
深度多任務聲回聲消除
摘要
聲學回聲消除或抑制方法旨在抑制揚聲器與麥克風之間的聲耦合產生的回聲。傳統的回聲估計方法採用自適應濾波。由於遠端信號聲路的非線性,需要進一步的後處理來衰減這些非線性分量。本文提出了一種基於深度門控循環神經網絡的麥克風信號的近端信號估計方法。利用多任務學習對該體系結構進行訓練,學習估計回聲的輔助任務,以改進估計乾淨的近端語音信號的主要任務。實驗結果表明,我們提出的基於深度學習的方法在單説話時段的回聲損耗增強(ERLE)和雙説話時段的語音質量感知評價(PESQ)評分方面優於現有的看不見説話人的方法。
摘要:非線性回聲消除,深度學習,門控循環神經網絡,循環神經網絡,門控循環單元
1 引言
當揚聲器發出的遠端信號耦合回近點的麥克風時,就會產生聲學回聲。因此,遠端用户聽到的是近端信號和他自己聲音的延遲和修改版本的混合,稱為聲學回聲。回聲消除器(AEC)或抑制器(AES)的目標是在不失真的情況下減少這種回聲。傳統的方法是通過自適應濾波器[1]來估計回聲路徑來解決這個問題。由於這些方法大多假定聲回聲和遠端信號之間存在線性關係,通常採用非線性後濾波來抑制殘留的殘餘回聲[2][3]。
神經網絡在過去的[4]中被用作非線性後濾波。然而,在當時,由於計算能力和訓練數據大小的限制,導致了相對較小的網絡實現和有限的整體AEC性能。近年來,深度學習在各種語音處理任務[5][6][7][8]中顯示出了巨大的潛力,但考慮到聲學回聲消除的工作並不多。Lee等人[9]使用深度神經網絡(DNN)估計殘差回聲抑制的增益。循環神經網絡(RNNs)在序列建模任務(如自然語言處理(NLP))中表現出了巨大的成功,特別是當它們被用於編碼器-解碼器框架[10]或作為序列學習機器[11]時。RNN在這些框架中特別強大,因為它們能夠高度建模這些任務中固有的豐富上下文依賴關係。最近,Zhang和Wang[12]利用雙向長期記憶(BLSTM)從麥克風和遠端信號的特徵來預測掩碼,然後利用該掩碼重新合成近端語音信號。為了實現回聲估計,在雙講期間,傳統的方法通常需要雙講檢測器(DTD),當近端和遠端信號同時出現時,停止濾波器自適應。相比之下,一些基於深度學習的回聲消除系統不需要單獨的DTD模塊來消除聲波回聲[9][12]。
本文提出了一種新的用於聲回聲消除的循環網絡。更具體地説,我們採用編碼解碼器結構的深門控循環單元(GRU)[10][13]網絡,將麥克風和遠端信號的光譜特徵映射到超空間,然後從編碼的超空間中解碼近端信號的目標光譜特徵。利用多任務學習對該體系結構進行訓練,學習估計回聲的輔助任務,以改進估計乾淨的近端語音信號的主要任務。實驗結果表明,該模型可以在不需要單獨的DTD的情況下,在單話音和雙話音週期內消除聲回聲。
本文其餘部分的結構如下。我們首先在第2節中給出這個問題的正式定義。然後,我們在第3節介紹我們的上下文感知多任務循環網絡,然後在第4節介紹實驗設置和結果。最後,我們在第5節中總結。
2 問題陳述
\(v(t)\)為\(t\)時刻的任意時域信號,系統模型和提出的解如圖1所示。麥克風信號\(d(t)\)由近端語音信號\(s(t)\)和聲學回聲\(y(t)\)組成:
\[d(t)=s(t)+y(t) (1) \]
\(x(t)\)的改進版本幷包括房間脈衝響應(RIR)和揚聲器失真。
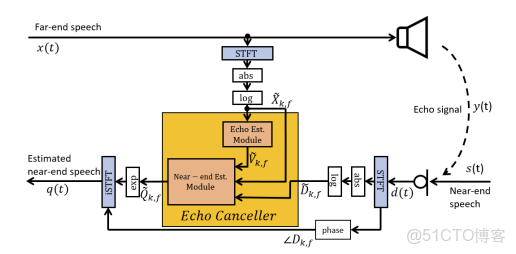
圖1 深度多任務聲回聲消除圖
\(q(t)\)。
回聲損耗增強度量(ERLE)通常用於評估系統在沒有近端信號的單講情況下實現的回聲減少。ERLE定義為:
\[E R L E(\mathrm{~dB})=10 \log _{10} \frac{E\left\{d^{2}(t)\right\}}{E\left\{\mathrm{q}^{2}(t)\right\}} (2)\]
式中,E是通過平均實現的統計期望操作。
