
大規模 GPU 集羣跨節點通信的核心是 “數據從本地 GPU 到遠程 GPU 的完整流轉過程”,其主要步驟圍繞 “數據準備→本地導出→跨節點傳輸→遠程導入→一致性校驗” 展開,每個步驟都對應着之前提到的通信延遲、擁塞、開銷等核心問題。
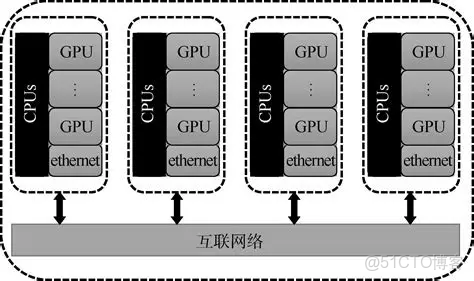
一、跨節點通信的核心步驟(按數據流轉順序)
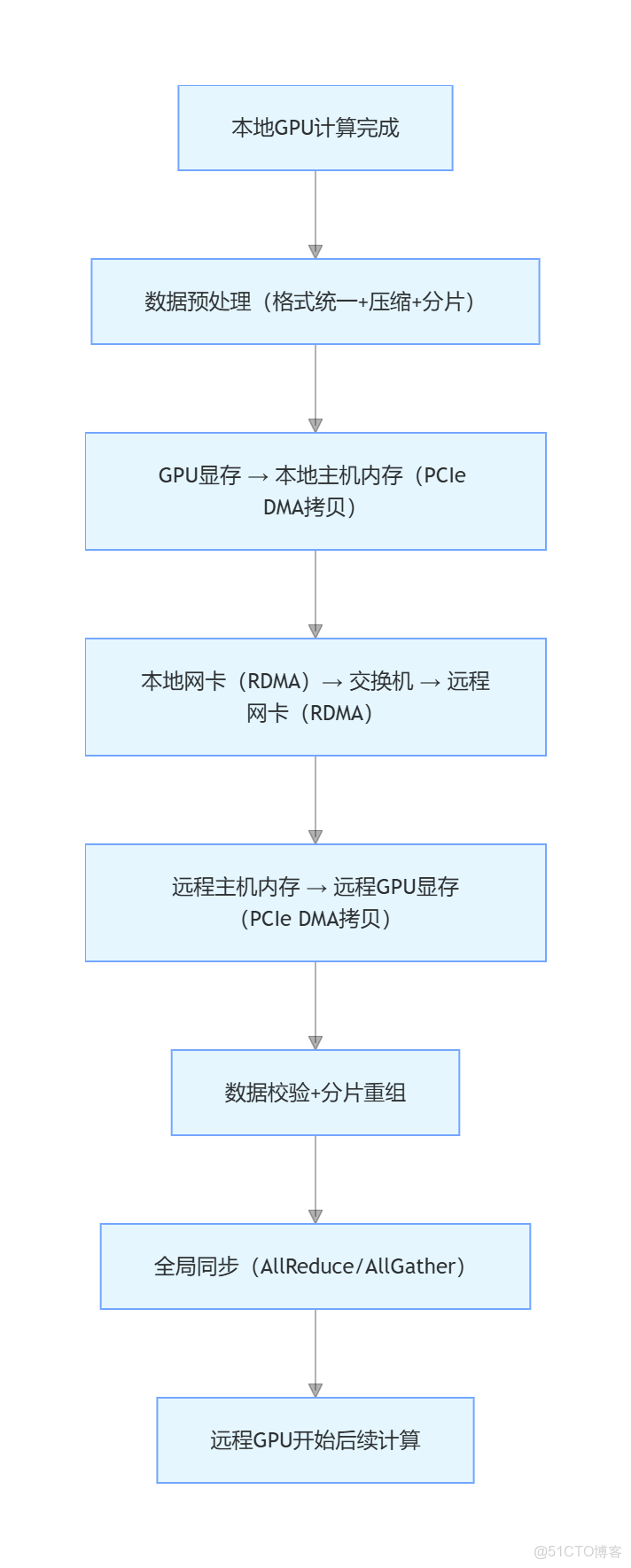
步驟 1:本地 GPU 數據準備與封裝(通信前預處理)
- 核心操作:本地 GPU 完成計算後(如大模型訓練中的 “前向傳播→反向傳播”),需要將待傳輸的數據(梯度、模型參數切片、中間計算結果等)進行預處理:
- 數據格式統一:將 GPU 顯存中的張量(Tensor)轉換為通信協議兼容的格式(如 NCCL 支持的統一張量格式);
- 數據壓縮 / 精度轉換:通過 FP16/FP8 混合精度、量化壓縮(如 INT8)減少數據量(例:FP32→FP8 可將數據量壓縮 4 倍);
- 數據分片與分組:按集羣拓撲(如節點分組、交換機端口分配)將大數據拆分為小分片,避免單條鏈路負載過重。
- 核心目標:減少後續傳輸的數據量,降低帶寬壓力。
- 關聯問題:若壓縮算法效率低或分片不合理,會導致後續傳輸擁塞(如分片過大導致單鏈路超時)。
步驟 2:本地 GPU→本地主機(CPU 內存)的數據導出
- 核心操作:GPU 顯存中的數據無法直接跨節點傳輸,需先通過PCIe 通道導出到本地服務器的 CPU 內存(主機內存):
- GPU 發起 DMA(直接內存訪問)請求,無需 CPU 參與,直接將顯存數據拷貝到主機內存的指定緩衝區(避免 CPU 開銷);
- 若數據量較大,會採用 “流水線拷貝”(邊計算邊拷貝),重疊計算與通信時間(如大模型訓練中的 “計算下一層梯度” 與 “上傳上一層梯度” 並行)。
- 核心目標:實現 GPU 數據向 “跨節點傳輸層” 的過渡。
- 關聯問題:PCIe 帶寬瓶頸(如 PCIe 3.0 x16 僅 32GB/s)會導致導出延遲,若 GPU 計算速度遠超 PCIe 拷貝速度,會出現 “GPU 等內存” 的閒置。
步驟 3:本地主機→遠程主機的跨節點數據傳輸(核心環節)
- 核心操作:這是跨節點通信的核心步驟,數據通過網卡 + 交換機在不同服務器節點間傳輸,流程如下:
- 本地網卡(如 RoCE/InfiniBand 網卡)從主機內存緩衝區讀取數據,通過 RDMA(遠程直接內存訪問)技術跳過 CPU 中轉,直接將數據發送到網卡硬件隊列;
- 數據經物理鏈路(光纖 / 網線)傳輸至集羣交換機(核心交換機 / 葉脊交換機),交換機會根據目標節點地址轉發數據(需查詢路由表);
- 遠程節點網卡接收數據,同樣通過 RDMA 直接寫入遠程主機的內存緩衝區(無需遠程 CPU 參與)。
- 核心目標:低延遲、高帶寬地完成跨節點數據傳輸。
- 關聯問題:
- 延遲累積:鏈路傳播延遲(如 10km 光纖延遲約 50μs)+ 交換機排隊延遲(擁塞時呈指數增長)+ 網卡處理延遲;
- 鏈路擁塞:大量節點同時傳輸時,核心交換機端口帶寬不足,導致數據排隊;
- 拓撲適配:若通信路徑未匹配葉脊拓撲(如跨核心層傳輸),會增加額外延遲。
步驟 4:遠程主機→遠程 GPU 的數據導入
