
目錄
1. sizeof和strlen的對⽐
2. 數組和指針筆試題解析
3. 指針運算筆試題解析
1. sizeof和strlen的對⽐
1.1 sizeof(單目操作符)
注意:sizeof不是函數,它只是操作符 ,以字節為單位
在學習操作符的時候,我們學習了 sizeof , sizeof 計算變量所佔內存空間⼤⼩的,單位是字 節,如果操作數是類型的話,計算的是使⽤類型創建的變量所佔內存空間的⼤⼩
sizeof 只關注佔⽤內存空間的⼤⼩,不在乎內存中存放什麼數據
int main()
{
int a = 0;
printf("%zd\n", sizeof(a));
printf("%zd\n", sizeof a); //證明了sizeof不是函數,因為函數後面必須加括號
printf("%zd\n", sizeof(int));
return 0;
}輸出結果:
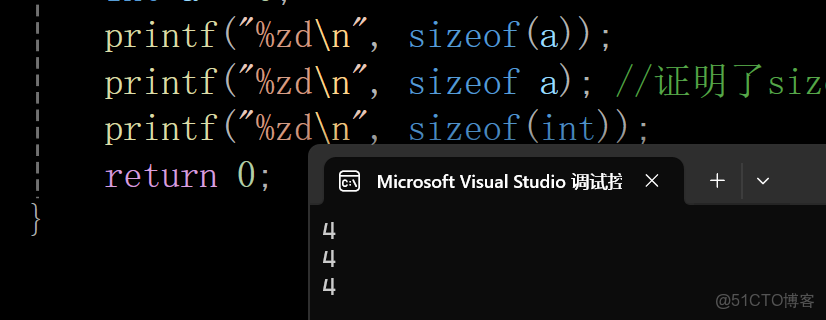
注意:證明了sizeof不是函數,因為函數後面必須加括號
printf("%zd\n", sizeof a)1.2 strlen
注意:它是一個庫函數,用來求字符串的長度,它還要一個頭文件<string.h>
strlen 是C語⾔庫函數,功能是求字符串⻓度。函數原型如下:
size_t strlen (const char* str);統計的是從 strlen 函數的參數 str 中這個地址開始向後, \0 之前字符串中字符的個數。
strlen 函數會⼀直向後找 \0 字符,直到找到為⽌,所以可能存在越界查找。
int main()
{
size_t len1 = strlen("abcdef\n");
size_t len2 = strlen("abc\0def\n"); //strlen計算的是\0之前的數字,所以這裏是3
printf("%zd\n", len1); //輸出7
printf("%zd\n", len2); //輸出3
return 0;
}輸出結果:
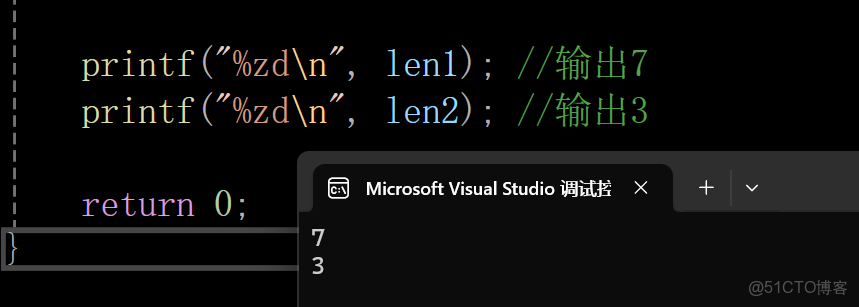
注意:strlen計算的是\0之前的數字,所以這裏是3
size_t len2 = strlen("abc\0def\n"); //strlen計算的是\0之前的數字,所以這裏是3
printf("%zd\n", len2); //輸出31.3 sizeof 和strlen的對⽐
|
sizeof
|
strlen
|
|
1. sizeof是操作符 2. sizeof計算操作數所佔內存的 ⼤⼩,單位是字節 3. 不關注內存中存放什麼數據 |
1. strlen是庫函數,使⽤需要包含頭⽂件 string.h 2. srtlen是求字符串⻓度的,統計的是 \0 之前字符的個數 3. 關注內存中是否有 \0 ,如果沒有 \0 ,就會持續往後找,可能 會越界 |
strlen函數有多種寫法
int main()
{
const char* str = "abcdef";
printf("%zd\n", strlen(str)); //輸出6
return 0;
}輸出結果:

還有一個寫法
int main()
{
char str[] = "abcdef";
printf("%zd\n", strlen(str)); //輸出6
return 0;
}輸出結果:

2. 數組和指針筆試題解析
2.1 ⼀維數組
數組名的理解
數組名是數組首元素(第一個元素)的地址