為了評價系統在雙講階段的性能,通常採用語音質量感知評價(PESQ)。PESQ僅通過將預估的接近結束語音與雙講期間的ground-truth接近結束語音進行比較來計算。PESQ評分範圍為-0.5 ~ 4.5,分數越高質量越好。
\(v(t)\)在幀k和頻率點f處的STFT復值譜記為\(V_{k, f}\)。它的相位表示為\(\angle V_{k, f}\),它的對數大小用\(\tilde{V}_{k, f}\)表示。讓\(\widetilde{V}_{k}\)為所有頻率點和幀k的對數幅值向量。
3 方法提出
在本文中,我們提出使用上下文感知的多任務門控RNN來估計近端語音信號。具體來説,我們使用的是對數譜特徵的遠端語音x和麥克風d作為輸入。目標輸出包括真實回聲信號的對數光譜特徵和近端語音信號s。該架構通過聯合優化加權損耗來估計近端語音和回聲信號。利用估計回聲得到的信息來更好地估計近端語音。據我們所知,本文是第一個提出用於AEC的多任務網絡。
\(\widetilde{\boldsymbol{V}}_{k}\)回聲信號。最後一層GRU的輸出從這個網絡饋送到另一個三層堆疊的GRU網絡與\(\widetilde{\boldsymbol{D}}_{k}\)和\(\widetilde{\boldsymbol{X}}_{k}\)並回歸到\(\widetilde{\boldsymbol{Q}}_{k}\),它是對近端信號的對數譜幅值的估計。
\(\widetilde{\boldsymbol{Q}}_{k}\)並利用短時傅里葉反變換(iSTFT)或Griffin-Lim算法[14]對麥克風信號進行相位分析。為了簡單起見,我們只展示了使用iSTFT重構的結果。
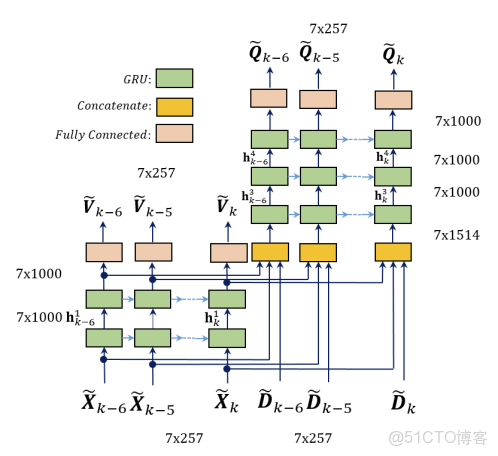
圖2 提出的用於回聲和近端信號估計的多任務展開GRU網絡
3.1 因果上下文感知的輸入和輸出
以前的研究表明,使用過去和/或未來的幀可以幫助對語音處理應用[15]的當前幀進行估計。然而,固定的上下文窗口通常用作全連接層[16]的輸入。在這些方法中,上下文信息可能會在第一層之後丟失,因為信息會流經更深的層。在他的研究中,我們在網絡的輸入和輸出中都使用了上下文特徵,以保持整個網絡的上下文信息。當前時間的輸入特徵由當前幀的特徵向量和之前六幀的特徵向量組成。選擇因果窗口是為了防止額外的延遲。有50%重疊的七幀產生了一個112ms的接受場,足夠長來處理語音信號。為了融入上下文感知,我們為回聲估計模塊和近端估計模塊分別部署了7個時間步長的展開深度GRU網絡,如圖2所示。
該網絡的輸出還包括當前幀特徵向量和之前的六幀。在訓練過程中,每一個幀都針對它們自己的目標進行優化。這有助於模型根據目標的上下文了解權重。在推理時間中,最後一幀僅作為模型的輸出。
3.2 基於多任務GRU的AEC
我們提出的AEC方法的基礎模型架構由GRU的一個變體組成。更具體地説,GRUs有以下輸出激活:
\[\mathbf{h}_{k}=\mathbf{z}_{k} \odot \mathbf{h}_{k-1}+\left(1-\mathbf{z}_{k}\right) \odot \hat{\mathbf{h}}_{k} (3)\]
其中\(\odot\)是element-wise的乘法,以及更新門\(\mathbf{Z}_{k}\)是:
\[\mathbf{z}_{k}=\sigma\left(\mathbf{W}_{z} \widetilde{\boldsymbol{X}}_{k}+\mathbf{U}_{z} \mathbf{h}_{k-1}\right) (4)\]
其中\(\sigma\)是sigmoid函數。候選隱藏狀態\(\hat{\mathbf{h}}_{k}\)通過計算:
