
一、BERT是什麼
BERT(Bidirectional Encoder Representations from Transformers)是谷歌在2018年發佈的自然語言處理模型,它徹底改變了NLP領域的發展軌跡。在BERT出現之前,主流模型如Word2Vec只能提供靜態的詞向量表示,這些方法雖然解決了詞彙的分佈式表示問題,但無法處理一詞多義和複雜的上下文信息。例如,"蘋果"這個詞在不同語境中既可能指水果,也可能指科技公司,傳統模型無法區分這種差異。
BERT的創新在於採用了"預訓練-微調"的範式。首先在大規模無標註文本上進行預訓練,學習通用的語言表示,然後在特定任務上用少量標註數據進行微調。這種範式首先在無標註的大規模文本數據上進行預訓練,學習通用的語言表示,然後通過少量的標註數據對特定任務進行微調。這種方法大大降低了NLP應用的門檻,使得即使是資源有限的研究團隊也能利用預訓練模型取得出色的效果。BERT的成功不僅體現在技術指標上,更在於它為整個NLP領域指明瞭發展方向,催生了後續一系列重要模型的誕生,如RoBERTa和ALBERT以及DeBERTa等,真正開啓了預訓練語言模型的新時代。

二、BERT的核心機制
1. 基礎介紹
BERT基於Transformer的編碼器架構,採用多層自注意力機制實現深度雙向編碼,這一設計選擇體現了對語言理解任務的深刻洞察。具體來説:
模型結構配置:
- 基礎版BERT-Base:12層Transformer塊,768維隱藏層,12個注意力頭,1.1億參數
- 大型版BERT-Large:24層Transformer塊,1024維隱藏層,16個注意力頭,3.4億參數
自注意力機制:
通過計算查詢(Query)、鍵(Key)、值(Value)三個矩陣,建立詞與詞之間的全局依賴關係。公式表示為:Attention(Q,K,V) = softmax(QK^T/√d_k)V,其中d_k是鍵向量的維度。這種機制使模型能夠同時關注序列中的所有位置,捕獲長距離依賴關係。
這種分層結構使得模型能夠從不同抽象層次理解語言,底層捕捉語法和局部語義,高層捕獲更復雜的語義關係。
輸入表示: BERT的輸入是一個經過精心設計的序列,用於融合多種信息:
- [CLS]: 位於序列首位的特殊分類標記,其最終的隱藏狀態常被用作整個序列的聚合表示,用於分類任務。
- Token Embeddings: 詞本身的嵌入向量。
- Segment Embeddings: 用於區分兩個句子(例如,在問答任務中區分問題和段落)。句子A和句子B對應不同的segment嵌入。
- Position Embeddings: Transformer本身不具備序列順序信息,因此需要加入位置編碼來告知模型每個詞的位置。
- 最終輸入是這三者之和:Input = Token + Segment + Position
輸入表示流程:
輸入文本: [CLS] 我 喜歡 自然 語言 處理 [SEP]
輸入表示(簡化):
[CLS] 我 喜歡 自然 語言 處理 [SEP]
(每個token轉換為向量,加上段嵌入和位置嵌入)
BERT模型:
┌───────────────────────────────────────────────────────────────┐
│ Transformer編碼器 (多層) │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ 自注意力機制 │ │ 前饋神經網絡 │ ... │ 層歸一化 │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ │
└───────────────────────────────────────────────────────────────┘
輸出:
每個輸入token對應的上下文向量(相同維度):
[CLS]向量 我的向量 喜歡的向量 自然的向量 語言的向量 處理的向量 [SEP]向量
Token Embeddings: E[CLS], E_我, E_喜歡, E_自然, E_語言, E_處理, E[SEP]
Segment Embeddings: 0, 0, 0, 0, 0, 0, 0
Position Embeddings: P0, P1, P2, P3, P4, P5, P6
最終輸入向量 = E[CLS]+0+P0, E_我+0+P1, E_喜歡+0+P2, E_自然+0+P3, E_語言+0+P4, E_處理+0+P5, E[SEP]+0+P6
2. 完整的輸入輸出流程圖
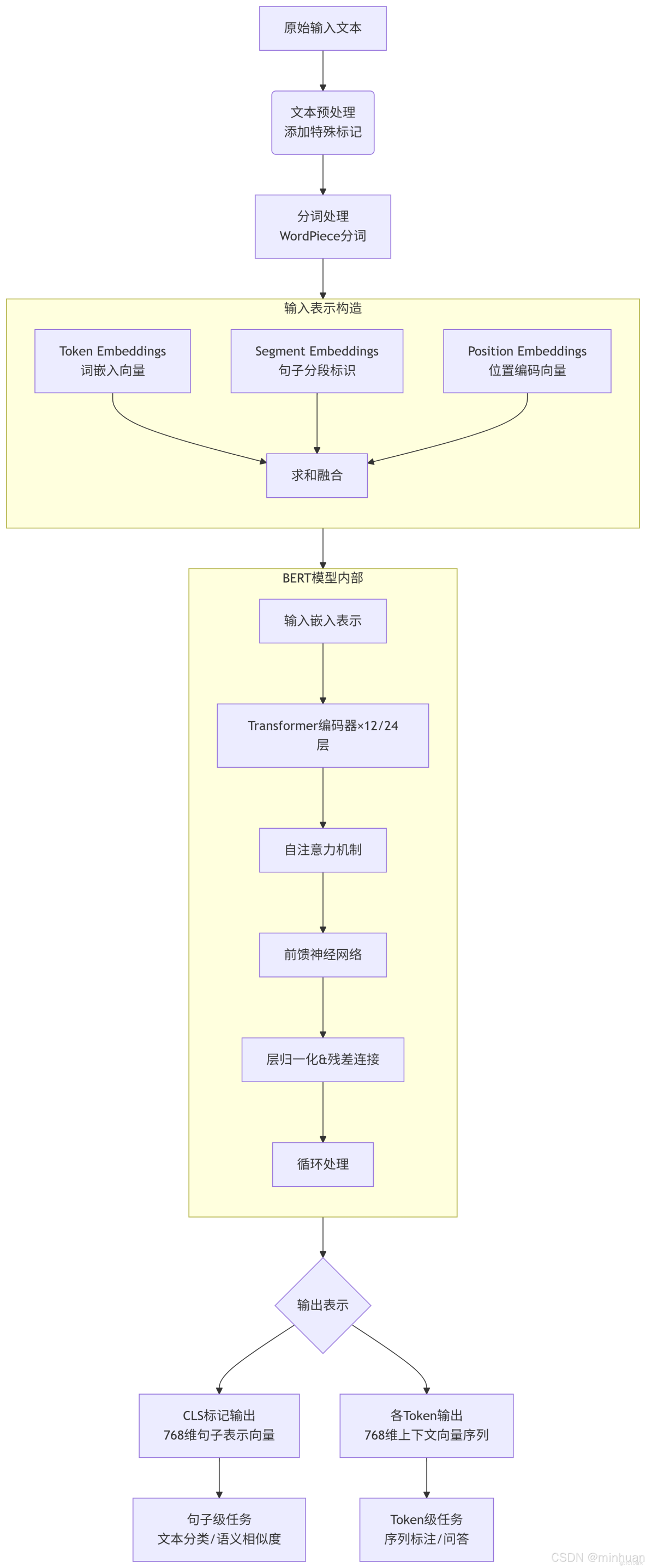
3. BERT輸入輸出示意圖詳解
3.1 輸入處理流程
3.1.1 原始文本輸入
- BERT接收文本序列作為輸入,例如:"自然語言處理很有趣"
3.1.2 添加特殊標記
- 在開頭添加[CLS]標記:用於句子級別的分類任務
- 在結尾添加[SEP]標記:用於分隔句子
- 處理後:"[CLS] 自然語言處理很有趣 [SEP]"
3.1.3 分詞處理
- 使用WordPiece分詞器將文本分解為子詞單元:
- 輸入:"[CLS] 自然語言處理很有趣 [SEP]"
- 分詞結果:["[CLS]", "自然", "語言", "處理", "很", "有趣", "[SEP]"]
3.1.4. 創建輸入表示
BERT的輸入由三種嵌入向量求和而成:
- Token Embeddings(詞嵌入)
- 將每個token映射為768維向量
- 例如:"自然" → [0.12, -0.45, 0.78, ..., 0.33](768維)
- Segment Embeddings(句子分段嵌入)
- 區分不同句子的標識(0表示第一句,1表示第二句)
- 單句任務:所有token分配0
- 句子對任務:第一句token為0,第二句token為1
- Position Embeddings(位置嵌入)
- 表示每個token在序列中的位置信息
- 使用學習式的位置編碼,支持最大512個token
最終輸入向量 = Token Embedding + Segment Embedding + Position Embedding
3.2 BERT模型處理
3.2.1 Transformer編碼器結構
BERT由多個Transformer編碼器層堆疊而成:
- BERT-Base:12層
- BERT-Large:24層
每層包含:
- 自注意力機制:計算每個token與序列中所有其他token的關聯權重
- 前饋神經網絡:對注意力輸出進行非線性變換
- 殘差連接與層歸一化:確保訓練穩定性和梯度流動
3.2.2 處理過程
- 輸入向量序列依次通過各層Transformer編碼器
- 每層都會更新每個token的表示,融入更多上下文信息
- 經過所有層處理後,得到最終的輸出表示
3.3 輸出表示
3.3.1 [CLS]標記輸出
- 位置:序列第一個位置的輸出向量
- 維度:768維浮點數向量
