
作者:沒有50CM手臂
這是 Python 最新的Dataclasses系列的第二部分內容。在第一部分裏,我介紹了dataclasses的一般用法。這篇博客主要介紹另一個特徵:dataclasses.field。
我們已經知道Dataclasses會生成他們自身的__init__方法。它同時把初始化的值賦給這些字段。以下是我們在上一篇博客裏定義的內容:
- 變量名
- 數據類型
這些內容僅給我們有限的dataclass字段使用範圍。讓我們討論一下這些侷限性,以及它們如何通過dataclass.field被解決。
複合初始化
考慮以下情形:你想要初始化一個變量為列表。你如何實現它呢?一種簡單的方式是使用__post_init__方法。
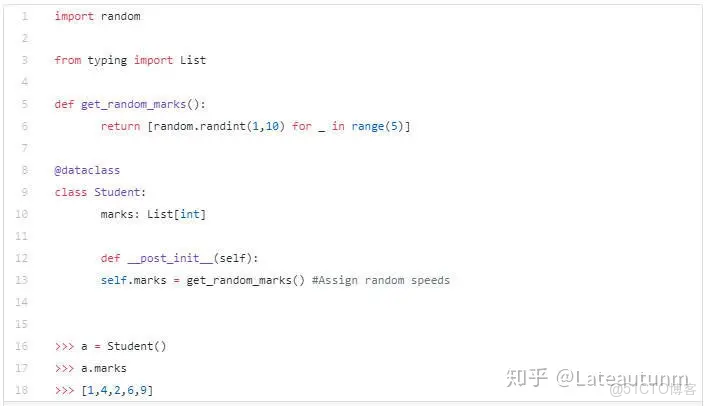
數據類Student產生了一個名為marks的列表。我們不傳遞marks的值,而是使用__post_init__方法初始化。這是我們定義的單一屬性。此外,我們必須在__post_init__裏調用get_random_marks函數。這些工作是額外的。
辛運的是,Python為我們提供了一個解決方案。我們可以使用dataclasses.field來定製化dataclass字段的行為以及它們在dataclass的影響。
仍然是上述的使用情形,讓我們從__post_init__裏去除get_random_marks的調用。以下是使用dataclasses.field的情形:
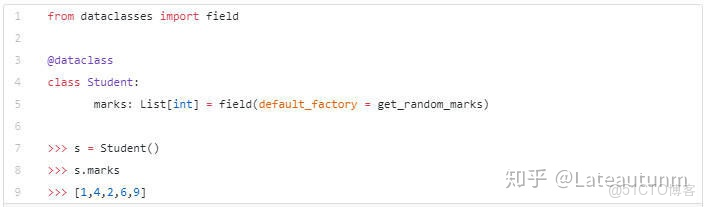
dataclasses.field接受了一個名為default_factory的參數,它的作用是:如果在創建對象時沒有賦值,則使用該方法初始化該字段。
default_factory必須是一個可以調用的無參數方法(通常為一個函數)。
這樣我們就可以使用複合形式初始化字段。現在,讓我們考慮另一個使用場景。
回到頂部
使用全部字段進行數據比較
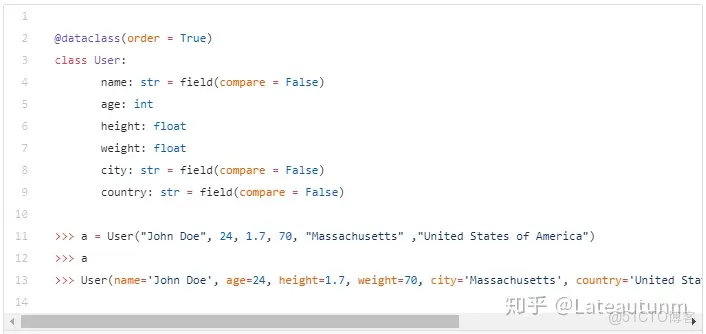
通過上篇博文,我們瞭解到,dataclass能夠自動生成<,=,>,<=和>=這些比較方法。但是這些比較方法的一個缺陷是,它們使用類中的所有字段進行比較,而這種情況往往不常見。更經常地,這種比較方法會給我們使用dataclasses造成麻煩。
考慮以下的使用情形:你有一個數據類用於存放用户的信息。現在,它可能存在以下字段:
- 姓名
- 年齡
- 身高
- 體重
你僅想比較用户對象的年齡、身高和體重。你不想比較姓名。這是後端開發者經常會遇到的使用情景。

自動生成的比較方法會比較一下的數組:

