────────
配置比例:股票60%、債券30%、現金10%
配置邏輯:基於中等風險偏好,側重權益資產追求增長
預期風險:中等
生成方式:Qwen快速響應
響應時間:< 2秒
温馨提示:投資有風險,決策需謹慎
"""
深思熟慮架構處理方式:
def _generate_personalized_advice(self, optimized_advice: Dict, user_analysis: Dict) -> Dict[str, Any]:
"""個性化建議生成 - 深思熟慮式"""
print(" 深思熟慮: 生成完整投資建議書")
prompt = """
生成完整的個性化投資建議書:
優化建議:{optimized_advice}
用户畫像:{user_profile}
請包含以下章節:
1. 投資目標回顧與可行性分析
2. 推薦策略詳細説明
3. 具體實施計劃和時間表
4. 風險管理和控制措施
5. 績效評估和調整機制
6. 後續服務和跟蹤安排
"""
final_text = self.llm.invoke(prompt)
return {
"reasoning_process": {
"analysis_stages": ["用户畫像", "市場分析", "策略生成", "風險優化", "個性化"],
"total_qwen_calls": 5,
"processing_time": "8秒"
},
"user_profile_summary": user_analysis,
"recommended_strategy": optimized_advice["recommended_strategy"],
"personalized_advice": final_text,
"implementation_plan": {
"phase1": "第1個月:建立60%核心倉位",
"phase2": "第2-3個月:逐步加倉至目標配置",
"phase3": "第4-6個月:優化調整,完成建倉"
},
"risk_management": optimized_advice["risk_controls"],
"monitoring_schedule": "月度表現回顧,季度策略調整"
}
# 最終輸出: 完整的結構化投資建議報告
環節對比總結:
|
方面 |
反應式 |
深思熟慮式 |
|
輸出形式 |
簡潔文本 |
結構化報告 |
|
內容深度 |
核心建議 |
完整實施方案 |
|
個性化 |
中等程度 |
高度個性化 |
|
可操作性 |
基礎指導 |
詳細執行計劃 |
|
後續跟蹤 |
無 |
完整的監控安排 |
6. 架構選擇指南
選擇反應式架構當:
# 用户需要即時答案
if query_complexity == "simple" and response_time_requirement == "fast":
use_reactive_architecture()
# 標準化諮詢場景
elif scenario in ["customer_service", "quick_consultation"]:
use_reactive_architecture()
# 資源受限環境
elif computational_resources == "limited":
use_reactive_architecture()
選擇深思熟慮架構當:
# 重大投資決策
if decision_importance == "high" and investment_amount == "large":
use_deliberative_architecture()
# 複雜個人情況
elif user_situation_complexity == "high":
use_deliberative_architecture()
# 長期財務規劃
elif time_horizon == "long_term" and planning_depth == "comprehensive":
use_deliberative_architecture()
六、總結
反應式與深思熟慮式智能投資顧問架構代表了AI在投資諮詢領域應用的兩種不同哲學和實踐路徑。反應式架構以其快速響應、高可擴展性的特點,適合標準化、高併發的諮詢場景;而深思熟慮式架構通過深度推理、個性化服務為複雜投資決策提供專業支持。
未來智能投顧的發展方向不是二選一,而是通過混合架構實現優勢互補。金融機構應根據自身業務特點、客户羣體和技術能力,選擇合適的架構組合策略。對於追求極致用户體驗的機構,可以優先部署反應式架構快速獲客;對於服務高淨值客户的機構,則應重點建設深思熟慮式架構提供深度服務。