但是有兩個例外
1.sizeof(數組名) -----數組名錶示的是整個數組,計算的是整個數組的大小,單位是字節
2.&數組名 ----數組名錶示的是整個數組,取出的是整個數的地址
除了上面兩個例外,其他的數組名都是數組首元素(第一個元素)的地址
代碼如下:
int main()
{
int a[] = { 1,2,3,4 };//4個元素
printf("%zd\n", sizeof(a)); //16 ----sizeof(數組名)的情況
printf("%zd\n", sizeof(a + 0)); //x64壞境是8,x86的壞境是4 ---a是首元素的地址,它的類型是int* ,所以a+0還是首元素的地址,是地址的話,它的大小就是4或者8,根據x64和x86壞境決定的
printf("%zd\n", sizeof(a+1));//8或者4 ---a是數組首元素的地址,它的類型是int* ,所以a+1會跳過1個整型,即a+1就是第二個元素的地址
printf("%zd\n", sizeof(a[1]));//4 ---a[1] 就是第二個元素,int是4個字節,所以這裏是4
printf("%zd\n", sizeof(*a)); //4 ---a是首元素的地址,*a就是首元素,首元素是int,所以是4個字節,這裏的 *a == a[0]
printf("%zd\n", sizeof(*&a));//16 ---這裏的*和&互相抵消了,所以 sizeof(*&a) == sizeof(a)
printf("%zd\n", sizeof(&a));//4或者8 ---&a是數組的地址,數組的地址也是地址,所以地址大小就是4或者8
printf("%zd\n", sizeof(&a+1));//4或者8 ---&a+1它是跳過了整個數組後的那個位置的地址,是地址,大小就是4或者8
printf("%zd\n", sizeof(&a[0]));//4或者8 ---&a[0]是首元素的地址,是地址大小就是4或者8
printf("%zd\n", sizeof(&a[0]+1));//4或者8 ---&a[0]+1是數組第二個元素的地址,是地址,大小就是4或者8
return 0;
}輸出結果:
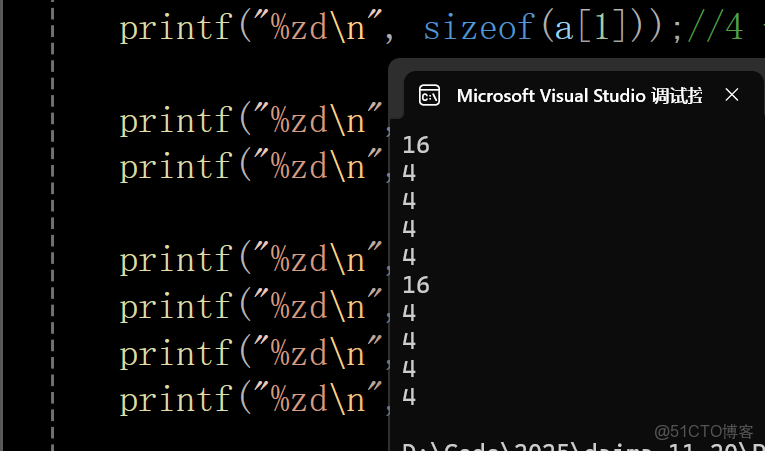
現在我們來一一解析一下上面的代碼:
輸出16 ----sizeof(數組名)的情況,int型為4個字節,總共有4個元素,
printf("%zd\n", sizeof(a));x64壞境是8,x86的壞境是4 ---a是首元素的地址,它的類型是int* ,所以a+0還是首元素的地址,是地址的話,它的大小就是4或者8,根據x64和x86壞境決定的
printf("%zd\n", sizeof(a + 0));輸出8或者4 ---a是數組首元素的地址,它的類型是int* ,所以a+1會跳過1個整型,即a+1就是第二個元素的地址
printf("%zd\n", sizeof(a+1));輸出4 ---a[1] 就是第二個元素,int是4個字節,所以這裏是4
printf("%zd\n", sizeof(a[1]));輸出4 ---a是首元素的地址,*a就是首元素,首元素是int,所以是4個字節,這裏的 *a == a[0]
printf("%zd\n", sizeof(*a));16 ---這裏的*和&互相抵消了,所以 sizeof(*&a) == sizeof(a)