- 核心操作:遠程主機內存中的數據通過PCIe 通道導入到目標 GPU 的顯存:
- 遠程 GPU 發起 DMA 請求,從主機內存緩衝區讀取數據,拷貝到自身顯存;
- 若為多卡並行(如數據並行),會同步進行 “數據分片重組”(將接收的多個分片合併為完整數據)。
- 核心目標:快速將數據交付給遠程 GPU,供後續計算使用。
- 關聯問題:若 PCIe 通道被本地其他任務佔用(如 CPU 同時進行數據預處理),會導致導入延遲,遠程 GPU 因等待數據而閒置。
步驟 5:數據一致性校驗與全局同步(通信後收尾)
- 核心操作:所有節點完成數據傳輸後,需進行全局同步,確保各 GPU 數據一致:
- 數據校驗:檢查接收數據的完整性(如通過 CRC 校驗),避免傳輸過程中出現數據損壞;
- 全局同步:通過集合通信操作(如 AllReduce、AllGather,由 NCCL/OpenMPI 等庫實現),完成梯度聚合、參數更新等操作(例:數據並行中,所有 GPU 的梯度彙總後取平均,再更新模型參數);
- 故障檢測:若某節點未按時完成傳輸或數據校驗失敗,觸發重試機制或故障轉移(如切換備用鏈路)。
- 核心目標:保障跨節點通信的可靠性和數據一致性。
- 關聯問題:
- 同步延遲:大規模集羣(如萬卡級)中,AllReduce 操作的延遲會隨節點數增加而線性增長;
- 容錯不足:若缺乏快速故障檢測機制,單個節點故障會導致整個同步過程阻塞。
二、跨節點通信的簡化流程圖(科研場景適配)
GPU 的通信機制會隨通信範圍(片內、單機多卡、多機多卡)變化,其內部通信的基本單元、不同場景下的通信實現方式,具體如下:
- GPU 內部通信的基本單元GPU 內部通信的基本單元是流多處理器(SM,NVIDIA)/ 計算單元(CU,AMD)。每個 SM/CU 包含大量計算核心、寄存器堆、共享內存等組件,同時 SM/CU 之間,以及 SM/CU 與顯存控制器、張量核心等專用單元的通信,是實現 GPU 內部海量並行任務數據流流轉的核心基礎。
- 同一張 GPU 內部通信的實現方式同一張 GPU 內部圍繞 SM/CU 構建了高效的片內通信架構,核心通過專用內部總線和共享存儲介質實現數據快速流轉,具體路徑如下:
- SM/CU 與寄存器堆、共享內存的通信:寄存器堆是 SM/CU 內線程私有的高速存儲,線程執行計算時可零延遲訪問寄存器中的數據;共享內存則是 SM/CU 內所有線程共享的存儲區域,線程間可通過共享內存交換數據,且訪問速度遠快於全局顯存。比如多個線程協作完成矩陣計算時,可先將中間結果寫入共享內存,再由其他線程讀取,配合
__syncthreads()等同步指令避免數據競爭。- SM/CU 與專用核心的通信:SM/CU 與張量核心、光線追蹤核心之間通過內部高速通道連接。當執行 AI 矩陣乘加任務時,SM 會將任務和數據傳遞給張量核心,張量核心完成高效運算後再將結果回傳給 SM;光線追蹤核心處理光影渲染數據時,也通過該通道與 SM 協同,快速獲取幾何數據和輸出渲染結果。
- SM/CU 與顯存控制器的通信:多個 SM/CU 通過 GPU 內部的片上總線連接到顯存控制器,顯存控制器負責調度 SM/CU 與全局顯存的數據傳輸。當 SM/CU 需要讀取大規模訓練數據,或存儲計算結果時,通過顯存控制器與 GDDR 系列、HBM 系列顯存交互,保障海量數據的穩定供給。