\[\hat{\mathbf{h}}_{k}=\operatorname{elu}\left(\mathbf{W} \widetilde{\boldsymbol{X}}_{k}+\mathbf{U}\left(\mathbf{r}_{k} \odot \mathbf{h}_{k-1}\right)\right) (5)\]
其中elu是指數線性單位函數且復位門\(\mathbf{r}_{k}\)通過計算:
\[\mathbf{r}_{k}=\sigma\left(\mathbf{W}_{r} \widetilde{\boldsymbol{X}}_{k}+\mathbf{U}_{r} \mathbf{h}_{k-1}\right) (6)\]
其中,\(\mathbf{U}, \mathbf{W}, \mathbf{U}_{r}, \mathbf{W}_{r}, \mathbf{U}_{z}\), 和 \(\mathbf{W}_{z}\)為GRUs的內部權重矩陣。
\(\widetilde{\boldsymbol{X}}_{k}\)作為每個GRU的輸入,並使用線性激活的全連接(FC)輸出層估算\(\widetilde{\boldsymbol{V}}_{k}\)。最後一個GRU層的輸出從第一個堆棧得到連接上下文感知幀\(\widetilde{\boldsymbol{X}}_{k}\)和\(\widetilde{\boldsymbol{D}}_{k}\)為第二個堆棧的第一個GRU層創建7×1514維度的輸入。第二堆棧由3個GRU層和一個FC層組成,線性激活來估計上下文組件幀的\(\widetilde{\boldsymbol{Q}}_{k}\)估計的近端語音。在圖2中,\(\widetilde{\boldsymbol{X}}_{k}\)是幀K的一個大小為257的特徵向量,和\(\mathbf{h}_{k}^{1}\)為第一層GRU的輸出向量,大小為1000。每個層的輸出尺寸如圖2所示。
\(\beta_{1}=0.9, \beta_{2}=0.999\),\(\epsilon=10^{-3}\)為100個epoch,批量大小為100。所有層的權值用Xavier方法[19]初始化,並將偏差設為零。我們將學習速率設置為0.0003。為了避免過擬合,我們對正則化常數為0.000001的所有權值使用L2正則化。
3.3 加權損失函數
語音處理應用中一個常見的損失函數是均方誤差(MSE)[12],它是在特徵域(通常是STFT)中從地真源s和網絡估計輸出q之間計算出來的。由於估計回波路徑信號可以提供更多信息來確定網絡權重(就像在卷積解決方案中一樣),我們提出了一個加權損失函數來使用該信息。這個函數是聯合優化的:
\[\operatorname{loss}_{k}=\beta \sum_{n=0}^{6}\left\|\tilde{S}_{k-n}-\widetilde{\boldsymbol{Q}}_{k-n}\right\|_{1}+(1-\beta) \sum_{n=0}^{6}\left\|\widetilde{\boldsymbol{Y}}_{k-n}-\widetilde{\boldsymbol{V}}_{k-n}\right\|_{1} (7)\]
其中,\(\beta\)是權重因子。
4 實驗結果
4.1 數據集的準備
我們使用TIMIT數據集[20]來評估AEC的性能。我們創建了與[12]中報告的數據集相似的數據集,具體採取了以下步驟:從TIMIT的630個揚聲器中,隨機選擇100對揚聲器(40 male-female, 30 male-male, 30 female-female)作為遠端和近端揚聲器。隨機選擇同一個遠端説話者的三種話語,然後連接起來形成一個遠端信號。通過填充前面和後面的零,一個近端揚聲器的每一個語音都被擴展到與遠端信號相同的大小。使用7個近端揚聲器的聲音產生3500個訓練混合物,每個近端信號與5個不同的遠端信號混合。