printf("%zd\n", sizeof(*&a));4或者8 ---&a是數組的地址,數組的地址也是地址,所以地址大小就是4或者8
4或者8 ---&a+1它是跳過了整個數組後的那個位置的地址,是地址,大小就是4或者8
4或者8 ---&a[0]是首元素的地址,是地址大小就是4或者8
4或者8 ---&a[0]+1是數組第二個元素的地址,是地址,大小就是4或者8
printf("%zd\n", sizeof(&a))
printf("%zd\n", sizeof(&a+1));
printf("%zd\n", sizeof(&a[0]));
printf("%zd\n", sizeof(&a[0]+1));2.2 字符數組
代碼如下:
int main()
{
char arr[] = { 'a','b','c','d','e','f' };//後面沒有省略的\0
printf("%zd\n", sizeof(arr));//6 ---數組名單獨放在了sizeof內部了,計算的是數組的大小,單位是字節
printf("%zd\n", sizeof(arr+0));//4或者8 ---arr是數組名,表示的是首元素的地址,arr+0還是首元素的地址,地址的大小就是4或者8
printf("%zd\n", sizeof(*arr));//1 ---arr是首元素的地址,*arr==arr[0]就是首元素a,char字符是1個字節
printf("%zd\n", sizeof(arr[1]));//1 ---arr[1]就是第二個元素b,字符大小是1個字節
printf("%zd\n", sizeof(&arr));//4或者8 ---&arr是數組地址,數組的地址也是地址,所以大小是4或者8
printf("%zd\n", sizeof(&arr+1));//4或者8 ---&arr+1,是跳過了整個數組後的那個位置的地址,是地址,大小就是4或者8
printf("%zd\n", sizeof(&arr[0]+1));//4或者8 ---&arr[0]+1是第二個元素的地址,是地址就是4或者8
return 0;
}輸出結果:
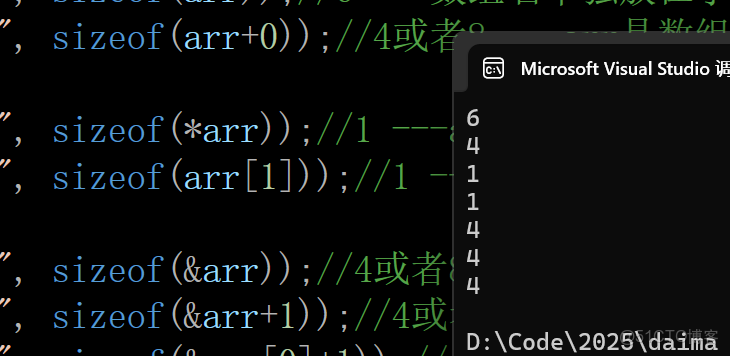
解析:
6 ---數組名單獨放在了sizeof內部了,計算的是數組的大小,單位是字節
4或者8 ---arr是數組名,表示的是首元素的地址,arr+0還是首元素的地址,地址的大小就是4或者8
printf("%zd\n", sizeof(arr));
printf("%zd\n", sizeof(arr+0));1 ---arr是首元素的地址,*arr==arr[0]就是首元素a,char字符是1個字節
1 ---arr[1]就是第二個元素b,字符大小是1個字節
printf("%zd\n", sizeof(*arr));
printf("%zd\n", sizeof(arr[1]));4或者8 ---&arr是數組地址,數組的地址也是地址,所以大小是4或者8
4或者8 ---&arr+1,是跳過了整個數組後的那個位置的地址,是地址,大小就是4或者8
4或者8 ---&arr[0]+1是第二個元素的地址,是地址就是4或者8
printf("%zd\n", sizeof(&arr));
printf("%zd\n", sizeof(&arr+1));
printf("%zd\n", sizeof(&arr[0]+1));把數組的初始化改一下
int main()
{