- 同一台服務器內的 GPU 通信方式同一服務器內多 GPU 通信核心依賴 PCIe、NVLink 等技術,搭配 GPU Direct P2P 等方案提升效率,具體如下:
- PCIe 總線 + GPU Direct P2P:這是通用服務器多 GPU 通信的基礎方式。未啓用 P2P 時,數據需經源 GPU→CPU 內存→目標 GPU 的路徑傳輸,延遲高;啓用 GPU Direct P2P 後,若多 GPU 連接在同一 PCIe 總線上,可直接跨 GPU 訪問彼此顯存,無需 CPU 介入。開發者可通過
cudaMemcpyPeer等 CUDA 函數調用該功能,實現數據直接拷貝。- NVLink+NVSwitch:為解決 PCIe 帶寬瓶頸,NVIDIA 的高端 GPU(如 H100 SXM5)通過 NVLink 技術實現 GPU 間高速點對點通信。NVLink 4.0 單卡雙向帶寬達 900GB/s,遠超 PCIe Gen5。當服務器內 GPU 數量較多時,還可通過 NVSwitch 構建全互聯拓撲,實現 8 卡甚至 16 卡的高效互聯,比如 DGX 服務器中的 8 塊 H100 SXM5 通過 NVSwitch 連接,總帶寬可達數 TB/s,滿足大規模並行計算的數據交換需求。
- 多台服務器之間的 GPU 通信方式多台服務器間的 GPU 通信需依託網絡技術,核心是通過繞開 CPU 的直接數據傳輸方案降低延遲,主流方式如下:
- GPU Direct RDMA:這是多服務器 GPU 通信的核心技術。它藉助支持 RDMA 的網絡設備(如 InfiniBand 網卡、RoCE 以太網卡),讓一台服務器的 GPU 直接訪問另一台服務器 GPU 的顯存,無需經過兩端的 CPU 和內存中轉。該方式大幅減少數據拷貝次數,延遲可降至微秒級,常見於分佈式 AI 訓練、超算集羣等場景。
- 網絡框架 + 協議封裝:在軟件層面,通過 NCCL(NVIDIA 集體通信庫)等工具封裝底層通信邏輯,支持
all_reduce“broadcast” 等集體通信操作,適配多服務器 GPU 的協同計算。同時可基於 RoCE(以太網上的 RDMA)、InfiniBand 等協議部署,其中 InfiniBand 主打極致性能,RoCE 則適配現有以太網環境,降低集羣部署成本。此外,少量場景也會通過傳統 Socket 通信間接傳輸 GPU 數據,但效率較低,僅適用於非性能敏感的小規模數據交換。
三、各步驟與核心問題的對應關係(科研優化重點)
|
通信步驟
|
核心問題關聯
|
科研場景優化方向
|
|
數據準備與封裝
|
數據量過大導致帶寬壓力
|
採用 FP8 混合精度、量化壓縮;按拓撲智能分片
|
|
本地 GPU→主機內存
|
PCIe 帶寬瓶頸
|
用 PCIe 5.0/6.0 提升帶寬;開啓計算 - 通信重疊
|
|
跨節點傳輸
|
延遲累積、鏈路擁塞、拓撲適配差
|
採用 InfiniBand/RoCEv2;基於葉脊拓撲優化路由;動態擁塞控制
|
|
遠程主機→遠程 GPU
|
PCIe 通道佔用、導入延遲
|
預留 GPU 專屬 PCIe 帶寬;優先級調度通信任務
|
|
一致性校驗與同步
|
同步延遲、容錯不足
|
用分層 AllReduce(如 NCCL Tree Reduce);部署快速故障檢測機制