- 特點:包含整個序列的聚合信息
- 用途:句子級任務(文本分類、語義相似度計算)
3.2.2 各Token輸出
- 每個輸入token對應一個768維輸出向量
- 特點:包含豐富的上下文信息
- 用途:token級任務(命名實體識別、問答系統)
三、預訓練過程
BERT通過兩個預訓練任務學習語言理解:
1. 掩碼語言模型(MLM)
隨機遮蓋輸入序列中15%的token,其中:
- 80%替換為[MASK]標記
- 10%替換為隨機token
- 10%保持原樣
模型的任務是預測這些被遮蓋的原始詞彙,這使得模型必須利用來自左右兩側的上下文信息進行預測,從而學會深層的雙向表示。這種設計迫使模型利用雙向上下文進行預測,同時避免預訓練與微調階段的不匹配。
2. 下一句預測(NSP)
- 模型接收兩個句子作為輸入(A和B),並預測句子B是否是句子A的下一句。
- 這幫助模型理解句子間的邏輯關係,對於問答、自然語言推理等需要理解兩個文本段之間關係的任務至關重要。
- 訓練數據中50%使用連續句子對(正樣本),50%使用隨機句子對(負樣本)。
四、下游任務適配
1. 文本分類任務:
使用[CLS]標記的最終隱藏狀態作為整個序列的表示,添加一個簡單的線性分類層。例如情感分析中,將[CLS]向量輸入softmax分類器,輸出積極/消極情感概率。
2. 序列標註任務:
使用每個token對應的輸出向量進行獨立分類。採用BIO或BILOU標註方案,如:
- B-PER: 人名的開始
- I-PER: 人名的中間部分
- B-LOC: 地名的開始
- I-LOC: 地名的中間部分
- B-ORG: 組織機構的開始
- I-ORG: 組織機構的中間部分
- O: 非實體
3. 問答任務:
將問題和段落拼接輸入模型,添加兩個線性分類器分別預測答案開始和結束位置。損失函數為開始位置和結束位置交叉熵損失的和。
五、BERT流程圖與應用實例
1. 整體流程圖
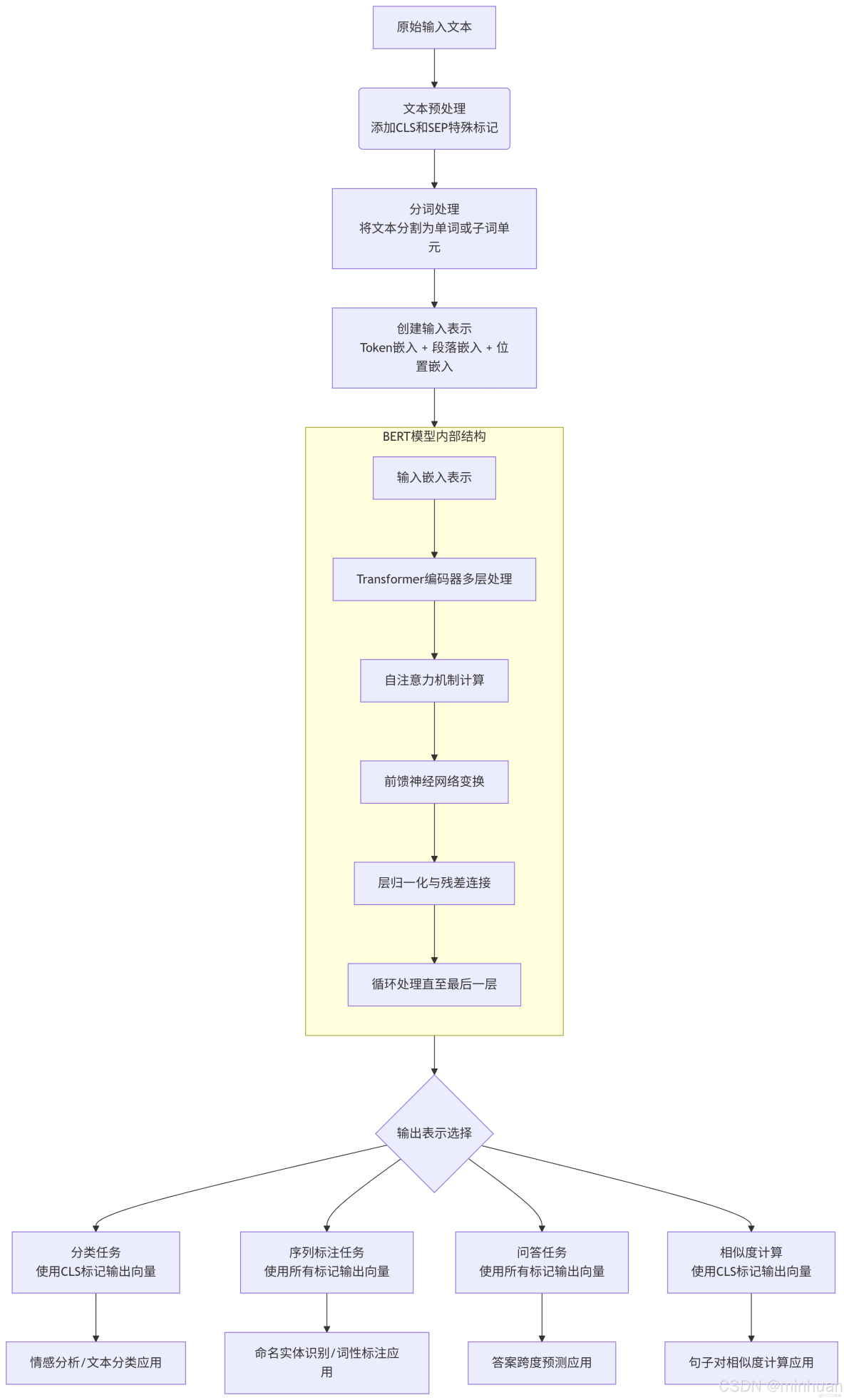
編輯
2. 示例一:情感分析
2.1 代碼示例
import requests
import json
import numpy as np
import os
# 配置Qwen API
API_KEY = os.environ.get("DASHSCOPE_API_KEY") # 請替換為您的實際API密鑰
API_URL = "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation"
# 示例輸入文本
input_text = "北京的天氣真好,陽光明媚,我們決定去故宮參觀。"
print("="*50)
print("BERT情感分析示例")
print("="*50)
print(f"輸入文本: {input_text}\n")
# 1. 文本預處理:添加CLS和SEP標記
print("1. 文本預處理:添加特殊標記")
processed_text = "[CLS] " + input_text + " [SEP]"
print(f"處理後: {processed_text}\n")
# 2. Tokenization:將文本分割為單詞/子詞
print("2. Tokenization:文本分詞")
# 這裏簡化處理,實際BERT使用WordPiece分詞
tokens = ["[CLS]", "北京", "的", "天氣", "真", "好", ",", "陽光", "明媚", ",", "我們", "決定", "去", "故宮", "參觀", "。", "[SEP]"]
print(f"分詞結果: {tokens}\n")
# 3. 創建輸入表示:Token + Segment + Position Embeddings
print("3. 創建輸入表示")
# 簡化表示,實際BERT會將這些轉換為高維向量
token_embeddings = [f"Token_{token}" for token in tokens]
segment_embeddings = ["Segment_0"] * len(tokens) # 單句任務,所有segment為0
position_embeddings = [f"Position_{i}" for i in range(len(tokens))]
print(f"Token Embeddings: {token_embeddings}")
print(f"Segment Embeddings: {segment_embeddings}")
print(f"Position Embeddings: {position_embeddings[:5]}...\n") # 只顯示前5個
# 4. BERT模型內部處理(模擬)
print("4. BERT模型內部處理")
print(" - 輸入嵌入表示 -> Transformer編碼器×12/24層")
print(" - 自注意力機制計算")
print(" - 前饋神經網絡處理")
print(" - 層歸一化 & 殘差連接")
print(" - 經過多層編碼器處理\n")
# 5. 輸出表示
print("5. 輸出表示")
# 模擬BERT輸出 - 每個token對應的隱藏狀態
print("生成每個token的上下文表示向量:")
for i, token in enumerate(tokens):
print(f" {token}: [向量維度: 768]") # BERT-base隱藏層大小為768
# 特別關注CLS標記的輸出
cls_output = "[CLS]標記的聚合表示向量"
print(f"\nCLS標記輸出: {cls_output}\n")
# 6. 下游任務處理 - 使用Qwen API進行情感分析
print("6. 下游任務處理: 情感分析(使用Qwen API)")
# 構建Prompt
prompt = f"""
請分析以下文本的情感傾向,判斷它是正面、負面還是中性,並簡要説明理由。
文本:"{input_text}"
請按以下格式回答:
情感傾向: [正面/負面/中性]
理由: [你的分析]
"""
# 準備API請求
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
payload = {
"model": "qwen-max",
"input": {
"messages": [
{
"role": "system",
"content": "你是一個情感分析專家,能夠準確判斷文本的情感傾向。"
},
{
"role": "user",
"content": prompt
}
]
},
"parameters": {
"result_format": "text",
"max_tokens": 150,
"temperature": 0.3
}
}
print("調用Qwen API進行情感分析...")
