
Transformer架構概述
Transformer架構主要的功能是高效地完成某些自然語言分析任務,比如英語到德語和英語到法語的翻譯任務,這裏要注意的是,大語言模型(LLM)不等於Transformer,我個人認為Transformer可以算是一種從預訓練數據中更好提取信息的方式,因此當我們在瞭解Transformer架構時,其中一個重要關注點是觀察文本的信息在其中遭受了何種處理。接下來我們將從在《Attention Is All You Need》這篇論文給出的示意圖出發,説明每一個部分所起到的作用。
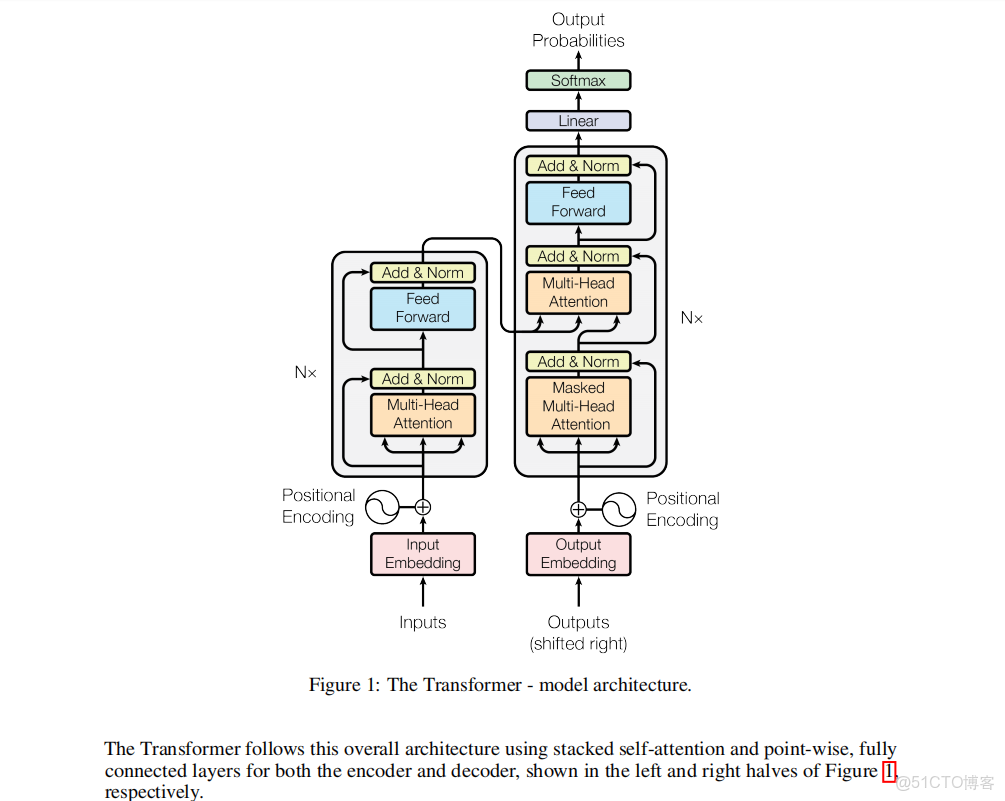
如圖所示,先從最下面的InputEmbedding和OutEmbedding開始。什麼是Embedding呢?這個單詞在這裏是一個專門術語,是詞嵌入的意思。詞嵌入(英語:Word embedding)是自然語言處理(NLP)中語言模型與表徵學習技術的統稱。概念上而言,它是指把一個維數為所有詞的數量的高維空間嵌入到一個維數低得多的連續向量空間中,每個單詞或詞組被映射為實數域上的向量。簡單來説,就是用向量描述自然語言,這裏的自然語言是以被tokenization化的詞為基本單位的,不同模型的分詞方法不同,這裏我們只需要把這些詞理解為某種基本單位就好,而詞嵌入就是給這些詞進行編碼,這些編碼包含了詞之間關係的信息。繼續往上,我們可以看到下一個環節Positional Encoding,翻譯過來就是位置編碼,位置編碼的作用是給每個詞一個確定的順序,因為在自然語言當中,詞出現的順序會影響句子的含義,這裏位置編碼和詞嵌入後所得向量的維度是相同的,因此兩者可以“相加”,完成這部分之後,Encoder所接受的就是詞向量和位置向量。
論文對位置向量的説明,我直接放在這裏
3.5 Positional Encoding
Since our model contains no recurrence and no convolution, in order for the model to make use of the order of the sequence, we must inject some information about the relative or absolute position of the tokens in the sequence. To this end, we add "positional encodings" to the input embeddings at the bottoms of the encoder and decoder stacks. The positional encodings have the same dimension \(d_{model }\) as the embeddings, so that the two can be summed. There are many choices of positional encodings, learned and fixed [9].
