引言
在前面的學習中,我們會發現Python程序只能在安裝了Python的電腦上運行,處理中文文本比較困難,今天,我們將瞭解Python的第三方庫並學習其中的PyInstaller和jieba庫。PyInstaller庫:它能將Python程序打包成獨立的可執行文件,在任何電腦上都能運行。Jieba庫則可以幫助我們處理中文文本,中文分詞,它是專門為中文分詞設計的強大工具。
一、第三方庫 - Python的"超級市場"
1、什麼是第三方庫
第三方庫是由Python社區廣大開發者創建和維護的、提供各種專業功能的代碼集合,它們並不是Python安裝包自帶,因此需要用户自己通過包管理工具(如pip)進行額外安裝。這些庫擴展了Python的應用領域,例如,numpy為科學計算提供了強大的多維數組支持,pandas是進行數據分析和處理的利器,matplotlib用於創建靜態、交互式和動畫可視化,requests讓處理HTTP網絡請求變得異常簡單,beautifulsoup4專門用於從HTML和XML文檔中解析和提取數據,而tensorflow和pytorch這樣的框架則成了機器學習和深度學習項目的基礎。
2、第三方庫的鏡像地址
為了提升在國內下載第三方庫的速度,我們可以使用國內的鏡像源,通過 -i 參數指定鏡像如果希望設置默認鏡像以避免每次手動指定,可以使用 pip config set global.index-url 命令一次性配置,這樣後續的所有安裝命令都會自動從該鏡像源高速下載。
# 使用清華鏡像
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 庫名
# 使用阿里雲鏡像
pip install -i https://mirrors.aliyun.com/pypi/simple/ 庫名
# 使用豆瓣鏡像
pip install -i https://pypi.douban.com/simple/ 庫名3、第三方庫的安裝方法
要安裝Python第三方庫,我們主要使用名為pip的包管理工具,所有的安裝命令都需要在系統的命令行終端中執行,而非Python解釋器內部。其基本用法包括使用 pip install 庫名`來安裝最新版本的指定庫;可以通過 pip install 庫名==版本號來安裝某個特定版本;使用 pip install --upgrade 庫名來將已安裝的庫升級到最新版;當需要移除某個庫時,則使用 pip uninstall 庫名;此外,通過運行 pip list 可以方便地查看當前環境中所有已安裝的庫及其版本信息。
# 查看pip版本
pip --version
# 安裝庫(以requests為例)
pip install requests
# 安裝多個庫
pip install requests beautifulsoup4 pandas
# 從requirements.txt安裝
pip install -r requirements.txt
# 查看已安裝的庫
pip list
# 查看某個庫的詳細信息
pip show requests
# 生成requirements.txt文件
pip freeze > requirements.txt
# 卸載庫
pip uninstall requests二、PyInstaller庫 - 將Python程序變成獨立應用
1、PyInstaller庫的介紹和安裝
PyInstaller是一個用於將 Python 程序打包成獨立可執行文件的第三方工具。它能將程序代碼、Python 解釋器以及所有相關的依賴庫“封裝”在一起,從而生成一個無需預先安裝 Python 環境或任何第三方庫、在對應操作系統上可直接雙擊運行的應用程序。
安裝PyInstaller:
# 使用pip安裝
pip install pyinstaller