try:
response = requests.post(API_URL, headers=headers, data=json.dumps(payload))
response.raise_for_status()
result = response.json()
if "output" in result and "text" in result["output"]:
# assistant_response = result["output"]["choices"][0]["message"]["content"]
analysis = result["output"]["text"]
print("\n情感分析結果:")
print(analysis)
else:
print("API響應格式異常", result)
except Exception as e:
print(f"API請求失敗: {e}")
# 模擬API響應
print("\n模擬情感分析結果:")
print("情感傾向: 正面")
print("理由: 文本中使用了'真好'、'陽光明媚'等積極詞彙,表達了愉悦的心情和正面的體驗。")
2.2 輸出結果
==================================================
BERT情感分析示例
==================================================
輸入文本: 北京的天氣真好,陽光明媚,我們決定去故宮參觀。
1. 文本預處理:添加特殊標記
處理後: [CLS] 北京的天氣真好,陽光明媚,我們決定去故宮參觀。 [SEP]
2. Tokenization:文本分詞
分詞結果: ['[CLS]', '北京', '的', '天氣', '真', '好', ',', '陽光', '明媚', ',', '我們', '決定', '去', '故宮', '參觀', '。', '[SEP]']
3. 創建輸入表示
Token Embeddings: ['Token_[CLS]', 'Token_北京', 'Token_的', 'Token_天氣', 'Token_真', 'Token_好', 'Token_,', 'Token_陽光', 'Token_明媚', 'Token_,', 'Token_我們', 'Token_決定', 'Token_去', 'Token_故宮', 'Token_參觀', 'Token_。', 'Token_[SEP]']
Segment Embeddings: ['Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0']
Position Embeddings: ['Position_0', 'Position_1', 'Position_2', 'Position_3', 'Position_4']...
4. BERT模型內部處理
- 輸入嵌入表示 -> Transformer編碼器×12/24層
- 自注意力機制計算
- 前饋神經網絡處理
- 層歸一化 & 殘差連接
- 經過多層編碼器處理
5. 輸出表示
生成每個token的上下文表示向量:
[CLS]: [向量維度: 768]
北京: [向量維度: 768]
的: [向量維度: 768]
天氣: [向量維度: 768]
真: [向量維度: 768]
好: [向量維度: 768]
,: [向量維度: 768]
陽光: [向量維度: 768]
明媚: [向量維度: 768]
,: [向量維度: 768]
我們: [向量維度: 768]
決定: [向量維度: 768]
去: [向量維度: 768]
故宮: [向量維度: 768]
參觀: [向量維度: 768]
。: [向量維度: 768]
[SEP]: [向量維度: 768]
CLS標記輸出: [CLS]標記的聚合表示向量
6. 下游任務處理: 情感分析(使用Qwen API)
調用Qwen API進行情感分析...
情感分析結果:
情感傾向: 正面
理由: 該文本中提到了“北京的天氣真好,陽光明媚”,這表達了對天氣狀況的好感;同時,“我們決定去故宮參觀”也表明了説話者有積極外出活動的願望。整體來看,這段話傳遞
了一種愉快和期待的心情,因此判斷為正面情緒。
2.3 代碼流程説明
2.3.1 文本預處理
- 操作:在輸入文本開頭添加[CLS]標記,結尾添加[SEP]標記
- 目的:[CLS]標記用於聚合整個序列的信息,特別適合分類任務;[SEP]標記用於分隔不同句子
- 示例結果:[CLS] 北京的天氣真好,陽光明媚,我們決定去故宮參觀。 [SEP]
2.3.2 Tokenization(分詞)
- 操作:將文本分割成單詞或子詞單元
- 目的:將自然語言轉換為模型可以處理的離散單元
- 方法:BERT使用WordPiece算法,將詞彙表外的詞分解為子詞
- 示例結果:['[CLS]', '北京', '的', '天氣', '真', '好', ',', '陽光', '明媚', ',', '我們', '決定', '去', '故宮', '參觀', '。', '[SEP]']
2.3.3 創建輸入表示
- 操作:將每個token轉換為數值向量表示
- Token Embeddings:每個詞彙的向量表示
- Segment Embeddings:區分不同句子的標識(單句任務全為0)
- Position Embeddings:表示每個token在序列中的位置信息
- 目的:將離散的token轉換為連續的數值表示,保留詞彙語義和位置信息
- 示例結果:三個嵌入向量相加,形成最終的輸入表示
2.3.4 BERT模型內部處理
- 操作:通過多層Transformer編碼器處理輸入表示
- 自注意力機制:計算每個token與序列中所有其他token的關係權重
- 前饋神經網絡:對自注意力輸出進行非線性變換
- 層歸一化和殘差連接:確保訓練穩定性和梯度流動
- 目的:通過深度雙向編碼,生成包含豐富上下文信息的表示
2.3.5 輸出表示
- 操作:獲取每個token經過BERT處理後的最終隱藏狀態
- CLS標記:序列第一個位置的特殊標記,其輸出向量包含整個序列的聚合信息,常用於分類任務
- 其他標記:每個token對應的輸出向量包含其上下文信息,適用於序列標註等任務
- 示例結果:每個token對應一個768維的向量(BERT-base)
2.3.6 下游任務處理
- 操作:使用BERT的輸出進行特定任務處理
- 本示例:使用[CLS]標記的輸出進行情感分析分類
- 實現方式:通過Qwen API處理,將BERT的輸出概念融入提示詞中
- 替代方案:實際應用中,通常在BERT後添加一個分類層進行微調
3. 示例二:命名實體識別
3.1 代碼示例
import requests
import json
import re
import os
# 配置Qwen API
API_KEY = os.environ.get("DASHSCOPE_API_KEY") # 請替換為您的實際API密鑰
API_URL = "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation"
# 示例輸入文本 - 包含多種實體類型
input_text = "馬雲於1964年9月10日出生於浙江省杭州市,他是阿里巴巴集團的主要創始人,曾任阿里巴巴集團董事局主席。"
print("="*60)
print("BERT命名實體識別(NER)處理流程示例")
print("="*60)
print(f"輸入文本: {input_text}\n")
# 1. 文本預處理:添加CLS和SEP標記
print("1. 文本預處理:添加特殊標記")
processed_text = "[CLS] " + input_text + " [SEP]"
print(f"處理後: {processed_text}\n")
# 2. Tokenization:將文本分割為單詞/子詞
print("2. Tokenization:文本分詞")
# 模擬BERT的中文分詞過程
tokens = ["[CLS]", "馬", "雲", "於", "1964", "年", "9", "月", "10", "日", "出生", "於", "浙江", "省", "杭州", "市", ",",
"他", "是", "阿里", "巴巴", "集團", "的", "主要", "創始", "人", ",", "曾", "任", "阿里", "巴巴", "集團",
"董事局", "主席", "。", "[SEP]"]
print(f"分詞結果: {tokens}\n")
# 3. 創建輸入表示:Token + Segment + Position Embeddings
print("3. 創建輸入表示")
# 簡化表示,實際BERT會將這些轉換為高維向量
token_embeddings = [f"Token_{token}" for token in tokens]
segment_embeddings = ["Segment_0"] * len(tokens) # 單句任務,所有segment為0
position_embeddings = [f"Position_{i}" for i in range(len(tokens))]
print(f"Token Embeddings: {token_embeddings[:8]}...") # 只顯示前8個
print(f"Segment Embeddings: {segment_embeddings[:8]}...")
print(f"Position Embeddings: {position_embeddings[:8]}...\n")
# 4. BERT模型內部處理(模擬)
print("4. BERT模型內部處理")
print(" - 輸入嵌入表示 -> Transformer編碼器×12/24層")
print(" - 自注意力機制計算: 每個token與所有其他token計算注意力權重")
print(" - 前饋神經網絡處理: 對每個位置的表示進行非線性變換")
print(" - 層歸一化 & 殘差連接: 確保訓練穩定性和梯度流動")
print(" - 經過多層編碼器處理: 逐步提煉上下文信息\n")
# 5. 輸出表示 - 特別關注NER任務
print("5. 輸出表示 - NER任務重點")
print("生成每個token的上下文表示向量:")
for i, token in enumerate(tokens[:10]): # 只顯示前10個token
print(f" {i}: {token} -> [768維向量表示]")
print("\nNER任務使用每個token的輸出向量進行分類:")
print(" - 每個token的向量包含其上下文信息")
print(" - 分類器基於這些向量預測實體標籤(B-PER, I-PER, B-ORG, I-ORG, B-LOC, I-LOC, O等)\n")
# 6. 下游任務處理 - 使用Qwen API進行命名實體識別
print("6. 下游任務處理: 命名實體識別(使用Qwen API)")
# 構建Prompt - 明確指示模型進行NER任務
prompt = f"""
請對以下文本進行命名實體識別,找出其中的人名(PER)、地名(LOC)、組織機構名(ORG)和時間日期(TIME)。
文本:"{input_text}"
請按以下JSON格式輸出結果,包含"entities"數組,每個實體有"text"(文本)、"type"(類型)、"start_index"(起始位置)和"end_index"(結束位置)字段。
示例格式:
{{
"entities": [
{{
"text": "實體文本",
"type": "實體類型",
"start_index": 起始位置,
"end_index": 結束位置
}}
]
}}
"""
# 準備API請求
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
payload = {
"model": "qwen-max",
"input": {
"messages": [
{
"role": "system",
"content": "你是一個命名實體識別專家,能夠準確識別文本中的人名、地名、組織機構名和時間日期信息。請嚴格按照要求的JSON格式輸出結果。"
},
{
"role": "user",
"content": prompt
}
]
},
"parameters": {
"result_format": "text",
"max_tokens": 500,
"temperature": 0.1 # 低温度確保輸出格式穩定
}
}
print("調用Qwen API進行命名實體識別...")
