
年份:2020-10-26
論文鏈接: https://aclanthology.org/2020.coling-main.138.pdfhttps://drive.google.com/file/d/1UAIVkuUgs122k02Ijln-AtaX2mHz70N-/viewhttps://drive.google.com/file/d/1iwFfXZDjwEz1kBK8z1To_YBWhfyswzYU/view
論文代碼:https://github.com/131250208/TPlinker-joint-extraction
相關背景:
問題任務:Extracting entities and relations from unstructured texts
傳統方法:Traditional pipelined approaches first extract entity mentions and then classify the relation types between candidate entity pairs.
傳統方法問題:忽略了實體與關係之間的關係;
最近方法:實體與關係一起抽取的聯合模型;
最近方法解決不了的問題:對於overlapping解決不了
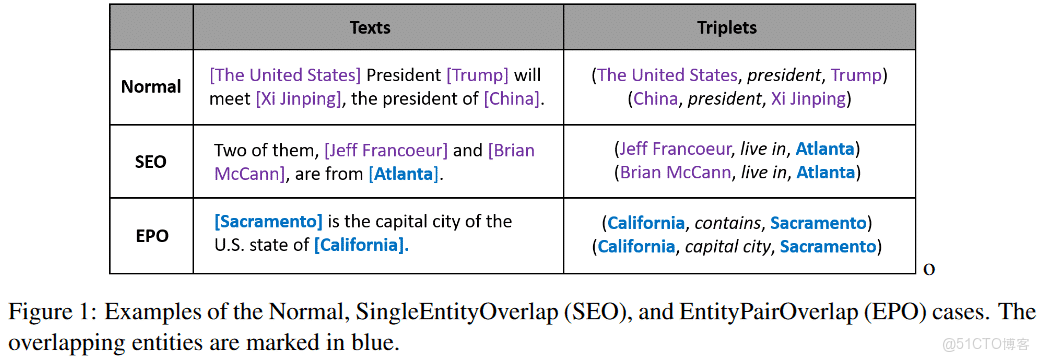
針對overlapping問題的解決方法:Decoder-based models 與 Decomposition-based models
overlapping方法的問題:exposure bias,訓練與預測不一樣。
綜上:提出了TPLinker, 把聯合抽取轉換成一個Token對的鏈接問題。
Tagging
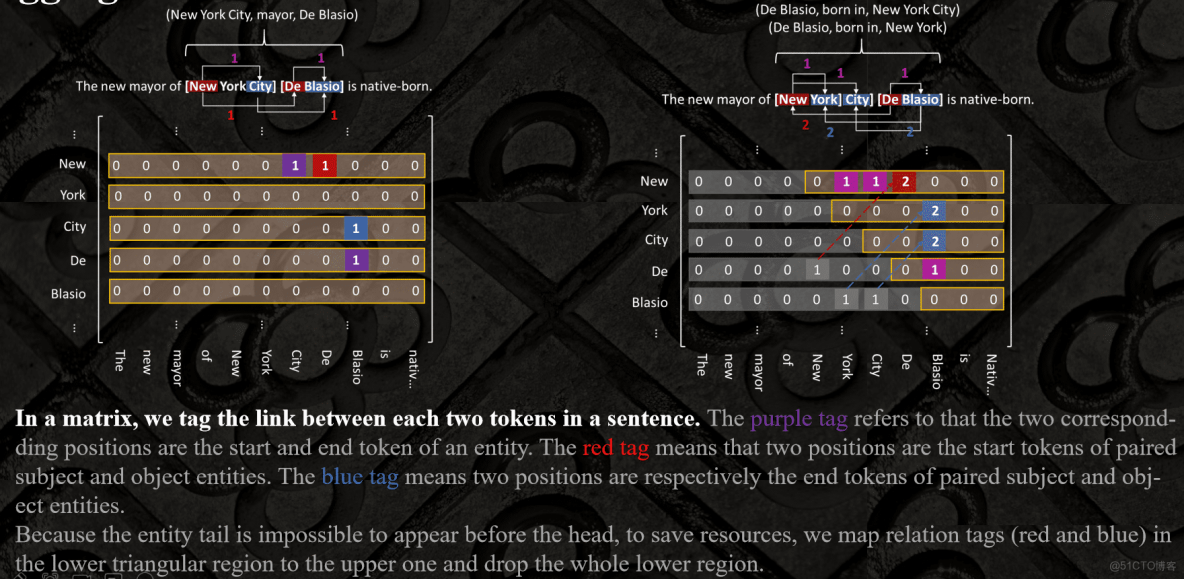
model
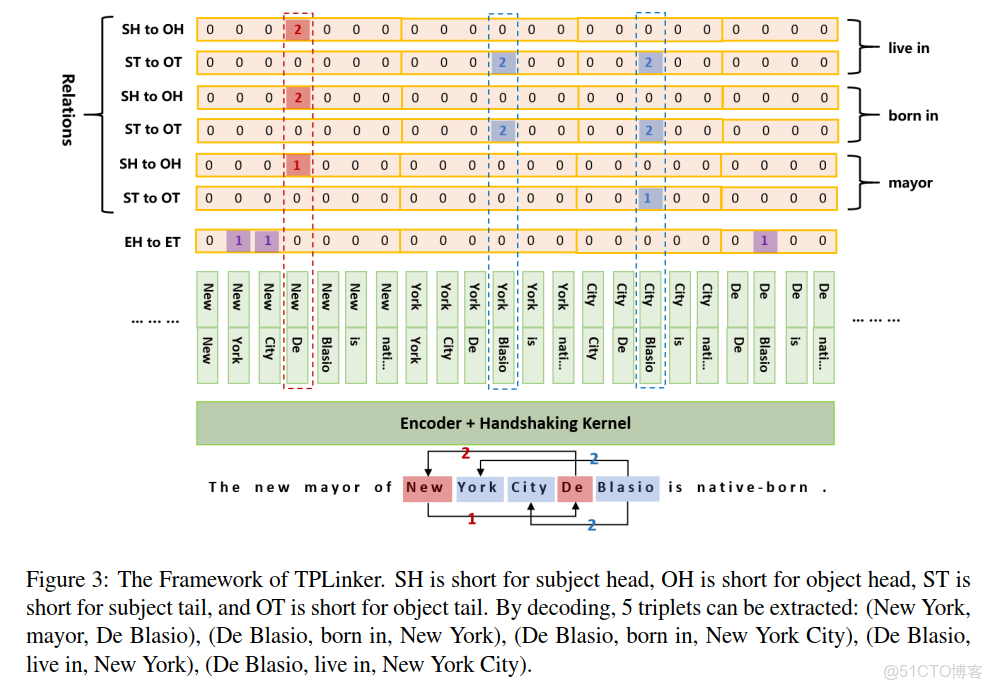
句子中的詞經過編碼器編碼後,直接拼接在一起,然後就是Handshaking Kernel:

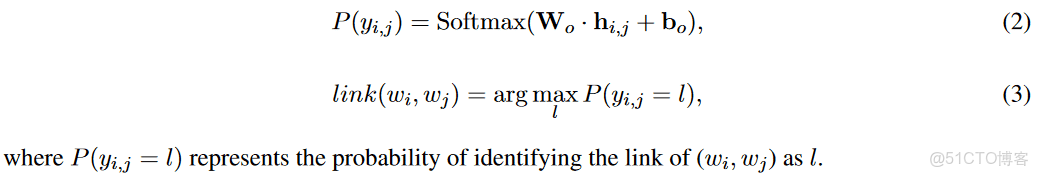
** 解碼説明:**
EH-to-ET: entity head to entity tail
SH-to-OH : subject head to object head
ST-to-OT :subject tail to object tail
例子:
實體範疇:
(“New”, “York”), (“New”, “City”) and (“De”, “Blasio”) 在EH-to-ET被標註為1,表示實體:“New York”, “New York City”, and “De Blasio”;