# 如果速度慢,可以使用國內鏡像
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyinstaller
# 驗證安裝是否成功,如果看到版本號,則安裝成功。
pyinstaller --version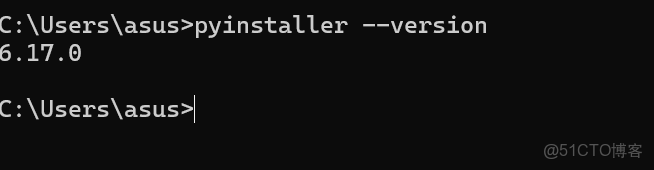
2、PyInstaller庫的使用
我們如果想要使用PyInstaller庫的話首先:
第一步:創建一個簡單的Python程序
# hello.py
name = input("請輸入你的名字:")
print(f"你好,{name}!這是一個打包後的Python程序。")第二步:使用PyInstaller打包
Pyinstaller 代碼文件路徑+代碼文件名# 基本打包命令
pyinstaller D:\python\PythonProject1 a2.py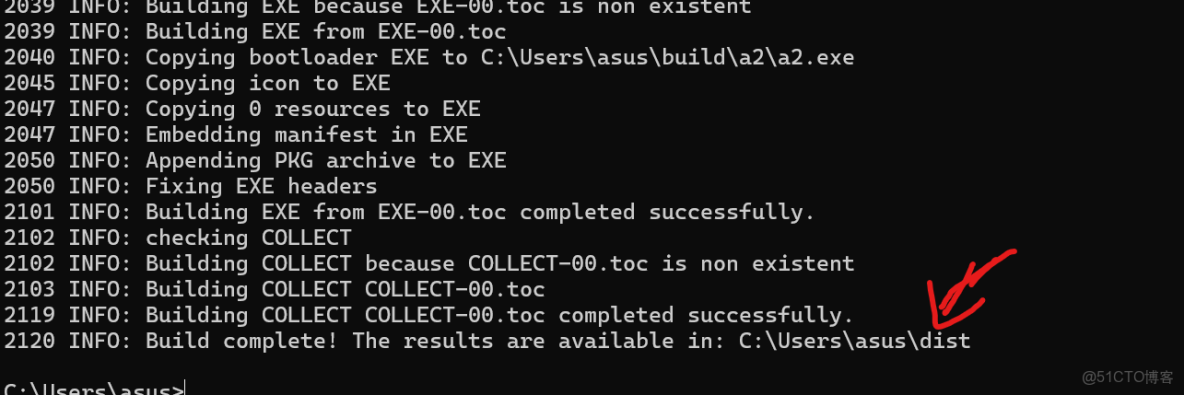
PyInstaller會分析hello.py,找出所有依賴的庫,創建一個build文件夾存放臨時文件,創建一個dist文件夾存放最終的可執行文件,在dist/hello文件夾中(Windows是dist/hello文件夾),你會找到可執行文件。

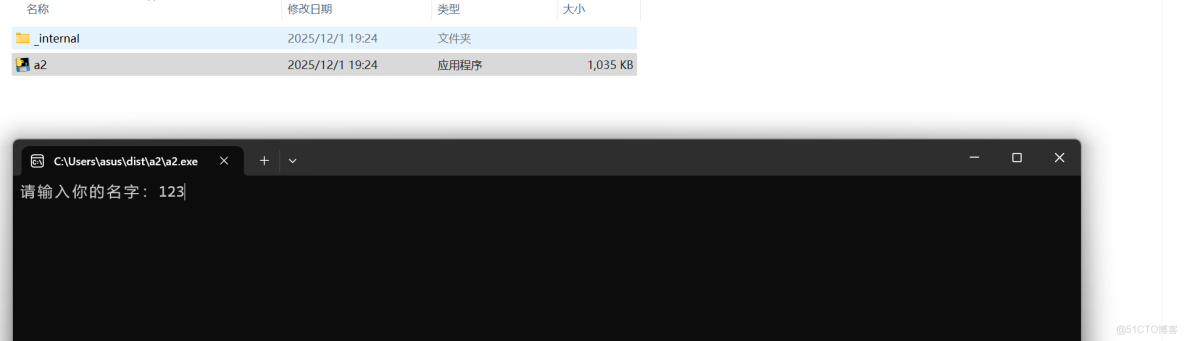
第三步:運行打包後的程序
Windows:雙擊dist/hello/hello.exe,Mac/Linux:在終端中運行./dist/hello/hello。現在即使電腦上沒有安裝Python,程序也能正常運行。
3、PyInstaller的高級用法
PyInstaller提供了許多有用的參數來自定義打包過程:
# 生成單個可執行文件(所有內容打包成一個exe)
pyinstaller -F hello.py
# 優點:只有一個文件,便於分發
# 缺點:啓動速度稍慢
# 生成單文件且不顯示命令行窗口(適合GUI程序)
pyinstaller -F -w calculator.py
# -w 表示不顯示控制枱窗口
# 添加圖標
pyinstaller -F -i myicon.ico hello.py
# 程序會使用myicon.ico作為圖標
# 隱藏導入的模塊(減少打包體積)
pyinstaller -F --hidden-import module_name hello.py
# 打包時排除某些模塊
pyinstaller -F --exclude-module unnecessary_module hello.py
# 指定輸出文件名
pyinstaller -F --name "我的程序" hello.py
# 生成的可執行文件名為"我的程序.exe"
# 清理之前的打包文件
pyinstaller --clean hello.py二、Jieba庫 - 中文分詞的利器
1、Jieba庫的原理分析
中文分詞是將連續的中文中文字符序列切分成具有獨立意義的詞語,中文文本的詞與詞之間沒有像英文空格那樣的顯式分隔符,且常存在組合歧義。而 Jieba 庫是解決這一問題的核心工具,其工作原理是:首先,用內置的“詞典”快速找出句子中所有可能的詞語組合;然後,像選擇最佳路線一樣,從中挑出最合理的切分方式;最後,即使遇到詞典裏沒有的新詞(比如網絡熱詞),它也能根據上下文猜出正確的切分結果。
2、jieba庫的解析
1)、Jieba庫的安裝
# 打開命令行,輸入以下命令:
pip install jieba
# 如果下載慢,可以用國內鏡像:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple jieba2)、jieba庫的解析
在jieba庫的安裝目錄中,最重要的是__init__.py文件,因為其中包含了用於創建分詞對象的類Tokenizer。ayalyse文件夾裏是用於設計算法以實現分析詞語的相關代碼,finalseg文件夾中是用於分詞完成後處理的相關代碼。lac_small文件夾中是用於創建詞法分析模型和模型數據讀取器的相關代碼,__main__.py文件可以實現用命令的形式運行jieba庫中函數的功能,dict.txt文件時jieba庫中的詞典用於保存所有詞語。