從剩下的430個揚聲器中,我們隨機挑選了另外100對作為遠端和近端揚聲器。我們按照上述相同的步驟進行,但這一次只使用近端揚聲器的三種聲音來生成300個測試混合物,其中每個近端信號與一個遠端信號混合。因此,測試混合物來自未經訓練的演講者。
\(x_{\max }\)設置為輸入信號最大音量的80%):
\[x_{c l i p}(t)=\left\{\begin{array}{c}-x_{\max } \text { if } x(t)<-x_{\max } \\x(t) \text { if }|x(t)| \leq x_{\max } \\ x_{\max } \text { if } x(t)>x_{\max } \end{array}\right. (8) \]
然後,為了模擬揚聲器失真,我們應用如下的sigmoid函數:
\[x_{n l}(t)=4\left(\frac{2}{1+\exp (-a . b(t))}-1\right) (9)\]
其中,\(b(t)=1.5 x_{\text {clip }}(t)-0.3 x_{\text {clip }}(t)^{2}\) 並且如果\(b(t)>0\)則\(a=4\)否則\(a=0.5\)。最後,將sigmoidal函數的輸出與隨機選擇的RIR\(g(t)\)去模擬遠端信號在室內的聲傳輸:
\[y_{n l}(t)=x_{n l}(t) * g(t) (10)\]
其中*表示卷積。RIRs的長度設置為512,模擬室大小為\(4 \mathrm{~m} \times 4 \mathrm{~m} \times 3 \mathrm{~m}\),麥克風固定在[2 2 1.5]m的位置,揚聲器隨機放置在7個距離麥克風1.5m的位置。利用圖像法[22]生成RIRs,混響時間(\(T_{60}\))為200ms。從7個RIRs中,我們使用前6個RIRs生成訓練數據,最後一個用於生成測試數據。我們還建模了一個線性回回聲路徑,只將遠端信號與RIR卷積產生回聲信號,該模型不考慮剪輯和揚聲器失真:
\[y_{\operatorname{lin}}(t)=x(t) * g(t) (11)\]
\(\{-6,-3,0,3,6\} \mathrm{dB}\)中隨機選擇產生信號與回聲比(SER)水平的麥克風信號。用户服務水平是根據“雙講”時段計算的:
\[\operatorname{SER}(\mathrm{dB})=10 \log _{10} \frac{E\left\{s^{2}(t)\right\}}{E\left\{\mathrm{y}^{2}(t)\right\}} (12)\]
對於測試混合物,我們在3個不同的SER級別(0dB、3.5dB和7dB)下生成麥克風信號。在SER水平為0dB、3.5dB和7dB時,未處理混合樣本的PESQ得分線性模型為1.87、2.11和2.34,非線性模型為1.78、2.03和2.26。未處理的PESQ分數是通過比較麥克風信號和雙話期間的近端信號來計算的。
4.2 數值結果
作為基準系統,我們使用頻域歸一化最小均方(NLMS)作為AES[23]。基於麥克風信號和遠端信號的能量,採用了DTD算法。在[24]中提出的方法的基礎上,我們進一步應用了一種RES算法。我們還將我們的結果與[12]中報道的雙向長短時記憶(BLSTM)方法進行了比較。
\(\widetilde{\boldsymbol{D}}_{k}\)和\(\widetilde{\boldsymbol{X}}_{k}\)作為輸入,損失函數的計算僅通過懲罰網絡輸出對ground-truth的近端語音特徵向量。結果表明,多任務GRU在PESQ和ERLE方面均優於單任務GRU。結果表明,該方法在所有條件下均優於傳統的AES+RES和BLSTM方法。
表1 聲學路徑線性模型的ERLE和PESQ得分
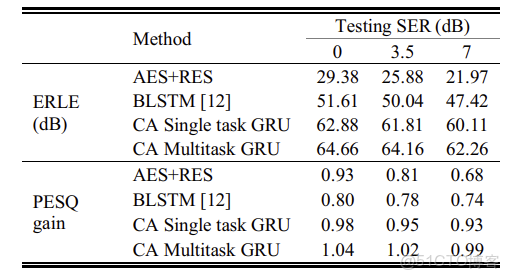