char arr[] = "abcdef"; //7個元素,最後省略的\0也是一個元素
printf("%zd\n", sizeof(arr));//7 ---arr是數組名,單獨放在了sizeof內部,計算的是數組的總大小
printf("%zd\n", sizeof(arr + 0));//4或者8 ---arr表示的是首元素的地址,arr+0還是首元素的地址,地址的大小就是4或者8
printf("%zd\n", sizeof(*arr));//1 ---*arr就是首元素a ,char類型字節為1
printf("%zd\n", sizeof(arr[1]));//1 ---arr[1]就是第二個元素b,字節是1
printf("%zd\n", sizeof(&arr));//4或者8 ---&arr是數組地址
printf("%zd\n", sizeof(&arr + 1));//4或者8 --- +1跳過整個地址,結果還是地址
printf("%zd\n", sizeof(&arr[0] + 1));//4或者8 --- +1就是第二個元素的地址,結果還是地址
return 0;
}輸出結果:
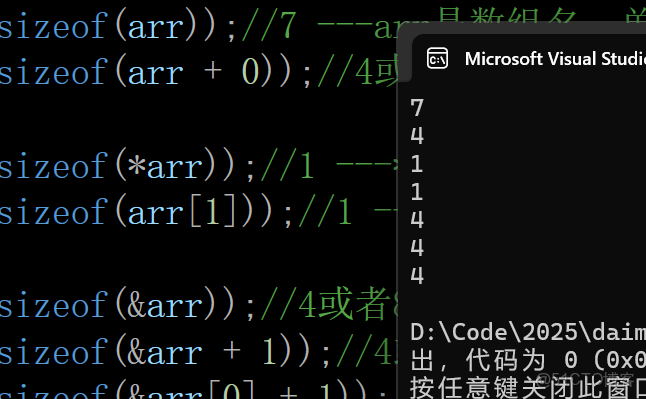
解析:
7 ---arr是數組名,單獨放在了sizeof內部,計算的是數組的總大小
4或者8 ---arr表示的是首元素的地址,arr+0還是首元素的地址,地址的大小就是4或者8
printf("%zd\n", sizeof(arr));
printf("%zd\n", sizeof(arr + 0));1 ---*arr就是首元素a ,char類型字節為1
1 ---arr[1]就是第二個元素b,字節是1
printf("%zd\n", sizeof(*arr));
printf("%zd\n", sizeof(arr[1]));4或者8 ---&arr是數組地址
4或者8 --- +1跳過整個地址,結果還是地址
4或者8 --- +1就是第二個元素的地址,結果還是地址
printf("%zd\n", sizeof(&arr));
printf("%zd\n", sizeof(&arr + 1));
printf("%zd\n", sizeof(&arr[0] + 1));初始化的創建換成指針
代碼如下:
int main()
{
const char* p = "abcdef";
printf("%d\n", sizeof(p));//4或者8 ---p是指針變量,計算的是指針變量的大小
printf("%d\n", sizeof(p+1));//4或者8 ---p+1就是b的地址
printf("%d\n", sizeof(*p));//1 ---p的類型是const char* ,而*p就是char類型
printf("%d\n", sizeof(p[0]));//1 ---p[0] == *(p+0) == *p == 'a'
printf("%d\n", sizeof(&p));//4或者8 ---取出的是p的地址
printf("%d\n", sizeof(&p+1));//4或者8 ---它跳過的是p指針變量後的地址
printf("%d\n", sizeof(&p[0]+1));//4或者8 ---&p[0] 取出的是首元素的地址,+1就是第二個元素的地址
return 0;
}輸出結果:
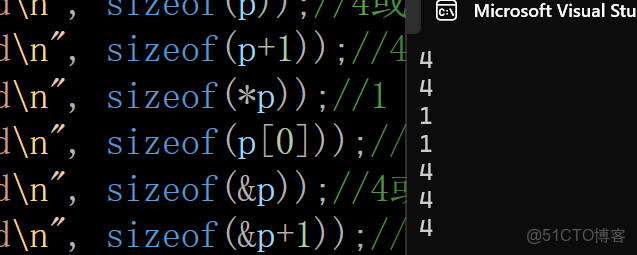
計算換成strlen
