
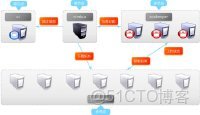
storm集羣在生產環境部署之後,通常會是如下的結構。從圖中可以看出zookeeper和supervisor都是多節點,任意1個zookeeper節點宕機或supervisor節點宕機均不會對系統整體運行造成影響,但nimbus和ui都是單節點。ui的單節點對系統的穩定運行沒有影響,僅提供storm-ui頁面展示統計信息。但nimbus承載了集羣的許多工作,如果nimbus單節點宕機,將會使系統整體的穩定運行造成極大風險。因此解決nimbus的單點問題,將會更加完善storm集羣的穩定性。
一、storm nimbus 單節點問題概述
1、storm集羣在生產環境部署之後,通常會是如下的結構:
從圖中可以看出zookeeper和supervisor都是多節點,任意1個zookeeper節點宕機或supervisor節點宕機均不會對系統整體運行造成影響,但nimbus和ui都是單節點。ui的單節點對系統的穩定運行沒有影響,僅提供storm-ui頁面展示統計信息。但nimbus承載了集羣的許多工作,如果nimbus單節點宕機,將會使系統整體的穩定運行造成極大風險。因此解決nimbus的單點問題,將會更加完善storm集羣的穩定性。
2、storm nimbus單節點的風險
(1)功能上,nimbus進程退出後,如果再同時發生worker進程宕機,宕機的worker將無法重啓,集羣將會有部分消息始終無法得到處理。
(2)監控上,nimbus進程不可用時,storm ui將無法訪問。
(3)機率上,機房由於演練或故障不可用時即會出現nimbus與worker進程同時故障的情形,面對風險的機率較大。
二、storm與解決nimbus單點相關的概念
1、【nimbus進程】storm集羣工作的全局指揮官。
(1)通過thrift接口,監聽並接收client對topology的submit,將topology代碼保存到本地目錄/nimbus/stormdist/下
(2)為client提交的topology計算任務分配,根據集羣worker資源情況,計算出topology的spout和bolt的task應該如何在worker間分配,任務分配結果寫入zookeeper
(3)通過thrift接口,監聽supervisor的下載topology代碼的請求,並提供下載
(4)通過thrift接口,監聽ui對統計信息的讀取,從zookeeper上讀取統計信息,返回給ui
(5)若進程退出後,立即在本機重啓,則不影響集羣運行。
2、【supervisor進程】storm集羣的資源管理者,按需啓動worker進程。
(1)定時從zookeeper檢查是否有代碼未下載到本地的新topology,定時刪除舊topology代碼
(2)根據nimbus的任務分配結果,在本機按需啓動1個或多個worker進程,監控守護所有的worker進程。
(3)若進程退出,立即在本機重啓,則不影響集羣運行。
3、【worker進程】storm集羣的任務構造者,構造spout或bolt的task實例,啓動executor線程。
(1)根據zookeeper上分配的task,在本進程中啓動1個或多個executor線程,將構造好的task實例交給executor去運行(死循環調用spout.nextTuple()或bolt.execute()方法)。
(2)向zookeeper寫入心跳
(3)維持傳輸隊列,發送tuple到其他的worker
(4)若進程退出,立即在本機重啓,則不影響集羣運行。
4、【executor線程】storm集羣的任務執行者,循環執行task代碼。
(1)執行1個或多個task(每個task對應spout或bolt的1個並行度),將輸出加入到worker裏的tuple隊列
