

什麼是Java Tabula Extractor?
Java Tabula Extractor 是一個基於tabula-java開發的Java庫,專門用於從PDF文件中提取表格數據。無論你是需要處理財務報表、數據報表還是其他包含表格的PDF文檔,這個庫都能幫你自動化完成數據提取工作。
核心功能特性
多功能支持
從PDF文件中精準提取表格數據
支持多種輸出格式(CSV、TSV、JSON)
支持指定特定區域進行提取
提供多種提取算法(流式、網格等)
靈活的部署選項
提供兩種JAR包滿足不同需求:
根據Tabula源碼進行修改編譯,重新打包更適合java項目中使用的jar包,可根據綁定資源自行下載(文件存放在:解壓後的tabula-master\java-tabula-extractor\target目錄下):
標準版JAR (java-tabula-extractor-1.0.0.jar) - 文件較小,需手動添加依賴
完整版JAR (java-tabula-extractor-1.0.0-shaded.jar) - 包含所有依賴,開箱即用
快速開始
環境準備
根據你的項目需求選擇合適的JAR包:
方案一:使用完整版JAR(推薦新手)
直接將 java-tabula-extractor-1.0.0-shaded.jar 添加到項目依賴中,無需其他配置。
方案二:使用標準版JAR
如果你使用標準版JAR,需要額外添加以下依賴:
<!-- Maven 依賴 -->
<dependency>
<groupId>technology.tabula</groupId>
<artifactId>tabula</artifactId>
<version>1.0.4</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.26</version>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.9</version>
</dependency>基礎使用示例
讓我們通過一個簡單的例子來看看如何使用這個庫:
import technology.tabula.PdfTableExtractor;
import technology.tabula.TabulaAPI;
import java.io.IOException;
import java.util.Arrays;
import java.util.List;
public class PdfTableExtractionExample {
public static void main(String[] args) {
try {
// 1. 定義要提取的表格區域 (頁碼, x1, y1, x2, y2)
PdfTableExtractor.TableRegion region =
new PdfTableExtractor.TableRegion(1, 50, 50, 500, 300);
List<PdfTableExtractor.TableRegion> regions = Arrays.asList(region);
// 2. 提取表格並輸出為CSV
String csvResult = TabulaAPI.extractTablesAsCSV("財務報表.pdf", regions);
// 3. 保存結果到文件
boolean success = saveCsvToFile(csvResult, "提取結果.csv", false);
if (success) {
System.out.println("表格提取成功!");
System.out.println("提取內容:");
System.out.println(csvResult);
}
} catch (IOException e) {
System.err.println("提取失敗: " + e.getMessage());
e.printStackTrace();
}
}
// 保存CSV文件的輔助方法
public static boolean saveCsvToFile(String csvContent, String filePath, boolean append) {
// 實現文件保存邏輯
return true;
}
}高級功能展示
1. 多種輸出格式支持
// 輸出為不同格式
String csv = TabulaAPI.extractTablesAsCSV("document.pdf", regions);
String tsv = TabulaAPI.extractTablesAsTSV("document.pdf", regions);
String json = TabulaAPI.extractTablesAsJSON("document.pdf", regions);
// 或者動態指定輸出格式
String result = TabulaAPI.extractTables("document.pdf", regions, "csv"); // 支持 "tsv", "json"2. 多種提取算法
PdfTableExtractor.TableRegion region = new PdfTableExtractor.TableRegion(1, 50, 50, 500, 300);
// 根據表格類型選擇合適的提取算法
region.setExtractionMethod(PdfTableExtractor.ExtractionMethod.LATTICE); // 網格表格
region.setExtractionMethod(PdfTableExtractor.ExtractionMethod.STREAM); // 流式表格
region.setExtractionMethod(PdfTableExtractor.ExtractionMethod.SPREADSHEET);// 電子表格