In this work, we use sine and cosine functions of different frequencies:
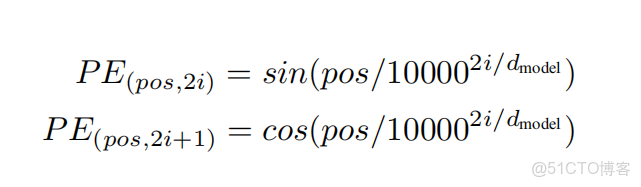
這裏採用了正餘弦編碼的方式確定位置編碼,有人認為這種比編碼方式更有利於模型學習較長長度上下文的信息,而且在進行數學運算時不會丟失過多信息,這裏我們大概瞭解就好。
注意這裏開始分為兩半部分,根據示意圖下面的註釋,左半部分為Encoder ,即解碼器,右半部分為Decoder,即編碼器,左邊的解碼器中包含multi-head -attention ,多頭注意力,Add&Norm,殘差連接和層歸一化,Feed-forward network.前饋神經網絡
先來處理多頭注意力的部分。如圖所示。
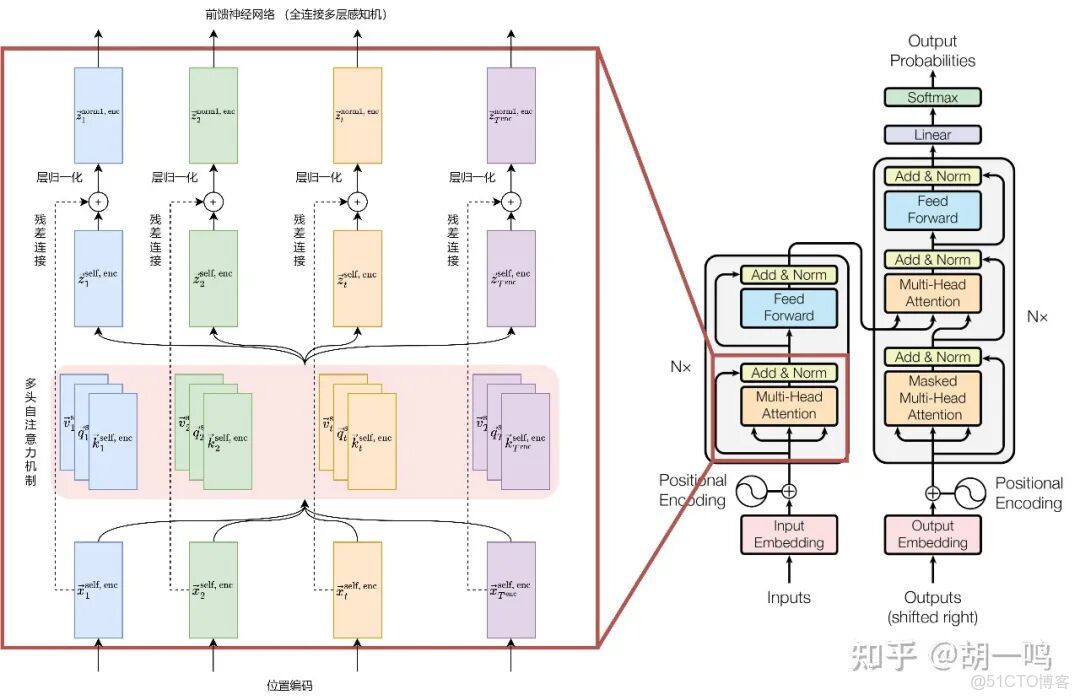
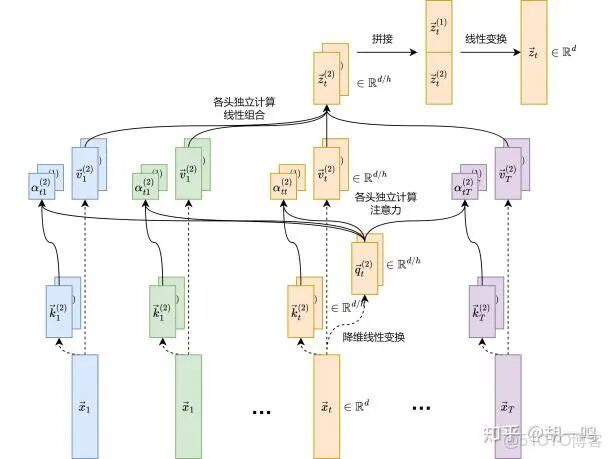
首先要解釋什麼是“多頭”(multi-head),所謂的“頭”,就是詞的向量維度所被區分的部分,一個部分就是一個“頭”,每個“頭”包括三部分向量,即K,Q,V。Query(查詢),代表當前關注的位置(如當前處理的單詞)。Key(鍵):代表序列中所有位置的標識,用於與 Query 匹配相似性。Value(值):存儲實際的信息,通過注意力權重加權後生成最終輸出。這三個矩陣都是通過訓練得到的,至於為什麼是這三個矩陣,以及為什麼要相乘,這裏我直接貼一個知乎上的回答。如何理解attention中的Q,K,V? - 知乎https://www.zhihu.com/question/298810062/answer/86505956036,大概意思是給整個訓練提供更多的信息和靈活度,讓權重隨着訓練過程的反向傳播而改變。在獲得QKV後,接下來再來觀察論文給出的注意力機制所表示的矩陣運算過程。