3、jieba庫的使用
Jieba提供了三種不同的分詞模式,就像切蛋糕的三種方式:
模式1:精確模式(只切出最合理的詞語,不會多切。)
import jieba
text = "我今天吃了沙縣小吃的雞腿飯"
result = jieba.cut(text, cut_all=False) # cut_all=False表示精確模式
print("精確模式:", "/".join(result))
模式2:全模式(切得最細)
import jieba
text = "我今天吃了沙縣小吃的雞腿飯"
result = jieba.cut(text, cut_all=True) # cut_all=True表示全模式
print("全模式:", "/".join(result))
模式3:搜索引擎模式(適合搜索)
import jieba
text = "我今天吃了沙縣小吃的雞腿飯"
result = jieba.cut_for_search(text)
print("搜索引擎模式:", "/".join(result))
4、添加自定義詞典
Jieba 庫提供了擴展詞典的機制,可以有效識別新詞或專業術語,以提升分詞的準確性。我們可以通過 jieba.add_word()臨時添加單個新詞,使 Jieba 在後續分詞中將其作為一個整體處理。
import jieba
text = "我買了沙縣小吃的雞腿飯"
result = list(jieba.cut(text))
print("沒教之前:", "/".join(result))
jieba.add_word("沙縣小吃") # 告訴Jieba這是一個詞
jieba.add_word("雞腿飯") # 告訴Jieba這是一個詞
result = list(jieba.cut(text))
print("教了之後:", "/".join(result))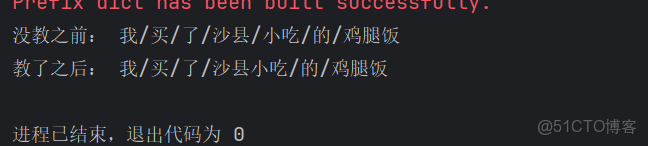
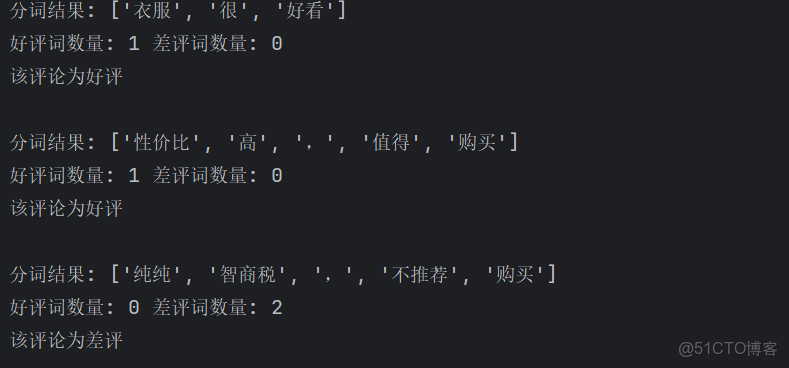
到這裏我們就基本學完了第三方庫中的內容了,現在 運用我們所學的知識完成一個小案例:實現判斷評論為好評或差評。
import jieba
# 添加自定義詞語
jieba.add_word('智商税')
jieba.add_word('不推薦')
jieba.add_word('純純') # 如果需要的話
good = ['好評', '好看', '性價比高', '值得']
bad = ['垃圾', '差評', '智商税', '不推薦']
a = '衣服很好看'
b = '性價比高,值得購買'
c = '純純智商税,不推薦購買'
def cc(sentence):
good_value = bad_value = 0
d = list(jieba.cut(sentence))
print(f"分詞結果: {d}")
for i in d:
if i in good:
good_value += 1
elif i in bad:
bad_value += 1
print('好評詞數量:', good_value, '差評詞數量:', bad_value)
if good_value > bad_value:
print('該評論為好評')
elif good_value == bad_value:
print('無法判斷')
else:
print('該評論為差評')
print() # 添加空行分隔
cc(a)
cc(b)
cc(c)