關係範疇:
(“New”,“De”)在SH-to-OH中與對於關係“mayor”中被標記為1,表示“mayor”的Subject以"NEW"開始,Object是以“De”開始的。
(“City”, “Blasio”)的在ST-to-OT中在關係“mayor”中標註為1,表示“mayor”的Subject以“City”結束,Object是以"Blasion"結束。
綜上實體範疇與關係範疇可得三元組:(“New York City”, mayor, “De Blasio”)
解碼步驟:
第一步,根據EH-to-ET抽取出所以實體,並採用詞典D來保存;
第二步,對於每個關係,首先處理了ST-to-OT序列的內容,然後處理SH-to-OH的內容;
第三步,迭代所以候選實體對判斷E的tail位置。
損失函數
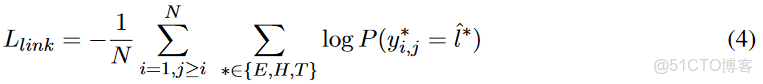
實驗結果
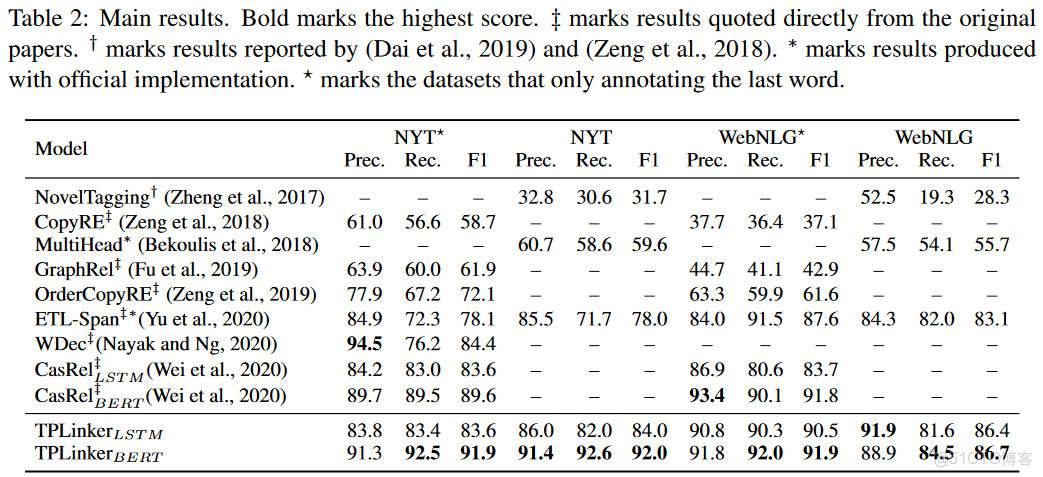
結果還是很不錯的,這裏重點是提出一個新的標註方式,把實體與關係轉成了token對來解決了。對於Handshaking Kernel裏面,要兩兩組合,如果對於文本比較長,效率是一個問題。故目前來看,想法還是很新穎的,應用上還得優化一下。
論文2:PRGC: Potential Relation and Global Correspondence Based Joint Relational Triple Extraction
年份:2021-06-17
相關背景:提出的模型與之前聽端到端的模型有點不一樣,這個是從關係抽取開始的。目的是想把冗餘的關係去掉。
基本概念
Single Entity Overlap (SEO) 單一實體重疊
Entity Pair Overlap (EPO) 實體對重疊 :即一個實體對之間存在着多種關係
Subject Object Overlap (SOO) 主客體重疊 :既是主體,又是客體
模型
關係判斷(Relation Judgement):(橙色虛線)Potential Relation Prediction
實體提取(Entity Extraction):(藍色虛線)Relation-Specific Sequence Taggers
主賓語對齊(Subject-object Alignment):(綠色虛線)Global Correspondence
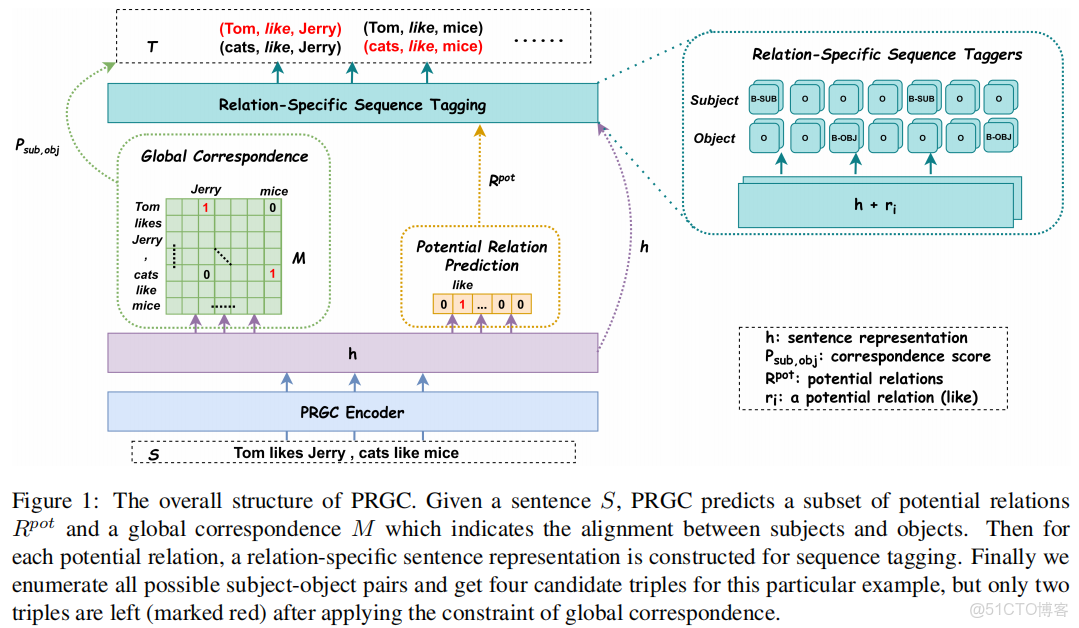
++ 對應上圖的Orage box ++
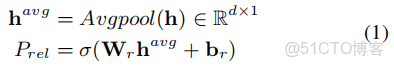