表2 聲學路徑非線性模型的ERLE和PESQ得分。
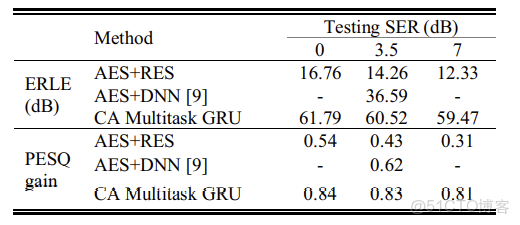
\(y_{n l}(t)\)因此,在產生麥克風信號時,我們的模型包含了功率放大器剪輯和揚聲器失真。我們再次比較了我們的方法與傳統AES+RES的結果。我們還將我們的結果與[9]中提出的使用基於DNN的正則的AES進行了比較,該正則表示為“AES+DNN”。結果表明,該方法在PESQ和ERLE方面都優於其他兩種方法。圖3中的聲譜圖展示了一個使用我們提出的帶有0dB SER的非線性回回聲路徑模型的深度多任務AEC示例。顯然,該方法在無明顯近端失真的情況下獲得了較好的回聲抑制效果。
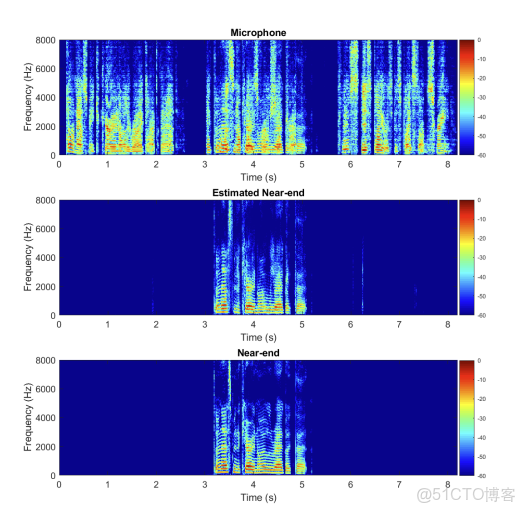
圖3 聲學路徑非線性模型和0dB SER中麥克風、估計近端和近端信號的譜圖
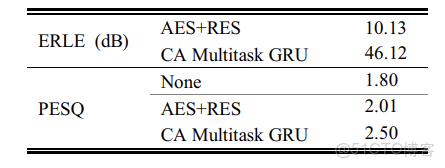
我們也評估了我們所提出的方法的性能存在的加性噪聲和非線性的回回聲路徑模型。在生成訓練數據時,我們在10dB信噪比水平添加白噪聲,在3.5dB SER水平添加非線性回回聲路徑。我們將我們的方法與傳統的AES+RES進行了比較。我們的基於多任務的方法比傳統方法有很大的優勢,如表3所示。
表3 回聲路徑非線性模型(SER=3.5dB)和加性噪聲(SNR =10dB)下的ERLE和PESQ得分。
5 總結
我們提出了一種用於AEC的深度多任務循環神經網絡,該網絡在單説話和雙説話兩種情況下都有很好的表現。我們展示了同時對回聲和近端信號進行端到端多任務學習的優勢。我們還演示了在估計純淨的近端信號時,具有低延遲因果上下文窗口的優勢,以提高上下文感知。在參考數據集上比較,我們提出的多任務AEC網絡能比其他方法更顯著地減少回聲,並且對加性背景噪聲有較強的魯棒性。在未來的工作中,我們打算在更嚴重的背景噪聲環境中探索AEC。
6 參考文獻
[1] E. Hänsler and G. Schmidt, Acoustic Echo and Noise Control: A Practical Approach, Adaptive and learning systems for signal processing, communications, and control. Hoboken, N.J, USA: Wiley-Interscience, 2004.
[2] S. Gustafsson, R. Martin, and P. Vary, “Combined acoustic echo control and noise reduction for hands-free telephony,” Signal Processing, vol. 64, no. 1, pp. 21–32, 1998.
[3] V. Turbin, A. Gilloire, and P. Scalart, “Comparison of three postfiltering algorithms for residual acoustic echo reduction,” in Proc. IEEE International Conference on Acoustics, Speech, and Signal Processing, 1997, pp. 307–310.
[4] A. Schwarz, C. Hofmann, and W. Kellermann, “Spectral featurebased nonlinear residual echo suppression,” in Proc. Applications of Signal Processing to Audio and Acoustics (WASPAA), 2013, pp. 1-4.
