
摘要:基於企業微信API的智能客服系統技術方案摘要:本文介紹了構建企業微信智能客服系統的完整技術方案。系統採用分層架構設計,整合了企業微信API、生成式AI和RAG技術,實現從傳統規則引擎到AI驅動的範式轉變。核心功能包括智能路由、多客服協作、知識庫檢索和上下文對話管理,並採用情感識別、緩存優化等高級策略提升用户體驗。系統支持容器化部署,建立了完善的監控指標體系和持續學習機制。未來發展方向包括多模態交互、預測性服務和深度個性化。該方案可顯著提升客服效率300%以上,降低人力成本40-60%,為企業數字化轉型提供有力支撐。
1 系統概述與設計理念
1.1 智能客服系統的商業價值與技術定位
在當前數字化轉型浪潮中,智能客服系統已成為企業提升服務質量、優化運營成本的核心工具。基於企業微信API構建的智能客服系統,能夠直接觸達企業微信積累的龐大用户羣體,實現無縫銜接的客户服務體驗。據統計,成功實施智能客服系統的企業可將客服效率提升300%以上,人力成本降低40-60%。
企業微信智能客服系統的獨特優勢在於其原生集成能力。與其他客服系統不同,它無需用户下載額外應用或適應新界面,直接在熟悉的溝通環境中提供服務。這種低門檻特性使得用户接受度顯著提高,特別是對於已有企業微信使用基礎的組織而言。
1.2 從傳統客服到AI驅動的範式轉變
傳統客服系統主要依賴規則引擎和關鍵詞匹配,這種模式在面對複雜、多變的用户查詢時顯得力不從心。現代智能客服系統則基於生成式AI和自然語言處理技術,實現了從"機械應答"到"智能對話"的根本轉變。
這一轉變的核心價值在於系統能夠理解用户意圖而非僅僅匹配關鍵詞。例如,當用户詢問"我怎麼退貨"和"商品不想要了怎麼辦"時,儘管表達方式不同,但智能系統能識別出相同的退貨諮詢意圖,並給出相應指導。
2 技術架構設計與核心組件
2.1 整體系統架構規劃
基於企業微信API的智能客服系統採用分層架構設計,確保各組件之間的高內聚低耦合。整體架構包含以下核心層次:
- 接入層:負責與企業微信平台直接交互,處理消息的接收與發送
- 邏輯層:實現業務邏輯,包括對話管理、意圖識別、路由分配等
- AI能力層:集成大模型能力,提供自然語言理解和生成
- 數據層:負責用户信息、對話記錄、知識庫等數據的存儲與管理
下表展示了智能客服系統各層次的技術選型建議:
|
架構層次
|
推薦技術方案
|
替代方案
|
適用場景
|
|
接入層 |
Flask/FastAPI (Python) |
Gin (Go) |
高併發消息處理 |
|
邏輯層 |
Spring Boot (Java) |
Django (Python) |
複雜業務邏輯 |
|
AI能力層 |
DeepSeek/豆包API |
本地化模型部署 |
平衡成本與性能 |
|
數據層 |
MySQL + Redis |
PostgreSQL + MongoDB |
結構化與緩存需求 |
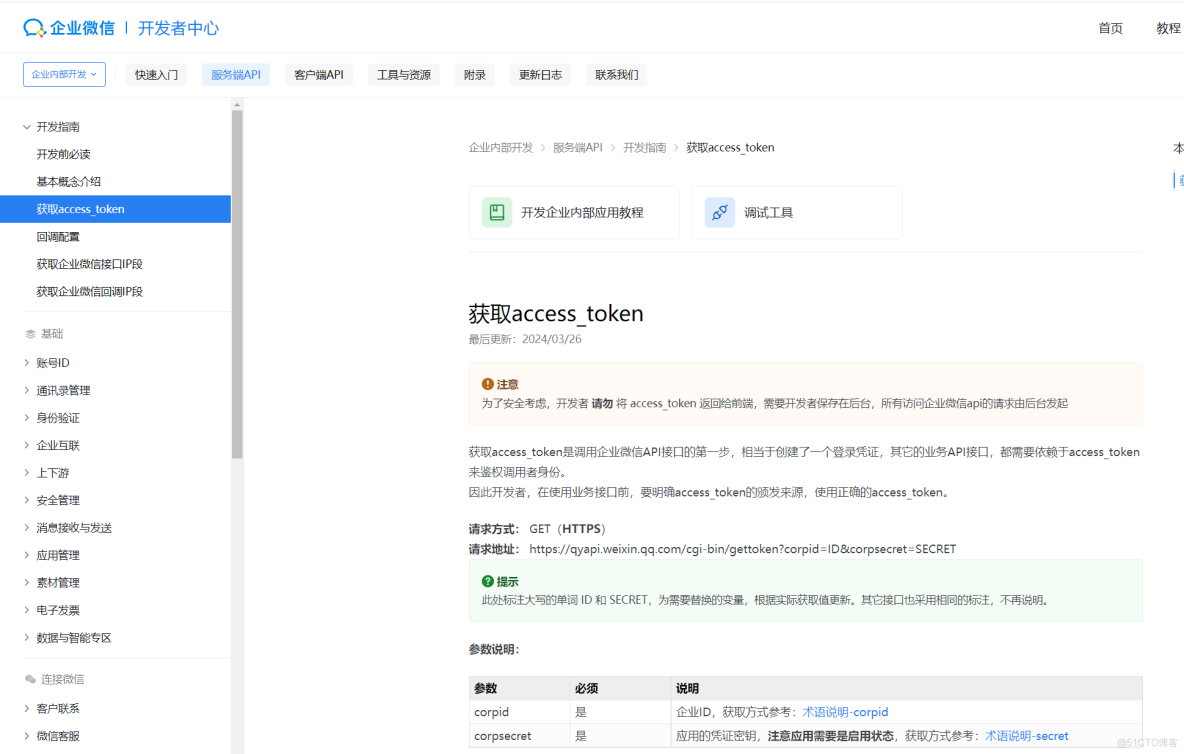
2.2 企業微信API集成詳解
企業微信API提供了全面的客服功能接口,包括消息接收、會話管理、客服賬號管理等。集成過程需要重點關注以下核心接口:
消息接收接口是企業微信向開發者服務器推送用户消息的入口。配置此接口需要在企業微信管理後台設置可信的回調URL,並完成Token和EncodingAESKey的驗證。以下是一個完整的消息接收處理示例:
from flask import Flask, request, jsonify
import xml.etree.ElementTree as ET
from wechatpy import parse_message, create_reply
app = Flask(__name__)
@app.route('/wx/callback', methods=['GET', 'POST'])
def callback():
if request.method == 'GET':
# 驗證回調URL
signature = request.args.get('msg_signature', '')
timestamp = request.args.get('timestamp', '')
nonce = request.args.get('nonce', '')
echostr = request.args.get('echostr', '')
# 驗證邏輯
if check_signature(signature, timestamp, nonce, echostr):
return echostr
else:
return '驗證失敗', 403
else:
# 處理消息
msg = parse_message(request.data)
# AI處理消息內容
response_content = ai_process_message(msg.content)
reply = create_reply(response_content, msg)
return reply.render()消息發送接口支持多種消息類型,包括文本、圖片、圖文、文件等。重要的是實現異步消息發送機制,避免因等待AI響應而觸發企業微信的5秒超時限制。
3 核心功能實現細節
3.1 智能路由與多客服協作
智能客服系統的核心功能之一是基於用户意圖的智能路由。系統需要能夠自動識別用户問題的類型和緊急程度,並將其分配給最合適的客服人員或AI處理。
實現智能路由需要建立客服技能標籤體系和問題分類模型。以下是技能路由的核心邏輯實現:
class SmartRouter:
def __init__(self):
self.agent_skills = {} # 客服技能庫
self.intent_classifier = IntentClassifier() # 意圖分類模型
def route_message(self, user_message, user_info):
# 分析用户意圖
intent = self.intent_classifier.predict(user_message)
# 根據意圖和客服技能匹配
suitable_agents = self.find_suitable_agents(intent)
# 考慮客服負載和優先級
best_agent = self.select_best_agent(suitable_agents)
return best_agent
def find_suitable_agents(self, intent):
suitable_agents = []
for agent_id, skills in self.agent_skills.items():
if intent in skills['expertise'] and skills['status'] == 'available':
suitable_agents.append(agent_id)
return suitable_agents多客服協作機制確保在主客服繁忙或離線時,系統能夠自動將對話轉移至其他可用客服。這種故障轉移機制需要實時監控客服狀態,並在轉移時傳遞完整的對話上下文。
3.2 知識庫構建與RAG應用
檢索增強生成技術是現代智能客服系統的核心技術,它通過結合知識庫檢索和大模型生成能力,提供準確且上下文相關的回答。
知識庫構建流程包括以下關鍵步驟:
- 文檔收集與預處理:從多種來源(產品手冊、FAQ、歷史對話)收集原始資料
- 內容清洗與結構化:去除無關信息,提取核心知識點
- 向量化與索引構建:使用嵌入模型將文本轉換為向量,建立高效檢索索引
以下是RAG實現的代碼示例:
class RAGSystem:
def __init__(self, embedding_model, llm, knowledge_base):
self.embedding_model = embedding_model
self.llm = llm
self.knowledge_base = knowledge_base
def retrieve_relevant_info(self, query, top_k=3):
# 將查詢轉換為向量
query_vector = self.embedding_model.encode(query)
# 向量相似度檢索
results = self.knowledge_base.similarity_search(query_vector, top_k)
return results
def generate_answer(self, query, context):
prompt = f"""
基於以下已知信息回答問題:
已知信息:{context}
問題:{query}
要求:
1. 如果已知信息足夠回答問題,請直接基於已知信息回答
2. 如果已知信息不足,請謹慎擴展,並註明哪些是已知信息,哪些是擴展內容
3. 回答要簡潔明瞭,專業友好
"""
response = self.llm.generate(prompt)
return response
def process_query(self, query):
# 檢索相關知識
relevant_info = self.retrieve_relevant_info(query)