*Avgpool: 表示平均池化操作。P計算出的內容是所有的關係分佈。*這一步把模型看成是多標籤二進制分類。如果概率超過某個閾值λ,則為對應關係分配標籤1,否則將對應的關係標籤置為0;接下來只需要將特定於關係的序列標籤應用於預測關係,而不是預測全部關係。
Relation-Specifific Sequence Tagging
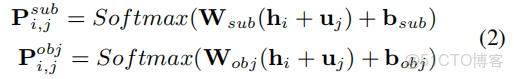
這裏是對某個字符,判斷它的BIO標註。
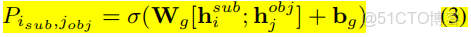
這部分主要是用來計算主體與客體是否有關係;
矩陣的分數。這個跟TPLinker那個還是比較像的。不過這個裏面的編碼求了平均值。同樣的一個問題:如果句子長度太長最後subject-object的對齊工作消耗的空間資源會很大。
關係的損失函數,在給定關係下的序列標註的預測,<sub,obj>對矩陣的那個Global矩陣的損失。

綜上的模型總結:相對於流行的模型來看,這裏加入了句子中的關係分類,目的是想過濾出潛在關係,然後,在過濾出的關係去找實體,這裏是基於給定關係之後來判斷這個實體是否是三元組中的sub或obj. 看到最後的損失函數,計算量還是比較大的。PRGC預測過程:首先預測潛在關係子集( potential relations)和包含所有主客體之間的對應分數的全局矩陣(global matrix); 然後序列標記(sequence tagging),抽取潛在關係的主體和客體;最後列舉所有實體候選對,全局對應矩陣( global correspondence matrix)進行過濾。
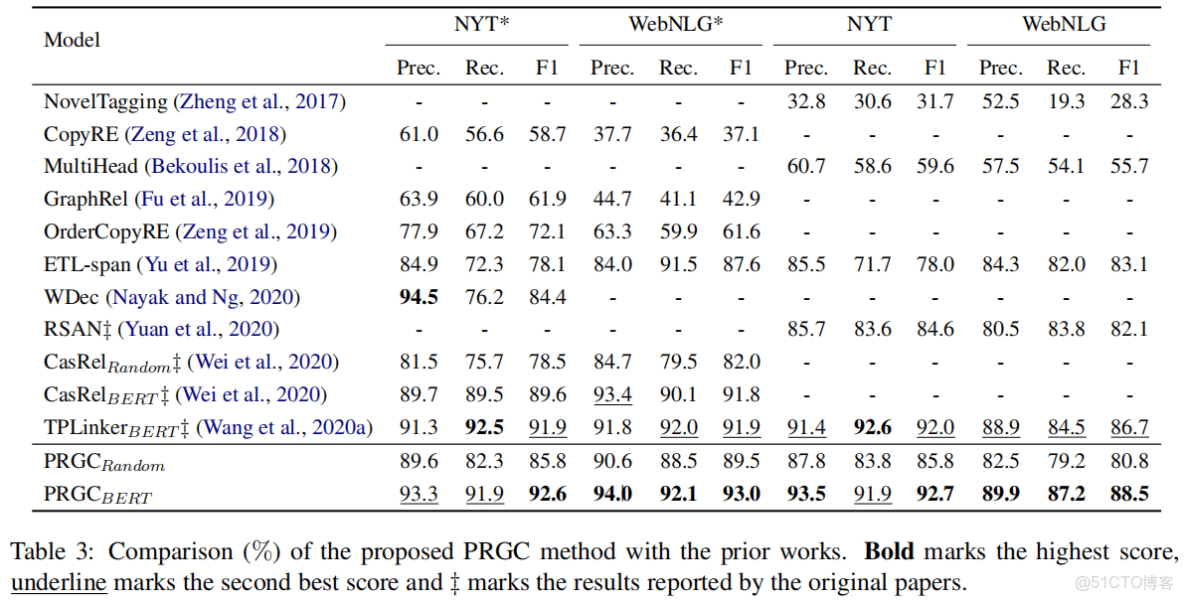
實驗結果
主要結果
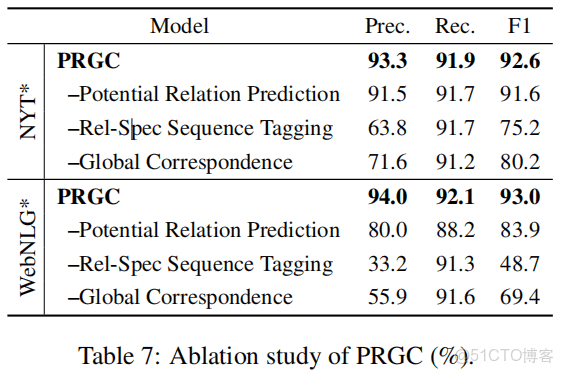
模型各個模塊的貢獻情況
論文3:Unified Named Entity Recognition as Word-Word Relation Classification
[1] J. Li等, 《Unified Named Entity Recognition as Word-Word Relation Classification》, arXiv, arXiv:2112.10070, 12月 2021. doi: 10.48550/arXiv.2112.10070.
年份:2021-12-19
動機:

W2NER scheme:
主要是引入兩個標註來使用NER統一化:Next-Neighboring-Word(NNW),Tail-Head-Word-(THW-*).