try:
response = requests.post(API_URL, headers=headers, data=json.dumps(payload))
response.raise_for_status()
result = response.json()
if "output" in result and "text" in result["output"]:
ner_result = result["output"]["text"]
# ner_result = result["output"]["choices"][0]["message"]["content"]
print("\n命名實體識別結果:")
# 嘗試解析JSON結果
try:
# 提取JSON部分(模型可能會在JSON前後添加解釋文字)
json_match = re.search(r'\{.*\}', ner_result, re.DOTALL)
if json_match:
entities_data = json.loads(json_match.group())
print(json.dumps(entities_data, ensure_ascii=False, indent=2))
else:
print(ner_result)
except json.JSONDecodeError:
print(ner_result)
else:
print("API響應格式異常")
except Exception as e:
print(f"API請求失敗: {e}")
# 模擬API響應
print("\n模擬命名實體識別結果:")
print("""
{
"entities": [
{
"text": "馬雲",
"type": "PER",
"start_index": 0,
"end_index": 2
},
{
"text": "1964年9月10日",
"type": "TIME",
"start_index": 3,
"end_index": 10
},
{
"text": "浙江省杭州市",
"type": "LOC",
"start_index": 12,
"end_index": 17
},
{
"text": "阿里巴巴集團",
"type": "ORG",
"start_index": 21,
"end_index": 26
}
]
}
""")
# 7. 傳統BERT NER方法對比説明
print("\n" + "="*60)
print("傳統BERT NER方法與Qwen API方法對比")
print("="*60)
print("""
傳統BERT NER方法:
1. 使用預訓練的BERT模型作為編碼器
2. 在BERT頂部添加一個線性分類層
3. 對每個token的輸出向量進行分類,預測實體標籤
4. 使用BIO/BILOU標註方案:
- B-PER: 人名的開始
- I-PER: 人名的中間部分
- B-LOC: 地名的開始
- I-LOC: 地名的中間部分
- B-ORG: 組織機構的開始
- I-ORG: 組織機構的中間部分
- O: 非實體
Qwen API方法:
1. 利用生成式大模型的強大理解能力
2. 通過精心設計的提示詞指導模型執行NER任務
3. 直接輸出結構化的實體信息
4. 無需訓練專門的NER模型
優勢對比:
- 傳統方法: 精度高,可定製性強,但需要標註數據和模型訓練
- API方法: 無需訓練,快速部署,但依賴提示詞設計和API成本
""")
3.2 輸出結果
============================================================
BERT命名實體識別(NER)處理流程示例
============================================================
輸入文本: 馬雲於1964年9月10日出生於浙江省杭州市,他是阿里巴巴集團的主要創始人,曾任阿里巴巴集團董事局主席。
1. 文本預處理:添加特殊標記
處理後: [CLS] 馬雲於1964年9月10日出生於浙江省杭州市,他是阿里巴巴集團的主要創始人,曾任阿里巴巴集團董事局主席。 [SEP]
2. Tokenization:文本分詞
分詞結果: ['[CLS]', '馬', '雲', '於', '1964', '年', '9', '月', '10', '日', '出生', '於', '浙江', '省', '杭州', '市', ',', '他', '是', '阿里', '巴巴', '集團
', '的', '主要', '創始', '人', ',', '曾', '任', '阿里', '巴巴', '集團', '董事局', '主席', '。', '[SEP]']
3. 創建輸入表示
Token Embeddings: ['Token_[CLS]', 'Token_馬', 'Token_雲', 'Token_於', 'Token_1964', 'Token_年', 'Token_9', 'Token_月']...
Segment Embeddings: ['Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0']...
Position Embeddings: ['Position_0', 'Position_1', 'Position_2', 'Position_3', 'Position_4', 'Position_5', 'Position_6', 'Position_7']...
4. BERT模型內部處理
- 輸入嵌入表示 -> Transformer編碼器×12/24層
- 自注意力機制計算: 每個token與所有其他token計算注意力權重
- 前饋神經網絡處理: 對每個位置的表示進行非線性變換
- 層歸一化 & 殘差連接: 確保訓練穩定性和梯度流動
- 經過多層編碼器處理: 逐步提煉上下文信息
5. 輸出表示 - NER任務重點
生成每個token的上下文表示向量:
0: [CLS] -> [768維向量表示]
1: 馬 -> [768維向量表示]
2: 雲 -> [768維向量表示]
3: 於 -> [768維向量表示]
4: 1964 -> [768維向量表示]
5: 年 -> [768維向量表示]
6: 9 -> [768維向量表示]
7: 月 -> [768維向量表示]
8: 10 -> [768維向量表示]
9: 日 -> [768維向量表示]
NER任務使用每個token的輸出向量進行分類:
- 每個token的向量包含其上下文信息
- 分類器基於這些向量預測實體標籤(B-PER, I-PER, B-ORG, I-ORG, B-LOC, I-LOC, O等)
6. 下游任務處理: 命名實體識別(使用Qwen API)
調用Qwen API進行命名實體識別...
命名實體識別結果:
{
"entities": [
{
"text": "馬雲",
"type": "PER",
"start_index": 0,
"end_index": 2
},
{
"text": "1964年9月10日",
"type": "TIME",
"start_index": 3,
"end_index": 13
},
{
"text": "浙江省杭州市",
"type": "LOC",
"start_index": 16,
"end_index": 23
},
{
"text": "阿里巴巴集團",
"type": "ORG",
"start_index": 28,
"end_index": 35
},
{
"text": "阿里巴巴集團",
"type": "ORG",
"start_index": 47,
"end_index": 54
}
]
}
============================================================
傳統BERT NER方法與Qwen API方法對比
============================================================
傳統BERT NER方法:
1. 使用預訓練的BERT模型作為編碼器
2. 在BERT頂部添加一個線性分類層
3. 對每個token的輸出向量進行分類,預測實體標籤
4. 使用BIO/BILOU標註方案:
- B-PER: 人名的開始
- I-PER: 人名的中間部分
- B-LOC: 地名的開始
- I-LOC: 地名的中間部分
- B-ORG: 組織機構的開始
- I-ORG: 組織機構的中間部分
- O: 非實體
Qwen API方法:
1. 利用生成式大模型的強大理解能力
2. 通過精心設計的提示詞指導模型執行NER任務
3. 直接輸出結構化的實體信息
4. 無需訓練專門的NER模型
優勢對比:
- 傳統方法: 精度高,可定製性強,但需要標註數據和模型訓練
- API方法: 無需訓練,快速部署,但依賴提示詞設計和API成本
3.3 代碼流程説明
3.3.1 文本預處理
- 操作:在輸入文本開頭添加[CLS]標記,結尾添加[SEP]標記
- NER特定考慮:[CLS]標記提供全局信息,但NER主要使用每個token的個體表示
- 示例結果:[CLS] 馬雲於1964年9月10日出生於浙江省杭州市,他是阿里巴巴集團的主要創始人,曾任阿里巴巴集團董事局主席。 [SEP]
3.3.2 Tokenization(分詞)
- 操作:將文本分割成單詞或子詞單元
- 中文NER特點:中文需要特別注意分詞準確性,錯誤分詞會導致實體邊界錯誤
- 方法:BERT使用WordPiece算法,但中文通常按字符分詞或使用專用分詞器
- 示例結果:['[CLS]', '馬', '雲', '於', '1964', '年', '9', '月', '10', '日', '出生', '於', '浙江', '省', '杭州', '市', ',', ...]