其中softmax函數和式子中的分母的作用主要是希望詞的維度比較大的時候能夠維持較好的數值穩定性。最後將所有頭的計算結果拼接在一起,構成一個完整的輸出,為什麼這裏要分開之後重新拼起來呢?作者的原話是“Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single attention head, averaging inhibits this.”大概意思是隻有這樣才能更好捕捉文本中的信息。
多頭注意力的計算過程如下,來源見水印。
下一個部分,Add&Norm,殘差連接和層歸一化,這部分的內容做一個粗糙理解就行,殘差連接的作用是擴大神經網絡的規模,而層歸一化的作用則是增加整個神經網絡的穩定性。
再下一個部分,Feed-forward network.前饋神經網絡。這裏要注意兩點,首先這個神經網絡是單向的,信息只能從輸入層流向隱藏層,再到輸出層,不會反向傳遞。其次,這裏起到的實際上是某種篩選信息的作用,至於如何篩選和為什麼篩選,我個人水平有限一下子也説不清楚,讀者有興趣可自己去查文獻。編碼器的部分就到此為止,最終的輸出結果,包含了每個位置在句子中的語義信息
接下來是解碼器的部分,也就是示意圖右邊一整列的部分,需要注意的是,這裏是一個自迴歸模型,也就它將自己的輸入作為輸出,簡單來説就是在輸出一個新的詞的時候,所依據的是上一個詞,整個輸出過程是一個接一個詞地輸出,而不是所有詞一同輸出,這裏説的是推理過程中詞的輸出方式而不是訓練方式,在訓練的過程中,所有訓練數據的位置都會進行計算。為了實現自迴歸模型的目標,需要引入掩碼自注意力機制,掩碼的作用是讓模型在生成新一個詞時,僅僅關注前面一個詞,在推理的過程中,隨着新的詞的生成,掩碼也會逐漸更新,直到所有內容生成完成。其實這裏用詞的生成是不太準確的,掩碼注意力機制在這裏並沒有直接生成詞,而是和前面的注意力機制一樣在進行QKV計算,因為這裏是一個接一個詞計算,通過這樣的方式計算整體的數據,就需要緩存K和V,這裏之所以不需要緩存Q是因為Q和最新一個詞有關,和之前的都沒有關係,所以就不需要緩存了。