int main()
{
char arr[] = { 'a','b','c','d','e','f' };
printf("%d\n", strlen(arr));//結果是隨機的---arr是首元素的地址,但是數組裏面沒有\0,所以strlen在計算的時候會導致越界訪問
printf("%d\n", strlen(arr+0));//同上
//printf("%d\n", strlen(*arr));//arr首元素的地址,*arr是數組的首元素,即'a',它的ASCII的值是97,相當於把97傳給了strlen,所以strlen得到的就是野指針,代碼有問題
//printf("%d\n", strlen(arr[1]));//arr[1]==‘b’,代碼錯誤,原因同上
printf("%d\n", strlen(&arr));//隨機值 ---&arr是數組的地址,起始位置是數組的第一個元素的位置,假如是隨機值是x
printf("%d\n", strlen(&arr+1));//隨機值 ---也是找不到\0 ,則值x-6
printf("%d\n", strlen(&arr[0]+1));//隨機值 ---它是從第二個元素開始往後計算的 , 則值x-1
return 0;
}輸出結果:

把數組的初始化改一下
int main()
{
char arr[] = "abcdef"; //後面有個省略的\0
printf("%d\n", strlen(arr));//6
printf("%d\n", strlen(arr + 0));//6 ---arr+0是首元素的地址,往後一直計算到\0之前的數為6個字符
//printf("%d\n", strlen(*arr));//錯誤代碼 ---strlen得到的是'a',為97,野指針
//printf("%d\n", strlen(arr[1]));//錯誤代碼 ---得到的是'b'
printf("%d\n", strlen(&arr));//6 ---&arr是數組的地址,也是從數組第一個元素往後找\0之前的數,為6
printf("%d\n", strlen(&arr + 1));//隨機值
printf("%d\n", strlen(&arr[0] + 1));//5 ---&arr[0] + 1相當於從'b'開始往後面找\0之前的數,為5
return 0;
}輸出結果:
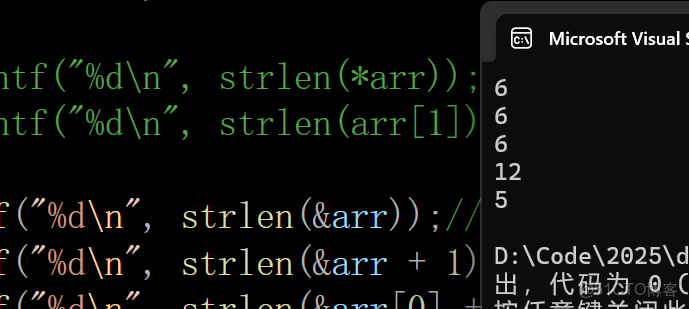
初始化的創建換成指針
int main()
{
char* p = "abcdef";
printf("%d\n", strlen(p));//6
printf("%d\n", strlen(p+1));//5
//printf("%d\n", strlen(*p));//錯誤代碼 ---*就是'a',是97,野指針
//printf("%d\n", strlen(p[0]));//錯誤代碼 ---p[0] == *(p+0) == *p 即'a',97野指針
printf("%d\n", strlen(&p));//隨機值 ---&p是指針變量p的地址,和字符串沒什麼關係,因為它是從p這個指針變量的起始位置開始往後計算的,又因為p變量存放的地址是什麼?我們不知道,所以是隨機值
printf("%d\n", strlen(&p+1));//隨機值 ---同上
printf("%d\n", strlen(&p[0]+1 ));//5 ---&p[0] 取出的是首元素的地址,+1就是第二個元素的地址