# 生成回答
answer = self.generate_answer(query, relevant_info)
return answer3.3 對話管理與上下文維護
多輪對話能力是衡量智能客服系統成熟度的重要指標。系統需要能夠維護對話上下文,理解指代關係,實現連貫的交互體驗。
對話管理的核心是對話狀態跟蹤和上下文編碼。以下是一個簡化的對話管理器實現:
class DialogueManager:
def __init__(self, max_turns=10):
self.max_turns = max_turns
self.dialogues = {} # 存儲各會話的對話歷史
def add_message(self, session_id, message, role):
if session_id not in self.dialogues:
self.dialogues[session_id] = []
self.dialogues[session_id].append({
'role': role,
'content': message,
'timestamp': time.time()
})
# 保持最近N輪對話
if len(self.dialogues[session_id]) > self.max_turns * 2:
self.dialogues[session_id] = self.dialogues[session_id][-self.max_turns*2:]
def get_context(self, session_id, recent_turns=3):
if session_id not in self.dialogues:
return ""
dialogues = self.dialogues[session_id]
# 獲取最近幾輪對話作為上下文
context_dialogues = dialogues[-recent_turns*2:] if len(dialogues) > recent_turns*2 else dialogues
context_str = ""
for dialogue in context_dialogues:
speaker = "用户" if dialogue['role'] == 'user' else "客服"
context_str += f"{speaker}: {dialogue['content']}\n"
return context_str4 高級功能與優化策略
4.1 情感識別與個性化響應
情感分析技術讓智能客服能夠感知用户情緒狀態,並調整迴應策略。當系統檢測到用户情緒激動或不滿時,可以優先轉入人工客服或採用更謹慎的迴應方式。
實現情感識別與個性化響應的代碼示例:
class SentimentAwareResponder:
def __init__(self, sentiment_model, llm):
self.sentiment_model = sentiment_model
self.llm = llm
def analyze_sentiment(self, text):
sentiment_result = self.sentiment_model.predict(text)
return sentiment_result
def generate_response(self, query, context, sentiment):
if sentiment['label'] == 'negative' and sentiment['score'] > 0.8:
# 高負面情緒特殊處理
prompt = f"""
用户情緒:非常不滿
用户問題:{query}
對話上下文:{context}
請以安撫用户情緒為首要目標,表達理解和歉意,然後專業地解決問題。
避免使用模板化回覆,要體現真誠和關懷。
"""
else:
# 正常回復
prompt = f"""
用户問題:{query}
對話上下文:{context}
請專業、友好地回答用户問題。
"""
response = self.llm.generate(prompt)
return response4.2 性能優化與高併發處理
企業環境中的智能客服系統需要處理高併發請求,這對系統性能提出了嚴峻挑戰。以下是一些關鍵優化策略:
連接池與緩存優化:建立數據庫連接池和緩存機制,顯著減少重複計算和數據庫查詢。
import redis
from django.core.cache import cache
class OptimizedResponseHandler:
def __init__(self):