|
注意:
RDMA並非必須從內存緩存讀取數據,它本質上可直接訪問經註冊固定的內存區域(多為應用程序的用户態內存,而非 CPU 緩存);同時藉助專用技術,RDMA 也能直接讀取 GPU 顯存,不過這需要特定的硬件與軟件支持,並非標準 RDMA 的默認能力。
- RDMA 無需依賴內存緩存讀取數據標準 RDMA 的設計目標是繞過 CPU 和操作系統內核,直接訪問主機的物理內存,而非 CPU 的內存緩存。其核心要求是將用於傳輸的數據緩衝區通過
ibv_reg_mr等接口註冊並固定,確保該內存區域的物理地址與虛擬地址映射不變,避免被操作系統換出。這個過程中,RDMA 網卡通過 DMA 引擎直接讀寫該物理內存區域,既不會佔用 CPU 緩存,也無需從內存緩存中讀取數據 —— 甚至為了減少 CPU 開銷,RDMA 訪問內存時還會刻意避免填充遠程主機的 CPU 緩存,以此保證 CPU 資源能專注於計算任務而非數據傳輸。- RDMA 可通過 GPUDirect RDMA 技術直接讀取 GPU 顯存標準 RDMA 默認僅支持訪問主機系統內存,而 GPU 顯存屬於獨立 PCIe 設備的內存空間,其地址管理機制與主機內存不同,RDMA 網卡無法直接識別。但 NVIDIA 推出的GPUDirect RDMA技術解決了這一問題,能讓 RDMA 網卡繞過 CPU 和主機內存,直接訪問 GPU 顯存,該技術的實現依賴以下關鍵條件和原理:
- 底層技術支撐:藉助 PCIe P2P(Peer-to-Peer)技術和 PCIe BAR(Base Address Register)機制。PCIe BAR 會在系統啓動時為 GPU 分配地址空間並映射顯存,而 PCIe P2P 允許同一 PCIe 交換機下的 RDMA 網卡和 GPU 直接訪問彼此的地址空間,為直連訪問提供硬件基礎。
- 驅動與軟件協作:NVIDIA GPU 驅動與 RDMA 網卡驅動需深度協作。開發者通過 CUDA API 分配 GPU 顯存後,可將顯存指針傳遞給 RDMA 內存註冊函數,驅動會完成顯存地址到 RDMA 網卡可識別地址的映射,讓 RDMA 網卡的 DMA 引擎能解析並訪問顯存地址。此外,GDRCopy 等開源庫還能進一步優化這一過程,通過將顯存映射到用户空間,降低訪問延遲。
- 硬件適配要求:GPU 需為 NVIDIA Tesla、H100 等支持 GPUDirect RDMA 的型號,RDMA 網卡需選用 Mellanox InfiniBand 等兼容型號,且兩者需連接在同一 PCIe 交換機下,否則會回退到 “顯存→主機內存→RDMA 網卡” 的中轉路徑。
在實際應用中,這種直連訪問常用於分佈式 AI 訓練等場景。例如多機 GPU 集羣執行 AllReduce 梯度同步時,通過 GPUDirect RDMA,RDMA 網卡可直接讀取各節點 GPU 顯存中的梯度數據並完成聚合,再將結果直接寫入各節點的 GPU 顯存,相比傳統中轉路徑,能顯著降低延遲、提升帶寬並減少 CPU 開銷。
四、科研場景關鍵補充
- 集合通信庫的作用:步驟 5 的全局同步依賴 NCCL(NVIDIA 集羣通信庫)、華為昇騰的 HCCL 等工具,這些庫會自動優化通信路徑(如根據集羣拓撲選擇最優同步策略),是跨節點通信的 “核心軟件支撐”。