return 0;
}輸出結果:
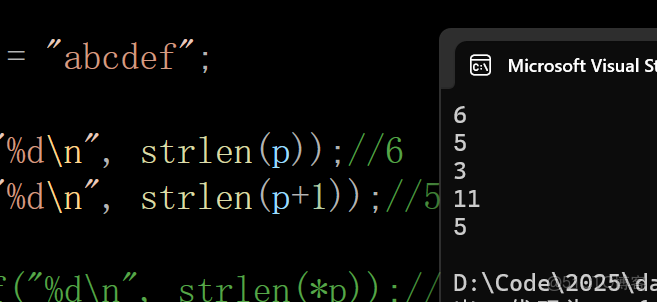
2.3二維數組
代碼如下:
int main()
{
int a[3][4] = { 0 };
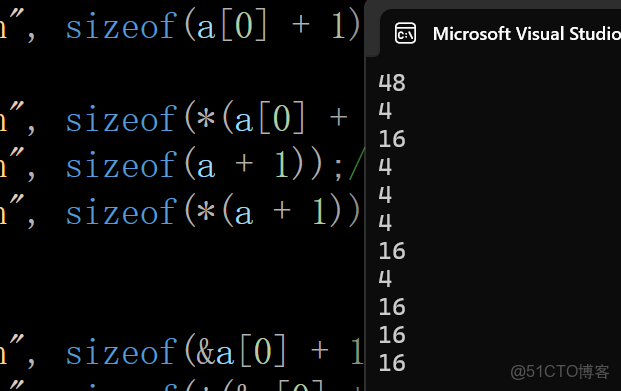
printf("%d\n", sizeof(a));//48 ---a是數組名,並且單獨放在sizeof內部,計算的是數組的大小,單位是字節
printf("%d\n", sizeof(a[0][0]));//4 ---a[0][0]就是第一行第一個元素,為int型 即4個字節
printf("%d\n", sizeof(a[0]));//16 ---a[0]是第一行的數組名,單獨放在sizeof內部,計算的是數組的總大小
printf("%d\n", sizeof(a[0] + 1));//4或者8 ---雖然a[0]是第一行的數組名,但是卻沒有單獨放在sizeof內部,所以這裏的數組名a[0]就是數組首元素的地址,即&a[0][0], +1後就是a[0][1]的地址
printf("%d\n", sizeof(*(a[0] + 1)));//4 ---*(a[0] + 1)表示第一行的第二個元素
printf("%d\n", sizeof(a + 1));//4或者8 ---a是數組名,沒有單獨放在sizeof裏面,a表示二維數組首元素的地址,也就是第一行的地址,a+1會跳過一行,即第二行的地址
printf("%d\n", sizeof(*(a + 1)));//16 ---a + 1是第二行的地址,*(a + 1)就是第二行,計算的是第二行的大小,即16
//還有一個思路:*(a + 1) == a[1] ,它就是第二行的數組名,也就是把a[1]單獨放在了sizeof裏面,然後單獨計算第二行的大小
printf("%d\n", sizeof(&a[0] + 1));//4或者8 ---a[0]是第一行的數組名,&a[0]取出的是第一行數組的地址,+1就是第二行的地址
printf("%d\n", sizeof(*(&a[0] + 1)));//16 ---*(&a[0] + 1)就是第二行數組
printf("%d\n", sizeof(*a));//16 ---a是數組名,沒有單獨放在sizeof內部,所以a表示二維數組首元素的地址,*a就是第二行數組,計算第二行數組的大小,即16
//還有一個思路:*a == *(a+1)== a[0]
printf("%d\n", sizeof(a[3]));//16 ---雖然我們沒有四行數組,但是sizeof並不會去訪問第四行的值,a[3]單獨放在sizeof內部,計算的是第四行的數組的大小,為16
return 0;
}輸出結果:
3.指針運算筆試題
3.1 題目1
代碼如下:
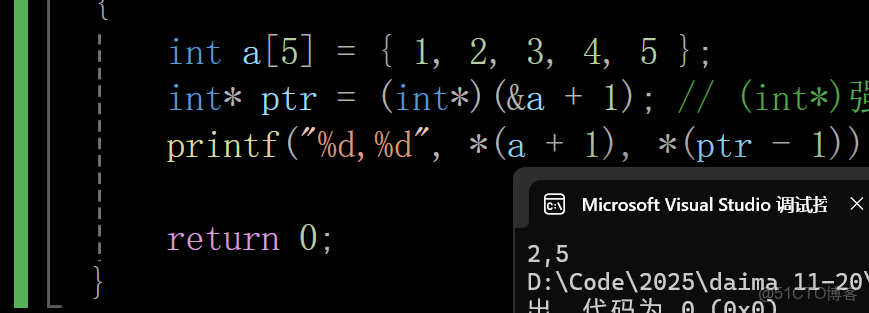
int main()
{
int a[5] = { 1, 2, 3, 4, 5 };
int* ptr = (int*)(&a + 1); // (int*)強制轉換為int* ,因為後面取的是地址
printf("%d,%d", *(a + 1), *(ptr - 1)); // 2 5
return 0;
}輸出結果:
3.2 題目2
在X86(32bit)環境下
假設結構體的⼤⼩是20個字節
程序輸出的結果是啥?
