
由於從老系統導數據是通過excel表的方式導出的,裏面數據有幾十萬條數據,如果只是簡單通過複製黏貼的方式複製到數據庫中,那麼這個過程將會非常耗時和繁瑣的。於是就去研究了下sqlloader如何使用,經過研究後發現這個方法非常管用,就記錄下來供大家參考參考
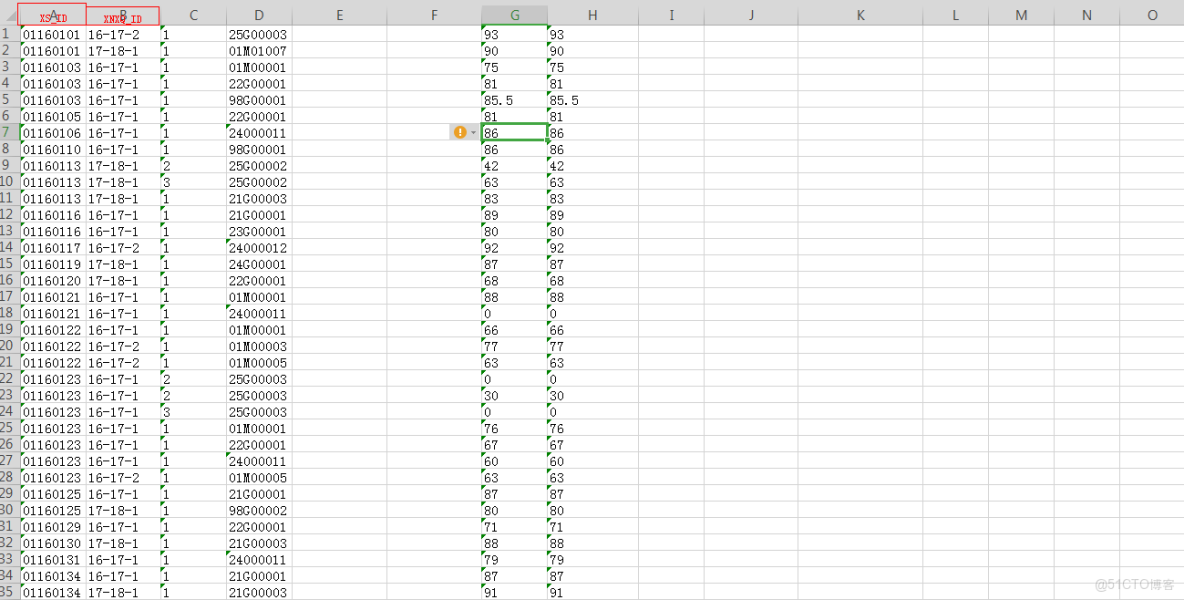
第一步:整理Excel表格的數據如下:
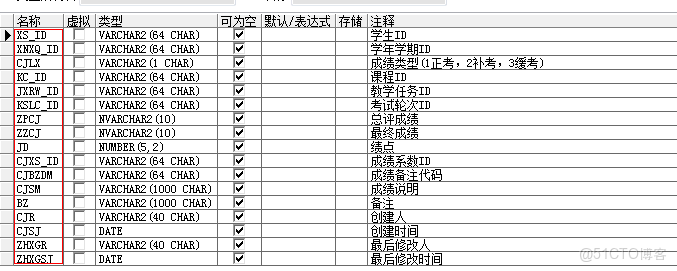
excel表格的數據列分別對應數據庫表的字段(注意:順序一定要嚴格按照數據庫表字段的順序)如:xs_id,xnxq_id,kc_id,cjlx,jxrw_id,kslc_id,zpcj,zzcj,jd,cjxs_id,cjbzdm,cjsm,bz,cjr,cjsj,zhxgr,zhxgsj
數據庫表設計如下:
編寫控制文件,先通過鼠標右鍵新建一個txt記事本,然後再修改類型為ctl文件,如命名為:input.ctl
裏面內容如下:其中
infile --告訴sqlldr要加載的數據就包含在控制文件本身
E:\sixscore.csv表示將第一步中的excel表格中數據轉換為csv文件後存放的位置
into table T_CJGL_XSHZCJ_TMP --加載到哪個表nullcols(xs_id,xnxq_id,cjlx,kc_id,jxrw_id,kslc_id,zpcj,zzcj,jd,cjxs_id,cjbzdm,cjsm,bz,cjr,cjsj,zhxgr,zhxgsj) --所要加載的列terminated by ','表示用逗號,
使用TRAILING NULLCOLS。這樣,如果輸入記錄中不存在某一列的數據,sqlldr就會為該列綁定一個null值。
具體代碼內容如下:load data
infile 'E:\sixscore.csv'
insert into table T_CJGL_XSHZCJ_TMP fields terminated by ','
trailing nullcols(xs_id,xnxq_id,cjlx,kc_id,jxrw_id,kslc_id,zpcj,zzcj,jd,cjxs_id,cjbzdm,cjsm,bz,cjr,cjsj,zhxgr,zhxgsj)將xls文件轉換成.csv文件,步驟如下:
1.點擊文件,另存為
2.選擇文件類型為.csv

注意:如果是多工作簿要先拆分出來,不然不能由.xsl格式轉換成.csv格式:
將input.ctl和.csv文件同時放在E盤如:
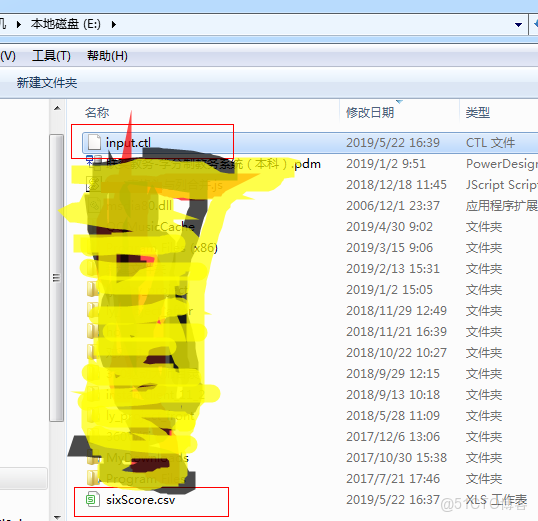
3.存放在自己指定的位置如E盤即可。
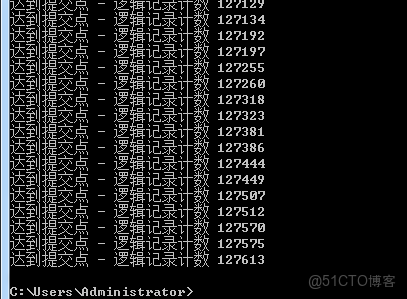
第四:打開win+R輸入cmd,然後輸入:sqlldr userid=tzjw_hxsj/tzjw_hxsj@55.192.96.100/orcl control=e:\input.ctl
點擊回車即可看到就表示成功了
-------------------------------------
sqlldr導入的四種加載方式:
APPEND :原先的表有數據 就加在後面
INSERT:裝載空表 如果原先的表有數據 sqlloader會停止 默認值
REPLACE :原先的表有數據 原先的數據會全部刪除
TRUNCATE :指定的內容和replace的相同 會用truncate語句刪除現存數據