NNW: 實體中兩個詞是否相鄰;
THW-*:標記實體的邊界與類型;
例子:Figure 1 (b)中,NNW表示相鄰,可以生成{aching in, in legs, in shoulders, aching in legs, aching in shoulders};
THW-S表示,實體Tail到Head的連接,可以得到上面的候選中的{aching in legs, aching in shoulders};這個都是S類型的實體。
模型:
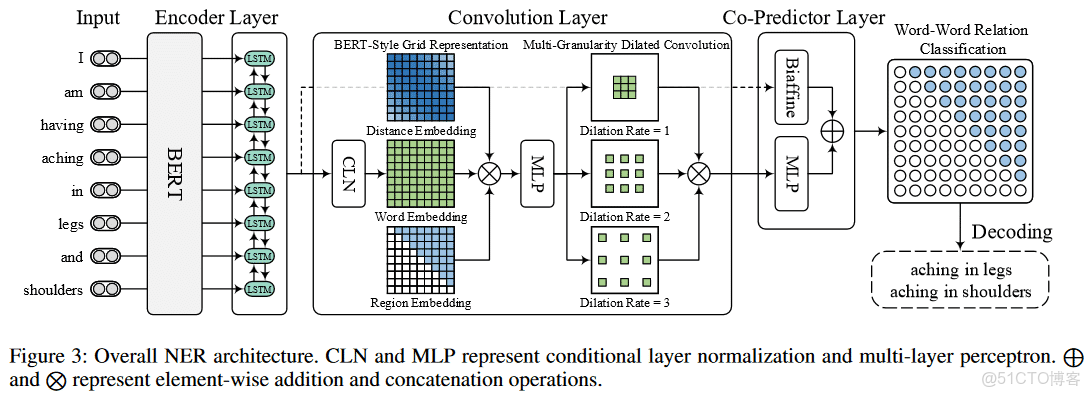
Encoder Layer
論文提到兩種方法:BERT , Bi-LSTM
Convolution Layer
卷積層包括三個模塊:
1.Conditional Layer Normalization; 用來生成詞對錶格。
2. BERT-Style Grid Representation Build-Up; 豐富單詞對錶格表示;
3. Multi-Granularity Dilated Convolution,用來捕捉距離與遠距離詞相關性的;
Conditional Layer Normalization

BERT-Style Grid Representation Build-Up
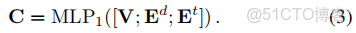
V: 詞信息;
Ed: 每個詞對的關係位置信息;
Et: 表示區分詞關係網格上下三角形區域的區域信息。
Multi-Granularity Dilated Convolution
空洞卷積(Dilated Convolution)中文名也叫膨脹卷積或者擴張卷積,英文名也叫Atrous Convolution
空洞卷積最初的提出是為了解決圖像分割的問題而提出的,常見的圖像分割算法通常使用池化層和卷積層來增加感受野(Receptive Filed),同時也縮小了特徵圖尺寸(resolution),然後再利用上採樣還原圖像尺寸,特徵圖縮小再放大的過程造成了精度上的損失,因此需要一種操作可以在增加感受野的同時保持特徵圖的尺寸不變,從而代替下采樣和上採樣操作,在這種需求下,空洞卷積就誕生了
這裏應用了multiple 2-dimensional dilated convolutions (DConv), l取1,2,3.

Biaffifine Predictor

MLP Predictor
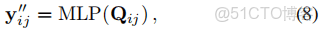
這個Q是卷積得到結果。

這個體現了殘差的形式。
損失函數
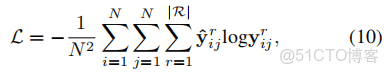
decodeing

預測把詞及詞關係看成有向詞圖。解碼就是使用NNW在詞圖中找到確定的詞路徑,THW輔助地去辨別有用的實體,並加上類型。
在示例(a)中,兩條路徑“A→B”和“D→E”對應於Flat實體,而THW關係表示它們的邊界和類型;
在示例(b)中,如果沒有THW關係,我們只能找到一條路徑,因此缺少“BC”。相比之下,藉助THW關係,很容易確定“BC”是嵌套在“ABC”中的,這説明了THW關係的必要性。
案例©顯示瞭如何識別不連續的實體。可以找到兩條路徑“A→B→C”和“A→B→D”,並且NNW關係有助於連接不連續的“AB”和“D”.
案例(d)中,通過有向詞圖,採用NNW與THW可以得到“ACD”,“BCE”兩實體。
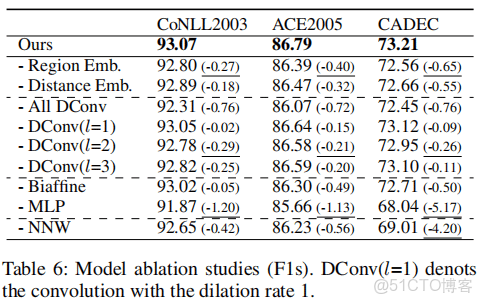
各個模塊的作用。
實驗
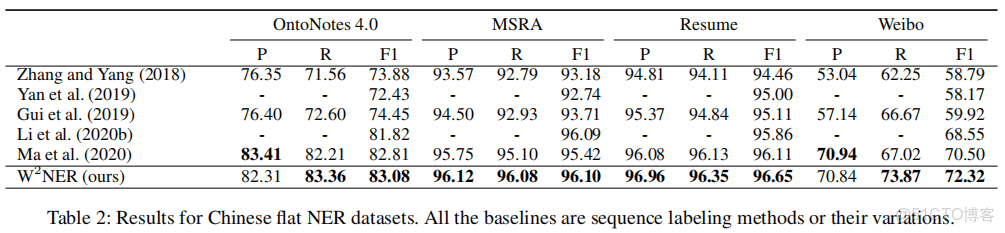
正常NER
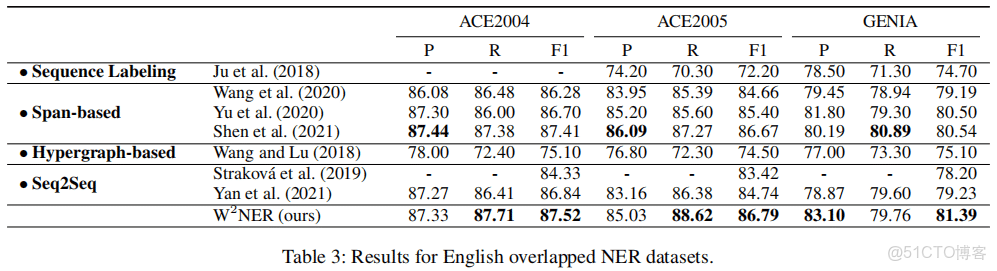
重疊NER
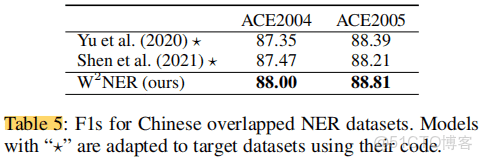
非連續NER
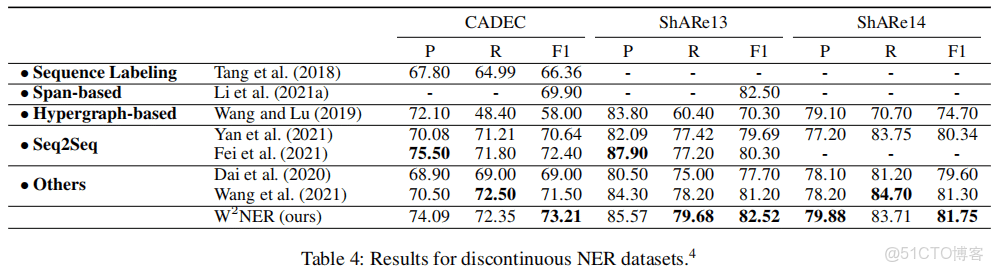
一個模型解決三種典型的NER,效果並不比較各種模型差,可以考慮嘗試。
補充一個ENR種類圖與典型的流派:
代碼相關
輸入數據格式—對於英文,包括了sentence與ner兩個信息。
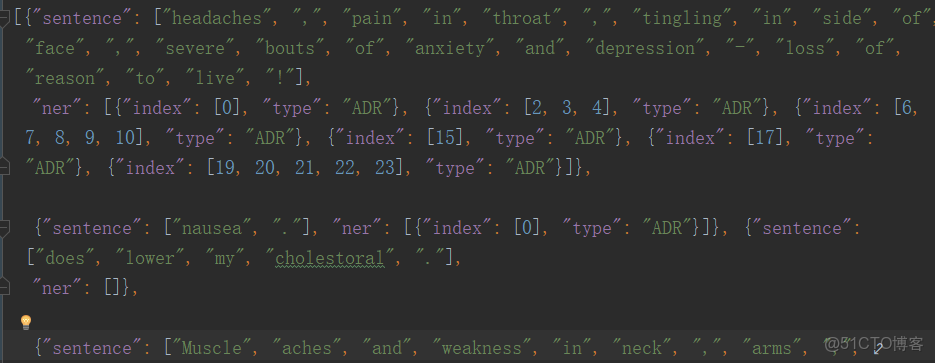
對於中文:不但包括了sentence與ner信息,還包含了word的分詞信息
數據預處理及數據集-- process_bert函數與RelationDataset類:
這裏面還一個是piece的概念,它表示比word更小的分割,這個在英文單詞上會比較常一些。對於中文如果用單字分割了,不會有這種piece分開了。
句子:[‘高’, ‘勇’, ‘:’, ‘男’, ‘,’, ‘中’, ‘國’, ‘國’, ‘籍’, ‘,’, ‘無’, ‘境’, ‘外’, ‘居’, ‘留’, ‘權’, ‘,’]