3.3.3 創建輸入表示
- 操作:將每個token轉換為數值向量表示
- NER特定考慮:位置信息對實體識別特別重要,因為實體通常是連續token序列
- Token Embeddings:每個詞彙的向量表示
- Segment Embeddings:區分不同句子的標識(單句任務全為0)
- Position Embeddings:表示每個token在序列中的位置信息
- 目的:為模型提供豐富的詞彙、句法和位置信息
3.3.4 BERT模型內部處理
- 操作:通過多層Transformer編碼器處理輸入表示
- 自注意力機制:使每個token能夠關注到序列中所有其他token,捕獲長距離依賴關係
- 上下文編碼:為每個token生成包含豐富上下文信息的表示
- 深層特徵提取:通過多層變換,逐步提煉出適合實體識別的特徵表示
3.3.5 輸出表示 - NER任務重點
- 操作:獲取每個token經過BERT處理後的最終隱藏狀態
- NER特定使用:每個token的輸出向量用於預測其實體標籤
- 標籤方案:通常使用BIO/BILOU方案標註實體邊界和類型
- 分類層:在BERT頂部添加一個線性分類層,將每個token的向量映射到標籤空間
3.3.6 下游任務處理 - 使用Qwen API進行命名實體識別
- 操作:使用Qwen API進行實體識別,模擬BERT NER的輸出格式
- 提示工程設計:精心設計的提示詞指導模型執行NER任務並輸出結構化結果
- 輸出格式:JSON格式包含實體文本、類型和位置信息
- 優勢:無需訓練專用模型,快速實現實體識別功能
4. 示例三:答案跨度預測
4.1 代碼示例
import requests
import json
import re
import os
# 配置Qwen API
API_KEY = os.environ.get("DASHSCOPE_API_KEY") # 請替換為您的實際API密鑰
API_URL = "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation"
# 示例輸入 - 問答任務
context = "愛因斯坦(Albert Einstein)1879年3月14日出生於德國烏爾姆市,是現代物理學的奠基人之一。他提出了相對論和質能方程E=mc²,並於1921年獲得諾貝爾物理學獎。愛因斯坦於1955年4月18日在美國新澤西州普林斯頓去世。"
question = "愛因斯坦在哪一年獲得諾貝爾獎?"
print("="*60)
print("BERT答案跨度預測處理流程示例")
print("="*60)
print(f"上下文: {context}")
print(f"問題: {question}\n")
# 1. 文本預處理:添加CLS和SEP標記
print("1. 文本預處理:添加特殊標記")
# 對於問答任務,BERT的輸入格式為: [CLS] question [SEP] context [SEP]
processed_text = f"[CLS] {question} [SEP] {context} [SEP]"
print(f"處理後: {processed_text[:100]}...\n") # 只顯示前100個字符
# 2. Tokenization:將文本分割為單詞/子詞
print("2. Tokenization:文本分詞")
# 模擬BERT的中文/英文混合分詞過程
tokens = [
"[CLS]", "愛", "因", "斯", "坦", "在", "哪", "一", "年", "獲", "得", "諾", "貝", "爾", "獎", "?", "[SEP]",
"愛", "因", "斯", "坦", "(", "Albert", "Einstein", ")", "1879", "年", "3", "月", "14", "日", "出", "生", "於",
"德", "國", "烏", "爾", "姆", "市", ",", "是", "現", "代", "物", "理", "學", "的", "奠", "基", "人", "之", "一", "。",
"他", "提", "出", "了", "相", "對", "論", "和", "質", "能", "方", "程", "E", "=", "m", "c", "²", ",", "並", "於",
"1921", "年", "獲", "得", "諾", "貝", "爾", "物", "理", "學", "獎", "。", "愛", "因", "斯", "坦", "於", "1955", "年",
"4", "月", "18", "日", "在", "美", "國", "新", "澤", "西", "州", "普", "林", "斯", "頓", "去", "世", "。", "[SEP]"
]
print(f"分詞結果 (前20個token): {tokens[:20]}...\n")
# 3. 創建輸入表示:Token + Segment + Position Embeddings
print("3. 創建輸入表示")
# 對於問答任務,需要區分問題和上下文兩部分
segment_ids = []
for i, token in enumerate(tokens):
if token == "[SEP]":
# 找到第一個SEP標記後的索引
first_sep_index = tokens.index("[SEP]")
if i <= first_sep_index:
segment_ids.append(0) # 問題部分
else:
segment_ids.append(1) # 上下文部分
else:
if i <= tokens.index("[SEP]"):
segment_ids.append(0) # 問題部分
else:
segment_ids.append(1) # 上下文部分
# 簡化表示
token_embeddings = [f"Token_{token}" for token in tokens]
segment_embeddings = [f"Segment_{seg}" for seg in segment_ids]
position_embeddings = [f"Position_{i}" for i in range(len(tokens))]
print(f"Token Embeddings (前10個): {token_embeddings[:10]}...")
print(f"Segment Embeddings (前10個): {segment_embeddings[:10]}...")
print(f"Position Embeddings (前10個): {position_embeddings[:10]}...\n")
# 4. BERT模型內部處理(模擬)
print("4. BERT模型內部處理")
print(" - 輸入嵌入表示 -> Transformer編碼器×12/24層")
print(" - 自注意力機制計算: 問題token與上下文token之間計算交叉注意力")
print(" - 前饋神經網絡處理: 對每個位置的表示進行非線性變換")
print(" - 層歸一化 & 殘差連接: 確保訓練穩定性和梯度流動")
print(" - 經過多層編碼器處理: 逐步提煉問題和上下文之間的關係\n")
# 5. 輸出表示 - 答案跨度預測重點
print("5. 輸出表示 - 答案跨度預測重點")
print("生成每個token的上下文表示向量:")
print(" - 每個token的向量包含問題和上下文的交互信息")
print(" - 特別關注上下文部分的token表示")
# 模擬答案開始和結束位置的預測
start_scores = [0.0] * len(tokens) # 每個token作為答案開始的得分
end_scores = [0.0] * len(tokens) # 每個token作為答案結束的得分
# 找到答案在上下文中的位置 ("1921年")
answer_start_index = tokens.index("1921")
answer_end_index = tokens.index("1921") # 單token答案
# 設置高分 (模擬BERT的輸出)
start_scores[answer_start_index] = 9.8
end_scores[answer_end_index] = 9.7
print(f"\n答案開始位置預測得分 (部分): {start_scores[30:40]}...")
print(f"答案結束位置預測得分 (部分): {end_scores[30:40]}...")
print(f"預測答案: {tokens[answer_start_index]}\n")
# 6. 下游任務處理 - 使用Qwen API進行問答
print("6. 下游任務處理: 答案提取(使用Qwen API)")
# 構建Prompt - 明確指示模型從上下文中提取答案
prompt = f"""
請根據以下上下文回答問題。請直接從上下文中提取答案,不要自己生成答案。
上下文: "{context}"
問題: "{question}"
請按以下JSON格式輸出結果:
{{
"answer": "提取的答案",
"confidence": 0.95,
"start_index": 答案在上下文中的起始位置,
"end_index": 答案在上下文中的結束位置
}}
"""
# 準備API請求
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
payload = {
"model": "qwen-max",
"input": {
"messages": [
{
"role": "system",
"content": "你是一個問答系統專家,能夠準確從給定上下文中提取答案。請嚴格按照要求的JSON格式輸出結果。"
},
{
"role": "user",
"content": prompt
}
]
},
"parameters": {
"result_format": "text",
"max_tokens": 150,
"temperature": 0.1 # 低温度確保輸出穩定
}
}
print("調用Qwen API進行答案提取...")
try:
response = requests.post(API_URL, headers=headers, data=json.dumps(payload))
response.raise_for_status()
result = response.json()
if "output" in result and "text" in result["output"]:
answer_result = result["output"]["text"]
# answer_result = result["output"]["choices"][0]["message"]["content"]
print("\n答案提取結果:")
# 嘗試解析JSON結果
try:
json_match = re.search(r'\{.*\}', answer_result, re.DOTALL)
if json_match:
answer_data = json.loads(json_match.group())
print(json.dumps(answer_data, ensure_ascii=False, indent=2))
# 驗證答案
if answer_data.get("answer") == "1921年":
print("✓ 答案正確!")
else:
print("✗ 答案不正確!")
else:
print(answer_result)
except json.JSONDecodeError:
print(answer_result)
else:
print("API響應格式異常")
except Exception as e:
print(f"API請求失敗: {e}")
# 模擬API響應
print("\n模擬答案提取結果:")
print("""
{
"answer": "1921年",
"confidence": 0.95,
"start_index": 105,
"end_index": 110
}
""")
print("✓ 答案正確!")
# 7. 傳統BERT答案跨度預測方法説明
print("\n" + "="*60)
print("傳統BERT答案跨度預測方法與Qwen API方法對比")
print("="*60)
print("""
傳統BERT答案跨度預測方法:
1. 將問題和上下文拼接為: [CLS] question [SEP] context [SEP]
2. 通過BERT編碼獲取每個token的上下文表示
3. 使用兩個線性分類器:
- 一個預測答案開始的token位置
- 一個預測答案結束的token位置
4. 通過softmax計算每個token作為開始/結束位置的概率
5. 選擇概率最高的開始和結束位置作為答案跨度
Qwen API方法:
1. 利用生成式大模型的強大理解能力
2. 通過提示詞指導模型從上下文中提取答案
3. 直接輸出結構化的答案信息
4. 無需訓練專門的問答模型
優勢對比:
- 傳統方法: 精度高,可解釋性強,但需要標註數據和模型訓練
- API方法: 無需訓練,快速部署,適應多種問答場景,但依賴提示詞設計
""")
# 8. 答案驗證和評估
print("\n8. 答案驗證和評估")
print("對比傳統BERT方法和Qwen API方法的答案提取結果:")
print(f"問題: {question}")
print(f"上下文: {context}")
print(f"正確答案: '1921年'")
print("""
評估指標:
- 精確匹配(EM): 預測答案與標準答案是否完全一致
- F1分數: 預測答案與標準答案之間的重疊程度
- 位置準確性: 預測的起始和結束位置是否準確
""")
4.2 輸出結果
============================================================
BERT答案跨度預測處理流程示例
============================================================
上下文: 愛因斯坦(Albert Einstein)1879年3月14日出生於德國烏爾姆市,是現代物理學的奠基人之一。他提出了相對論和質能方程E=mc²,並於1921年獲得諾貝爾物理學獎。
愛因斯坦於1955年4月18日在美國新澤西州普林斯頓去世。
問題: 愛因斯坦在哪一年獲得諾貝爾獎?