[5] G. Hinton, L. Deng, G. E. Dahl, A. Mohamed, N. Jaitly, A. Senior, V. Vanhoucke, P. Nguyen, T. Sainath, and B. Kingsbury, “Deep neural networks for acoustic modeling in speech recognition,” IEEE Signal Processing Magazine, vol. 29, no. 6, pp.82–97, 2012.
[6] Y. Wang and D. L. Wang, “Towards scaling up classificationbased speech separation,” IEEE Transactions on Acoustics, Speech and Signal Processing, vol. 21, no. 7, pp. 1381–1390, 2013.
[7] X. Lu, Y. Tsao, S. Matsuda, and C. Hori, “Speech enhancement based on deep denoising autoencoder,” in Proc. Annual Conference of the International Speech Communication Association, 2013, pp. 555–559.
[8] Y. Xu, J. Du, L.-R. Dai, and C.-H. Lee, “An experimental study on speech enhancement based on deep neural networks,” IEEE Signal Processing Letters, vol. 21, no. 1, pp. 65–68, 2014.
[9] C. M. Lee, J. W. Shin, and N. S. Kim, “DNN-based residual echo suppression,” in Proc. Annual Conference of the International Speech Communication Association, 2015, pp. 1775–1779.
[10] K. Cho, B. van Merriënboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwen, and Y. Bengio, “Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation,” in Proc. Empirical Methods in Natural Language Processing, 2014, pp. 1724–1734.
[11] I. Sutskever, O. Vinyals, and Q. V. Le, “Sequence to sequence learning with neural networks,” in Proc. Advances Neural Information Processing Systems, 2014, pp. 3104–3112.
[12] H. Zhang and D. Wang, “Deep Learning for Acoustic Echo Cancellation in Noisy and Double-Talk Scenarios,” in Proc. Annual Conference of the International Speech Communication Association, 2018, pp. 3239-3243.
[13] J. Chung, C. Gulcehre, K. Cho, and Y. Bengio, “Empirical evaluation of gated recurrent neural networks on sequence modeling,” in Proc. NIPS Deep Learning Workshop, 2014.
[14] D. Griffin and J. Lim, “Signal estimation from modified shorttime fourier transform,” IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 32, no. 2, pp. 236–243, 1984.
[15] F. Santos and T. H. Falk., “Speech Dereverberation With ContextAware Recurrent Neural Networks,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 26, no 7, pp. 1236–1246, 2018.
[16] K. Han, Y. Wang, D. Wang, W. S. Woods, I. Merks, and T. Zhang, “Learning spectral mapping for speech dereverberation and denoising,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 23, no. 6, pp. 982–992, 2015.
[17] S. J. Reddi, S. Kale, and S. Kumar, “On the convergence of Adam and beyond,” in International Conference on Learning Representations (ICLR), 2018.
[18] D. P. Kingma and J. L. Ba, “Adam: a method for stochastic optimization,” in International Conference on Learning Representations (ICLR), 2015.
[19] X. Glorot, and Y. Bengio, “Understanding the difficulty of training deep feedforward neural networks,” in Proc. International Conference on Artificial Intelligence and Statistics, 2010, pp. 249-256.
[20] . F. Lamel, R. H. Kassel, and S. Seneff, “Speech database development: Design and analysis of the acoustic-phonetic corpus,” in Speech Input/Output Assessment and Speech Databases, 1989.
[21] S. Malik and G. Enzner, “State-space frequency-domain adaptive filtering for nonlinear acoustic echo cancellation,” IEEE Transactions on audio, speech, and language processing, vol. 20, no. 7, pp. 2065–2079, 2012.
[22] J. B. Allen, D. A. Berkley, “Image method for efficiently simulating small-room acoustics,” The Journal of Acoustic Society of America, vol. 65, no. 4, pp. 943-950, 1979.
[23] C. Faller and J. Chen, “Suppressing acoustic echo in a spectral envelope space,” IEEE Transactions on Acoustic, Speech and Signal Processing, vol. 13, no. 5, pp. 1048–1062, 2005.
[24] R. Martin and S. Gustafsson, “The echo shaping approach to acoustic echo control”, Speech Communication, vol. 20, no. 3-4, pp. 181-190, 1996.