bert_input:[ 101 7770 1235 8038 4511 8024 704 1744 1744 5093 8024 3187 1862 1912 2233 4522 3326 8024 102]
grid_labels:
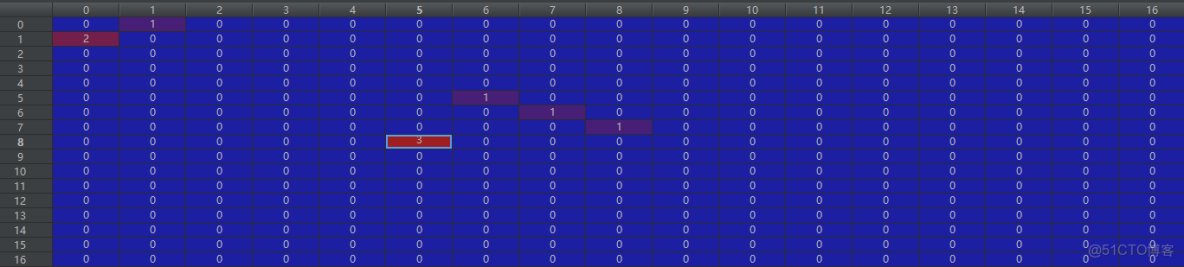
對於這個數據的解釋,要查看下面一個變量:
1表地後繼表示即論文中的NNW,2表示名字,3表示國家,以此類推的數字表示。
dist_inputs:距離矩陣
處理器返回的結果為:bert_inputs, grid_labels, grid_mask2d, pieces2word, dist_inputs, sent_length, entity_text
毫無疑問,數據集(RelationDataset)中也採用了這七個字段:
class RelationDataset(Dataset):
def __init__(self, bert_inputs, grid_labels, grid_mask2d, pieces2word, dist_inputs, sent_length, entity_text):
self.bert_inputs = bert_inputs
self.grid_labels = grid_labels
self.grid_mask2d = grid_mask2d
self.pieces2word = pieces2word
self.dist_inputs = dist_inputs
self.sent_length = sent_length
self.entity_text = entity_text
def __getitem__(self, item):
return torch.LongTensor(self.bert_inputs[item]), \
torch.LongTensor(self.grid_labels[item]), \
torch.LongTensor(self.grid_mask2d[item]), \
torch.LongTensor(self.pieces2word[item]), \
torch.LongTensor(self.dist_inputs[item]), \
self.sent_length[item], \
self.entity_text[item]
def __len__(self):
return len(self.bert_inputs)模型:
第一個內容,bert編碼器:
self.bert = AutoModel.from_pretrained(config.bert_name, cache_dir="./cache/", output_hidden_states=True)
這裏做了一個是否選擇bert後面4層的開關:
if self.use_bert_last_4_layers:
bert_embs = torch.stack(bert_embs[2][-4:], dim=-1).mean(-1)
else:
bert_embs = bert_embs[0]
第二個內容:把piece最大池化成word表達:
# 處理pieces, 採用最大池化把pieces變成詞表達
length = pieces2word.size(1)
min_value = torch.min(bert_embs).item()
_bert_embs = bert_embs.unsqueeze(1).expand(-1, length, -1, -1)
_bert_embs = torch.masked_fill(_bert_embs, pieces2word.eq(0).unsqueeze(-1), min_value)
word_reps, _ = torch.max(_bert_embs, dim=2)
word_reps = self.dropout(word_reps)第三個內容: 詞編碼-bi_LSTM
packed_embs = pack_padded_sequence(word_reps, sent_length.cpu(), batch_first=True, enforce_sorted=False)
packed_outs, (hidden, _) = self.encoder(packed_embs)
word_reps, _ = pad_packed_sequence(packed_outs, batch_first=True, total_length=sent_length.max())**附:pack_padded_sequence與pad_packed_sequence。**在LSTM中,因為pad會影響模型的效果,所以要把pad刪除再傳進模型。pack_padded_sequence把pad的內容去掉,輸入為