(2)執行storm內部線程acker,負責發送消息處理狀態給對應spoult所在的worker
【注1】Worker、Executor、Task關係可以參考
三、nimbus目前無法做到多節點的原因
1、nimbus節點的ip地址在配置文件中storm.yaml,更換機器後ip地址變化,需要更新集羣所有節點的配置文件後重啓集羣。
2、客户端submitTopology時也需要取得nimbus ip上傳代碼。nimbus更換機器後,client也需要修改配置文件。
3、nimbus機器的本地硬盤存放了topology的代碼,更換機器後代碼全部丟失,新啓動的supervisor將無法下載正在運行的topology代碼。
4、storm ui是從nimbus讀取集羣統計信息的,nimbus更換機器後ui也需要修改配置文件後重啓。
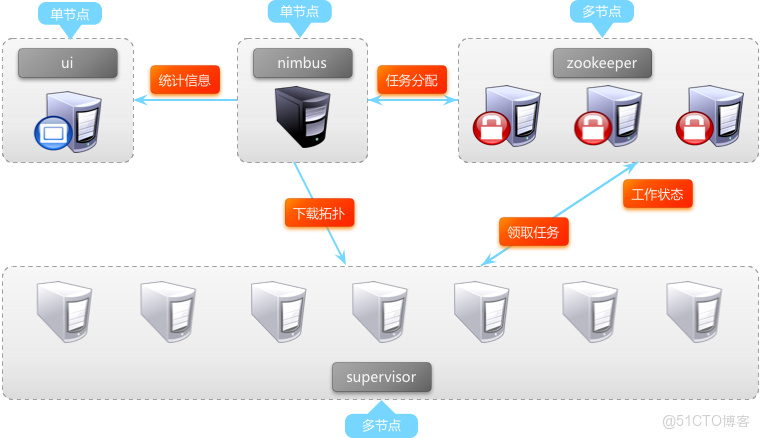
5、同時啓動多個nimbus節點,會面臨多個nimbus併發計算topology的任務分配,併發寫入zookeeper,併發清理zookeeper等諸多不可預料的問題。即使存在多個nimbus節點,storm-ui、supervisor、client等也只會使用配置文件指定的ip的節點。
【注】storm在設計之初就做到了節點進程間通過zookeeper鬆散耦合,進程相對獨立,單個進程的退出不會影響集羣運行,因此nimbus做到多節點並不存在十分巨大的困難。但作者@Nathanmarz認為nimbus單節點問題並不是storm最緊急和嚴重的問題,因此在0.8.2版本之前nimbus ip地址依舊是在配置文件。
四、解決nimbus單點問題的關鍵
1、supervisor、client、ui對nimbus節點ip動態獲取,而非由配置文件指定。
2、在nimbus更換機器後,supervisor仍然可隨時下載到topology的代碼。
五、業界對nimbus單點問題的努力
1、storm作者Nathanmarz對高可用的nimbus提出了這樣的規劃:
- nimbus目前的本地存儲topology代碼方式需要更加靈活,比如既支持本地存儲,也支持分佈式存儲
- nimbus節點之間需要實現基於zookeeper的自選舉機制
- 客户端能夠通過zookeeper找到nimbus leader的ip地址來submit topology
2、來自俄羅斯的@Frostmanfork了storm-0.8.2,並在此版本基礎上着手實現Nathanmarz對nimbus-ha的規劃。Frostman抽象出了INimbusStorage.java存儲接口:
1 public interface INimbusStorage {
2 void init(Map conf);
3 InputStream open(String path);
4 OutputStream create(String path);
5 List<String> list(String path);
6 void delete(String path);
7 void mkdirs(String path);
8 boolean isSupportDistributed();
9 }【注1】INimbusStorage為topology代碼的分佈式存儲與本地存儲預留了接口,Forstman同時提供了本地存儲實現類storage.clj。
【注2】Nathanmarz因此在0.8.2版本的基礎上,新開了storm-0.8.2-ha分支,專門用來解決nimbus單點問題,並將Frostman已完成的nimbus-storage代碼合併到該分支。
3、Frostman在nimbus-storage基礎上繼續增加了nimbus多節點選舉機制,(目前尚未被Nathanmarz合併入storm-ha分支)。