self.redis_client = redis.Redis(host='localhost', port=6379, db=0)
def get_cached_response(self, query_hash):
# 檢查緩存中是否有相似問題的回答
cached_answer = self.redis_client.get(f"response_cache:{query_hash}")
return cached_answer.decode('utf-8') if cached_answer else None
def process_query_optimized(self, query):
# 生成查詢哈希用於緩存查找
query_hash = hashlib.md5(query.encode()).hexdigest()
# 先檢查緩存
cached_response = self.get_cached_response(query_hash)
if cached_response:
return cached_response
# 緩存未命中,正常處理
response = self.rag_system.process_query(query)
# 緩存結果
self.redis_client.setex(f"response_cache:{query_hash}", 3600, response) # 緩存1小時
return response異步處理與消息隊列:使用Celery等異步任務框架處理耗時操作,避免阻塞主請求線程。
from celery import Celery
app = Celery('smart_customer_service', broker='redis://localhost:6379/0')
@app.task
def process_message_async(session_id, message_content):
# 模擬耗時處理
response = ai_processor.process(message_content)
# 發送回覆
send_response_to_wechat(session_id, response)
# 在視圖函數中異步處理
def handle_wechat_message(request):
session_id = request.POST.get('session_id')
message_content = request.POST.get('content')
# 異步處理消息
process_message_async.delay(session_id, message_content)
# 立即返回接受響應
return JsonResponse({'status': 'accepted'})5 部署、監控與持續改進
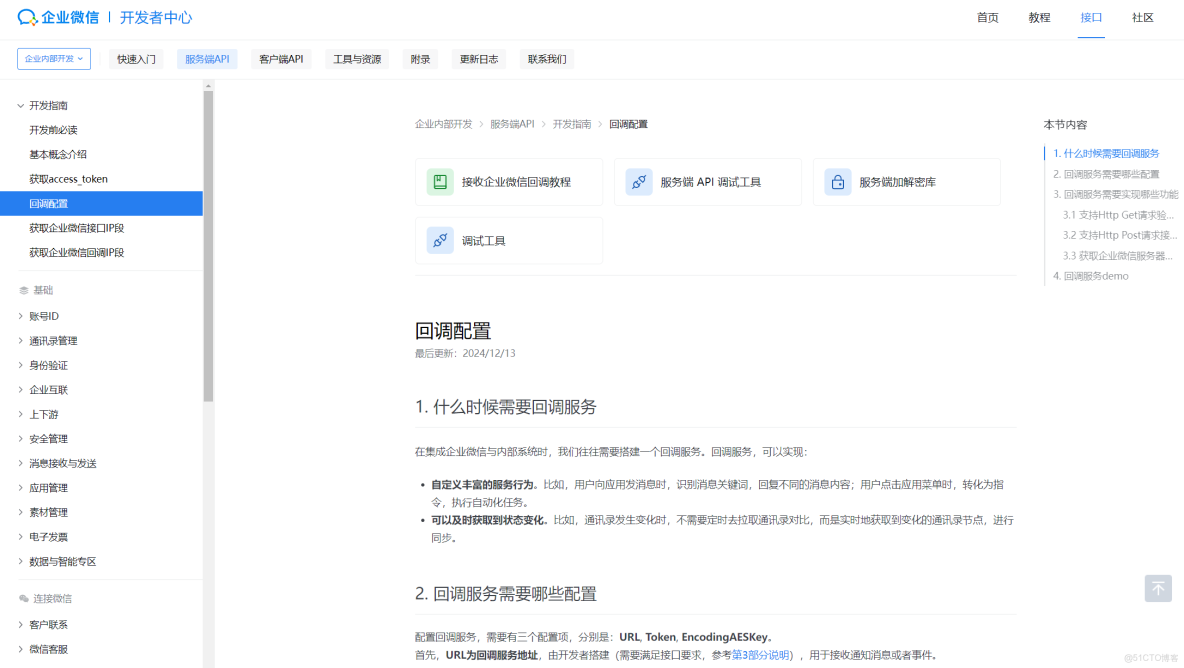
5.1 系統部署與運維管理
智能客服系統的生產環境部署需要綜合考慮安全性、可擴展性和可靠性。推薦使用容器化部署方式,便於版本管理和水平擴展。
監控體系構建是確保系統穩定運行的關鍵。需要建立以下監控指標:
- 性能指標:響應時間、吞吐量、錯誤率
- 業務指標:問題解決率、用户滿意度、轉人工率
- AI指標:意圖識別準確率、回答質量評分
以下是一個監控系統的簡單實現:
class SystemMonitor:
def __init__(self):
self.metrics = {
'response_times': [],
'error_count': 0,
'total_requests': 0
}
def record_response_time(self, response_time):
self.metrics['response_times'].append(response_time)
# 保持最近1000個記錄
if len(self.metrics['response_times']) > 1000:
self.metrics['response_times'] = self.metrics['response_times'][-1000:]
def record_error(self):
self.metrics['error_count'] += 1
def record_request(self):
self.metrics['total_requests'] += 1
def get_performance_report(self):