(B×T×* )的格式。當LSTM處理完之後,進行一次pad_packed_sequence,然後再把pad加回去了。
第四個內容—內容信息(內容信息,位置信息,區域信息):
cln是一個layerNorm層
self.cln = LayerNorm(config.lstm_hid_size, config.lstm_hid_size, conditional=True)
cln編碼後:
cln = self.cln(word_reps.unsqueeze(2), word_reps)
# 位置信息
dis_emb = self.dis_embs(dist_inputs)
# 矩陣的區域信息
tril_mask = torch.tril(grid_mask2d.clone().long())
reg_inputs = tril_mask + grid_mask2d.clone().long()
reg_emb = self.reg_embs(reg_inputs)==附:torch.tril:==pytorch中tril函數主要用於返回一個矩陣主對角線以下的下三角矩陣,其它元素全部為0 00。當輸入是一個多維張量時,返回的是同等維度的張量並且最後兩個維度的下三角矩陣的。
第五點內容卷積
conv_inputs = torch.cat([dis_emb, reg_emb, cln], dim=-1)
conv_inputs = torch.masked_fill(conv_inputs, grid_mask2d.eq(0).unsqueeze(-1), 0.0)
conv_outputs = self.convLayer(conv_inputs)
conv_outputs = torch.masked_fill(conv_outputs, grid_mask2d.eq(0).unsqueeze(-1), 0.0)第六點預測器–CoPredictor
class CoPredictor(nn.Module):
def __init__(self, cls_num, hid_size, biaffine_size, channels, ffnn_hid_size, dropout=0):
super().__init__()
self.mlp1 = MLP(n_in=hid_size, n_out=biaffine_size, dropout=dropout)
self.mlp2 = MLP(n_in=hid_size, n_out=biaffine_size, dropout=dropout)
self.biaffine = Biaffine(n_in=biaffine_size, n_out=cls_num, bias_x=True, bias_y=True)
self.mlp_rel = MLP(channels, ffnn_hid_size, dropout=dropout)
self.linear = nn.Linear(ffnn_hid_size, cls_num)
self.dropout = nn.Dropout(dropout)
def forward(self, x, y, z):
h = self.dropout(self.mlp1(x))
t = self.dropout(self.mlp2(y))
o1 = self.biaffine(h, t)
z = self.dropout(self.mlp_rel(z))
o2 = self.linear(z)
return o1 + o2附:掩碼操作masked_fill,用value填充tensor中與mask中值為1位置相對應的元素。mask的形狀必須與要填充的tensor形狀一致。
再看一下Biaffine:
class Biaffine(nn.Module):
def __init__(self, n_in, n_out=1, bias_x=True, bias_y=True):
super(Biaffine, self).__init__()
self.n_in = n_in
self.n_out = n_out
self.bias_x = bias_x
self.bias_y = bias_y
weight = torch.zeros((n_out, n_in + int(bias_x), n_in + int(bias_y)))
nn.init.xavier_normal_(weight)
self.weight = nn.Parameter(weight, requires_grad=True)
def forward(self, x, y):
if self.bias_x:
x = torch.cat((x, torch.ones_like(x[..., :1])), -1)
if self.bias_y:
y = torch.cat((y, torch.ones_like(y[..., :1])), -1)
# [batch_size, n_out, seq_len, seq_len]
s = torch.einsum('bxi,oij,byj->boxy', x, self.weight, y)
# remove dim 1 if n_out == 1
s = s.permute(0, 2, 3, 1)
return s這裏最有趣的就是對einsum(愛因斯坦求和)進行理解,三個變量的規則就在其中了。論文中的biaffine公式也有描述了。
愛因斯坦求和是一種對求和公式簡潔高效的記法,其原則是當變量下標重複出現時,即可省略繁瑣的求和符號。
其中, i,j為自由指標, k為啞指標.
啞指標: 在表達式的某項中, 若某指標重複出現兩次, 則表示要把該項指標在取值範圍內遍歷求和. 該重複指標稱為啞指標或簡稱啞標. (未被求和的指標稱為自由指標)
自由指標: 在表達式的某項中, 若某指標只出現一次, 若在取值範圍內輪流取該指標的任一值時, 關係式恆成立. 該指標稱為自由指標.
einsum的本質是嵌套循環。

後來修改成多GPU來使用,不過在lstm輸出後要修改一下那個padding的長度。要不concat那裏就會報接不起來的錯誤了。
論文4:OneRel: Joint Entity and Relation Extraction with One Module in One Step
年份:2022-03-17
用一個模型去解決實體及關係的聯合抽取任務,名字叫OneRel;
作者:北理工
看摘要
忽略三元組依賴信息,會造成級聯錯誤與信息冗餘,提出了OneRel: 把實體關係聯合抽取看成fine-grained triple分類任務來處理,由scoring-based classififier 與 relation-specifific horns tagging strategy組成。效果SOTA。
看結論(與摘要相應的,多出展望):
1. 把聯合抽取任務轉制換成一個粒度三元組分類問題。
2. 提出了基於分數分類器與Rel-Spec Horns標註策略的單步聯合單模型。
展望(不足):
- 評分函數會影響模型效率;
- 在其實信息抽取任務的深探。
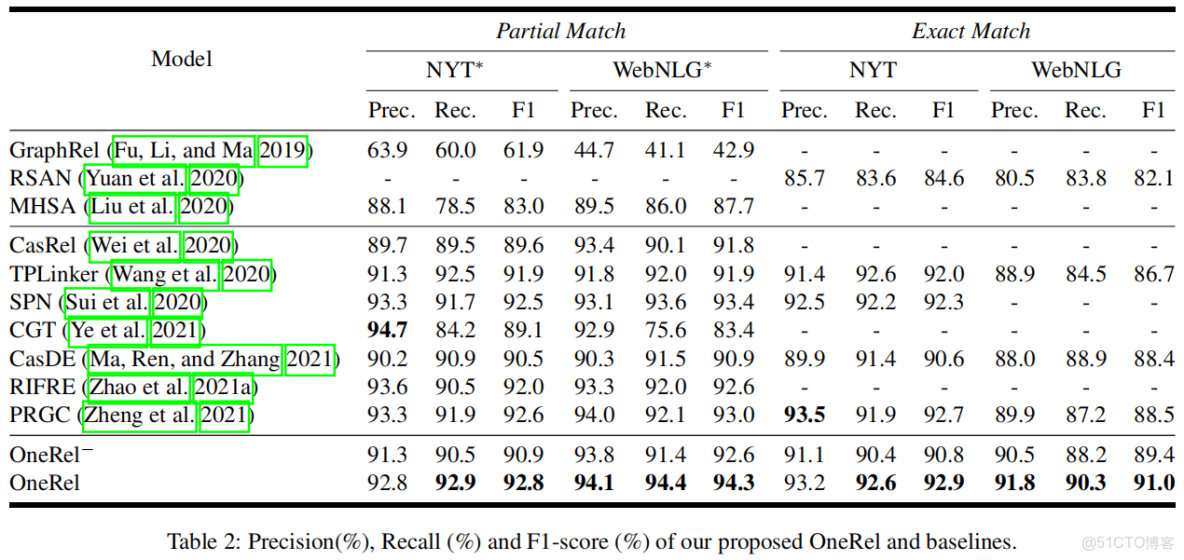
表現還不錯。
看方法
兩部分內容: 標註體系(Rel-Spec Horns Tagging)及模型(Scoring-based Classififier)
一般看來創新點有兩個地方:標註體系、模型
tagging
“BIE” :Begin, Inside, End
“HB”: 實體的開始token(the beginning token of the head entity)
“TE” : 尾實體的結束token(the end token of the tail entity)
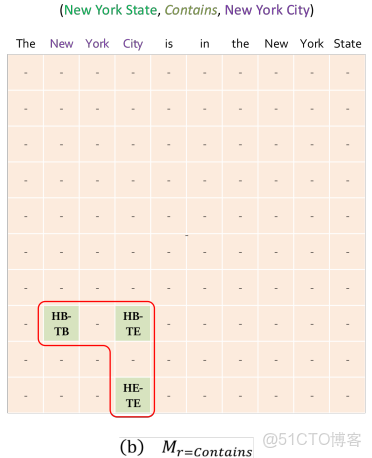
tagging strategy
(1)“HB-TB”: 具體關係下的一對實體的頭實體開始token及尾實體token; 例如:對於三元組(“New York City” ,Located in, “New York
State”)中,(“New”, Located in, “New”) 標註為“HB-TB”;
(2)“HB-TE”: 以上同理,(“New”, Located in, “State”) 標註為“HB-TE”;
(3)“HE-TE”: 以上同理,(“City”, Located in, “State”)標註為“HE-TE”;
(4)“-”: 除了上面三種情況之外的情況 ,都標註為“-”
只用三個角被標註所以叫:Rel-Spec Horns Tagging
例子:
tagging體系優點:
- 把9種標註變成三角標註;
- 負樣本容易構建;
- 解碼簡單有效;
- 對於*EntityPairOverlap *(EPO) 、 *SingleEntityOverlap *(SEO) 和 HeadTailOverlap(HTO1 )問題可以容易解決。
Decoding
編碼:{e1, e2, …, eL} = BERT({x1, x2, …, xL})
最終的評分函數:
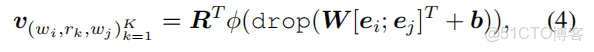
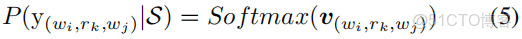
損失函數:
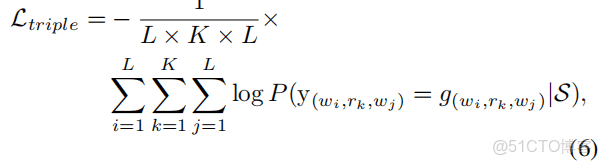
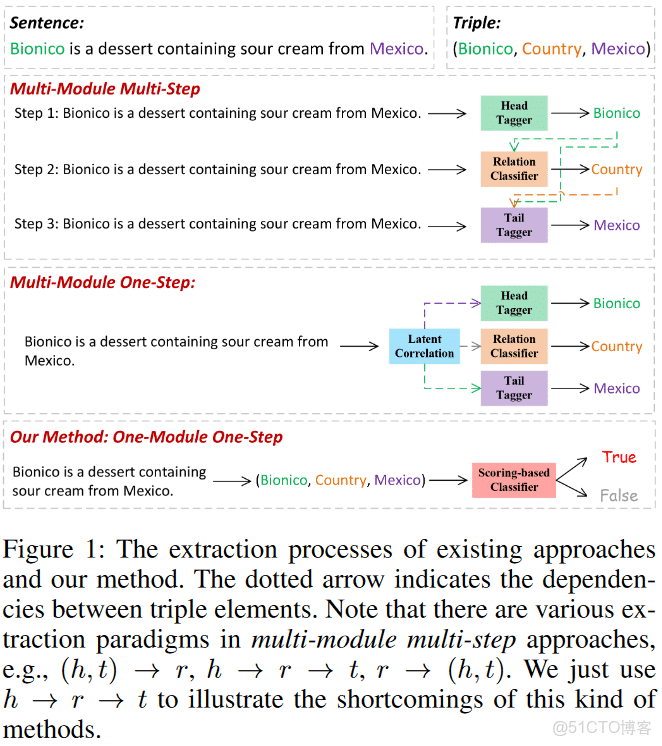