這將會破壞我們的意圖。我們不想讓姓名(name)用於比較。那麼,如何使用dataclasses.field來實現我們的想法呢?
下面是具體步驟:
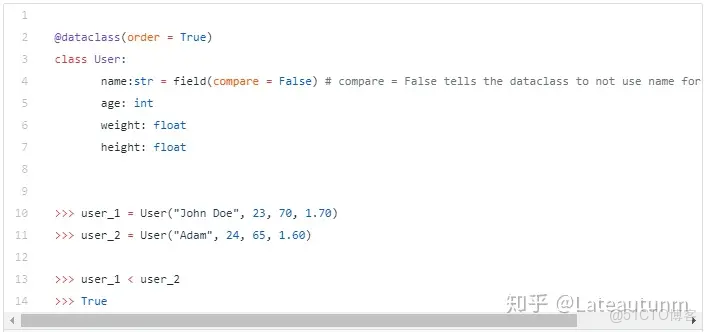
默認情況下,所用的字段都用於比較,因此我們僅僅需要指定哪些字段用於比較,而實現方法是直接把不需要的字段定義為filed(compare=False)。
一個更為簡單的應用情形也可以被討論。讓我們定義一個數據類,它被用來存儲一個數字激起字符串表示。我們想讓比較僅僅發生在該數字的值,而不是他的字符串表示。
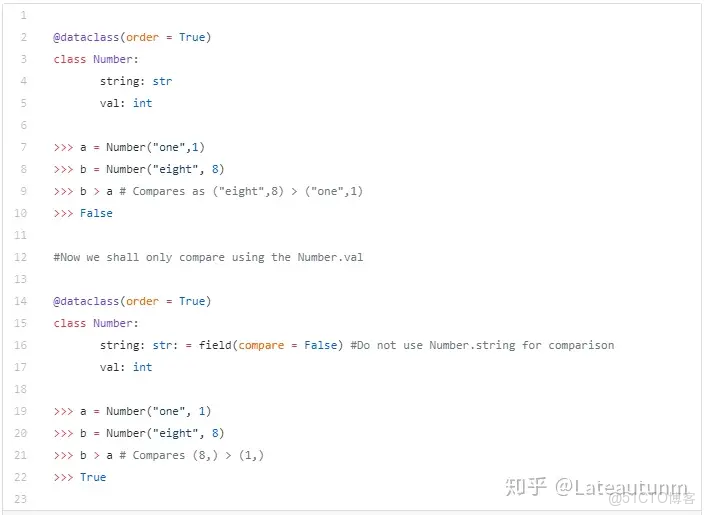
現在,我們有更大的自由來控制 dataclasses 的行為。看起來很棒!
回到頂部
使用全部字段進行數據表示
自動生成的__repr__方法使用所有的字段用於表示。當然,這也不是大多數情形下的理想選擇,尤其是當你的數據類有大量的字段時。單個對象的表示會變得異常臃腫,對調試來説也不利。
想象一下在你的日誌裏看到這樣的表示吧,然後還要寫一個正則表達式來搜索它。太可怕了,對吧?
當然,我們也能夠個性化這種行為。考慮一個類似的使用場景,也許最合適的用於表示的屬性是姓名(name)。那麼對__repr__,我們僅使用它:

這樣看起來就很棒了。調試很方便,比較也有意義!
回到頂部
從初始化中省略字段
目前為止我們看到的所有例子,都有一個共同特點——即我們需要為所有被聲明的字段傳遞值,除了有默認值之外。在那種情形下(指有默認值的情況下),我們可以選擇傳遞值,也可以不傳遞。

但是,還有一種情形:我們可能不想在初始化時設定某個字段的值。這也是一種常見的使用場景。也許你在追蹤一個對象的狀態,並且希望它在初始化時一直被設為False。更一般地,這個值在初始化時不能夠被傳遞。
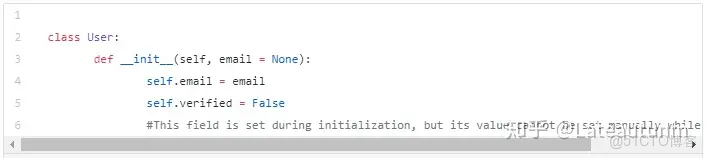
那麼,我們如何實現上述想法呢?以下是具體內容:

瞧啊!我們現在對dataclasses的使用有了更大的靈活性。
回到頂部
總結
希望上兩篇博文能夠幫助你理解dataclass,希望你能儘快在項目中使用它們!