- 萬卡級集羣的特殊處理:超大規模集羣(如鵬城雲腦 II)會將通信步驟拆分為 “節點內同步→機架內同步→跨機架同步”,通過分層拓撲減少跨核心層的傳輸,降低延遲。
- 大模型訓練的優化重點:步驟 2 和步驟 4 的 “計算 - 通信重疊”(如 Megatron-LM 的流水線並行)、步驟 3 的 “拓撲感知路由”(如 NCCL 的拓撲檢測功能)是提升效率的關鍵,能將 GPU 閒置時間從 40% 降至 10% 以下。
注意:
單個 GPU 內部的多流處理器(SM)通信不需要使用集合通信,而同一台服務器內的多 GPU 通信通常在特定場景下需要,普通場景可用更簡單的點對點通信,以下是具體分析:
- 單個 GPU 內部多流處理器(SM):無需集合通信。集合通信的核心是多個獨立通信節點(如多 GPU、多服務器)參與的全局協同通信(如廣播、歸約等),而單個 GPU 內的多 SM 屬於同一硬件單元,其通信設計目標是低延遲的局部協同,依賴硬件層面的原生機制即可高效實現,完全不需要集合通信。具體依靠兩種方式:
- 共享存儲 + 線程同步:SM 間可藉助 GPU 的共享內存、寄存器堆等存儲介質交換數據。例如多個 SM 協作處理矩陣計算時,可將中間結果寫入共享內存,配合
__syncthreads()等 CUDA 同步指令,實現 SM 內線程組的有序讀寫,無需複雜的全局通信邏輯。- 內部高速總線調度:SM 與張量核心、顯存控制器等組件通過 GPU 內部高速片上總線連接,數據傳輸由硬件調度完成。比如 SM 需要從全局顯存讀取數據時,通過總線直接與顯存控制器交互,數據流轉路徑短且高效,無需集合通信的多節點協調流程。
- 同一台服務器內的多 GPU:按需使用集合通信。多 GPU 屬於相互獨立的硬件節點,其通信方式需根據場景選擇,普通點對點傳輸無需集合通信,而大規模並行計算等場景則必須依賴集合通信保障效率,具體分為兩種情況:
- 普通場景:點對點通信即可滿足。若僅需兩台 GPU 間的數據傳輸,比如將 GPU0 的計算結果拷貝到 GPU1,可通過 CUDA 的
cudaMemcpyPeer等接口調用 GPU Direct P2P 技術,依託 PCIe 或 NVLink 實現直接的數據拷貝。這種點對點通信無需其他 GPU 參與,流程簡單,比集合通信更節省開銷。- 大規模並行場景:必須使用集合通信。在深度學習訓練、高性能計算等場景中,多 GPU 常需完成全局數據協同,此時必須藉助集合通信。例如數據並行訓練中,每輪迭代後所有 GPU 需同步梯度數據,通過 NCCL 庫提供的
AllReduce集合通信原語,可將所有 GPU 的梯度數據聚合後再分發到每個 GPU,保障模型參數一致性;再如模型並行中,需通過Broadcast原語將主 GPU 的模型參數廣播到其他 GPU。NCCL 這類專為 GPU 設計的庫,還會針對 PCIe、NVLink 的硬件拓撲優化通信路徑,其效率遠高於手動組合點對點通信實現同等功能。
總結
大規模 GPU 集羣跨節點通信的核心步驟是 “數據預處理→本地導出→跨節點傳輸→遠程導入→全局同步”,每個步驟都涉及硬件(GPU、PCIe、網卡、交換機)和軟件(通信庫、壓縮算法)的協同。科研中優化跨節點通信,本質是針對每個步驟的瓶頸(如 PCIe 帶寬、鏈路擁塞、同步延遲),通過硬件升級、軟件優化、拓撲適配等方式,減少數據傳輸的時間和開銷,讓 GPU 算力充分釋放。