avg_response_time = np.mean(self.metrics['response_times']) if self.metrics['response_times'] else 0
error_rate = self.metrics['error_count'] / self.metrics['total_requests'] if self.metrics['total_requests'] > 0 else 0
return {
'avg_response_time': avg_response_time,
'error_rate': error_rate,
'total_requests': self.metrics['total_requests']
}5.2 持續學習與模型優化
智能客服系統需要持續學習機制來適應新的用户查詢和業務變化。以下是實現持續學習的關鍵方法:
反饋循環機制:收集用户對回答的滿意度反饋,用於改進模型和知識庫。
class FeedbackLearningSystem:
def __init__(self, rag_system):
self.rag_system = rag_system
self.feedback_db = FeedbackDatabase()
def process_feedback(self, query, response, feedback, correct_answer=None):
# 記錄反饋
self.feedback_db.add_feedback(query, response, feedback, correct_answer)
# 根據反饋類型採取不同行動
if feedback == 'negative' and correct_answer:
# 將正確答案添加到知識庫
self.rag_system.add_to_knowledge_base(query, correct_answer)
# 定期重新訓練模型
if self.feedback_db.get_negative_feedback_count() > 100:
self.retrain_model()
def retrain_model(self):
# 獲取反饋數據
feedback_data = self.feedback_db.get_feedback_data()
# 基於反饋數據重新訓練模型
# 具體實現取決於使用的模型和技術棧
passA/B測試框架:對比不同算法或模型版本的效果,數據驅動決策。
class ABTestFramework:
def __init__(self):
self.active_experiments = {}
def assign_variant(self, user_id, experiment_name):
# 確定性分配用户到實驗組
hash_value = hashlib.md5(f"{user_id}{experiment_name}".encode()).hexdigest()
variant = int(hash_value, 16) % 2 # 50/50分配
return 'A' if variant == 0 else 'B'
def track_experiment_result(self, experiment_name, variant, success):
# 記錄實驗結果
key = f"{experiment_name}:{variant}"
if key not in self.active_experiments:
self.active_experiments[key] = {'trials': 0, 'successes': 0}
self.active_experiments[key]['trials'] += 1
if success:
self.active_experiments[key]['successes'] += 16 總結與展望
企業微信API智能客服系統的建設是一個持續迭代的過程,需要平衡技術先進性與業務實用性。隨着AI技術的快速發展,特別是大語言模型能力的不斷提升,智能客服系統正朝着更自然、更智能的方向演進。
未來,企業微信智能客服系統的發展趨勢將集中在以下幾個方向:
- 多模態交互:支持圖像、語音、視頻等多種輸入輸出方式
- 預測性服務:基於用户行為預測需求,主動提供幫助
- 深度個性化:根據用户歷史和行為特徵,提供高度定製化的服務體驗
- 生態集成:與企業內部其他系統深度集成,提供無縫的業務辦理能力
通過本文介紹的技術方案和實施策略,企業可以構建出高效、智能的客服系統,顯著提升客户滿意度和運營效率。