region.setExtractionMethod(PdfTableExtractor.ExtractionMethod.BASIC); // 基礎算法
region.setExtractionMethod(PdfTableExtractor.ExtractionMethod.GUESS); // 自動猜測3. 多區域提取
// 提取PDF中多個不同區域的表格
List<PdfTableExtractor.TableRegion> regions = Arrays.asList(
new PdfTableExtractor.TableRegion(1, 50, 50, 300, 200), // 第一個表格區域
new PdfTableExtractor.TableRegion(1, 50, 250, 300, 400), // 第二個表格區域
new PdfTableExtractor.TableRegion(2, 50, 50, 500, 300) // 第三頁的表格區域
);
String result = TabulaAPI.extractTablesAsCSV("多表格文檔.pdf", regions);核心API詳解
TableRegion類
PdfTableExtractor.TableRegion 用於定義要提取的表格區域:
// 創建表格區域
TableRegion region = new TableRegion(
1, // 頁碼(從1開始)
50, // 左上角x座標
50, // 左上角y座標
500, // 右下角x座標
300 // 右下角y座標
);
// 設置提取方法
region.setExtractionMethod(PdfTableExtractor.ExtractionMethod.LATTICE);
// 設置輸出格式
region.setOutputFormat("csv");座標系統説明:座標系的原點位於頁面的左上角,向右為x軸正方向,向下為y軸正方向。
TabulaAPI類
主要靜態方法:
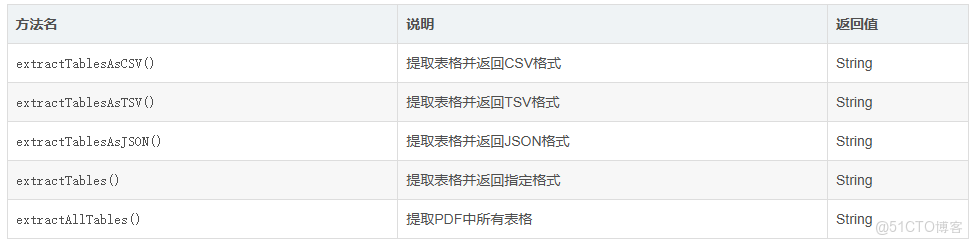
實戰案例:財務報表處理
假設我們需要從財務報表PDF中提取數據表:
public class FinancialReportProcessor {
public void processFinancialReport(String pdfPath) {
try {
// 定義財務報表區域(通常位於頁面中央)
List<PdfTableExtractor.TableRegion> regions = Arrays.asList(
new PdfTableExtractor.TableRegion(1, 100, 150, 500, 400)
);
// 使用網格算法提取(適合規整的財務報表)
regions.get(0).setExtractionMethod(PdfTableExtractor.ExtractionMethod.LATTICE);
// 提取數據
String csvData = TabulaAPI.extractTablesAsCSV(pdfPath, regions);
// 處理提取的數據
processExtractedData(csvData);
} catch (IOException e) {
System.err.println("處理財務報表失敗: " + e.getMessage());
}
}
private void processExtractedData(String csvData) {
// 這裏可以添加數據清洗、驗證等邏輯
String[] lines = csvData.split("\n");
System.out.println("成功提取 " + (lines.length - 1) + " 行數據");
// 保存到文件
saveCsvToFile(csvData, "財務數據.csv", false);
}
}常見問題解答
這個庫能處理掃描版的PDF嗎?
不能。Tabula只能處理基於文本的PDF,對於掃描版的圖片PDF需要先進行OCR識別。
如何確定表格的座標區域?
建議使用Tabula的原生桌面應用先進行可視化區域選擇,獲取準確座標後再在代碼中使用。
提取結果不準確怎麼辦?
嘗試不同的提取算法(LATTICE vs STREAM)
調整區域座標
檢查PDF文件質量
支持批量處理嗎?
庫本身專注於單個文件提取,但你可以輕鬆封裝批量處理邏輯:
public class BatchPdfProcessor {
public void processMultipleFiles(List<String> pdfFiles) {
for (String pdfFile : pdfFiles) {
try {
String result = TabulaAPI.extractAllTables(pdfFile);
// 處理每個文件的結果
} catch (IOException e) {
System.err.println("處理文件失敗: " + pdfFile);
}
}
}
}性能優化建議
- 合理選擇提取算法:根據表格特徵選擇最合適的算法
- 精確指定區域:避免提取不必要的區域內容
- 批量處理時注意內存:大文件批量處理時注意JVM內存配置
- 使用緩存機制:對於重複處理的文件可以考慮緩存結果
總結
Java Tabula Extractor是一個功能強大且易於使用的PDF表格提取工具,無論是處理簡單的數據表還是複雜的財務報表,它都能提供出色的解決方案。通過本文的介紹,相信你已經掌握了它的基本用法和高級特性。
主要優勢:
- 提取精度高
- 支持多種輸出格式
- 靈活的提取算法
- 完善的錯誤處理
- 活躍的社區支持
如果你在項目中需要處理PDF表格數據,不妨試試這個強大的工具,相信它會大大提高你的工作效率!