這篇文章感覺有點囉嗦。提出了一種新的標註方案。這種抽取三元組的方法,是否少了實體類型?其實我還比較關注實體類型的,是否可以在關係上推導出實體類型?
論文5:OneEE: A One-Stage Framework for Fast Overlapping and Nested Event Extraction
[1] H. Cao et al., ‘OneEE: A One-Stage Framework for Fast Overlapping and Nested Event Extraction’. arXiv, Sep. 06, 2022. Accessed: Oct. 12, 2022. [Online]. Available: http://arxiv.org/abs/2209.02693 年份:2022-09-26
解決問題:
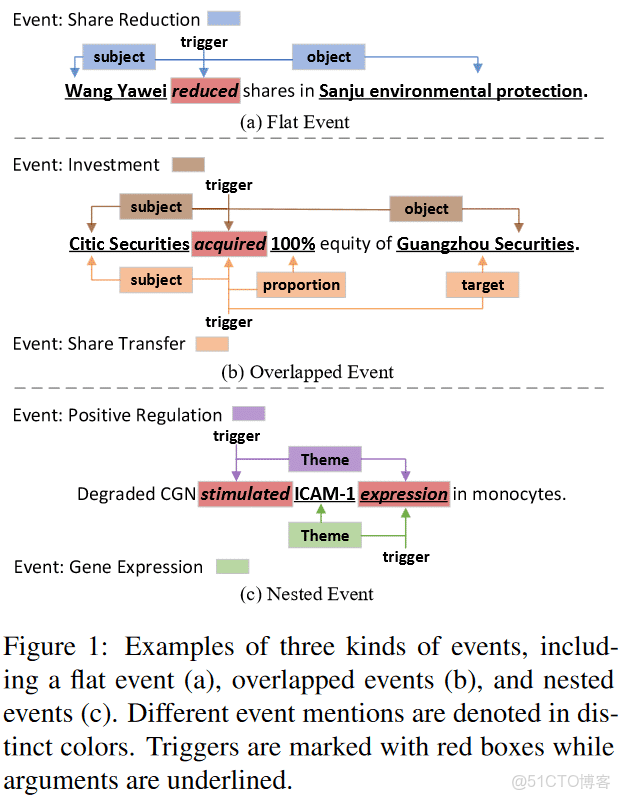
論文提出OneEE, 把EE任務採用word-word關係識別任務來解決。觸發語或相關參數一齊識別與抽取。模型由adaptive enven fusion module與distance-aware predictor構成。
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-WbRZMhcD-1666014120039)(https://www.jianguoyun.com/c/tblv2/Xu0c-GgQsUSNnT28QzkliG7VkhHvlD6PpcEdy_tzPqE4M5ukEWYl770yYFYshtsm5NcqC-lF/U-lATKLRCvNj4EgWWIRemw/l)]
設計成兩種關係標註,一種是spnas標籤:S-*,即是用它來表示實體, 一種是role標籤:R-*,即是用來表示事件的中心詞與參數的關係。
S-*處理Trigger與argument關係;R-*表示參數的角色分類。
“S-T”: 是用來標記trigger的首尾邊界的關係;
“S-A”:是用來標記argument的首尾邊界的關係;
“R-S”:表示“subject”參數與trigger之間的關係;
“R-O”,“R-T”,"R-P"分別表示“object”,“target”,"proportion"參數所trigger之間的關係。
例如(a)中, 事件:Invesment, 由“s-” 表示的trigger實體:acquired; argument實體有“Citic Securities”與“Guangzhou Securities”; 由“R-*”表示的關係為R-S上的邊與R-O的邊,用了gmw
模型:
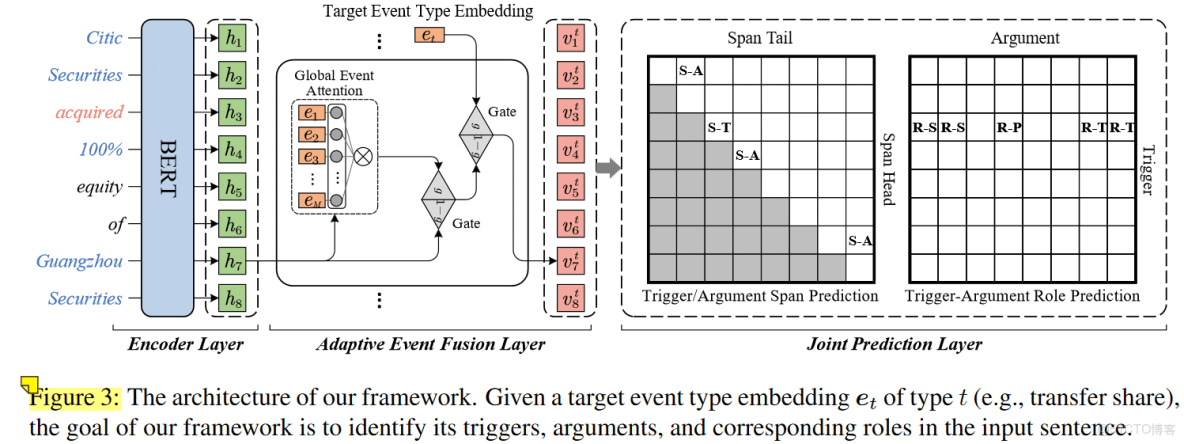
模型包含了三個部分。
Adaptive Event Fusion Layer
fuse層: event信息 + 上下文信息
內容包括:關注力模塊,兩個門整合模塊(用來融合全局與target事件信息)。
Attention Mechanism

Gate Fusion Mechanism
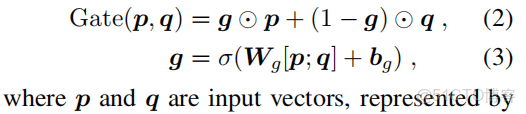
p,q就輸入向量,g是全連接經過激活函數的結果。
應用attention Mechanism與Gate Fusion Mechanism兩公式

E表示事件的嵌入,採用隨機初始化的方法來初始化的。
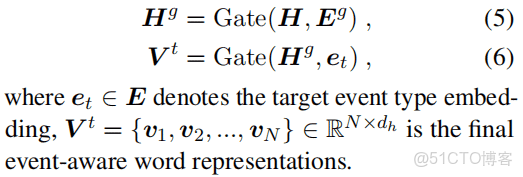
這裏的目的是使用詞表達帶有事件的信息,叫做具有事件感知的詞表達。
聯合預測兩詞之間的span與role關係。
對於每個詞對,計算一個分數去衡量關係(span關係與role關係)的可能性。
Distance-aware Score

損失函數

這裏引了一個閾值δ,當存在關係的大於δ,否則小於δ.
模型訓練過程中是經過採樣的,關係採樣數K,如下的效果:
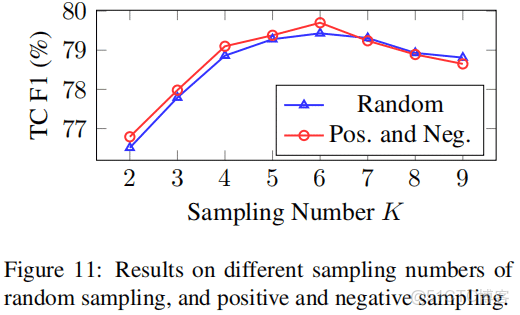
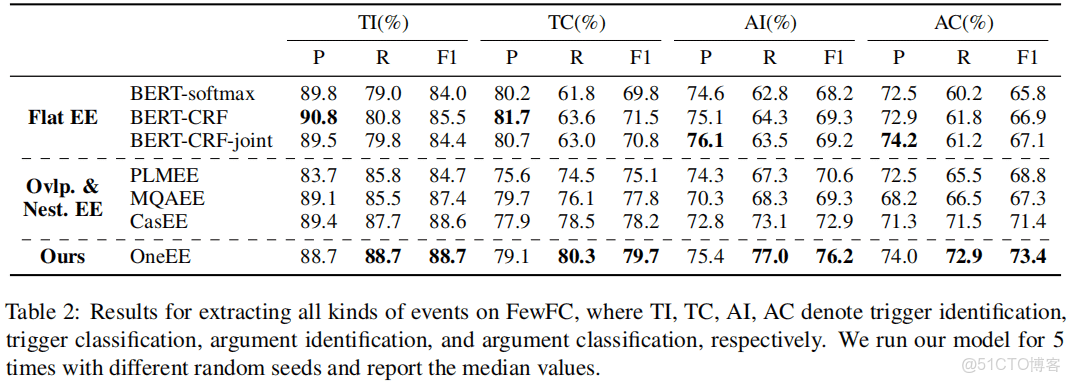
實驗效果
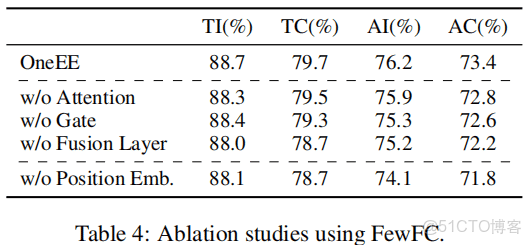
模型的各個部分的作用:
總結: 其實事件抽取是實體與關係抽取的另個角度,不過它會顯得更詳細,它有一個事件背景。就好像分詞與NER的關係。分詞的任務,只要可以把詞分開就好,可是NER還有一個類型在。實體與關係的模型,只要把實體抽出來有關係就好,可是事件中還要有事件的角色,就是中心詞,其它實體要圍繞它,其它的實體就叫做中心詞的屬性了,這個中心詞還決定了事件是什麼與事件類型。NLP的任務是環環相關扣的,就看你站在哪個角度來看它。可以是end-end的形式,也可以每步每步都拆開,看任務而定。
made by happyprince