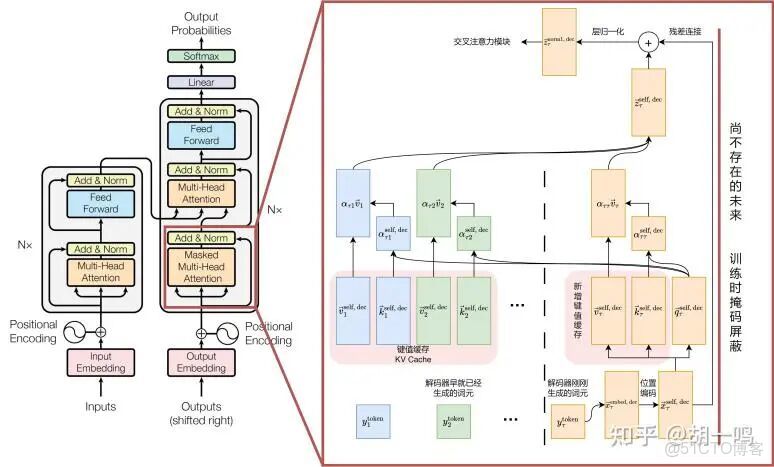
掩碼注意力機制如圖所示,虛線左邊是已經生成的詞,右邊是剛剛生成的詞,這裏只是把需要一次性生成的信息變為一個接一個生成。
接下來是交叉注意力機制。如圖所示
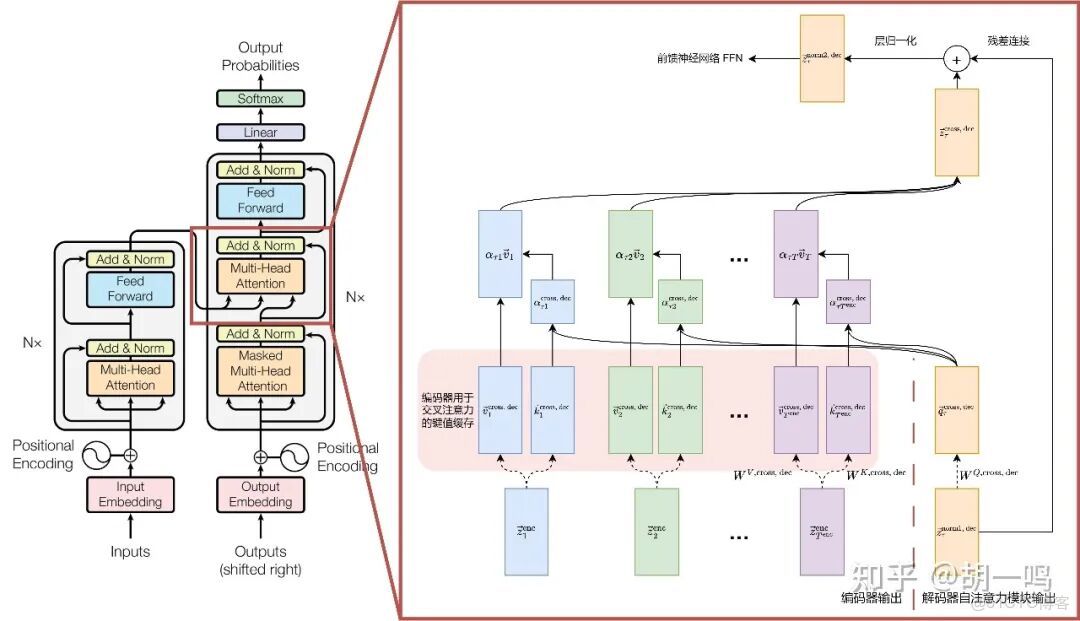
交叉注意力機制在這裏的作用是把來自編碼器和解碼器的數據拼接在一起,注意這裏的解碼器只輸出了Q的信息,這裏就不展開具體的QKV計算了。
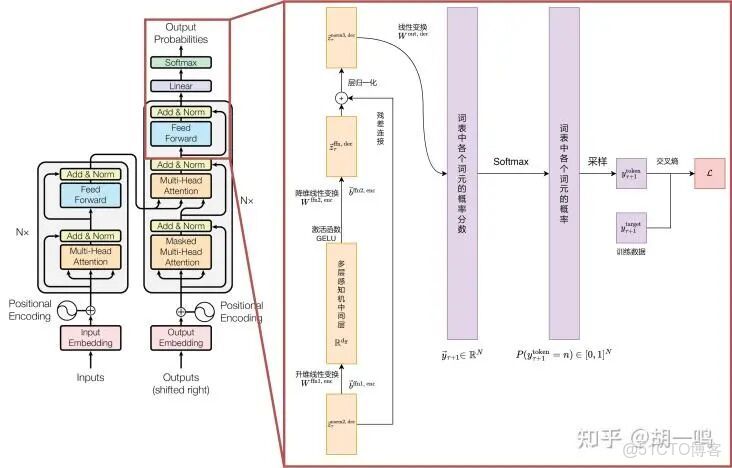
最後,在經過一系列複雜的數學變換之後得到最終的輸出結果。Decoder 最終的輸出是一個向量,其中每個元素是浮點數。我們怎麼把這個向量轉換為單詞呢?這就是我們框選的線性層(Linear)和softmax層完成的。線性層就是一個普通的全連接神經網絡,可以把解碼器輸出的向量,映射到一個更大的向量,這個向量稱為 logits 向量:假設我們的模型有 10000 個英語單詞(模型的輸出詞彙表),此 logits 向量便會有 10000 個數字,每個數表示一個單詞的分數。然後,Softmax 層會把這些分數轉換為概率(把所有的分數轉換為正數,並且加起來等於 1)。然後選擇最高概率的那個數字對應的詞,就是這個時間步的輸出單詞。
Transformer也有很多變種,但是萬變不離其宗,Transformer的層就Encoder和Decoder兩種,無非是搭配組合還有多少層數的問題,即,N層Encoder,N層Decoder,N層Encoder-Decoder混合,其中每種方案都很成功,都可以自我演進。Transformer架構的詳細計算步驟,後面有時間我們會再討論。