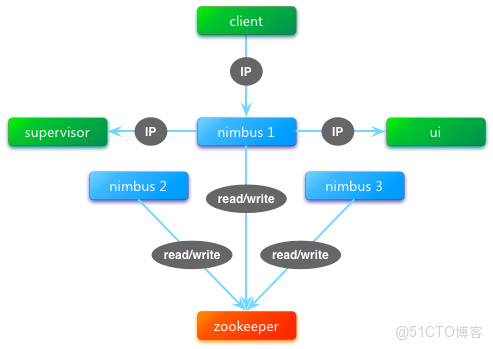
nimbus多節點選舉機制真正實現了nimbus的多節點啓動。nimbus進程啓動後即通過搶佔zookeeper的InterProcessMutex鎖成為leader,非leader的nimbus進程一直處於block狀態,不進行後續工作,當leader宕機時,搶佔到鎖的下1個節點成為新leader。由此解決了多nimbus進程會併發讀寫zookeeper的問題。
Frostman同時將所有配置文件中的nimbus ip地址轉移到了zookeeper中存儲leader ip地址,並在storm-ui中增加了nimbus多節點leader狀態的展示。
但由於本地存儲是不支持分佈式的,即無法同時啓動多個nimbus節點(非leader節點無topology代碼),因此其選舉功能也僅限於演示,無法實際運用。
4、來自yahoo的@anfeng (twitter @Andy Feng)試圖將nimbus及ui使用的端口號由配置文件指定改為自動查找可用端口,但作者建議其在Frostman的nimbus-ha基礎上增加此feature,這樣storm-ha將更加趨於智能化。
六、nimbus單點問題的解決思路
1、Frostman的工作已為徹底解決nimbus單點問題奠定了重要基礎:
- nimbus ip地址動態獲取
- topology代碼存儲方案可定製
- nimbus多節點選舉,宕機自動切換
- nimbus leader狀態ui展示
在Frostman工作的基礎上繼續深入,將極大減少工作量。
2、Frostman並未解決topology代碼如何在多個nimbus節點或集羣所有節點間共享的問題。Nathamarz的理想規劃是:實現storm集羣中所有nimbus、supervisor機器之間通過P2P協議共享topology代碼,但目前限於BitTorrent未完成的工作,目前暫停了nimbus-ha分支的開發。
3、最終選定的解決方案:實現定製的nimbus-storage插件NimbusCloudStorage,使得所有nimbus節點在啓動後均從leader 輪詢下載本地不存在的topology代碼。依次滿足supervisor在nimbus節點切換後下載代碼的需求。
七、NimbusCloudStorage的實現
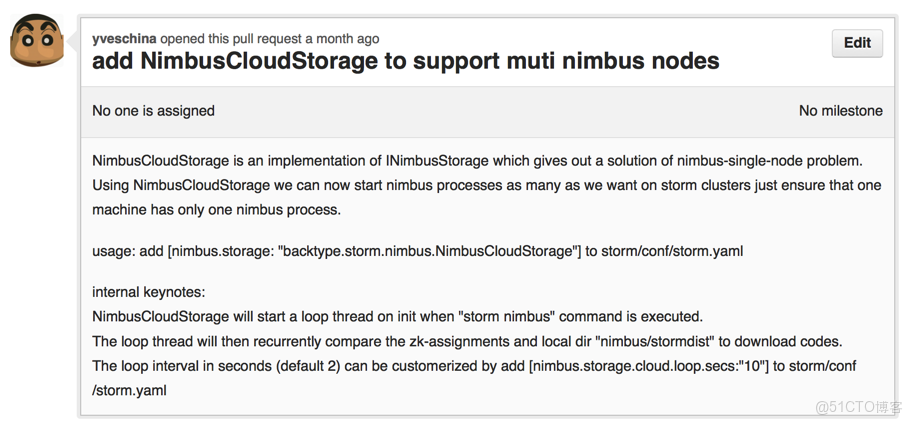
1、 工作機制
在nimbus進程啓動後,NimbusCloudStorage會啓動1個新的線程,定時輪詢zookeeper上正在運行的topology id,並依此比對本地存儲的代碼中是否有未下載的,一旦發現代碼未下載,則從zookeeper獲取nimbus leader節點的ip,並向其請求下載topology的代碼。
2、 使用方法
storm/conf/storm/yaml配置文件中增加【nimbus.storage: "backtype.storm.nimbus.NimbusCloudStorage"】即可
【注】Frostman已經2個月沒看github了,⊙﹏⊙b汗,導致NimbusCloudStorage的pull request一直處於open狀態。目前新的工作一直在fork出來的storm-ha分支commit,本地編譯release版本storm-0.8.2-tb。
總結:
基於開源社區對storm-nimbus-ha的推進,通過實現新的storage插件既解決了nimbus-ha方案中重要的topology代碼共享問題,又避免了對storm源碼的過度侵入,實現了1個class解決nimbus-ha問題,為實現nimbus-ha提供了一種思路。