struct Test
{
int Num;
char* pcName;
short sDate;
char cha[2];
short sBa[4];
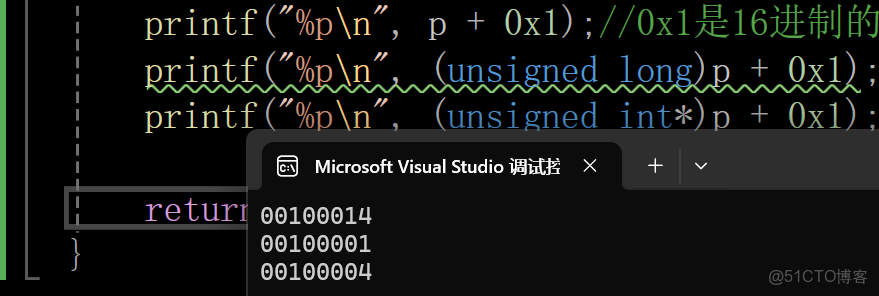
}*p = (struct Test*)0x100000; // 強制轉換為(struct Test*) p是指針變量,這裏我們存放的是地址0x100000(隨便取的)
int main()
{
printf("%p\n", p + 0x1);//0x1是16進制的1
printf("%p\n", (unsigned long)p + 0x1);//unsigned long是無符號的整型 ,這裏按整型+1來計算就行了
printf("%p\n", (unsigned int*)p + 0x1);//unsigned int*無符號的整型指針,這裏的+1相當於+4
return 0;
}輸出結果:
3.3 題目3
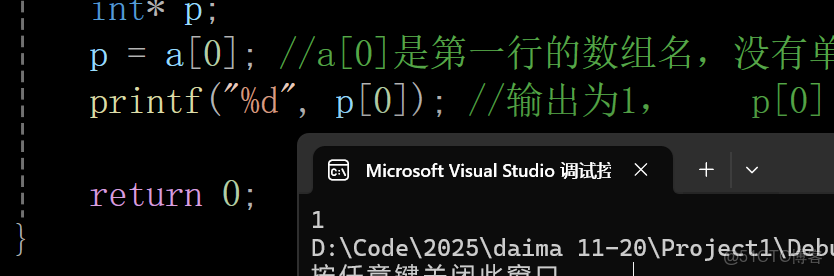
int main()
{
int a[3][2] = { (0, 1), (2, 3), (4, 5) }; //注意這裏是小括號,(0, 1)是一個逗號表達式,按照從左往右來計算
//正真的數組 = {1 ,3 ,5}
int* p;
p = a[0]; //a[0]是第一行的數組名,沒有單獨放在sizeof內部,所以表示的是首元素的地址,即&a[0][0]的地址,
printf("%d", p[0]); //輸出為1, p[0] == *(p+0) == *p
return 0;
}輸出結果:
3.4 題目4
假設環境是x86環境,程序輸出的結果是啥?
int main()
{
int a[5][5];
int(*p)[4]; //p是一個數組指針,p指向的數組是4個整型元素的
p = a;
printf("%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
return 0;
}3.5 題目5
int main()
{
int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int* ptr1 = (int*)(&aa + 1);
int* ptr2 = (int*)(*(aa + 1));
printf("%d,%d", *(ptr1 - 1), *(ptr2 - 1));
return 0;
}3.6 題目6
int main()
{
char* a[] = { "work","at","alibaba" };
char** pa = a;
pa++;
printf("%s\n", *pa);
return 0;
}3.7 題目7
int main()
{
char* c[] = { "ENTER","NEW","POINT","FIRST" };
char** cp[] = { c + 3,c + 2,c + 1,c };
char*** cpp = cp;
printf("%s\n", **++cpp);
printf("%s\n", *-- * ++cpp + 3);
printf("%s\n", *cpp[-2] + 3);
printf("%s\n", cpp[-1][-1] + 1);
return 0;
}