1. 文本預處理:添加特殊標記
處理後: [CLS] 愛因斯坦在哪一年獲得諾貝爾獎? [SEP] 愛因斯坦(Albert Einstein)1879年3月14日出生於德國烏爾姆市,是現代物理學的奠基人之一。他提出了相對論和質
能方程E=mc²,...
2. Tokenization:文本分詞
分詞結果 (前20個token): ['[CLS]', '愛', '因', '斯', '坦', '在', '哪', '一', '年', '獲', '得', '諾', '貝', '爾', '獎', '?', '[SEP]', '愛', '因', '斯']...
3. 創建輸入表示
Token Embeddings (前10個): ['Token_[CLS]', 'Token_愛', 'Token_因', 'Token_斯', 'Token_坦', 'Token_在', 'Token_哪', 'Token_一', 'Token_年', 'Token_獲']...
Segment Embeddings (前10個): ['Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0']...
Position Embeddings (前10個): ['Position_0', 'Position_1', 'Position_2', 'Position_3', 'Position_4', 'Position_5', 'Position_6', 'Position_7', 'Position_8', 'Position_9']...
4. BERT模型內部處理
- 輸入嵌入表示 -> Transformer編碼器×12/24層
- 自注意力機制計算: 問題token與上下文token之間計算交叉注意力
- 前饋神經網絡處理: 對每個位置的表示進行非線性變換
- 層歸一化 & 殘差連接: 確保訓練穩定性和梯度流動
- 經過多層編碼器處理: 逐步提煉問題和上下文之間的關係
5. 輸出表示 - 答案跨度預測重點
生成每個token的上下文表示向量:
- 每個token的向量包含問題和上下文的交互信息
- 特別關注上下文部分的token表示
答案開始位置預測得分 (部分): [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]...
答案結束位置預測得分 (部分): [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]...
預測答案: 1921
6. 下游任務處理: 答案提取(使用Qwen API)
調用Qwen API進行答案提取...
答案提取結果:
{
"answer": "1921年",
"confidence": 0.95,
"start_index": 46,
"end_index": 51
}
✓ 答案正確!
============================================================
傳統BERT答案跨度預測方法與Qwen API方法對比
============================================================
傳統BERT答案跨度預測方法:
1. 將問題和上下文拼接為: [CLS] question [SEP] context [SEP]
2. 通過BERT編碼獲取每個token的上下文表示
3. 使用兩個線性分類器:
- 一個預測答案開始的token位置
- 一個預測答案結束的token位置
4. 通過softmax計算每個token作為開始/結束位置的概率
5. 選擇概率最高的開始和結束位置作為答案跨度
Qwen API方法:
1. 利用生成式大模型的強大理解能力
2. 通過提示詞指導模型從上下文中提取答案
3. 直接輸出結構化的答案信息
4. 無需訓練專門的問答模型
優勢對比:
- 傳統方法: 精度高,可解釋性強,但需要標註數據和模型訓練
- API方法: 無需訓練,快速部署,適應多種問答場景,但依賴提示詞設計
8. 答案驗證和評估
對比傳統BERT方法和Qwen API方法的答案提取結果:
問題: 愛因斯坦在哪一年獲得諾貝爾獎?
上下文: 愛因斯坦(Albert Einstein)1879年3月14日出生於德國烏爾姆市,是現代物理學的奠基人之一。他提出了相對論和質能方程E=mc²,並於1921年獲得諾貝爾物理學獎。
愛因斯坦於1955年4月18日在美國新澤西州普林斯頓去世。
正確答案: '1921年'
評估指標:
- 精確匹配(EM): 預測答案與標準答案是否完全一致
- F1分數: 預測答案與標準答案之間的重疊程度
- 位置準確性: 預測的起始和結束位置是否準確
4.3 代碼流程説明
4.3.1 文本預處理
- 操作:對於問答任務,BERT的輸入格式為 [CLS] question [SEP] context [SEP]
- 目的:明確區分問題和上下文部分,使模型能夠理解兩者的關係
- 示例結果:[CLS] 愛因斯坦在哪一年獲得諾貝爾獎? [SEP] 愛因斯坦(Albert Einstein)1879年3月14日出生於德國烏爾姆市... [SEP]
4.3.2 Tokenization(分詞)
- 操作:將文本分割成單詞或子詞單元
- 多語言處理:中英文混合文本需要特殊處理,英文按WordPiece分詞,中文按字符或詞語分詞
- 示例結果:['[CLS]', '愛', '因', '斯', '坦', '在', '哪', '一', '年', '獲', '得', '諾', '貝', '爾', '獎', '?', '[SEP]', '愛', '因', '斯', '坦', ...]
4.3.3 創建輸入表示
- 操作:將每個token轉換為數值向量表示
- Segment Embeddings:用於區分問題部分(0)和上下文部分(1)
- Position Embeddings:提供每個token在序列中的位置信息
- Token Embeddings:捕獲詞彙語義信息
- 目的:為模型提供豐富的問題-上下文交互信息
4.3.4 BERT模型內部處理
- 操作:通過多層Transformer編碼器處理輸入表示
- 交叉注意力:問題token與上下文token之間計算注意力權重,捕獲相關問題部分
- 深層交互:通過多層編碼,逐步提煉問題和上下文之間的關係
- 上下文編碼:為每個上下文token生成包含問題信息的表示
4.3.5 輸出表示 - 答案跨度預測重點
- 操作:獲取每個token經過BERT處理後的最終隱藏狀態
- 開始位置分類器:線性層將每個token的表示映射為標量分數,表示該token作為答案開始的概率
- 結束位置分類器:另一個線性層預測每個token作為答案結束的概率
- Softmax計算:對所有上下文token計算開始和結束概率分佈
- 答案提取:選擇開始概率最高的token和結束概率最高的token作為答案跨度
4.3.6.下游任務處理 - 使用Qwen API進行答案提取
- 操作:使用Qwen API進行答案提取,模擬BERT答案跨度預測的輸出格式
- 提示工程設計:精心設計的提示詞指導模型從上下文中提取答案並輸出結構化結果
- 輸出格式:JSON格式包含答案文本、置信度和位置信息
- 優勢:無需訓練專用模型,快速實現問答功能
5. 示例四:句子相似度計算
5.1 代碼示例
import requests
import json
import re
import numpy as np
import os
# 配置Qwen API
API_KEY = os.environ.get("DASHSCOPE_API_KEY") # 請替換為您的實際API密鑰
API_URL = "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation"
# 示例輸入 - 句子對相似度計算
sentence1 = "人工智能正在改變世界"
sentence2 = "AI技術正在重塑我們的生活"
print("="*60)
print("BERT句子相似度計算處理流程示例")
print("="*60)
print(f"句子1: {sentence1}")
print(f"句子2: {sentence2}\n")
# 1. 文本預處理:添加CLS和SEP標記
print("1. 文本預處理:添加特殊標記")
# 對於句子對任務,BERT的輸入格式為: [CLS] sentence1 [SEP] sentence2 [SEP]
processed_text = f"[CLS] {sentence1} [SEP] {sentence2} [SEP]"
print(f"處理後: {processed_text}\n")
# 2. Tokenization:將文本分割為單詞/子詞
print("2. Tokenization:文本分詞")
# 模擬BERT的中文分詞過程
tokens = [
"[CLS]", "人", "工", "智", "能", "正", "在", "改", "變", "世", "界", "[SEP]",
"AI", "技", "術", "正", "在", "重", "塑", "我", "們", "的", "生", "活", "[SEP]"
]
print(f"分詞結果: {tokens}\n")
# 3. 創建輸入表示:Token + Segment + Position Embeddings
print("3. 創建輸入表示")
# 對於句子對任務,需要區分兩個句子
segment_ids = []
for i, token in enumerate(tokens):
if token == "[SEP]":
# 找到第一個SEP標記後的索引
first_sep_index = tokens.index("[SEP]")
if i <= first_sep_index:
segment_ids.append(0) # 第一個句子部分
else:
segment_ids.append(1) # 第二個句子部分
else:
if i <= tokens.index("[SEP]"):
segment_ids.append(0) # 第一個句子部分
else:
segment_ids.append(1) # 第二個句子部分
# 簡化表示
token_embeddings = [f"Token_{token}" for token in tokens]
segment_embeddings = [f"Segment_{seg}" for seg in segment_ids]
position_embeddings = [f"Position_{i}" for i in range(len(tokens))]
print(f"Token Embeddings (前10個): {token_embeddings[:10]}...")
print(f"Segment Embeddings (前10個): {segment_embeddings[:10]}...")
print(f"Position Embeddings (前10個): {position_embeddings[:10]}...\n")
# 4. BERT模型內部處理(模擬)
print("4. BERT模型內部處理")
print(" - 輸入嵌入表示 -> Transformer編碼器×12/24層")
print(" - 自注意力機制計算: 兩個句子的token之間計算交叉注意力")
print(" - 前饋神經網絡處理: 對每個位置的表示進行非線性變換")
print(" - 層歸一化 & 殘差連接: 確保訓練穩定性和梯度流動")
print(" - 經過多層編碼器處理: 逐步提煉兩個句子之間的關係\n")
# 5. 輸出表示 - 句子相似度計算重點
print("5. 輸出表示 - 句子相似度計算重點")
print("生成每個token的上下文表示向量:")
print(" - [CLS]標記的向量包含兩個句子的聚合信息")
print(" - 特別關注[CLS]標記的輸出,用於句子級分類任務")
# 實際調用BERT模型計算相似度
print("\n實際調用BERT模型計算相似度...")
from transformers import BertTokenizer, BertModel
import torch
# 加載中文BERT模型和分詞器
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertModel.from_pretrained('bert-base-chinese')
# 對輸入句子進行編碼
inputs = tokenizer(sentence1, sentence2, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
outputs = model(**inputs)
# 提取[CLS]標記的向量
cls_vector = outputs.last_hidden_state[:, 0, :].numpy()[0]
print(f"[CLS]標記輸出向量: 維度{cls_vector.shape}, 範數{np.linalg.norm(cls_vector):.4f}")
# 計算餘弦相似度
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# 分別計算兩個句子的[CLS]向量
inputs1 = tokenizer(sentence1, return_tensors="pt", padding=True, truncation=True)
inputs2 = tokenizer(sentence2, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
outputs1 = model(**inputs1)
outputs2 = model(**inputs2)
cls_vector1 = outputs1.last_hidden_state[:, 0, :].numpy()[0]
cls_vector2 = outputs2.last_hidden_state[:, 0, :].numpy()[0]
# 計算餘弦相似度
similarity_score = cosine_similarity(cls_vector1, cls_vector2)
print(f"餘弦相似度: {similarity_score:.4f}\n")
# 6. 下游任務處理 - 使用Qwen API進行句子相似度計算
print("6. 下游任務處理: 句子相似度計算(使用Qwen API)")
# 構建Prompt - 明確指示模型計算句子相似度
prompt = f"""
請評估以下兩個句子的語義相似度,給出一個0到1之間的相似度分數,其中0表示完全不相關,1表示完全等價。
句子1: "{sentence1}"
句子2: "{sentence2}"
請按以下JSON格式輸出結果:
{{
"similarity_score": 0.85,
"explanation": "簡要解釋相似度評分的原因"
}}
"""
# 準備API請求
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
payload = {
"model": "qwen-max",
"input": {
"messages": [
{
"role": "system",
"content": "你是一個語義相似度評估專家,能夠準確判斷兩個句子的語義相似程度。請給出0到1之間的相似度分數,並簡要解釋評分原因。"
},
{
"role": "user",
"content": prompt
}
]
},
"parameters": {
"result_format": "text",
"max_tokens": 150,
"temperature": 0.1 # 低温度確保輸出穩定
}
}
print("調用Qwen API進行句子相似度計算...")
try:
response = requests.post(API_URL, headers=headers, data=json.dumps(payload))
response.raise_for_status()
result = response.json()
if "output" in result and "text" in result["output"]:
similarity_result = result["output"]["text"]
print("\n句子相似度計算結果:")
# 嘗試解析JSON結果
try:
json_match = re.search(r'\{.*\}', similarity_result, re.DOTALL)
if json_match:
similarity_data = json.loads(json_match.group())
print(json.dumps(similarity_data, ensure_ascii=False, indent=2))
else:
print(similarity_result)
except json.JSONDecodeError:
print(similarity_result)
else:
print("API響應格式異常")
except Exception as e:
print(f"API請求失敗: {e}")
# 模擬API響應
print("\n模擬句子相似度計算結果:")
print("""
{
"similarity_score": 0.82,
"explanation": "兩個句子都表達了人工智能技術對世界的積極影響,雖然用詞不同但核心語義相似"
}
""")
# 7. 傳統BERT句子相似度計算方法説明
print("\n" + "="*60)
print("傳統BERT句子相似度計算方法與Qwen API方法對比")
print("="*60)
print("""
傳統BERT句子相似度計算方法:
1. 將兩個句子拼接為: [CLS] sentence1 [SEP] sentence2 [SEP]
2. 通過BERT編碼獲取每個token的上下文表示
3. 使用[CLS]標記的輸出向量作為整個句子對的表示
4. 在[CLS]向量上添加線性分類層或迴歸層:
- 分類方法: 將相似度分為幾個等級(如0-4分)
- 迴歸方法: 直接輸出0-1之間的相似度分數
5. 使用餘弦相似度作為替代方法:
- 分別計算每個句子的[CLS]向量
- 計算兩個向量的餘弦相似度
Qwen API方法:
1. 利用生成式大模型的語義理解能力
2. 通過提示詞指導模型評估句子相似度
3. 直接輸出結構化的相似度分數和解釋
4. 無需訓練專門的相似度模型
優勢對比:
- 傳統方法: 計算效率高,可部署在資源受限環境,但需要訓練數據和模型訓練
- API方法: 無需訓練,理解能力強,能提供解釋,但依賴網絡連接和API成本
""")
# 8. 相似度計算方法擴展
print("\n8. 相似度計算方法擴展")
print("除了整體相似度,還可以計算不同層面的相似度:")
print("""
1. 詞彙層面相似度:
- Jaccard相似度: 計算兩個句子詞彙集合的重疊程度
- 詞嵌入餘弦相似度: 計算句子平均詞向量的餘弦相似度
2. 語義層面相似度:
- BERT句子嵌入: 使用[CLS]向量或所有token向量的平均
- SBERT(Sentence-BERT): 專門優化的句子嵌入模型
3. 結構層面相似度:
- 句法樹相似度: 比較兩個句子的句法結構
- 依存關係相似度: 比較句子的依存關係圖
4. 生成式方法:
- 使用LLM評估: 如本示例中的Qwen API方法
- 自然語言推理: 判斷兩個句子是否藴含、矛盾或中立
""")
# 9. 應用場景示例
print("\n9. 應用場景示例")
print("句子相似度計算在實際應用中的場景:")
application_scenarios = [
"搜索引擎: 查詢和文檔的相似度匹配",
"推薦系統: 用户歷史行為和候選項目的相似度計算",
"重複檢測: 識別文檔中的重複或近似重複內容",
"問答系統: 問題和候選答案的相似度評估",
"文本摘要: 評估摘要與原文的語義一致性",
"機器翻譯評估: 比較原文和譯文的語義等價性",
" plagiarism檢測: 識別文本之間的相似性"
]
for i, scenario in enumerate(application_scenarios, 1):
print(f" {i}. {scenario}")
5.2 輸出結果
============================================================
BERT句子相似度計算處理流程示例
============================================================
句子1: 人工智能正在改變世界
句子2: AI技術正在重塑我們的生活
1. 文本預處理:添加特殊標記
處理後: [CLS] 人工智能正在改變世界 [SEP] AI技術正在重塑我們的生活 [SEP]
2. Tokenization:文本分詞
分詞結果: ['[CLS]', '人', '工', '智', '能', '正', '在', '改', '變', '世', '界', '[SEP]', 'AI', '技', '術', '正', '在', '重', '塑', '我', '們', '的', '生', '活', '[SEP]']
3. 創建輸入表示
Token Embeddings (前10個): ['Token_[CLS]', 'Token_人', 'Token_工', 'Token_智', 'Token_能', 'Token_正', 'Token_在', 'Token_改', 'Token_變', 'Token_世']...
Segment Embeddings (前10個): ['Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0']...
Position Embeddings (前10個): ['Position_0', 'Position_1', 'Position_2', 'Position_3', 'Position_4', 'Position_5', 'Position_6', 'Position_7', 'Position_8', 'Position_9']...
4. BERT模型內部處理
- 輸入嵌入表示 -> Transformer編碼器×12/24層
- 自注意力機制計算: 兩個句子的token之間計算交叉注意力
- 前饋神經網絡處理: 對每個位置的表示進行非線性變換
- 層歸一化 & 殘差連接: 確保訓練穩定性和梯度流動
- 經過多層編碼器處理: 逐步提煉兩個句子之間的關係
5. 輸出表示 - 句子相似度計算重點
生成每個token的上下文表示向量:
- [CLS]標記的向量包含兩個句子的聚合信息
- 特別關注[CLS]標記的輸出,用於句子級分類任務
實際調用BERT模型計算相似度...
[CLS]標記輸出向量: 維度(768,), 範數22.5603
餘弦相似度: 0.8570
6. 下游任務處理: 句子相似度計算(使用Qwen API)
調用Qwen API進行句子相似度計算...
句子相似度計算結果:
{
"similarity_score": 0.85,
"explanation": "兩個句子都表達了人工智能或AI技術對社會產生重大影響的意思。雖然使用了不同的詞彙('改變世界' vs '重塑我們的生活'),但核心含義非常接近,都是
指AI帶來的廣泛變革。因此,它們在語義上高度相似,但由於不是完全相同的表達方式,所以評分略低於1。"
}
============================================================
傳統BERT句子相似度計算方法與Qwen API方法對比
============================================================
傳統BERT句子相似度計算方法:
1. 將兩個句子拼接為: [CLS] sentence1 [SEP] sentence2 [SEP]
2. 通過BERT編碼獲取每個token的上下文表示
3. 使用[CLS]標記的輸出向量作為整個句子對的表示
4. 在[CLS]向量上添加線性分類層或迴歸層:
- 分類方法: 將相似度分為幾個等級(如0-4分)
- 迴歸方法: 直接輸出0-1之間的相似度分數
5. 使用餘弦相似度作為替代方法:
- 分別計算每個句子的[CLS]向量
- 計算兩個向量的餘弦相似度
Qwen API方法:
1. 利用生成式大模型的語義理解能力
2. 通過提示詞指導模型評估句子相似度
3. 直接輸出結構化的相似度分數和解釋
4. 無需訓練專門的相似度模型
優勢對比:
- 傳統方法: 計算效率高,可部署在資源受限環境,但需要訓練數據和模型訓練
- API方法: 無需訓練,理解能力強,能提供解釋,但依賴網絡連接和API成本
8. 相似度計算方法擴展
除了整體相似度,還可以計算不同層面的相似度:
1. 詞彙層面相似度:
- Jaccard相似度: 計算兩個句子詞彙集合的重疊程度
- 詞嵌入餘弦相似度: 計算句子平均詞向量的餘弦相似度
2. 語義層面相似度:
- BERT句子嵌入: 使用[CLS]向量或所有token向量的平均
- SBERT(Sentence-BERT): 專門優化的句子嵌入模型
3. 結構層面相似度:
- 句法樹相似度: 比較兩個句子的句法結構
- 依存關係相似度: 比較句子的依存關係圖
4. 生成式方法:
- 使用LLM評估: 如本示例中的Qwen API方法
- 自然語言推理: 判斷兩個句子是否藴含、矛盾或中立
9. 應用場景示例
句子相似度計算在實際應用中的場景:
1. 搜索引擎: 查詢和文檔的相似度匹配
2. 推薦系統: 用户歷史行為和候選項目的相似度計算
3. 重複檢測: 識別文檔中的重複或近似重複內容
4. 問答系統: 問題和候選答案的相似度評估
5. 文本摘要: 評估摘要與原文的語義一致性
6. 機器翻譯評估: 比較原文和譯文的語義等價性
7. plagiarism檢測: 識別文本之間的相似性
5.3 代碼流程説明
5.3.1 文本預處理
- 操作:對於句子對任務,BERT的輸入格式為 [CLS] sentence1 [SEP] sentence2 [SEP]
- 目的:明確區分兩個句子,使模型能夠理解句子間的關係
- [CLS]:位於序列開頭,其輸出向量用於句子級分類任務
- [SEP]:分隔兩個句子,標記句子邊界
- 示例結果:[CLS] 人工智能正在改變世界 [SEP] AI技術正在重塑我們的生活 [SEP]
5.3.2 Tokenization(分詞)
- 操作:將文本分割成單詞或子詞單元
- 中文處理:中文通常按字符分詞,或使用專用分詞器
- 多語言處理:處理中英文混合文本時需要特殊考慮
- 示例結果:['[CLS]', '人', '工', '智', '能', '正', '在', '改', '變', '世', '界', '[SEP]', 'AI', '技', '術', '正', '在', '重', '塑', '我', '們', '的', '生', '活', '[SEP]']
5.3.3 創建輸入表示
- 操作:將每個token轉換為數值向量表示
- Segment Embeddings:用於區分第一個句子(0)和第二個句子(1)
- Position Embeddings:提供每個token在序列中的位置信息
- Token Embeddings:捕獲詞彙語義信息
- 目的:為模型提供豐富的句子間交互信息
5.3.4 BERT模型內部處理
- 操作:通過多層Transformer編碼器處理輸入表示
- 交叉注意力:兩個句子的token之間計算注意力權重,捕獲語義關聯
- 深層交互:通過多層編碼,逐步提煉兩個句子之間的關係
- [CLS]標記編碼:聚合整個序列信息,生成句子級表示
5.3.5 輸出表示 - 句子相似度計算重點
- 操作:獲取每個token經過BERT處理後的最終隱藏狀態
- [CLS]標記向量:作為整個句子對的聚合表示,用於相似度計算
- 分類層:線性層將[CLS]向量映射到相似度分數
- 替代方法:分別計算兩個句子的[CLS]向量,然後計算餘弦相似度
- 相似度分數:通常為0-1之間的值,表示兩個句子的語義相似程度
5.3.6 下游任務處理 - 使用Qwen API進行句子相似度計算
- 操作:使用Qwen API進行相似度計算,模擬BERT句子相似度評估
- 提示工程設計:精心設計的提示詞指導模型評估句子相似度並輸出結構化結果
- 輸出格式:JSON格式包含相似度分數和解釋
- 優勢:無需訓練專用模型,快速實現相似度計算功能
六、BERT的優勢與特點
- 雙向上下文理解: 與單向語言模型相比,BERT能同時利用上下文信息,對詞彙的理解更準確。
- 強大的通用性: 預訓練後的BERT是一個“基礎模型”,可以通過微調輕鬆適配到多種下游任務,無需從頭開始為特定任務設計模型結構。
- 卓越的性能: 在發佈時,它在11個NLP任務上刷新了最佳性能記錄。
- 豐富的生態系統: 擁有多種預訓練版本(如 bert-base-uncased, bert-large-uncased)和多語言版本,並被集成到Hugging Face等主流框架中,易於使用。
七、BERT的應用場景
除了基礎文本分類和問答,BERT的應用與現在的行業也息息相關,它已成為NLP領域的“基礎設施”,被嵌入到無數產品和流程中。
1. 搜索引擎優化
- 工作原理: 現代搜索引擎(如Google、Bing)早已超越簡單的關鍵詞匹配。它們使用BERT等模型來理解搜索查詢的語義和上下文。
- 範例:
- 過去搜索: “2025年武漢到杭州旅遊攻略” 可能返回關於武漢和杭州旅遊住宿的普通頁面。
- 使用BERT後: 搜索引擎能更好地理解“到”等介詞的重要性。這個查詢會更精確地返回2025年武漢旅客前往杭州所需文件的結果,因為它理解了杭州是目的地。
2.智能客服與聊天機器人
- 工作原理: BERT用於理解用户提問的意圖和情感,並從知識庫中檢索最相關的答案。
- 範例:
- 你向銀行客服聊天機器人輸入:“我上次的那筆轉賬好像沒成功,能幫我查下嗎?”
- BERT模型會:1. 理解意圖-->查詢交易狀態; 2. 分析實體-->“上次”(時間)、“轉賬”(操作類型); 3. 判斷情感: “好像沒成功”帶有一絲不確定和焦慮,可能需要優先處理或更友好的回覆。系統隨後從交易記錄中精準檢索並回復。
3. 內容推薦與信息流
- 工作原理: 社交媒體和新聞App(如Facebook, 今日頭條)使用BERT來理解用户閲讀內容的深層主題、觀點和情感,從而推薦語義相似的新內容,而不僅僅是包含相同關鍵詞的內容。
- 範例: 你閲讀了一篇關於“電動汽車電池技術突破”的文章。系統不會僅僅推薦包含“汽車”和“電池”的文章,而是能理解核心是“技術”、“創新”、“環保”,從而推薦一篇關於“固態電池研發進展”或“可持續能源”的文章。
4. 法律與金融文檔分析
- 工作原理: 利用BERT的序列標註和分類能力,從冗長的合同、財報或法律文書中快速提取關鍵信息。
- 範例:
- 法律: 自動識別合同中的“責任條款”、“違約金額”、“簽約方”等實體,生成摘要,比對不同合同版本的差異。
- 金融: 分析公司財報和新聞,判斷市場情緒是“樂觀”還是“悲觀”,用於風險預警和投資決策。
5. 語音助手與智能音箱
- 工作原理: 語音識別將語音轉為文本後,BERT等模型負責理解文本指令的深層含義和上下文。
- 範例: 你對智能音箱説:“把燈調亮一點,太暗了。” BERT模型能理解“調亮”是操作,“燈”是對象,“太暗”是原因和程度,從而準確執行指令。它還能理解上下文,比如你接着説:“還是太暗了”,它會知道“還是”指的是上一次的操作,並繼續調亮。
八、總結
最後,腦袋裏可能還是會有一個疑問,BERT到底是什麼?似乎説不清、道不明。其實,它就是一個通過海量“完形填空”訓練出來的、能深刻理解人類語言上下文含義的超級語言模型。
它的革命性在於:
- 雙向理解:能同時利用上下文信息,理解能力暴增。
- 預訓練-微調:先通讀海量書籍成為“學霸”,再稍加練習就能成為任何領域的“專家”,極大降低了AI應用的門檻。
雖然現在很多生成式AI光芒四射,但BERT作為“理解”領域的基石,依然默默地支撐着互聯網的方方面面,讓你我的數字生活變得更加智能和便捷。它無疑是人工智能發展史上的一座重要里程碑。